Formal Models and Verification of Memory Management in a Hypervisor Pauline Bolignano
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
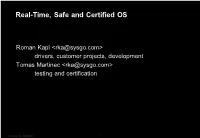
Real-Time, Safe and Certified OS
Real-Time, Safe and Certified OS Roman Kapl <[email protected]> drivers, customer projects, development Tomas Martinec <[email protected]> testing and certification © SYSGO AG · INTERNAL 1 Introduction • PikeOS – real-time, safety certified OS • Desktop and Server vs. • Embedded • Real-Time • Safety-Critical • Certified • Differences • Scheduling • Resource management • Features • Development © SYSGO AG · INTERNAL 2 Certification • Testing • Analysis • Lot of time • Even more paper • Required for safety-critical systems • Trains • Airplanes © SYSGO AG · INTERNAL 3 PikeOS • Embedded, real-time, certified OS • ~150 people (not just engineers) • Rail • Avionics • Space • This presentation is not about PikeOS specifically © SYSGO AG · INTERNAL 4 PikeOS technical • Microkernel • Inspired by L4 • Memory protection (MMU) • More complex than FreeRTOS • Virtualization hypervisor • X86, ARM, SPARC, PowerPC • Eclipse IDE for development © SYSGO AG · INTERNAL 5 Personalities • General • POSIX • Linux • Domain specific • ARINC653 • PikeOS native • Other • Ada, RT JAVA, AUTOSAR, ITRON, RTEMS © SYSGO AG · INTERNAL 6 PikeOS Architecture App. App. App. App. App. App. Volume Syste m Provider Partition PikeOS Para-Virtualized HW Virtualized File System (Native, POSIX, Guest OS PikeOS Native ARINC653, ...) Guest OS Linux, Android Linux, Android Device Driver User Space / Partitions Syste m PikeOS System Software ExtensionSyste m Extension PikeOS Microkernel Kernel Space / Hypervisor Architecture Platform Kernel Level Support Package Support Package Driver SoC / -

Sistemi Operativi Real-Time Marco Cesati Lezione R13 Sistemi Operativi Real-Time – II Schema Della Lezione
Sistemi operativi real-time Marco Cesati Lezione R13 Sistemi operativi real-time – II Schema della lezione Caratteristiche comuni VxWorks LynxOS Sistemi embedded e real-time QNX eCos Windows Linux come RTOS 15 gennaio 2013 Marco Cesati Dipartimento di Ingegneria Civile e Ingegneria Informatica Università degli Studi di Roma Tor Vergata SERT’13 R13.1 Sistemi operativi Di cosa parliamo in questa lezione? real-time Marco Cesati In questa lezione descriviamo brevemente alcuni dei più diffusi sistemi operativi real-time Schema della lezione Caratteristiche comuni VxWorks LynxOS 1 Caratteristiche comuni degli RTOS QNX 2 VxWorks eCos 3 LynxOS Windows Linux come RTOS 4 QNX Neutrino 5 eCos 6 Windows Embedded CE 7 Linux come RTOS SERT’13 R13.2 Sistemi operativi Caratteristiche comuni dei principali RTOS real-time Marco Cesati Corrispondenza agli standard: generalmente le API sono proprietarie, ma gli RTOS offrono anche compatibilità (compliancy) o conformità (conformancy) allo standard Real-Time POSIX Modularità e Scalabilità: il kernel ha una dimensione Schema della lezione Caratteristiche comuni (footprint) ridotta e le sue funzionalità sono configurabili VxWorks Dimensione del codice: spesso basati su microkernel LynxOS QNX Velocità e Efficienza: basso overhead per cambi di eCos contesto, latenza delle interruzioni e primitive di Windows sincronizzazione Linux come RTOS Porzioni di codice non interrompibile: generalmente molto corte e di durata predicibile Gestione delle interruzioni “separata”: interrupt handler corto e predicibile, ISR lunga -

