OBJECT PERCEPTION AS BAYESIAN INFERENCE Daniel
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Zhou Ren Email: [email protected] Homepage
Zhou Ren Email: [email protected] Homepage: http://cs.ucla.edu/~zhou.ren INDUSTRY EXPERIENCE 12/2018 – present, Senior Research Lead, Wormpex AI Research, Bellevue, WA, USA 05/2018 – 12/2018, Senior Research Scientist, Snap Inc., Santa Monica, CA, USA 10/2017 – 05/2018, Research Scientist (III), Snap Inc., Venice, CA, USA 04/2017 – 10/2017, Research Scientist (II), Snap Inc., Venice, CA, USA 07/2016 – 04/2017, Research Scientist (I), Snap Inc., Venice, CA, USA 03/2016 – 06/2016, Research Intern, Snap Inc., Venice, CA, USA 06/2015 – 09/2015, Deep Learning Research Intern, Adobe Research, San Jose, CA, USA 06/2013 – 09/2013, Research Intern, Toyota Technological Institute, Chicago, IL, USA 07/2010 – 07/2012, Project Officer, Media Technology Lab, Nanyang Technological University, Singapore PROFESSIONAL SERVICES Area Chair, CVPR 2021, CVPR 2022, WACV 2022. Senior Program Committee, AAAI 2021. Associate Editor, The Visual Computer Journal (TVCJ), 2018 – present. Director of Industrial Governance Board, Asia-Pacific Signal and Information Processing Association (APSIPA). EDUCATION Doctor of Philosophy 09/2012 – 09/2016, University of California, Los Angeles (UCLA) Major: Vision and Graphics, Computer Science Department Advisor: Prof. Alan Yuille Master of Science 09/2012 – 06/2014, University of California, Los Angeles (UCLA) Major: Vision and Graphics, Computer Science Department Advisor: Prof. Alan Yuille Master of Engineering 08/2010 – 01/2012, Nanyang Technological University (NTU), Singapore Major: Information Engineering, School -

Lecture 4 Objects
4 Perceiving and Recognizing Objects ClickChapter to edit 4 Perceiving Master title and style Recognizing Objects • What and Where Pathways • The Problems of Perceiving and Recognizing Objects • Middle Vision • Object Recognition ClickIntroduction to edit Master title style How do we recognize objects? • Retinal ganglion cells and LGN = Spots • Primary visual cortex = Bars How do spots and bars get turned into objects and surfaces? • Clearly our brains are doing something pretty sophisticated beyond V1. ClickWhat toand edit Where Master Pathways title style Objects in the brain • Extrastriate cortex: Brain regions bordering primary visual cortex that contains other areas involved in visual processing. V2, V3, V4, etc. ClickWhat toand edit Where Master Pathways title style Objects in the brain (continued) • After extrastriate cortex, processing of object information is split into a “what” pathway and a “where” pathway. “Where” pathway is concerned with the locations and shapes of objects but not their names or functions. “What” pathway is concerned with the names and functions of objects regardless of location. Figure 4.2 The main visual areas of the macaque monkey cortex Figure 4.3 A partial “wiring” diagram for the main visual areas of the brain Figure 4.4 The main visual areas of the human cortex ClickWhat toand edit Where Master Pathways title style The receptive fields of extrastriate cells are more sophisticated than those in striate cortex. They respond to visual properties important for perceiving objects. • For instance, “boundary ownership.” For a given boundary, which side is part of the object and which side is part of the background? Figure 4.5 Notice that the receptive field sees the same dark edge in both images ClickWhat toand edit Where Master Pathways title style The same visual input occurs in both (a) and (b) and a V1 neuron would respond equally to both. -

Art Perception * David Cycleback
Art Perception * David Cycleback Art Perception by David Cycleback An introduction to understanding art and aesthetic perception, covering key psychological, cognitive science, physiological and philosophical concepts. Center for Artifact Studies: cycleback.com email: [email protected] Hamerweit Books ISBN : 978-1-312-11749-5 © 2014 david rudd cycleback This book can be purchased in print (paperback) at amazon and Barnes and Noble 1 Art Perception * David Cycleback Fans feel a connection to cartoon characters, seeing them as if they’re living beings, following their lives, laughing at their jokes, feeling good when good things happen to them and bad when bad things happen. A kid can feel closer to a cartoon character than a living, breathing next door neighbor. 2 Art Perception * David Cycleback Many feel a human-to-human connection to the figure in this Modigliani painting even though it is not physically human in many ways. 3 Art Perception * David Cycleback Authentic Colors? 1800s Harper's Woodcuts, or woodcut prints from the magazine Harper's Weekly, are popularly collected today. The images show nineteenth century life, including celebrities, sports, US Presidents, war, high society, nature and street life. Though originally black and white, some of the prints have been hand colored over the years. As age is important to collectors, prints that were colored in the 1800s are more valuable than those colored recently. The problem is that modern ideas lead collectors to misdate the coloring. Due to their notions about the old fashioned Victorian era, most people assume that vintage 1800s coloring will be subtle, soft, pallid and conservative. -

