Reliable Multicast Protocols and Their Application on the Green Bank Telescope
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ipv6 Addresses
56982_CH04II 12/12/97 3:34 PM Page 57 CHAPTER 44 IPv6 Addresses As we already saw in Chapter 1 (Section 1.2.1), the main innovation of IPv6 addresses lies in their size: 128 bits! With 128 bits, 2128 addresses are available, which is ap- proximately 1038 addresses or, more exactly, 340.282.366.920.938.463.463.374.607.431.768.211.456 addresses1. If we estimate that the earth’s surface is 511.263.971.197.990 square meters, the result is that 655.570.793.348.866.943.898.599 IPv6 addresses will be available for each square meter of earth’s surface—a number that would be sufficient considering future colo- nization of other celestial bodies! On this subject, we suggest that people seeking good hu- mor read RFC 1607, “A View From The 21st Century,” 2 which presents a “retrospective” analysis written between 2020 and 2023 on choices made by the IPv6 protocol de- signers. 56982_CH04II 12/12/97 3:34 PM Page 58 58 Chapter Four 4.1 The Addressing Space IPv6 designers decided to subdivide the IPv6 addressing space on the ba- sis of the value assumed by leading bits in the address; the variable-length field comprising these leading bits is called the Format Prefix (FP)3. The allocation scheme adopted is shown in Table 4-1. Table 4-1 Allocation Prefix (binary) Fraction of Address Space Allocation of the Reserved 0000 0000 1/256 IPv6 addressing space Unassigned 0000 0001 1/256 Reserved for NSAP 0000 001 1/128 addresses Reserved for IPX 0000 010 1/128 addresses Unassigned 0000 011 1/128 Unassigned 0000 1 1/32 Unassigned 0001 1/16 Aggregatable global 001 -

Introduction to IP Multicast Routing
Introduction to IP Multicast Routing by Chuck Semeria and Tom Maufer Abstract The first part of this paper describes the benefits of multicasting, the Multicast Backbone (MBONE), Class D addressing, and the operation of the Internet Group Management Protocol (IGMP). The second section explores a number of different algorithms that may potentially be employed by multicast routing protocols: - Flooding - Spanning Trees - Reverse Path Broadcasting (RPB) - Truncated Reverse Path Broadcasting (TRPB) - Reverse Path Multicasting (RPM) - Core-Based Trees The third part contains the main body of the paper. It describes how the previous algorithms are implemented in multicast routing protocols available today. - Distance Vector Multicast Routing Protocol (DVMRP) - Multicast OSPF (MOSPF) - Protocol-Independent Multicast (PIM) Introduction There are three fundamental types of IPv4 addresses: unicast, broadcast, and multicast. A unicast address is designed to transmit a packet to a single destination. A broadcast address is used to send a datagram to an entire subnetwork. A multicast address is designed to enable the delivery of datagrams to a set of hosts that have been configured as members of a multicast group in various scattered subnetworks. Multicasting is not connection oriented. A multicast datagram is delivered to destination group members with the same “best-effort” reliability as a standard unicast IP datagram. This means that a multicast datagram is not guaranteed to reach all members of the group, or arrive in the same order relative to the transmission of other packets. The only difference between a multicast IP packet and a unicast IP packet is the presence of a “group address” in the Destination Address field of the IP header. -

Optimizing Xcast Treemap Performance with NFV and SDN T
Optimizing Xcast Treemap Performance with NFV and SDN T. Khoa Phan Joined work with David Griffin and Miguel Rio University College London Next Generation Networking workshop, July 2016 Facebook Livestream System A B source Origin server C Edge cache Live stream server Origin server D E Fig. 4: Facebook livestream system - CDN [1] • 98% of user requests can be served immediately by edge caches • Each edge cache can serve up to 200,000 users simultaneously [1] https://code.facebook.com/posts/1653074404941839/under-the-hood-broadcasting-live-video-to-millions/ 2 What is Xcast Treemap? S Breath-first tree traversal A B C D E List of IP addresses A 2 0 2 0 0 Treemap Sender S creates packets: B C A B C D E Src: S, Dest: A Payload 2 0 2 0 0 D E Unicast part Xcast treemap part (optional) Today router only understands unicast part. Xcast router lookups and forwards for each IP in the list. Xcast end-host and Xcast router software are available (in IPv6): http://www.ee.ucl.ac.uk/~uceetkp/Xcast_software.zip 3 How Xcast Treemap works? Unicast routing table at R3 Dest Next hop Full Xcast packet header created by S: C C A B C D E D D Src: S, Dest: A Payload 2 0 2 0 0 E E Dest in List dests in unicast part X6Tpart A B D S A | A B C D E B | B D | D A S C B C R1 R2 C | C D E R3 C | C D E E | E Dest Next hop D E E A A Today router B, C, D, E R2 Unicast routing table at R1 Fig. -

