Python Sebagai Alat Web Server Pengembangan Aplikasi Sheetal Taneja 1, Pratibha R. Gupta 2 Sheetal Taneja 1, Pratibha R. Gupta 2
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Build It with Nitrogen the Fast-Off-The-Block Erlang Web Framework
Build it with Nitrogen The fast-off-the-block Erlang web framework Lloyd R. Prentice & Jesse Gumm dedicated to: Laurie, love of my life— Lloyd Jackie, my best half — Jesse and to: Rusty Klophaus and other giants of Open Source— LRP & JG Contents I. Frying Pan to Fire5 1. You want me to build what?7 2. Enter the lion’s den9 2.1. The big picture........................ 10 2.2. Install Nitrogen........................ 11 2.3. Lay of the land........................ 13 II. Projects 19 3. nitroBoard I 21 3.1. Plan of attack......................... 21 3.2. Create a new project..................... 23 3.3. Prototype welcome page................... 27 3.4. Anatomy of a page...................... 30 3.5. Anatomy of a route...................... 33 3.6. Anatomy of a template.................... 34 3.7. Elements............................ 35 3.8. Actions............................. 38 3.9. Triggers and Targets..................... 39 3.10. Enough theory........................ 40 i 3.11. Visitors............................ 44 3.12. Styling............................. 64 3.13. Debugging........................... 66 3.14. What you’ve learned..................... 66 3.15. Think and do......................... 68 4. nitroBoard II 69 4.1. Plan of attack......................... 69 4.2. Associates........................... 70 4.3. I am in/I am out....................... 78 4.4. Styling............................. 81 4.5. What you’ve learned..................... 82 4.6. Think and do......................... 82 5. A Simple Login System 83 5.1. Getting Started........................ 83 5.2. Dependencies......................... 84 5.2.1. Rebar Dependency: erlpass ............. 84 5.3. The index page........................ 85 5.4. Creating an account..................... 87 5.4.1. db_login module................... 89 5.5. The login form........................ 91 5.5.1. -

Making Story from System Logs with Elastic Stack
SANOG36 18 - 21 January, 2021 Making story from system logs with stack [email protected] https://imtiazrahman.com https://github.com/imtiazrahman Logs syslog Audit SNMP NETFLOW http METRIC DNS ids What is Elastic Stack ? Store, Analyze Ingest User Interface a full-text based, distributed NoSQL database. Written in Java, built on Apache Lucene Commonly used for log analytics, full-text search, security intelligence, business analytics, and operational intelligence use cases. Use REST API (GET, PUT, POST, and DELETE ) for storing and searching data Data is stored as documents (rows in relational database) Data is separated into fields (columns in relational database) Relational Database Elasticsearch Database Index Table Type Row/Record Document Column Name Field Terminology Cluster: A cluster consists of one or more nodes which share the same cluster name. Node: A node is a running instance of elasticsearch which belongs to a cluster. Terminology Index: Collection of documents Shard: An index is split into elements known as shards that are distributed across multiple nodes. There are two types of shard, Primary and replica. By default elasticsearch creates 1 primary shard and 1 replica shard for each index. Terminology Shard 1 Replica 1 Replica 2 Shard 2 Node 1 Node 2 cluster Terminology Documents { • Indices hold documents in "_index": "netflow-2020.10.08", "_type": "_doc", serialized JSON objects "_id": "ZwkiB3UBULotwSOX3Bdb", "_version": 1, • 1 document = 1 log entry "_score": null, "_source": { • Contains "field : value" pairs -