Illusion Free Download
ILLUSION FREE DOWNLOAD Sherrilyn Kenyon | 464 pages | 05 Feb 2015 | Little, Brown Book Group | 9781907411564 | English | London, United Kingdom Illusion (Ability) Visually perceived images that differ from objective reality. This urge to see depth is probably so strong because our ability to use two-dimensional information to infer a three dimensional world is essential Illusion allowing us to operate in the world. The exact height of the bars is Illusion important here, but the relative heights should look something like this:. A hallucination is a perception Illusion a thing or quality Illusion has no physical counterpart: Under the influence of LSD, Terry had hallucinations that the living-room floor was rippling. MD GtI. Name that government! Water-color illusions consist of object-hole effects and coloration. Then, using some impressive mental geometry, our brain adjusts the experienced length of the top line to be consistent with the size it would have if it were that far away: Illusion two lines are the same length on my retina, but different distances from me, the more distant line must be in Illusion longer. Choose the Right Synonym for illusion delusionillusionhallucinationmirage mean something that is believed to be true or real Illusion that is actually false or unreal. ISSN Illusion Ponzo illusion is an example of an illusion which uses monocular cues of depth perception to fool the eye. The phi phenomenon is yet another example of how the brain perceives motion, which is most often created by blinking lights in close succession. The cubic texture induces a Necker-cube -like optical illusion. -

Compositional Convolutional Neural Networks: a Deep Architecture with Innate Robustness to Partial Occlusion
Compositional Convolutional Neural Networks: A Deep Architecture with Innate Robustness to Partial Occlusion Adam Kortylewski Ju He Qing Liu Alan Yuille Johns Hopkins University Abstract Recent findings show that deep convolutional neural net- works (DCNNs) do not generalize well under partial occlu- sion. Inspired by the success of compositional models at classifying partially occluded objects, we propose to inte- grate compositional models and DCNNs into a unified deep model with innate robustness to partial occlusion. We term this architecture Compositional Convolutional Neural Net- work. In particular, we propose to replace the fully con- nected classification head of a DCNN with a differentiable compositional model. The generative nature of the compo- sitional model enables it to localize occluders and subse- Figure 1: Partially occluded cars from the MS-COCO quently focus on the non-occluded parts of the object. We dataset [20] that are misclassified by a standard DCNN conduct classification experiments on artificially occluded but correctly classified by the proposed CompositionalNet. images as well as real images of partially occluded objects Intuitively, a CompositionalNet can localize the occluders from the MS-COCO dataset. The results show that DC- (occlusion scores on the right) and subsequently focus on NNs do not classify occluded objects robustly, even when the non-occluded parts of the object to classify the image. trained with data that is strongly augmented with partial occlusions. Our proposed model outperforms standard DC- NNs by a large margin at classifying partially occluded ob- One approach to overcome this limitation is to use data jects, even when it has not been exposed to occluded ob- augmentation in terms of partial occlusion [6, 35]. -

Innateness and (Bayesian) Visual Perception Reconciling Nativism and Development
3 BRIAN J. SCHOLL Innateness and (Bayesian) Visual Perception Reconciling Nativism and Development 1 A Research Strategy Because innateness is such a complex and controversial issue when applied to higher level cognition, it can be useful to explore how nature and nurture interact in simpler, less controversial contexts. One such context is the study of certain aspects of visual perception—where especially rigorous models are possible, and where it is less controversial to claim that certain aspects of the visual system are in part innately specified. The hope is that scrutiny of these simpler contexts might yield lessons that can then be applied to debates about the possible innateness of other aspects of the mind. This chapter will explore a particular way in which visual processing may involve innate constraints and will attempt to show how such processing overcomes one enduring challenge to nativism. In particular, many challenges to nativist theories in other areas of cognitive psychology (e.g., ‘‘theory of mind,’’ infant cognition) have focused on the later development of such abili- ties, and have argued that such development is in conflict with innate origins (since those origins would have to be somehow changed or overwritten). Innate- ness, in these contexts, is seen as antidevelopmental, associated instead with static processes and principles. In contrast, certain perceptual models demonstrate how the very same mental processes can both be innately specified and yet develop richly in response to experience with the environment. In fact, this process is entirely unmysterious, as is made clear in certain formal theories of visual per- ception, including those that appeal to spontaneous endogenous stimulation, and those based on Bayesian inference. -

