Openvms Performance Management
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Demystifying the Real-Time Linux Scheduling Latency
Demystifying the Real-Time Linux Scheduling Latency Daniel Bristot de Oliveira Red Hat, Italy [email protected] Daniel Casini Scuola Superiore Sant’Anna, Italy [email protected] Rômulo Silva de Oliveira Universidade Federal de Santa Catarina, Brazil [email protected] Tommaso Cucinotta Scuola Superiore Sant’Anna, Italy [email protected] Abstract Linux has become a viable operating system for many real-time workloads. However, the black-box approach adopted by cyclictest, the tool used to evaluate the main real-time metric of the kernel, the scheduling latency, along with the absence of a theoretically-sound description of the in-kernel behavior, sheds some doubts about Linux meriting the real-time adjective. Aiming at clarifying the PREEMPT_RT Linux scheduling latency, this paper leverages the Thread Synchronization Model of Linux to derive a set of properties and rules defining the Linux kernel behavior from a scheduling perspective. These rules are then leveraged to derive a sound bound to the scheduling latency, considering all the sources of delays occurring in all possible sequences of synchronization events in the kernel. This paper also presents a tracing method, efficient in time and memory overheads, to observe the kernel events needed to define the variables used in the analysis. This results in an easy-to-use tool for deriving reliable scheduling latency bounds that can be used in practice. Finally, an experimental analysis compares the cyclictest and the proposed tool, showing that the proposed method can find sound bounds faster with acceptable overheads. 2012 ACM Subject Classification Computer systems organization → Real-time operating systems Keywords and phrases Real-time operating systems, Linux kernel, PREEMPT_RT, Scheduling latency Digital Object Identifier 10.4230/LIPIcs.ECRTS.2020.9 Supplementary Material ECRTS 2020 Artifact Evaluation approved artifact available at https://doi.org/10.4230/DARTS.6.1.3. -

Context Switch in Linux – OS Course Memory Layout – General Picture
ContextContext switchswitch inin LinuxLinux ©Gabriel Kliot, Technion 1 Context switch in Linux – OS course Memory layout – general picture Stack Stack Stack Process X user memory Process Y user memory Process Z user memory Stack Stack Stack tss->esp0 TSS of CPU i task_struct task_struct task_struct Process X kernel Process Y kernel Process Z kernel stack stack and task_struct stack and task_struct and task_struct Kernel memory ©Gabriel Kliot, Technion 2 Context switch in Linux – OS course #1 – kernel stack after any system call, before context switch prev ss User Stack esp eflags cs … User Code eip TSS … orig_eax … tss->esp0 es Schedule() function frame esp ds eax Saved on the kernel stack during ebp a transition to task_struct kernel mode by a edi jump to interrupt and by SAVE_ALL esi macro edx thread.esp0 ecx ebx ©Gabriel Kliot, Technion 3 Context switch in Linux – OS course #2 – stack of prev before switch_to macro in schedule() func prev … Schedule() saved EAX, ECX, EDX Arguments to contex_switch() Return address to schedule() TSS Old (schedule’s()) EBP … tss->esp0 esp task_struct thread.eip thread.esp thread.esp0 ©Gabriel Kliot, Technion 4 Context switch in Linux – OS course #3 – switch_to: save esi, edi, ebp on the stack of prev prev … Schedule() saved EAX, ECX, EDX Arguments to contex_switch() Return address to schedule() TSS Old (schedule’s()) EBP … tss->esp0 ESI EDI EBP esp task_struct thread.eip thread.esp thread.esp0 ©Gabriel Kliot, Technion 5 Context switch in Linux – OS course #4 – switch_to: save esp in prev->thread.esp -

