Recognition of Ultra Low Resolution, Anti-Aliased Text with Small Font Sizes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Letters Are Made for Reading
Letters are made for reading A lot of things has to be taken into consideration when you make typographical choices. With the typography of logos and headlines, etc, the style and tone of your publication is determined. But when it comes to the body text, legibility is more important than anything else. BACK IN THE LATE SEVENTIES when I was study- In ”micro” typography, on the other hand, legi- ing architecture at the Royal Academy of Arts, one bility is more important than style. Or maybe we of the rules we were taught was: ”A building must ought to talk about ”readability”, a phrase used by have a distinctive entrance”. That ought to make some typographers, making the point that what sense: It hardly matters what’s inside a house if you fi nd legible depends more than anything else you can’t fi nd the door, does it? on what you are used to read. However perfect Good typography, I’d say, is like the entrance the letterforms of a new typeface, it may still ap- to a house. It should lead you inside, help you to pear hard to read if people think it looks strange. the contents—which is indeed the most important Perhaps this is why most people still prefer text thing. with serifs even though repeated surveys have But then again, what is good typography? Well, shown no legibility differences between sans and as there are numerous disciplines of graphic de- serif typefaces. sign, this question does not have one single—or If you read the same newspaper every day, simple—answer. -

Basic Styles of Lettering for Monuments and Markers.Indd
BASIC STYLES OF LETTERING FOR MONUMENTS AND MARKERS Monument Builders of North America, Inc. AA GuideGuide ToTo TheThe SelectionSelection ofof LETTERINGLETTERING From primitive times, man has sought to crude or garish or awkward letters, but in communicate with his fellow men through letters of harmonized alphabets which have symbols and graphics which conveyed dignity, balance and legibility. At the same meaning. Slowly he evolved signs and time, they are letters which are designed to hieroglyphics which became the visual engrave or incise cleanly and clearly into expression of his language. monumental stone, and to resist change or obliteration through year after year of Ultimately, this process evolved into the exposure. writing and the alphabets of the various tongues and civilizations. The early scribes The purpose of this book is to illustrate the and artists refi ned these alphabets, and the basic styles or types of alphabets which have development of printing led to the design been proved in memorial art, and which are of alphabets of related character and ready both appropriate and practical in the lettering readability. of monuments and markers. Memorial art--one of the oldest of the arts- Lettering or engraving of family memorials -was among the fi rst to use symbols and or individual markers is done today with “letters” to inscribe lasting records and history superb fi delity through the use of lasers or the into stone. The sculptors and carvers of each sandblast process, which employs a powerful generation infl uenced the form of letters and stream or jet of abrasive “sand” to cut into the numerals and used them to add both meaning granite or marble. -

Resources Ton 'QX Repository (For Details, Contact Peter Ab- Bott, E-Mail Address Above)
TUGboat, Volume 10 (1989), No. 2 Janet users may obtain back issues from the As- Resources ton 'QX repository (for details, contact Peter Ab- bott, e-mail address above). DECnetISPAN users may obtain back issues from the European (con- Announcing (belatedly) -MAG tact Massimo Calvani, fisicaQastrpd.infn. it) or American (contact Ed Bell, 7388 : :bell) DECnet Don Hosek T)?J repositories. University of Illinois at Chicago Others with network access should send a mes- After being chided for not publicizing my electronic sage to archive-serverQsun.soe.clarkson.edu "magazine" enough, I have decided to make a formal with the first line being path followed by an address announcement of its availability to the 'J&X cornmu- from Clarkson to you, and then a line nity at large. get texmag texmag.v.nn What is =MAG? for each back issue desired where v is the volume number and nn the issue number. The line index WMAG is available free of charge to anyone reach- texmag will give a list of back issues available. able by electronic mail and is published approxi- A typical mail request may resemble: mately every two months. The subject material index t exmag generally falls somewhere between the somewhat get texmag texmag.l.08 chaotic (but still useful) correspondence of 'QXHAX and UKW, and the printed matter in TUGboat How do I submit articles to TEXMAG? and QXline. Some previous articles have included I was hoping you would ask. Articles are accepted an early version of Dominik Wujastyk's article on on all aspects of T)?J, M'QX, and METAFONT from fonts from TUB 9#2; an overview of the differ- specific information on interfacing graphics packages ent font files used by 'QX, METAFONT, and device with particular DVI drivers to general information drivers; macros for commutative diagrams and sim- on macro writing to product reviews to whatever ple chemical equations and many other topics. -