Vmware Fusion 12 Vmware Fusion Pro 12 Using Vmware Fusion
Using VMware Fusion 8 SEP 2020 VMware Fusion 12 VMware Fusion Pro 12 Using VMware Fusion You can find the most up-to-date technical documentation on the VMware website at: https://docs.vmware.com/ VMware, Inc. 3401 Hillview Ave. Palo Alto, CA 94304 www.vmware.com © Copyright 2020 VMware, Inc. All rights reserved. Copyright and trademark information. VMware, Inc. 2 Contents Using VMware Fusion 9 1 Getting Started with Fusion 10 About VMware Fusion 10 About VMware Fusion Pro 11 System Requirements for Fusion 11 Install Fusion 12 Start Fusion 13 How-To Videos 13 Take Advantage of Fusion Online Resources 13 2 Understanding Fusion 15 Virtual Machines and What Fusion Can Do 15 What Is a Virtual Machine? 15 Fusion Capabilities 16 Supported Guest Operating Systems 16 Virtual Hardware Specifications 16 Navigating and Taking Action by Using the Fusion Interface 21 VMware Fusion Toolbar 21 Use the Fusion Toolbar to Access the Virtual-Machine Path 21 Default File Location of a Virtual Machine 22 Change the File Location of a Virtual Machine 22 Perform Actions on Your Virtual Machines from the Virtual Machine Library Window 23 Using the Home Pane to Create a Virtual Machine or Obtain One from Another Source 24 Using the Fusion Applications Menus 25 Using Different Views in the Fusion Interface 29 Resize the Virtual Machine Display to Fit 35 Using Multiple Displays 35 3 Configuring Fusion 37 Setting Fusion Preferences 37 Set General Preferences 37 Select a Keyboard and Mouse Profile 38 Set Key Mappings on the Keyboard and Mouse Preferences Pane 39 Set Mouse Shortcuts on the Keyboard and Mouse Preference Pane 40 Enable or Disable Mac Host Shortcuts on the Keyboard and Mouse Preference Pane 40 Enable Fusion Shortcuts on the Keyboard and Mouse Preference Pane 41 Set Fusion Display Resolution Preferences 41 VMware, Inc. -

Performance Study of Real-Time Operating Systems for Internet Of
IET Software Research Article ISSN 1751-8806 Performance study of real-time operating Received on 11th April 2017 Revised 13th December 2017 systems for internet of things devices Accepted on 13th January 2018 E-First on 16th February 2018 doi: 10.1049/iet-sen.2017.0048 www.ietdl.org Rafael Raymundo Belleza1 , Edison Pignaton de Freitas1 1Institute of Informatics, Federal University of Rio Grande do Sul, Av. Bento Gonçalves, 9500, CP 15064, Porto Alegre CEP: 91501-970, Brazil E-mail: [email protected] Abstract: The development of constrained devices for the internet of things (IoT) presents lots of challenges to software developers who build applications on top of these devices. Many applications in this domain have severe non-functional requirements related to timing properties, which are important concerns that have to be handled. By using real-time operating systems (RTOSs), developers have greater productivity, as they provide native support for real-time properties handling. Some of the key points in the software development for IoT in these constrained devices, like task synchronisation and network communications, are already solved by this provided real-time support. However, different RTOSs offer different degrees of support to the different demanded real-time properties. Observing this aspect, this study presents a set of benchmark tests on the selected open source and proprietary RTOSs focused on the IoT. The benchmark results show that there is no clear winner, as each RTOS performs well at least on some criteria, but general conclusions can be drawn on the suitability of each of them according to their performance evaluation in the obtained results. -