AWS Certified Advanced Networking - Specialty Exam
N E T 2 0 7 - R Understanding the basics of IPv6 networking on AWS Shakeel Ahmad Solutions Architect Amazon Web Services © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Agenda Why IPv6 Brief overview of the IPv6 protocol IPv6 in Amazon VPC IPv4 to IPv6 migration patterns Hands-on with IPv6 on AWS © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. IPv4 exhaustion IPv4 vs IPv6 address size IPv4: 32-bit / 4,294,967,296 addresses (~4.3 x 109) 11000000 00000000 00000010 00000001 IPv6: 128-bit / 340,282,366,920,938,463,463,374,607,431,768,211,456 addresses (~3.4 x 1038) 0010000000000001 0000110110111000 0000111011000010 0000000000000000 0000000000000000 0000000000000000 0000000000000000 0000000000000001 © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. IPv4 vs IPv6 address types IPv4: Address types 1. Unicast 2. Broadcast 3. Multicast IPv6: Address types 1. Unicast 2. Multicast 3. Anycast IPv4 vs IPv6 address format IPv4: Dotted Decimal Notation + CIDR 192.168.0.1/24 127.0.0.1 IPv6: Colon-Separated Hextet Notation + CIDR 2001:0db8:0ec2:0000:0000:0000:0000:0001/64 0000:0000:0000:0000:0000:0000:0000:0001 2001:db8:ec2:0:0:0:0:1/64 0:0:0:0:0:0:0:1 2001:db8:ec2::1/64 ::1 © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Amazon VPC—dual-stack VPC Internet gateway IPv4: IPv6: Instance Public Subnet Amazon VPC—private subnet? NAT? VPC Egress-only internet gateway IPv4: IPv6: Instance X Private subnet Amazon VPC—IPv6 routing and more . -

Modeling and Analyzing Anycast and Geocast Routing in Wireless Mesh Networks
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 7, No. 9, 2016 Modeling and Analyzing Anycast and Geocast Routing in Wireless Mesh Networks Fazle Hadi∗, Sheeraz Ahmed†, Abid Ali Minhas‡, Atif Naseer§ ∗ Preston University Kohat, Peshawar Campus, Pakistan † Preston University Kohat, Peshawar Campus, Pakistan ‡ Al Yamamah University Riyadh, Saudi Arabia § Science and Technology Unit, Umm Al Qura University, Saudi Arabia Abstract—Wireless technology has become an essential part of this era’s human life and has the capability of connecting virtually to any place within the universe. A mesh network is a self healing wireless network, built through a number of distributed and redundant nodes to support variety of applications and provide reliability. Similarly, anycasting is an important service that might be used for a variety of applications. In this paper we have studied anycast routing in the wireless mesh networks and the anycast traffic from the gateway to the mesh network having multiple anycast groups. We have also studied the geocast traffic in which the packets reach to the group head via unicast traffic and then are broadcasted inside the group. Moreover, we have studied the intergroup communication between different anycast groups. The review of the related literature shows that no one has considered anycasting and geocasting from gateway to the mesh network while considering the multiple anycast groups and intergroup communication. The network is modeled, simulated and analyzed for its various parameters using OMNET++ simulator. Keywords—Mesh Network; Anycast; Geocast; Routing; Unicast Fig. 1. Basic mesh architecture [21] I. INTRODUCTION for every node considering the gateway as a source of heat) The basic aim of the wireless mesh networks (WMNs) is [2]. -