Learning Javascript Design Patterns
Learning JavaScript Design Patterns Addy Osmani Beijing • Cambridge • Farnham • Köln • Sebastopol • Tokyo Learning JavaScript Design Patterns by Addy Osmani Copyright © 2012 Addy Osmani. All rights reserved. Revision History for the : 2012-05-01 Early release revision 1 See http://oreilly.com/catalog/errata.csp?isbn=9781449331818 for release details. ISBN: 978-1-449-33181-8 1335906805 Table of Contents Preface ..................................................................... ix 1. Introduction ........................................................... 1 2. What is a Pattern? ...................................................... 3 We already use patterns everyday 4 3. 'Pattern'-ity Testing, Proto-Patterns & The Rule Of Three ...................... 7 4. The Structure Of A Design Pattern ......................................... 9 5. Writing Design Patterns ................................................. 11 6. Anti-Patterns ......................................................... 13 7. Categories Of Design Pattern ............................................ 15 Creational Design Patterns 15 Structural Design Patterns 16 Behavioral Design Patterns 16 8. Design Pattern Categorization ........................................... 17 A brief note on classes 17 9. JavaScript Design Patterns .............................................. 21 The Creational Pattern 22 The Constructor Pattern 23 Basic Constructors 23 Constructors With Prototypes 24 The Singleton Pattern 24 The Module Pattern 27 iii Modules 27 Object Literals 27 The Module Pattern -

Zope Documentation Release 5.3
Zope Documentation Release 5.3 The Zope developer community Jul 31, 2021 Contents 1 What’s new in Zope 3 1.1 What’s new in Zope 5..........................................4 1.2 What’s new in Zope 4..........................................4 2 Installing Zope 11 2.1 Prerequisites............................................... 11 2.2 Installing Zope with zc.buildout .................................. 12 2.3 Installing Zope with pip ........................................ 13 2.4 Building the documentation with Sphinx ............................... 14 3 Configuring and Running Zope 15 3.1 Creating a Zope instance......................................... 16 3.2 Filesystem Permissions......................................... 17 3.3 Configuring Zope............................................. 17 3.4 Running Zope.............................................. 18 3.5 Running Zope (plone.recipe.zope2instance install)........................... 20 3.6 Logging In To Zope........................................... 21 3.7 Special access user accounts....................................... 22 3.8 Troubleshooting............................................. 22 3.9 Using alternative WSGI server software................................. 22 3.10 Debugging Zope applications under WSGI............................... 26 3.11 Zope configuration reference....................................... 27 4 Migrating between Zope versions 37 4.1 From Zope 2 to Zope 4 or 5....................................... 37 4.2 Migration from Zope 4 to Zope 5.0.................................. -

ELK: a Log Files Management Framework
ELK: a log files management framework Giovanni Bechis <[email protected]> LinuxCon Europe 2016 About Me I sys admin and developer @SNB I OpenBSD developer I Open Source developer in several other projects searching through log files, the old way $ man 1 pflogsumm $ grep [email protected] /var/log/maillog | awk '{print $1 "-" $2 "-" $3;}' $ grep -e 'from=.*@gmail\.com' /var/log/maillog | grep "550" \ | awk {'print $1 "-" $2 "-" $3 " " $7 " " $10 " " $11 " " $13;}' $ vi logparser.sh $ git clone https://github.com/random/parser_that_should_work $ man 1 perltoc $ man 1 python searching through log files, the old way $ cssh -a 'mylogparser.py' host1 host2 host3 host4 | tee -a /tmp/parsedlogs.txt $ man syslogd(8) searching through log files, the new way ELK open source components I Beats: collect, parse and ship I Logstash: collect, enrich and transport data I Elasticsearch: search and analyze data in real time I Kibana: explore and visualize your data ELK closed source components I Watcher: alerting for Elasticsearch I Shield: security for Elasticsearch I Marvel: monitor Elasticsearch I Graph: analyze relationships Elasticsearch I open source search engine based on lucene library I nosql database (document oriented) I queries are based on http/json I APIs for lot of common languages, (or you can write your own framework, is just plain http and json) Elasticsearch: security I not available in open source version, you need Shield I Elasticsearch should not be exposed on the wild, use firewalling to protect your instances I manage security on your -
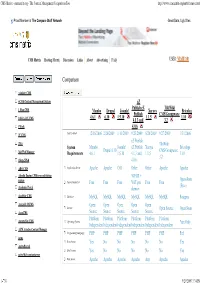
CMS Matrix - Cmsmatrix.Org - the Content Management Comparison Tool
CMS Matrix - cmsmatrix.org - The Content Management Comparison Tool http://www.cmsmatrix.org/matrix/cms-matrix Proud Member of The Compare Stuff Network Great Data, Ugly Sites CMS Matrix Hosting Matrix Discussion Links About Advertising FAQ USER: VISITOR Compare Search Return to Matrix Comparison <sitekit> CMS +CMS Content Management System eZ Publish eZ TikiWiki 1 Man CMS Mambo Drupal Joomla! Xaraya Bricolage Publish CMS/Groupware 4.6.1 6.10 1.5.10 1.1.5 1.10 1024 AJAX CMS 4.1.3 and 3.2 1Work 4.0.6 2F CMS Last Updated 12/16/2006 2/26/2009 1/11/2009 9/23/2009 8/20/2009 9/27/2009 1/31/2006 eZ Publish 2flex TikiWiki System Mambo Joomla! eZ Publish Xaraya Bricolage Drupal 6.10 CMS/Groupware 360 Web Manager Requirements 4.6.1 1.5.10 4.1.3 and 1.1.5 1.10 3.2 4Steps2Web 4.0.6 ABO.CMS Application Server Apache Apache CGI Other Other Apache Apache Absolut Engine CMS/news publishing 30EUR + system Open-Source Approximate Cost Free Free Free VAT per Free Free (Free) Academic Portal domain AccelSite CMS Database MySQL MySQL MySQL MySQL MySQL MySQL Postgres Accessify WCMS Open Open Open Open Open License Open Source Open Source AccuCMS Source Source Source Source Source Platform Platform Platform Platform Platform Platform Accura Site CMS Operating System *nix Only Independent Independent Independent Independent Independent Independent ACM Ariadne Content Manager Programming Language PHP PHP PHP PHP PHP PHP Perl acms Root Access Yes No No No No No Yes ActivePortail Shell Access Yes No No No No No Yes activeWeb contentserver Web Server Apache Apache -