Openvms Record Management Services Reference Manual
OpenVMS Record Management Services Reference Manual Order Number: AA-PV6RD-TK April 2001 This reference manual contains general information intended for use in any OpenVMS programming language, as well as specific information on writing programs that use OpenVMS Record Management Services (OpenVMS RMS). Revision/Update Information: This manual supersedes the OpenVMS Record Management Services Reference Manual, OpenVMS Alpha Version 7.2 and OpenVMS VAX Version 7.2 Software Version: OpenVMS Alpha Version 7.3 OpenVMS VAX Version 7.3 Compaq Computer Corporation Houston, Texas © 2001 Compaq Computer Corporation Compaq, AlphaServer, VAX, VMS, the Compaq logo Registered in U.S. Patent and Trademark Office. Alpha, PATHWORKS, DECnet, DEC, and OpenVMS are trademarks of Compaq Information Technologies Group, L.P. in the United States and other countries. UNIX and X/Open are trademarks of The Open Group in the United States and other countries. All other product names mentioned herein may be the trademarks of their respective companies. Confidential computer software. Valid license from Compaq required for possession, use, or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor’s standard commercial license. Compaq shall not be liable for technical or editorial errors or omissions contained herein. The information in this document is provided "as is" without warranty of any kind and is subject to change without notice. The warranties for Compaq products are set forth in the express limited warranty statements accompanying such products. Nothing herein should be construed as constituting an additional warranty. -

Overcoming Traditional Problems with OS Huge Page Management
MEGA: Overcoming Traditional Problems with OS Huge Page Management Theodore Michailidis Alex Delis Mema Roussopoulos University of Athens University of Athens University of Athens Athens, Greece Athens, Greece Athens, Greece [email protected] [email protected] [email protected] ABSTRACT KEYWORDS Modern computer systems now feature memory banks whose Huge pages, Address Translation, Memory Compaction aggregate size ranges from tens to hundreds of GBs. In this context, contemporary workloads can and do often consume ACM Reference Format: Theodore Michailidis, Alex Delis, and Mema Roussopoulos. 2019. vast amounts of main memory. This upsurge in memory con- MEGA: Overcoming Traditional Problems with OS Huge Page Man- sumption routinely results in increased virtual-to-physical agement. In The 12th ACM International Systems and Storage Con- address translations, and consequently and more importantly, ference (SYSTOR ’19), June 3–5, 2019, Haifa, Israel. ACM, New York, more translation misses. Both of these aspects collectively NY, USA, 11 pages. https://doi.org/10.1145/3319647.3325839 do hamper the performance of workload execution. A solu- tion aimed at dramatically reducing the number of address translation misses has been to provide hardware support for 1 INTRODUCTION pages with bigger sizes, termed huge pages. In this paper, we Computer memory capacities have been increasing sig- empirically demonstrate the benefits and drawbacks of using nificantly over the past decades, leading to the development such huge pages. In particular, we show that it is essential of memory hungry workloads that consume vast amounts for modern OS to refine their software mechanisms to more of main memory. This upsurge in memory consumption rou- effectively manage huge pages. -

Oracle Database Installation Guide 10G Release 2 (10.2)
Oracle®[1] Database Installation Guide 11g Release 2 (11.2) for HP OpenVMS Itanium E56668-01 June 2015 Oracle Database Installation Guide, 11g Release 2 (11.2) for HP OpenVMS Itanium E56668-01 Copyright © 2008, 2015, Oracle and/or its affiliates. All rights reserved. Primary Author: Nisha Sridhar Contributors: Dave Hayter, Gary Huffman, Marc Noel, Chris Schuetz, David Miller, Kevin Duffy, Steve Holck, Grant Hayden, Gary Tate This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -
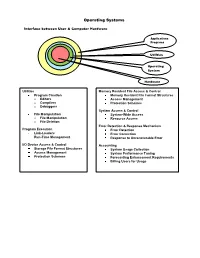
Operating Systems
Operating Systems Interface between User & Computer Hardware Applications Programs Utilities Operating System Hardware Utilities Memory Resident File Access & Control Program Creation Memory Resident File Format Structures o Editors Access Management o Compilers Protection Schemes o Debuggers System Access & Control File Manipulation System-Wide Access o File Manipulation Resource Access o File Deletion Error Detection & Response Mechanism Program Execution Error Detection Link-Loaders Error Correction Run-Time Management Response to Unrecoverable Error I/O Device Access & Control Accounting Storage File Format Structures System Usage Collection Access Management System Performance Tuning Protection Schemes Forecasting Enhancement Requirements Billing Users for Usage Resource Manager O/S KernelKernel I/O Controller Printers, Keyboards, I/O Controller Monitors, Portions of Cameras, the O/S Etc. currently in use Computer Main System Memory Portions of Various I/O Application Devices Programs Currently in use Operating System Data Application Programs I/O Controller Storage Processor Processor Data Processor Processor Operation Allocation of Main Memory is made jointly by both the O/S and Memory Management Hardware O/S controls access to I/O devices by Application Programs O/S controls access to and use of files O/S controls access to and use of the processors, i.e., how much time can be allocated to the execution of a particular Application Program Classification of Operating Systems Interactive O/S Keyboard & Monitor Access to O/S Immediate, -