Thai Typefaces (Part 1): Assumption on Visibility and Legibility Problems
Thai Typefaces (Part 1): Assumption on Visibility and Legibility Problems 1* 2 3 Rachapoom PUNSONGSERM , Shoji SUNAGA , Hisayasu IHARA 1 Graduate School of Design, Kyushu University, Fukuoka, Japan 1 Faculty of Fine and Applied Arts, Thammasat University, Pathum Thani, Thailand 2,3 Faculty of Design, Kyushu University, Fukuoka, Japan Abstract Background Regarding the growing elderly population, which several countries are experiencing right now, various typeface designs have been developed to address the need for increased legibility and visibility. Certainly, common factors that affect the well-being of the elderly are related to visual acuity. The universal design fonts (UD fonts) developed in Japan are regarded as a role model for the development of highly legible and visible Thai typefaces. As Thailand’s society matures, the concern for creating a Thai UD font based on human-centered design is ideal for the purpose of supporting elderly people as well as people with amblyopia and low vision Methods As the first step to developing a Thai UD font, as a preliminary study, we qualitatively tested the tolerance of Thai characters under blurred conditions. We used the fifty Thai conventional text fonts in the boundary of ‘The Table of Thai Character's Relationship’ in the same character heights as stimuli. The stimuli simulated the visual acuity of people with poor vision at different blur levels. Results From the tests, we have established the expected Thai confused pairs, as the assumptions. We found the simulated condition revealed many problems with the visibility and the legibility matters of Thai Characters, as the assumptions; however, these findings led to ideas and possible solutions, which may provide assistance for the approach to designing the first Thai UD font. -

Font HOWTO Font HOWTO
Font HOWTO Font HOWTO Table of Contents Font HOWTO......................................................................................................................................................1 Donovan Rebbechi, elflord@panix.com..................................................................................................1 1.Introduction...........................................................................................................................................1 2.Fonts 101 −− A Quick Introduction to Fonts........................................................................................1 3.Fonts 102 −− Typography.....................................................................................................................1 4.Making Fonts Available To X..............................................................................................................1 5.Making Fonts Available To Ghostscript...............................................................................................1 6.True Type to Type1 Conversion...........................................................................................................2 7.WYSIWYG Publishing and Fonts........................................................................................................2 8.TeX / LaTeX.........................................................................................................................................2 9.Getting Fonts For Linux.......................................................................................................................2 -

The File Cmfonts.Fdd for Use with Latex2ε
The file cmfonts.fdd for use with LATEX 2".∗ Frank Mittelbach Rainer Sch¨opf 2019/12/16 This file is maintained byA theLTEX Project team. Bug reports can be opened (category latex) at https://latex-project.org/bugs.html. 1 Introduction This file contains the external font information needed to load the Computer Modern fonts designed by Don Knuth and distributed with TEX. From this file all .fd files (font definition files) for the Computer Modern fonts, both with old encoding (OT1) and Cork encoding (T1) are generated. The Cork encoded fonts are known under the name ec fonts. 2 Customization If you plan to install the AMS font package or if you have it already installed, please note that within this package there are additional sizes of the Computer Modern symbol and math italic fonts. With the release of LATEX 2", these AMS `extracm' fonts have been included in the LATEX font set. Therefore, the math .fd files produced here assume the presence of these AMS extensions. For text fonts in T1 encoding, the directive new selects the new (version 1.2) DC fonts. For the text fonts in OT1 and U encoding, the optional docstrip directive ori selects a conservatively generated set of font definition files, which means that only the basic font sizes coming with an old LATEX 2.09 installation are included into the \DeclareFontShape commands. However, on many installations, people have added missing sizes by scaling up or down available Metafont sources. For example, the Computer Modern Roman italic font cmti is only available in the sizes 7, 8, 9, and 10pt. -