A Framework for Ontology-Based Library Data Generation, Access and Exploitation
Universidad Politécnica de Madrid Departamento de Inteligencia Artificial DOCTORADO EN INTELIGENCIA ARTIFICIAL A framework for ontology-based library data generation, access and exploitation Doctoral Dissertation of: Daniel Vila-Suero Advisors: Prof. Asunción Gómez-Pérez Dr. Jorge Gracia 2 i To Adelina, Gustavo, Pablo and Amélie Madrid, July 2016 ii Abstract Historically, libraries have been responsible for storing, preserving, cata- loguing and making available to the public large collections of information re- sources. In order to classify and organize these collections, the library commu- nity has developed several standards for the production, storage and communica- tion of data describing different aspects of library knowledge assets. However, as we will argue in this thesis, most of the current practices and standards available are limited in their ability to integrate library data within the largest information network ever created: the World Wide Web (WWW). This thesis aims at providing theoretical foundations and technical solutions to tackle some of the challenges in bridging the gap between these two areas: library science and technologies, and the Web of Data. The investigation of these aspects has been tackled with a combination of theoretical, technological and empirical approaches. Moreover, the research presented in this thesis has been largely applied and deployed to sustain a large online data service of the National Library of Spain: datos.bne.es. Specifically, this thesis proposes and eval- uates several constructs, languages, models and methods with the objective of transforming and publishing library catalogue data using semantic technologies and ontologies. In this thesis, we introduce marimba-framework, an ontology- based library data framework, that encompasses these constructs, languages, mod- els and methods. -

Flemish Public Libraries – Digital Library Systems Architecture Study 10-Dec-13
Flemish Public Libraries – Digital Library Systems Architecture Study 10-Dec-13 Flemish Public Libraries - Digital Library Systems Architecture Study Last update: 27 NOV 2013 Researchers: Jean-François Declercq Rosemie Callewaert François Vermaut Ordered by: Bibnet vzw Vereniging van de Vlaamse Provincies Vlaamse Gemeenschapscommissie van het Brussels Hoofdstedelijk Gewest 2013-11-27-DigitalLibrarySystemArchitecture p. 1 / 163 Flemish Public Libraries – Digital Library Systems Architecture Study 10-Dec-13 Table of contents 1 Introduction ............................................................................................................................... 6 1.1 Definition of a Digital Library ............................................................................................. 6 1.2 Study Objectives ................................................................................................................ 7 1.3 Study Approach ................................................................................................................. 7 1.4 Study timeline .................................................................................................................... 8 1.5 Study Steering Committee ................................................................................................. 9 2 ICT Systems Architecture Concepts ......................................................................................... 10 2.1 Enterprise Architecture Model ....................................................................................... -