Software Product Description and Quickspecs
VSI OpenVMS Alpha Version 8.4-2L2 Operating System DO-DVASPQ-01A Software Product Description and QuickSpecs PRODUCT NAME: VSI OpenVMS Alpha Version 8.4-2L2 DO-DVASPQ-01A This SPD and QuickSpecs describes the VSI OpenVMS Alpha Performance Release Operating System software, Version 8.4-2L2 (hereafter referred to as VSI OpenVMS Alpha V8.4-2L2). DESCRIPTION OpenVMS is a general purpose, multiuser operating system that runs in both production and development environments. VSI OpenVMS Alpha Version 8.4-2L2 is the latest release of the OpenVMS Alpha computing environment by VMS Software, Inc (VSI). VSI OpenVMS Alpha V8.4-2L2 is compiled to take advantage of architectural features such as byte and word memory reference instructions, and floating-point improvements, which are available only in HPE AlphaServer EV6 or later processors. This optimized release improves performance by taking advantage of faster hardware-based instructions that were previously emulated in software. NOTE: VSI OpenVMS Alpha V8.4-2L2 does not work on, and is not supported on, HPE AlphaServer pre-EV6 systems. OpenVMS Alpha supports HPE’s AlphaServer series computers. OpenVMS software supports industry standards, facilitating application portability and interoperability. OpenVMS provides symmetric multiprocessing (SMP) support for multiprocessing systems. The OpenVMS operating system can be tuned to perform well in a wide variety of environments. This includes combinations of compute-intensive, I/O-intensive, client/server, real-time, and other environments. Actual system performance depends on the type of computer, available physical memory, and the number and type of active disk and tape drives. The OpenVMS operating system has well-integrated networking, distributed computing, client/server, windowing, multi-processing, and authentication capabilities. -

1.Operating Systems Overview
OPERATING SYSTEMS OVERVIEW Contents O.S.Functions The Evolution of O.S. Characteristics of O.S. Basic hardware elements 1 Contents O.S.Components System calls O.S.Structure USER 1 USER 2 USER 3 USER n compiler text interpreter database editor system operating system computer hardware 2 Programming system components compilers loader linker comand interpreter (shell) … O.S. purposes to make a computer more convenient and easier to use to allow more efficient operations of the whole computer system 3 To simplify the program development The O.S. masks the details of the hardware from the programmer and provides the programmer with a convenient interface for using system resources (system calls) To simplify the program development Definition of an extended (virtual) machine 4 VIRTUAL MACHINE ES: DISK CONTROLLER commands: read, write, head motion, ecc… parameters: sector address, number of sectors for each track, ecc… state and error conditions 5 Hardware resource allocation Access to system resources must be controlled and conflicts for resource contention resolved Hardware resource allocation Any user should be provided with required resources, by following suitable policies 6 The details for the management of hardware resources must be hidden to users System calls provide the interface between the application programs and the O.S. 7 THE EVOLUTION OF O.S. Serial processing No O.S. Control by console Scheduling Setup time 8 Simple batch systems Monitor Resident in main memory Control of the program execution “batch” solution -

Asynchronous Page Faults Aix Did It Red Hat Author Gleb Natapov August 10, 2010
Asynchronous page faults Aix did it Red Hat Author Gleb Natapov August 10, 2010 Abstract Host memory overcommit may cause guest memory to be swapped. When guest vcpu access memory swapped out by a host its execution is suspended until memory is swapped back. Asynchronous page fault is a way to try and use guest vcpu more efficiently by allowing it to execute other tasks while page is brought back into memory. Part I How KVM Handles Guest Memory and What Inefficiency it Has With Regards to Host Swapping Mapping guest memory into host memory But we do it on demand Page fault happens on first guest access What happens on a page fault? 1 VMEXIT 2 kvm mmu page fault() 3 gfn to pfn() 4 get user pages fast() no previously mapped page and no swap entry found empty page is allocated 5 page is added into shadow/nested page table What happens on a page fault? 1 VMEXIT 2 kvm mmu page fault() 3 gfn to pfn() 4 get user pages fast() no previously mapped page and no swap entry found empty page is allocated 5 page is added into shadow/nested page table What happens on a page fault? 1 VMEXIT 2 kvm mmu page fault() 3 gfn to pfn() 4 get user pages fast() no previously mapped page and no swap entry found empty page is allocated 5 page is added into shadow/nested page table What happens on a page fault? 1 VMEXIT 2 kvm mmu page fault() 3 gfn to pfn() 4 get user pages fast() no previously mapped page and no swap entry found empty page is allocated 5 page is added into shadow/nested page table What happens on a page fault? 1 VMEXIT 2 kvm mmu page fault() 3 gfn to pfn() -