Improving the Reliability of Commodity Operating Systems
Improving the Reliability of Commodity Operating Systems MICHAEL M. SWIFT, BRIAN N. BERSHAD, and HENRY M. LEVY University of Washington Despite decades of research in extensible operating system technology, extensions such as device drivers remain a significant cause of system failures. In Windows XP, for example, drivers account for 85% of recently reported failures. This paper describes Nooks, a reliability subsystem that seeks to greatly enhance OS reliability by isolating the OS from driver failures. The Nooks approach is practical: rather than guaranteeing complete fault tolerance through a new (and incompatible) OS or driver architecture, our goal is to prevent the vast majority of driver-caused crashes with little or no change to existing driver and system code. Nooks isolates drivers within lightweight protection domains inside the kernel address space, where hardware and software prevent them from corrupting the kernel. Nooks also tracks a driver’s use of kernel resources to facilitate automatic clean-up during recovery. To prove the viability of our approach, we implemented Nooks in the Linux operating system and used it to fault-isolate several device drivers. Our results show that Nooks offers a substantial increase in the reliability of operating systems, catching and quickly recovering from many faults that would otherwise crash the system. Under a wide range and number of fault conditions, we show that Nooks recovers automatically from 99% of the faults that otherwise cause Linux to crash. While Nooks was designed for drivers, our techniques generalize to other kernel extensions. We demonstrate this by isolating a kernel-mode file system and an in-kernel Internet service. -

Performance Analysis of Selected Hypervisors (Virtual Machine Monitors - Vmms) Waldemar Graniszewski, Adam Arciszewski
INTL JOURNAL OF ELECTRONICS AND TELECOMMUNICATIONS, 2016, VOL. 62, NO. 3, PP. 231–236 Manuscript received August 12, 2016; revised September, 2016. DOI: 10.1515/eletel-2016-0031 Performance analysis of selected hypervisors (Virtual Machine Monitors - VMMs) Waldemar Graniszewski, Adam Arciszewski Abstract—Virtualization of operating systems and network results for CPU, NIC, kernel compilation time and storage infrastructure plays an important role in current IT projects. benchmarks’ tests are presented in Section IV. Finally, in With the number of services running on different hardware Section V, we draw some conclusions. resources it is easy to provide availability, security and efficiency using virtualizers. All virtualization vendors claim that their hypervisor (virtual machine monitor - VMM) is better than their II. BACKGROUND AND RELATED WORK competitors. In this paper we evaluate performance of different In this section we present some general background for solutions: proprietary software products (Hyper-V, ESXi, OVM, VirtualBox), and open source (Xen). We are using standard virtualisation technology (in Subsection II-A) and a short benchmark tools to compare efficiency of main hardware com- review of related work (in Subsection II-B). ponents, i.e. CPU (nbench), NIC (netperf), storage (Filebench), memory (ramspeed). Results of each tests are presented. A. Background Keywords—virtualisation, virtualmachines, benchmark, per- As mentioned earlier, in Section I, cloud computing and formance, hypervisor, virtual machine monitor, vmm services provided by data centers require robust software for their operation. With data center server consolidation, the I. INTRODUCTION portability of each solution plays an important role. In the N recent years the most popular IT projects have been last decade both proprietary software like VMware ESXi, Mi- I based on cloud computing. -

Security Target Pikeos Separation Kernel V4.2.2
Security Target PikeOS Separation Kernel v4.2.2 Document ID Revision DOORS Baseline Date State 00101-8000-ST 20.6 N.A. 2018-10-10 App Author: Dominic Eschweiler SYSGO AG Am Pfaffenstein 14, D-55270 Klein-Winternheim Notice: The contents of this document are proprietary to SYSGO AG and shall not be disclosed, disseminated, copied, or used except for purposes expressly authorized in writing by SYSGO AG. Doc. ID: 00101-8000-ST Revision: 20.6 This page intentionally left blank Copyright 2018 Page 2 of 47 All rights reserved. SYSGO AG Doc. ID: 00101-8000-ST Revision: 20.6 This page intentionally left blank Copyright 2018 Page 3 of 47 All rights reserved. SYSGO AG Doc. ID: 00101-8000-ST Revision: 20.6 Table of Contents 1 Introduction .................................................................................................................... 6 1.1 Purpose of this Document ........................................................................................... 6 1.2 Document References ................................................................................................ 6 1.2.1 Applicable Documents......................................................................................... 6 1.2.2 Referenced Documents ....................................................................................... 6 1.3 Abbreviations and Acronyms ....................................................................................... 6 1.4 Terms and Definitions................................................................................................ -