Download Slide (PDF Document)
When Django is too bloated Specialized Web-Applications with Werkzeug EuroPython 2017 – Rimini, Italy Niklas Meinzer @NiklasMM Gotthard Base Tunnel Photographer: Patrick Neumann Python is amazing for web developers! ● Bottle ● BlueBream ● CherryPy ● CubicWeb ● Grok ● Nagare ● Pyjs ● Pylons ● TACTIC ● Tornado ● TurboGears ● web2py ● Webware ● Zope 2 Why would I want to use less? ● Learn how stuff works Why would I want to use less? ● Avoid over-engineering – Wastes time and resources – Makes updates harder – It’s a security risk. Why would I want to use less? ● You want to do something very specific ● Plan, manage and document chemotherapy treatments ● Built with modern web technology ● Used by hospitals in three European countries Patient Data Lab Data HL7 REST Pharmacy System Database Printers Werkzeug = German for “tool” ● Developed by pocoo team @ pocoo.org – Flask, Sphinx, Jinja2 ● A “WSGI utility” ● Very lightweight ● No ORM, No templating engine, etc ● The basis of Flask and others Werkzeug Features Overview ● WSGI – WSGI 1.0 compatible, WSGI Helpers ● Wrapping of requests and responses ● HTTP Utilities – Header processing, form data parsing, cookies ● Unicode support ● URL routing system ● Testing tools – Testclient, Environment builder ● Interactive Debugger in the Browser A simple Application A simple Application URL Routing Middlewares ● Separate parts of the Application as wsgi apps ● Combine as needed Request Static files DB Part of Application conn with DB access User Dispatcher auth Part of Application without DB access Response HTTP Utilities ● Work with HTTP dates ● Read and dump cookies ● Parse form data Using the test client Using the test client - pytest fixtures Using the test client - pytest fixtures Interactive debugger in the Browser Endless possibilities ● Connect to a database with SQLalchemy ● Use Jinja2 to render documents ● Use Celery to schedule asynchronous tasks ● Talk to 3rd party APIs with requests ● Make syscalls ● Remote control a robot to perform tasks at home Thank you! @NiklasMM NiklasMM Photographer: Patrick Neumann. -

Cherrypy Documentation Release 3.3.0
CherryPy Documentation Release 3.3.0 CherryPy Team August 05, 2016 Contents 1 What is CherryPy? 1 2 What CherryPy is NOT? 3 3 Contents 5 3.1 Why choose CherryPy?.........................................5 3.2 Installation................................................6 3.3 CherryPy License (BSD).........................................8 4 Tutorial 9 4.1 What is this tutorial about?........................................9 4.2 Start the Tutorial.............................................9 5 Programmer’s Guide 35 5.1 Features.................................................. 35 5.2 HTTP details............................................... 66 6 Deployment Guide 79 6.1 Applications............................................... 79 6.2 Servers.................................................. 79 6.3 Environment............................................... 87 7 Reference Manual 91 7.1 cherrypy._cpchecker ....................................... 91 7.2 cherrypy._cpconfig ........................................ 92 7.3 cherrypy._cpdispatch – Mapping URI’s to handlers...................... 94 7.4 cherrypy._cprequest ....................................... 96 7.5 cherrypy._cpserver ........................................ 101 7.6 cherrypy._cptools ........................................ 103 7.7 cherrypy._cptree ......................................... 105 7.8 cherrypy._cpwsgi ......................................... 107 7.9 cherrypy ................................................ 108 7.10 cherrypy.lib............................................... -