Chapter 4 Network Layer
Chapter 4 Network Layer A note on the use of these ppt slides: We’re making these slides freely available to all (faculty, students, readers). Computer They’re in PowerPoint form so you see the animations; and can add, modify, and delete slides (including this one) and slide content to suit your needs. Networking: A Top They obviously represent a lot of work on our part. In return for use, we only ask the following: Down Approach v If you use these slides (e.g., in a class) that you mention their source th (after all, we’d like people to use our book!) 6 edition v If you post any slides on a www site, that you note that they are adapted Jim Kurose, Keith Ross from (or perhaps identical to) our slides, and note our copyright of this Addison-Wesley material. March 2012 Thanks and enjoy! JFK/KWR All material copyright 1996-2012 J.F Kurose and K.W. Ross, All Rights Reserved Network Layer 4-1 Chapter 4: outline 4.1 introduction 4.5 routing algorithms 4.2 virtual circuit and § link state datagram networks § distance vector 4.3 what’s inside a router § hierarchical routing 4.4 IP: Internet Protocol 4.6 routing in the Internet § datagram format § RIP § IPv4 addressing § OSPF § BGP § ICMP § IPv6 4.7 broadcast and multicast routing Network Layer 4-2 Interplay between routing, forwarding routing algorithm determines routing algorithm end-end-path through network forwarding table determines local forwarding table local forwarding at this router dest address output link address-range 1 3 address-range 2 2 address-range 3 2 address-range 4 1 IP destination -

Bosch IP Video Networks
Bosch IP Video Networks en Bosch IP Video Manual Bosch IP Video Networks Table of Contents | en 3 Table of Contents 1 Introduction 5 2 Examples for Bosch IP Video network solutions 7 3 General network concepts 13 3.1 OSI 7 Layer Model 13 3.2 Hubs and switches 13 3.3 Routers and Layer 3 switches 14 3.4 Unicast – broadcast – multicast 14 3.5 IP addresses 15 3.6 Ports 16 3.7 VLAN 17 3.8 Network models 17 3.9 Centralized or decentralized recording 20 4 Bosch IP Video key features 21 4.1 Video quality and resolution 21 4.2 Dual streaming 21 4.3 Multicast 22 4.4 Bandwidth 25 4.5 Video Content Analysis 27 4.6 Recording at the edge 27 5 Calculating network bandwidth and storage capacity 28 5.1 Network bandwidth calculation 29 5.2 Storage calculation for VRM recording 30 6 Planning Bosch IP Video networks 31 6.1 Used ports 31 6.1.1 Centralized VRM recording 36 6.1.2 Decentralized VRM recording 37 6.1.3 Centralized NVR recording 38 6.1.4 Decentralized NVR recording 39 6.2 Bandwidth calculation 39 6.2.1 Decentralized VRM recording 40 6.2.2 Decentralized VRM recording with export 42 6.2.3 Centralized NVR recording 42 6.2.4 Centralized NVR recording with export 44 6.3 Storage calculation 44 6.3.1 VRM recording and iSCSI sessions 45 6.3.2 VRM playback 45 6.3.3 VRM storage calculation 46 6.3.4 Calculation example 1 46 6.3.5 Calculation example 2 46 6.4 VLAN 46 Bosch Sicherheitsssysteme GmbH Bosch IP Video Manual - | V2 | 2011.07 4 en | Table of Contents Bosch IP Video Networks 6.5 Examples for recording solutions 48 6.5.1 Direct-to-iSCSI recording 48 6.5.2 Centralized VRM recording 50 6.5.3 Decentralized VRM recording 52 6.5.4 Centralized NVR recording 53 6.5.5 Decentralized NVR recording 55 6.5.6 Pros and Cons of the different recording solutions 57 Index 58 - | V2 | 2011.07 Bosch IP Video Manual Bosch Sicherheitsssysteme GmbH Bosch IP Video Networks Introduction | en 5 1 Introduction This manual collects important information for different target groups on the requirements that Bosch IP Video products have on networks. -