What Is an Operating System III 2.1 Compnents II an Operating System
Page 1 of 6 What is an Operating System III 2.1 Compnents II An operating system (OS) is software that manages computer hardware and software resources and provides common services for computer programs. The operating system is an essential component of the system software in a computer system. Application programs usually require an operating system to function. Memory management Among other things, a multiprogramming operating system kernel must be responsible for managing all system memory which is currently in use by programs. This ensures that a program does not interfere with memory already in use by another program. Since programs time share, each program must have independent access to memory. Cooperative memory management, used by many early operating systems, assumes that all programs make voluntary use of the kernel's memory manager, and do not exceed their allocated memory. This system of memory management is almost never seen any more, since programs often contain bugs which can cause them to exceed their allocated memory. If a program fails, it may cause memory used by one or more other programs to be affected or overwritten. Malicious programs or viruses may purposefully alter another program's memory, or may affect the operation of the operating system itself. With cooperative memory management, it takes only one misbehaved program to crash the system. Memory protection enables the kernel to limit a process' access to the computer's memory. Various methods of memory protection exist, including memory segmentation and paging. All methods require some level of hardware support (such as the 80286 MMU), which doesn't exist in all computers. -

Openvms: an Introduction
The Operating System Handbook or, Fake Your Way Through Minis and Mainframes by Bob DuCharme VMS Table of Contents Chapter 7 OpenVMS: An Introduction.............................................................................. 7.1 History..........................................................................................................................2 7.1.1 Today........................................................................................................................3 7.1.1.1 Popular VMS Software..........................................................................................4 7.1.2 VMS, DCL................................................................................................................4 Chapter 8 Getting Started with OpenVMS........................................................................ 8.1 Starting Up...................................................................................................................7 8.1.1 Finishing Your VMS Session...................................................................................7 8.1.1.1 Reconnecting..........................................................................................................7 8.1.2 Entering Commands..................................................................................................8 8.1.2.1 Retrieving Previous Commands............................................................................9 8.1.2.2 Aborting Screen Output.........................................................................................9 -

Measuring Software Performance on Linux Technical Report
Measuring Software Performance on Linux Technical Report November 21, 2018 Martin Becker Samarjit Chakraborty Chair of Real-Time Computer Systems Chair of Real-Time Computer Systems Technical University of Munich Technical University of Munich Munich, Germany Munich, Germany [email protected] [email protected] OS program program CPU .text .bss + + .data +/- + instructions cache branch + coherency scheduler misprediction core + pollution + migrations data + + interrupt L1i$ miss access + + + + + + context mode + + (TLB flush) TLB + switch data switch miss L1d$ +/- + (KPTI TLB flush) miss prefetch +/- + + + higher-level readahead + page cache miss walk + + multicore + + (TLB shootdown) TLB coherency page DRAM + page fault + cache miss + + + disk + major minor I/O Figure 1. Event interaction map for a program running on an Intel Core processor on Linux. Each event itself may cause processor cycles, and inhibit (−), enable (+), or modulate (⊗) others. Abstract that our measurement setup has a large impact on the results. Measuring and analyzing the performance of software has More surprisingly, however, they also suggest that the setup reached a high complexity, caused by more advanced pro- can be negligible for certain analysis methods. Furthermore, cessor designs and the intricate interaction between user we found that our setup maintains significantly better per- formance under background load conditions, which means arXiv:1811.01412v2 [cs.PF] 20 Nov 2018 programs, the operating system, and the processor’s microar- chitecture. In this report, we summarize our experience on it can be used to improve high-performance applications. how performance characteristics of software should be mea- CCS Concepts • Software and its engineering → Soft- sured when running on a Linux operating system and a ware performance; modern processor.