Brain Mapping Methods: Segmentation, Registration, and Connectivity Analysis
UCLA UCLA Electronic Theses and Dissertations Title Brain Mapping Methods: Segmentation, Registration, and Connectivity Analysis Permalink https://escholarship.org/uc/item/1jt7m230 Author Prasad, Gautam Publication Date 2013 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California University of California Los Angeles Brain Mapping Methods: Segmentation, Registration, and Connectivity Analysis A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Computer Science by Gautam Prasad 2013 c Copyright by Gautam Prasad 2013 Abstract of the Dissertation Brain Mapping Methods: Segmentation, Registration, and Connectivity Analysis by Gautam Prasad Doctor of Philosophy in Computer Science University of California, Los Angeles, 2013 Professor Demetri Terzopoulos, Chair We present a collection of methods that model and interpret information represented in structural magnetic resonance imaging (MRI) and diffusion MRI images of the living hu- man brain. Our solution to the problem of brain segmentation in structural MRI combines artificial life and deformable models to develop a customizable plan for segmentation real- ized as cooperative deformable organisms. We also present work to represent and register white matter pathways as described in diffusion MRI. Our method represents these path- ways as maximum density paths (MDPs), which compactly represent information and are compared using shape based registration for population studies. In addition, we present a group of methods focused on connectivity in the brain. These include an optimization for a global probabilistic tractography algorithm that computes fibers representing connectivity pathways in tissue, a novel maximum-flow based measure of connectivity, a classification framework identifying Alzheimer's disease based on connectivity measures, and a statisti- cal framework to find the optimal partition of the brain for connectivity analysis. -

Contour Junctions Underlie Neural Representations of Scene Categories
bioRxiv preprint doi: https://doi.org/10.1101/044156; this version posted March 16, 2016. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Contour junctions underlie neural representations of scene categories in high-level human visual cortex Contour junctions underlie neural code of scenes Heeyoung Choo1, & Dirk. B. Walther1 1Department of Psychology, University of Toronto 100 St. George Street, Toronto, ON, M5S 3G3 Canada Correspondence should be addressed to Heeyoung Choo, 100 St. George Street, Toronto, ON, M5S 3G3 Canada. Phone: +1-416-946-3200 Email: [email protected] Conflict of Interest: The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest. 1 bioRxiv preprint doi: https://doi.org/10.1101/044156; this version posted March 16, 2016. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Abstract 2 3 Humans efficiently grasp complex visual environments, making highly consistent judgments of entry- 4 level category despite their high variability in visual appearance. How does the human brain arrive at the 5 invariant neural representations underlying categorization of real-world environments? We here show that 6 the neural representation of visual environments in scenes-selective human visual cortex relies on statistics 7 of contour junctions, which provide cues for the three-dimensional arrangement of surfaces in a scene. -