Understanding the Interactions Between Unicast and Group Communications Sessions in Ad Hoc Networks
UNDERSTANDING THE INTERACTIONS BETWEEN UNICAST AND GROUP COMMUNICATIONS SESSIONS IN AD HOC NETWORKS Lap Kong Law, Srikanth V. Krishnamurthy and Michails Faloutsos '' Department of Computer Science & Engineering University of California, Riverside Riverside, California 92521 {lklaw,krish,michalis}@cs.ucr.edu Abstract In this paper, our objective is to study and understand the mutual effects be tween the group communication protocols and unicast sessions in mobile ad hoc networks. The motivation of this work is based on the fact that a realistic wire less networks would typically have to support different simultaneous network applications, many of which may be unicast but some of which may need broad cast or multicast. However, almost all of the prior work on evaluating protocols in ad hoc networks examine protocols in isolation. In this paper, we compare the interactions of broadcast/multicast and unicast protocols and understand the microscopic nature of the interactions. We find that unicast sessions are sig nificantly affected by the group communication sessions. In contrast, unicast sessions have less influence on the performance of group communications due to redundant packet transmissions provided by the latter. We believe that our study is a first step towards understanding such protocol interactions in ad hoc networks. 1. Introduction Most routing protocol evaluations assume Implicitly that only the protocol under consideration Is deployed In the network. However, ad hoc networks are likely to support many types of communication such as unicast, broadcast, and multicast at the same time. Although the performance evaluation of a protocol In Isolation can lend valuable Insights on Its behavior and performance, the protocol may have complex Interactions with other coexisting protocols. -

Design Guide For: Streaming
Crestron Electronics, Inc. Streaming Design Guide Crestron product development software is licensed to Crestron dealers and Crestron Service Providers (CSPs) under a limited non-exclusive, non transferable Software Development Tools License Agreement. Crestron product operating system software is licensed to Crestron dealers, CSPs, and end-users under a separate End-User License Agreement. Both of these Agreements can be found on the Crestron website at www.crestron.com/legal/software_license_agreement. The product warranty can be found at www.crestron.com/warranty. The specific patents that cover Crestron products are listed at patents.crestron.com. Crestron, the Crestron logo, Capture HD, Crestron Studio, DM, and DigitalMedia are trademarks or registered trademarks of Crestron Electronics, Inc. in the United States and/or other countries. HDMI and the HDMI logo are either trademarks or registered trademarks of HDMI Licensing LLC in the United States and/or other countries. Hulu is either a trademark or registered trademark of Hulu, LLC in the United States and/or other countries. Netflix is either a trademark or registered trademark of Netflix, Inc. in the United States and/or other countries. Wi-Fi is either a trademark or registered trademark of Wi-Fi Alliance in the United States and/or other countries. Other trademarks, registered trademarks, and trade names may be used in this document to refer to either the entities claiming the marks and names or their products. Crestron disclaims any proprietary interest in the marks and names of others. Crestron is not responsible for errors in typography or photography. This document was written by the Technical Publications department at Crestron. -

Unicast Routing Protocols (RIP, OSPF, and BGP)
Unicast Routing Protocols (RIP, OSPF, and BGP) Chapter 11 Routing Protocols Routing Protocol is combination of rules and procedures lets routers in internet inform each other of route changes Autonomous System (AS) is group of networks and routers under authority of single administration Intradomain routing is routing inside AS Handled by interior routing protocol Interdomain routing is routing between AS’s Handled by exterior routing protocol 2 Autonomous Systems 3 Routing Protocols 4 Distance Vector Routing Uses Bellman-Ford algorithm for creating routing table for routers in AS Each node shares its routing table with its immediate neighbors periodically and when there is a change 5 Bellman-Ford Algorithm 6 Distance Vector Routing 7 Distance Vector Routing 4 3 2 Net5 , 1Net4 , 1Net2 , 1 8 Count to Infinity -- Two-Node Instability 9 Solutions to Instability Defining Infinity Define 16 as infinity Split Horizon If node B reaches X via A, then B does not need to advertise to A its (B's) distance to X Split Horizon and Poison Reverse If node B reaches X via A, then B will advertise to A that its (B's) distance to X is infinity 10 Three-Node Instability 11 Routing Information Protocol (RIP) Intradomain routing protocol Based on distance vector routing Uses hop count as metric (cost) Infinite distance defined as 16 hops 12 Example of a domain using RIP 13 RIP Message Format Command: Request (1), Response (2) Version: 1 Family: TCP/IP (2) 14 Requests and Responses Request Message Response (Update) Message Solicited response: -