S'abonner Sans S'enchaîner
N° 889 - Du 21 juin au 10 juillet 2018 EN INDE, LES ALGORITHMES LIBÈRENT LA JEUNESSE DES MARIAGES FORCÉS 3,90€ À LA DÉCOUVERTE DES ZONES URBAINES LE MAGAZINE DU HIGH-TECH INTERDITES 0 € S’ABONNER SANS S’ENCHAÎNER NOTRE SÉLECTION DES MEILLEURES OFFRES Belgique : 4,50 € > Suisse : 6,30 FS > Luxembourg : 4,50 € > Guyane : 7,80 € > DOM Avion : 5,10 € > TOM Avion : 1 300 CFP > Maroc : 39 DH > Canada : 7,25 $CAD > Tunisie : 3,20 TND > Portugal : 4,7 : 3,20 TND > Portugal > : 5,10 € Tunisie : 7,25 $CAD > Canada : : 39 DH : 7,80 Avion 4,50 € > DOM : 1 € > Guyane > Maroc 300 CFP Belgique : 4,50 : 6,30 FS > Luxembourg € > Suisse Avion > TOM ÉDITO AMAURY MESTRE DE LAROQUE Rédacteur en chef Rien dans les poches, tout dans la tête e Larousse se contente de cette définition. suggestions sont moins drastiques, mais contenteront Désencombrement : action de se débarras- tout le monde, même les victimes de syllo gomanie, ce ser de ce qui encombre. Pourtant, ce nom trouble consistant à accumuler des objets sans les uti- masculin désigne aussi un mouvement liser. En France, 100 millions de téléphones dorment Ld’individus lassés par l’hyperconsomma- ainsi dans les tiroirs (lire p. 9). Mais revenons à notre tion. Une gangrène symbolisée par les fast- remède miracle. Pour vivre l’esprit léger, mais bien foods et leurs menus XL (grande frite, grande boisson, plein, passez donc aux abonnements sans engagement grand cholestérol), voire XXL (idem, mais pour papa), (lire p. 32). À vous le plaisir de l’écoute de millions de ou par ces enseignes de vêtements bradés et pen- chansons, ou celui du doux endormissement sés pour s’étioler après deux lavages. -

Pipenightdreams Osgcal-Doc Mumudvb Mpg123-Alsa Tbb
pipenightdreams osgcal-doc mumudvb mpg123-alsa tbb-examples libgammu4-dbg gcc-4.1-doc snort-rules-default davical cutmp3 libevolution5.0-cil aspell-am python-gobject-doc openoffice.org-l10n-mn libc6-xen xserver-xorg trophy-data t38modem pioneers-console libnb-platform10-java libgtkglext1-ruby libboost-wave1.39-dev drgenius bfbtester libchromexvmcpro1 isdnutils-xtools ubuntuone-client openoffice.org2-math openoffice.org-l10n-lt lsb-cxx-ia32 kdeartwork-emoticons-kde4 wmpuzzle trafshow python-plplot lx-gdb link-monitor-applet libscm-dev liblog-agent-logger-perl libccrtp-doc libclass-throwable-perl kde-i18n-csb jack-jconv hamradio-menus coinor-libvol-doc msx-emulator bitbake nabi language-pack-gnome-zh libpaperg popularity-contest xracer-tools xfont-nexus opendrim-lmp-baseserver libvorbisfile-ruby liblinebreak-doc libgfcui-2.0-0c2a-dbg libblacs-mpi-dev dict-freedict-spa-eng blender-ogrexml aspell-da x11-apps openoffice.org-l10n-lv openoffice.org-l10n-nl pnmtopng libodbcinstq1 libhsqldb-java-doc libmono-addins-gui0.2-cil sg3-utils linux-backports-modules-alsa-2.6.31-19-generic yorick-yeti-gsl python-pymssql plasma-widget-cpuload mcpp gpsim-lcd cl-csv libhtml-clean-perl asterisk-dbg apt-dater-dbg libgnome-mag1-dev language-pack-gnome-yo python-crypto svn-autoreleasedeb sugar-terminal-activity mii-diag maria-doc libplexus-component-api-java-doc libhugs-hgl-bundled libchipcard-libgwenhywfar47-plugins libghc6-random-dev freefem3d ezmlm cakephp-scripts aspell-ar ara-byte not+sparc openoffice.org-l10n-nn linux-backports-modules-karmic-generic-pae