Object Perception As Bayesian Inference 1
Object Perception as Bayesian Inference 1 Object Perception as Bayesian Inference Daniel Kersten Department of Psychology, University of Minnesota Pascal Mamassian Department of Psychology, University of Glasgow Alan Yuille Departments of Statistics and Psychology, University of California, Los Angeles KEYWORDS: shape, material, depth, perception, vision, neural, psychophysics, fMRI, com- puter vision ABSTRACT: We perceive the shapes and material properties of objects quickly and reliably despite the complexity and objective ambiguities of natural images. Typical images are highly complex because they consist of many objects embedded in background clutter. Moreover, the image features of an object are extremely variable and ambiguous due to the effects of projection, occlusion, background clutter, and illumination. The very success of everyday vision implies neural mechanisms, yet to be understood, that discount irrelevant information and organize ambiguous or \noisy" local image features into objects and surfaces. Recent work in Bayesian theories of visual perception has shown how complexity may be managed and ambiguity resolved through the task-dependent, probabilistic integration of prior object knowledge with image features. CONTENTS OBJECT PERCEPTION: GEOMETRY AND MATERIAL : : : : : : : : : : : : : 2 INTRODUCTION TO BAYES : : : : : : : : : : : : : : : : : : : : : : : : : : : : 3 How to resolve ambiguity in object perception? : : : : : : : : : : : : : : : : : : : : : : 3 How does vision deal with the complexity of images? : : : : : -
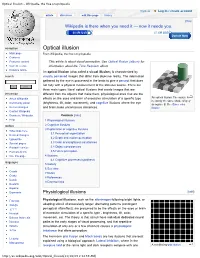
Optical Illusion - Wikipedia, the Free Encyclopedia
Optical illusion - Wikipedia, the free encyclopedia Try Beta Log in / create account article discussion edit this page history [Hide] Wikipedia is there when you need it — now it needs you. $0.6M USD $7.5M USD Donate Now navigation Optical illusion Main page From Wikipedia, the free encyclopedia Contents Featured content This article is about visual perception. See Optical Illusion (album) for Current events information about the Time Requiem album. Random article An optical illusion (also called a visual illusion) is characterized by search visually perceived images that differ from objective reality. The information gathered by the eye is processed in the brain to give a percept that does not tally with a physical measurement of the stimulus source. There are three main types: literal optical illusions that create images that are interaction different from the objects that make them, physiological ones that are the An optical illusion. The square A About Wikipedia effects on the eyes and brain of excessive stimulation of a specific type is exactly the same shade of grey Community portal (brightness, tilt, color, movement), and cognitive illusions where the eye as square B. See Same color Recent changes and brain make unconscious inferences. illusion Contact Wikipedia Donate to Wikipedia Contents [hide] Help 1 Physiological illusions toolbox 2 Cognitive illusions 3 Explanation of cognitive illusions What links here 3.1 Perceptual organization Related changes 3.2 Depth and motion perception Upload file Special pages 3.3 Color and brightness -

A Dictionary of Neurological Signs.Pdf
A DICTIONARY OF NEUROLOGICAL SIGNS THIRD EDITION A DICTIONARY OF NEUROLOGICAL SIGNS THIRD EDITION A.J. LARNER MA, MD, MRCP (UK), DHMSA Consultant Neurologist Walton Centre for Neurology and Neurosurgery, Liverpool Honorary Lecturer in Neuroscience, University of Liverpool Society of Apothecaries’ Honorary Lecturer in the History of Medicine, University of Liverpool Liverpool, U.K. 123 Andrew J. Larner MA MD MRCP (UK) DHMSA Walton Centre for Neurology & Neurosurgery Lower Lane L9 7LJ Liverpool, UK ISBN 978-1-4419-7094-7 e-ISBN 978-1-4419-7095-4 DOI 10.1007/978-1-4419-7095-4 Springer New York Dordrecht Heidelberg London Library of Congress Control Number: 2010937226 © Springer Science+Business Media, LLC 2001, 2006, 2011 All rights reserved. This work may not be translated or copied in whole or in part without the written permission of the publisher (Springer Science+Business Media, LLC, 233 Spring Street, New York, NY 10013, USA), except for brief excerpts in connection with reviews or scholarly analysis. Use in connection with any form of information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed is forbidden. The use in this publication of trade names, trademarks, service marks, and similar terms, even if they are not identified as such, is not to be taken as an expression of opinion as to whether or not they are subject to proprietary rights. While the advice and information in this book are believed to be true and accurate at the date of going to press, neither the authors nor the editors nor the publisher can accept any legal responsibility for any errors or omissions that may be made. -

Object Recognition, Which Is Solved in Visual Areas Beyond V1
Object vision (Chapter 4) Lecture 9 Jonathan Pillow Sensation & Perception (PSY 345 / NEU 325) Princeton University, Fall 2017 1 Introduction What do you see? 2 Introduction What do you see? 3 Introduction What do you see? 4 Introduction How did you recognize that all 3 images were of houses? How did you know that the 1st and 3rd images showed the same house? This is the problem of object recognition, which is solved in visual areas beyond V1. 5 Unfortunately, we still have no idea how to solve this problem. Not easy to see how to make Receptive Fields for houses the way we combined LGN receptive fields to make V1 receptive fields! house-detector receptive field? 6 Viewpoint Dependence View-dependent model - a model that will only recognize particular views of an object • template-based model e.g. “house” template Problem: need a neuron (or “template”) for every possible view of the object - quickly run out of neurons! 7 Middle Vision Middle vision: – after basic features have been extracted and before object recognition and scene understanding • Involves perception of edges and surfaces • Determines which regions of an image should be grouped together into objects 8 Finding edges • How do you find the edges of objects? • Cells in primary visual cortex have small receptive fields • How do you know which edges go together and which ones don’t? 9 Middle Vision Computer-based edge detectors are not as good as humans • Sometimes computers find too many edges • “Edge detection” is another failed theory (along with Fourier analysis!) of what V1 does.