Surviving the TEX Font Encoding Mess Understanding The
Surviving the TEX font encoding mess Understanding the world of TEX fonts and mastering the basics of fontinst Ulrik Vieth Taco Hoekwater · EuroT X ’99 Heidelberg E · FAMOUS QUOTE: English is useful because it is a mess. Since English is a mess, it maps well onto the problem space, which is also a mess, which we call reality. Similary, Perl was designed to be a mess, though in the nicests of all possible ways. | LARRY WALL COROLLARY: TEX fonts are mess, as they are a product of reality. Similary, fontinst is a mess, not necessarily by design, but because it has to cope with the mess we call reality. Contents I Overview of TEX font technology II Installation TEX fonts with fontinst III Overview of math fonts EuroT X ’99 Heidelberg 24. September 1999 3 E · · I Overview of TEX font technology What is a font? What is a virtual font? • Font file formats and conversion utilities • Font attributes and classifications • Font selection schemes • Font naming schemes • Font encodings • What’s in a standard font? What’s in an expert font? • Font installation considerations • Why the need for reencoding? • Which raw font encoding to use? • What’s needed to set up fonts for use with T X? • E EuroT X ’99 Heidelberg 24. September 1999 4 E · · What is a font? in technical terms: • – fonts have many different representations depending on the point of view – TEX typesetter: fonts metrics (TFM) and nothing else – DVI driver: virtual fonts (VF), bitmaps fonts(PK), outline fonts (PFA/PFB or TTF) – PostScript: Type 1 (outlines), Type 3 (anything), Type 42 fonts (embedded TTF) in general terms: • – fonts are collections of glyphs (characters, symbols) of a particular design – fonts are organized into families, series and individual shapes – glyphs may be accessed either by character code or by symbolic names – encoding of glyphs may be fixed or controllable by encoding vectors font information consists of: • – metric information (glyph metrics and global parameters) – some representation of glyph shapes (bitmaps or outlines) EuroT X ’99 Heidelberg 24. -
Using Fonts Installed in Local Texlive - Tex - Latex Stack Exchange
27-04-2015 Using fonts installed in local texlive - TeX - LaTeX Stack Exchange sign up log in tour help TeX LaTeX Stack Exchange is a question and answer site for users of TeX, LaTeX, ConTeXt, and related Take the 2minute tour × typesetting systems. It's 100% free, no registration required. Using fonts installed in local texlive I have installed texlive at ~/texlive . I have installed collectionfontsrecommended using tlmgr . Now, ~/texlive/2014/texmfdist/fonts/ has several folders: afm , cmap , enc , ... , vf . Here is the output of tlmgr info helvetic package: helvetic category: Package shortdesc: URW "Base 35" font pack for LaTeX. longdesc: A set of fonts for use as "dropin" replacements for Adobe's basic set, comprising: Century Schoolbook (substituting for Adobe's New Century Schoolbook); Dingbats (substituting for Adobe's Zapf Dingbats); Nimbus Mono L (substituting for Abobe's Courier); Nimbus Roman No9 L (substituting for Adobe's Times); Nimbus Sans L (substituting for Adobe's Helvetica); Standard Symbols L (substituting for Adobe's Symbol); URW Bookman; URW Chancery L Medium Italic (substituting for Adobe's Zapf Chancery); URW Gothic L Book (substituting for Adobe's Avant Garde); and URW Palladio L (substituting for Adobe's Palatino). installed: Yes revision: 31835 sizes: run: 2377k relocatable: No catdate: 20120606 22:57:48 +0200 catlicense: gpl collection: collectionfontsrecommended But when I try to compile: \documentclass{article} \usepackage{helvetic} \begin{document} Hello World! \end{document} It gives an error: ! LaTeX Error: File `helvetic.sty' not found. Type X to quit or <RETURN> to proceed, or enter new name. -

Vision Performance Institute
Vision Performance Institute Technical Report Individual character legibility James E. Sheedy, OD, PhD Yu-Chi Tai, PhD John Hayes, PhD The purpose of this study was to investigate the factors that influence the legibility of individual characters. Previous work in our lab [2], including the first study in this sequence, has studied the relative legibility of fonts with different anti- aliasing techniques or other presentation medias, such as paper. These studies have tested the relative legibility of a set of characters configured with the tested conditions. However the relative legibility of individual characters within the character set has not been studied. While many factors seem to affect the legibility of a character (e.g., character typeface, character size, image contrast, character rendering, the type of presentation media, the amount of text presented, viewing distance, etc.), it is not clear what makes a character more legible when presenting in one way than in another. In addition, the importance of those different factors to the legibility of one character may not be held when the same set of factors was presented in another character. Some characters may be more legible in one typeface and others more legible in another typeface. What are the character features that affect legibility? For example, some characters have wider openings (e.g., the opening of “c” in Calibri is wider than the character “c” in Helvetica); some letter g’s have double bowls while some have single (e.g., “g” in Batang vs. “g” in Verdana); some have longer ascenders or descenders (e.g., “b” in Constantia vs. -