Information Guide for Managing Vmware Esxi : Vmware, Inc
INFORMATION GUIDE Managing VMware ESXi VMWARE INFORMATION GUIDE Table of Contents Introduction ............................................................................................................ 3 Deployment ........................................................................................................... 3 Large-Scale Standardized Deployment ............................................................. 4 Interactive and Scripted Management ................................................................. 5 VI Client .............................................................................................................. 5 Remote Command Line Interfaces .................................................................... 6 File Management ............................................................................................... 7 Remote Command Line Interface and ESX 3 ..................................................... 8 Third-Party Management Applications ................................................................. 8 Common Information Model ............................................................................. 8 VI API .................................................................................................................. 8 SNMP .................................................................................................................. 9 System Image Design ............................................................................................. 10 Patching and Upgrading -

A Comparison of Virtual Lab Solutions for Online Cyber Security Education
Communications of the IIMA Volume 12 Issue 4 Article 6 2012 A Comparison of Virtual Lab Solutions for Online Cyber Security Education Joon Son California State University, San Bernardino Chinedum Irrechukwu University of Maryland University College Patrick Fitzgibbons University of Maryland University College Follow this and additional works at: https://scholarworks.lib.csusb.edu/ciima Recommended Citation Son, Joon; Irrechukwu, Chinedum; and Fitzgibbons, Patrick (2012) "A Comparison of Virtual Lab Solutions for Online Cyber Security Education ," Communications of the IIMA: Vol. 12 : Iss. 4 , Article 6. Available at: https://scholarworks.lib.csusb.edu/ciima/vol12/iss4/6 This Article is brought to you for free and open access by CSUSB ScholarWorks. It has been accepted for inclusion in Communications of the IIMA by an authorized editor of CSUSB ScholarWorks. For more information, please contact [email protected]. Virtual Lab for Online Cyber Security Education Son, Irrechukwu & Fitzgibbons Virtual Lab for Online Cyber Security Education Joon Son California State University, San Bernardino [email protected] Chinedum Irrechukwu University of Maryland University College (UMUC) [email protected] Patrick Fitzgibbons University of Maryland University College (UMUC) [email protected] ABSTRACT In this paper the authors describe their experience of designing a virtual lab architecture capable of providing hundreds of students with a hands on learning experience in support of an online educational setting. The authors discuss alternative approaches of designing a virtual lab and address the criteria in selecting the optimal deployment method. The authors conclude that virtualization offers a significant instructional advantage in delivering a cost effective and flexible hands on learning experience. -

Mos - Virtualization
MOS - VIRTUALIZATION Tobias Stumpf, Marcus H¨ahnel WS 2017/18 Goals Give you an overview about: • virtualization and virtual machines in general, • hardware virtualization on x86, • our research regarding virtualization. We will not discuss: • lots and lots of details, • language runtimes, • how to use XEN/KVM/. MOS - Virtualization slide 3 What is Virtualization? Outline What is Virtualization? Very Short History Virtualization on x86 Example: L4Linux Example: NOVA Example: Karma VMM MOS - Virtualization slide 4 What is Virtualization? Starting Point You want to write a new operating system that is • secure, • trustworthy, • small, • fast, • fancy. but . MOS - Virtualization slide 5 What is Virtualization? Commodity Applications Users expect to run all the software they are used to (\legacy"): • browsers, • Word, • iTunes, • certified business applications, • new (Windows/DirectX) and ancient (DOS) games. Porting or rewriting all is infeasible! MOS - Virtualization slide 6 What is Virtualization? One Solution: Virtualization \By virtualizing a commodity OS [...] we gain support for legacy applications, and devices we don't want to write drivers for." \All this allows the research community to finally escape the straitjacket of POSIX or Windows compatibility [...]" Roscoe:2007:HV:1361397.1361401 MOS - Virtualization slide 7 What is Virtualization? Virtualization virtual existing in essence or effect though not in actual fact http://wordnetweb.princeton.edu \All problems in computer science can be solved by another level of indirection." David Wheeler MOS - Virtualization slide 8 What is Virtualization? Emulation Suppose you develop for a system G (guest, e.g. an ARM-based phone) on your workstation H (host, e.g., an x86 PC). An emulator for G running on H precisely emulates G's • CPU, • memory subsystem, and • I/O devices. -