Main Theme Networks: Part II Circuit Switching, Packet Switching, the Network Layer
Data Communications & Networks Session 8 – Main Theme Networks: Part II Circuit Switching, Packet Switching, The Network Layer Dr. Jean-Claude Franchitti New York University Computer Science Department Courant Institute of Mathematical Sciences Adapted from course textbook resources Computer Networking: A Top-Down Approach, 5/E Copyright 1996-2013 J.F. Kurose and K.W. Ross, All Rights Reserved 1 Agenda 1 Session Overview 2 Networks Part 2 3 Summary and Conclusion 2 What is the class about? .Course description and syllabus: »http://www.nyu.edu/classes/jcf/csci-ga.2262-001/ »http://cs.nyu.edu/courses/Fall13/CSCI-GA.2262- 001/index.html .Textbooks: » Computer Networking: A Top-Down Approach (6th Edition) James F. Kurose, Keith W. Ross Addison Wesley ISBN-10: 0132856204, ISBN-13: 978-0132856201, 6th Edition (02/24/12) 3 Course Overview . Computer Networks and the Internet . Application Layer . Fundamental Data Structures: queues, ring buffers, finite state machines . Data Encoding and Transmission . Local Area Networks and Data Link Control . Wireless Communications . Packet Switching . OSI and Internet Protocol Architecture . Congestion Control and Flow Control Methods . Internet Protocols (IP, ARP, UDP, TCP) . Network (packet) Routing Algorithms (OSPF, Distance Vector) . IP Multicast . Sockets 4 Course Approach . Introduction to Basic Networking Concepts (Network Stack) . Origins of Naming, Addressing, and Routing (TCP, IP, DNS) . Physical Communication Layer . MAC Layer (Ethernet, Bridging) . Routing Protocols (Link State, Distance Vector) . Internet Routing (BGP, OSPF, Programmable Routers) . TCP Basics (Reliable/Unreliable) . Congestion Control . QoS, Fair Queuing, and Queuing Theory . Network Services – Multicast and Unicast . Extensions to Internet Architecture (NATs, IPv6, Proxies) . Network Hardware and Software (How to Build Networks, Routers) . -
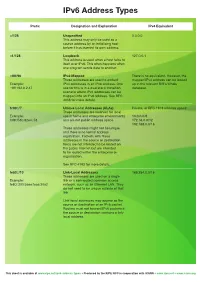
Ipv6 Address Types
IPv6 Address Types Prefix Designation and Explanation IPv4 Equivalent ::/128 Unspecified 0.0.0.0 This address may only be used as a source address by an initialising host before it has learned its own address. ::1/128 Loopback 127.0.0.1 This address is used when a host talks to itself over IPv6. This often happens when one program sends data to another. ::ffff/96 IPv4-Mapped There is no equivalent. However, the These addresses are used to embed mapped IPv4 address can be looked Example: IPv4 addresses in an IPv6 address. One up in the relevant RIR’s Whois ::ffff:192.0.2.47 use for this is in a dual stack transition database. scenario where IPv4 addresses can be mapped into an IPv6 address. See RFC 4038 for more details. fc00::/7 Unique Local Addresses (ULAs) Private, or RFC 1918 address space: These addresses are reserved for local Example: use in home and enterprise environments 10.0.0.0/8 fdf8:f53b:82e4::53 and are not public address space. 172.16.0.0/12 192.168.0.0/16 These addresses might not be unique, and there is no formal address registration. Packets with these addresses in the source or destination fields are not intended to be routed on the public Internet but are intended to be routed within the enterprise or organisation. See RFC 4193 for more details. fe80::/10 Link-Local Addresses 169.254.0.0/16 These addresses are used on a single Example: link or a non-routed common access fe80::200:5aee:feaa:20a2 network, such as an Ethernet LAN.