Typographers'
TUGboat, Volume 39 (2018), No. 3 171 Typographers’ Inn Table 1: Widths of set for some related serif, sans-serif, and monospace fonts Peter Flynn CMR abcdefghijlkmnopqrstuvwxyz O0|I1l Font tables CMSS abcdefghijlkmnopqrstuvwxyz O0|I1l CMTT abcdefghijlkmnopqrstuvwxyz O0|I1l Peter Wilson has rightly called me to account for PT Serif abcdefghijlkmnopqrstuvwxyz O0|I1l missing out the fonttable (two t’s) package in the de- PT Sans abcdefghijlkmnopqrstuvwxyz O0|I1l scription of my experimental fontable (one t) package PT Mono abcdefghijlkmnopqrstuvwxyz O0|I1l [4, p 17]. Libertine abcdefghijlkmnopqrstuvwxyz O0|I1l The fonttable package is much more powerful Biolinum abcdefghijlkmnopqrstuvwxyz O0|I1l than the one I am [still] working on, and I was so Lib. Mono abcdefghijlkmnopqrstuvwxyz O0|I1l intent on reimplementing the specific requirements Plex Serif abcdefghijlkmnopqrstuvwxyz O0|I1l abcdefghijlkmnopqrstuvwxyz O0|I1l A Plex Sans of the allfnt8.tex file in X LE TEX to the exclusion Plex Mono abcdefghijlkmnopqrstuvwxyz O0|I1l of pretty much everything else that I didn’t do any Nimbus Serif abcdefghijlkmnopqrstuvwxyz O0|I1l justice to fonttable (and a number of other test and do. Sans abcdefghijlkmnopqrstuvwxyz O0|I1l display tools). do. Mono abcdefghijlkmnopqrstuvwxyz O0|I1l I am expecting shortly to have more time at my do. Mono N abcdefghijlkmnopqrstuvwxyz O0|I1l disposal to remedy this and other neglected projects. Times abcdefghijlkmnopqrstuvwxyz O0|I1l Helvetica abcdefghijlkmnopqrstuvwxyz O0|I1l Monospace that fits Courier abcdefghijlkmnopqrstuvwxyz O0|I1l Luxi Mono * abcdefghijlkmnopqrstuvwxyz O0|I1l One of the recurrent problems in documentation is finding a suitable monospace font for program listings Times, Helvetica, and Courier (unrelated) are included for or other examples of code. -
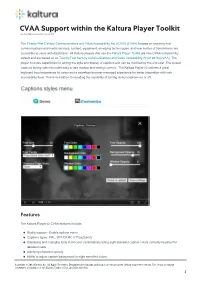
CVAA Support Within the Kaltura Player Toolkit Last Modified on 06/21/2020 4:25 Pm IDT
CVAA Support within the Kaltura Player Toolkit Last Modified on 06/21/2020 4:25 pm IDT The Twenty-First Century Communications and Video Accessibility Act of 2010 (CVAA) focuses on ensuring that communications and media services, content, equipment, emerging technologies, and new modes of transmission are accessible to users with disabilities. All Kaltura players that use the Kaltura Player Toolkit are now CVAA compliant by default and are based on on Twenty-First Century Communications and Video Accessibility Act of 2010 (CVAA). The player includes capabilities for editing the style and display of captions and can be modified by the end user. The closed captions styling editor includes easy to use markup and testing controls. The Kaltura Player v2 delivers a great keyboard input experience for users and a seamless browser-managed experience for better integration with web accessibility tools. This is in addition to including the capability of turning closed captions on or off. Features The Kaltura Player v2 CVAA features include: Studio support - Enable options menu Captions types: XML, SRT/DFXP, VTT(outband) Displaying and changing fonts in 64 color combinations using eight standard caption colors currently required for television sets. Adjusting character opacity Ability to adjust caption background in eight specified colors. Copyright ©️ 2019 Kaltura Inc. All Rights Reserved. Designated trademarks and brands are the property of their respective owners. Use of this document constitutes acceptance of the Kaltura Terms of Use and Privacy Policy. 1 Ability to adjust character edge (i.e., non, raised, depressed, uniform or drop shadow). Ability to adjust caption window color and opacity. -

P Font-Change Q UV 3
p font•change q UV Version 2015.2 Macros to Change Text & Math fonts in TEX 45 Beautiful Variants 3 Amit Raj Dhawan [email protected] September 2, 2015 This work had been released under Creative Commons Attribution-Share Alike 3.0 Unported License on July 19, 2010. You are free to Share (to copy, distribute and transmit the work) and to Remix (to adapt the work) provided you follow the Attribution and Share Alike guidelines of the licence. For the full licence text, please visit: http://creativecommons.org/licenses/by-sa/3.0/legalcode. 4 When I reach the destination, more than I realize that I have realized the goal, I am occupied with the reminiscences of the journey. It strikes to me again and again, ‘‘Isn’t the journey to the goal the real attainment of the goal?’’ In this way even if I miss goal, I still have attained goal. Contents Introduction .................................................................................. 1 Usage .................................................................................. 1 Example ............................................................................... 3 AMS Symbols .......................................................................... 3 Available Weights ...................................................................... 5 Warning ............................................................................... 5 Charter ....................................................................................... 6 Utopia .......................................................................................