Us 2019 / 0319868 A1
US 20190319868A1 ( 19) United States (12 ) Patent Application Publication ( 10) Pub . No. : US 2019 /0319868 A1 Svennebring et al. ( 43 ) Pub . Date : Oct. 17 , 2019 ( 54 ) LINK PERFORMANCE PREDICTION (52 ) U . S . CI. TECHNOLOGIES CPC .. .. H04L 43/ 0882 (2013 . 01 ); H04W 24 /08 ( 2013 . 01 ) (71 ) Applicant : Intel Corporation , Santa Clara , CA (57 ) ABSTRACT (US ) Various systems and methods for determining and commu nicating Link Performance Predictions (LPPs ), such as in ( 72 ) Inventors : Jonas Svennebring , Sollentuna (SE ) ; connection with management of radio communication links, Antony Vance Jeyaraj, Bengaluru ( IN ) are discussed herein . The LPPs are predictions of future network behaviors /metrics ( e . g . , bandwidth , latency , capac (21 ) Appl . No. : 16 /452 , 352 ity , coverage holes , etc . ) . The LPPs are communicated to applications and /or network infrastructure, which allows the applications/ infrastructure to make operational decisions for ( 22 ) Filed : Jun . 25 , 2019 improved signaling / link resource utilization . In embodi ments , the link performance analysis is divided into multiple layers that determine their own link performance metrics, Publication Classification which are then fused together to make an LPP. Each layer (51 ) Int . Cl. runs different algorithms, and provides respective results to H04L 12 / 26 ( 2006 .01 ) an LPP layer /engine that fuses the results together to obtain H04W 24 / 08 (2006 .01 ) the LPP . Other embodiments are described and / or claimed . 700 Spatio - Temporal History Data Tx1 : C1 TIDE _ 1, DE _ 2 . .. Txt : C2 T2 DE _ 1 , DE _ 2 , . .. win Txs : C3 122 T : DE _ 1, DE _ 2 , .. TN DE _ 1 , DE _ 2 .. TxN : CN CELL LOAD MODEL 710 Real- Time Data 744 704 Patent Application Publication Oct. -

Guest OS Compatibility Guide
Guest OS Compatibility Guide Guest OS Compatibility Guide Last Updated: September 29, 2021 For more information go to vmware.com. Introduction VMware provides the widest virtualization support for guest operating systems in the industry to enable your environments and maximize your investments. The VMware Compatibility Guide shows the certification status of operating system releases for use as a Guest OS by the following VMware products: • VMware ESXi/ESX Server 3.0 and later • VMware Workstation 6.0 and later • VMware Fusion 2.0 and later • VMware ACE 2.0 and later • VMware Server 2.0 and later VMware Certification and Support Levels VMware product support for operating system releases can vary depending upon the specific VMware product release or update and can also be subject to: • Installation of specific patches to VMware products • Installation of specific operating system patches • Adherence to guidance and recommendations that are documented in knowledge base articles VMware attempts to provide timely support for new operating system update releases and where possible, certification of new update releases will be added to existing VMware product releases in the VMware Compatibility Guide based upon the results of compatibility testing. Tech Preview Operating system releases that are shown with the Tech Preview level of support are planned for future support by the VMware product but are not certified for use as a Guest OS for one or more of the of the following reasons: • The operating system vendor has not announced the general availability of the OS release. • Not all blocking issues have been resolved by the operating system vendor.