The Bird and the Fish: Motion Field-Based Frame Interpolation in the Context of a Story
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tvorba Interaktivního Animovaného Příběhu
Středoškolská technika 2014 Setkání a prezentace prací středoškolských studentů na ČVUT Tvorba interaktivního animovaného příběhu Sami Salama Střední průmyslová škola na Proseku Novoborská 2, 190 00 Praha 9 1 Obsah 1 Obsah .................................................................................................................. 1 2 2D grafika (základní pojmy) ................................................................................. 3 2.1 Základní vysvětlení pojmu (počítačová) 2D grafika ....................................... 3 2.2 Rozdíl - 2D vs. 3D grafika .............................................................................. 3 2.3 Vektorová grafika ........................................................................................... 4 2.4 Rastrová grafika ............................................................................................ 6 2.5 Výhody a nevýhody rastrové grafiky .............................................................. 7 2.6 Rozlišení ........................................................................................................ 7 2.7 Barevná hloubka............................................................................................ 8 2.8 Základní grafické formáty .............................................................................. 8 2.9 Druhy komprese dat ...................................................................................... 9 2.10 Barevný model .......................................................................................... -

Kristina Reed Joins the Madison Square Garden Company As Senior Vice President, Creative Development and Strategy
Kristina Reed Joins the Madison Square Garden Company as Senior Vice President, Creative Development and Strategy July 22, 2019 NEW YORK, July 22, 2019 (GLOBE NEWSWIRE) -- The Madison Square Garden Company (NYSE:MSG) today announced that Academy Award- winning producer and creator, Kristina Reed, has joined MSG as Senior Vice President, Creative Development and Strategy. In this newly-created position, Ms. Reed will drive the development of creative content for the Company’s state-of-the-art MSG Sphere venues, which will utilize cutting-edge, immersive technology and compelling, multi-sensory storytelling to revolutionize the entertainment experience. Kristina Reed Joins The Madison Square Garden Company As Senior Vice President, Creative Development And Strategy Ms. Reed will be responsible for developing and implementing a slate of content for MSG Sphere venues, from conception to execution. She will work closely with internal and external teams to identify, evaluate and oversee creative development prospects; greenlight content to production; and establish and develop a sustainable digital pipeline for content delivery. Ms. Reed will be charged with developing these projects for both MSG Sphere, as well as other commercial clients. MSG anticipates that the first MSG Sphere, which is currently under construction in Las Vegas, will be completed during calendar year 2021, followed by the second MSG Sphere in London, which is expected approximately a year later, pending necessary approvals. Ms. Reed will report to Jennifer Vogt, President, Creative Content and Production, who recently joined MSG to oversee MSG’s overall content strategy and development for MSG Sphere and other production assets. Ms. Vogt joined MSG from Walt Disney Imagineering after successfully spearheading show design and production for Star Wars, “Galaxy’s Edge,” Disney’s largest single-themed land expansion in its history. -

Wmc Investigation: 10-Year Analysis of Gender & Oscar
WMC INVESTIGATION: 10-YEAR ANALYSIS OF GENDER & OSCAR NOMINATIONS womensmediacenter.com @womensmediacntr WOMEN’S MEDIA CENTER ABOUT THE WOMEN’S MEDIA CENTER In 2005, Jane Fonda, Robin Morgan, and Gloria Steinem founded the Women’s Media Center (WMC), a progressive, nonpartisan, nonproft organization endeav- oring to raise the visibility, viability, and decision-making power of women and girls in media and thereby ensuring that their stories get told and their voices are heard. To reach those necessary goals, we strategically use an array of interconnected channels and platforms to transform not only the media landscape but also a cul- ture in which women’s and girls’ voices, stories, experiences, and images are nei- ther suffciently amplifed nor placed on par with the voices, stories, experiences, and images of men and boys. Our strategic tools include monitoring the media; commissioning and conducting research; and undertaking other special initiatives to spotlight gender and racial bias in news coverage, entertainment flm and television, social media, and other key sectors. Our publications include the book “Unspinning the Spin: The Women’s Media Center Guide to Fair and Accurate Language”; “The Women’s Media Center’s Media Guide to Gender Neutral Coverage of Women Candidates + Politicians”; “The Women’s Media Center Media Guide to Covering Reproductive Issues”; “WMC Media Watch: The Gender Gap in Coverage of Reproductive Issues”; “Writing Rape: How U.S. Media Cover Campus Rape and Sexual Assault”; “WMC Investigation: 10-Year Review of Gender & Emmy Nominations”; and the Women’s Media Center’s annual WMC Status of Women in the U.S. -

Utah's Science, Technology, Talent and Innovation
Preparing for the Future: Utah’s Science, Technology, Talent and Innovation Plan Prepared for: Governor’s Office of Economic Development Utah System of Higher Education Prepared by: Battelle Technology Partnership Practice Spring 2012 Battelle does not engage in research for advertising, sales promotion, or endorsement of our clients’ interests including raising investment capital or recommending investments decisions, or other publicity purposes, or for any use in litigation. Battelle endeavors at all times to produce work of the highest quality, consistent with our contract commitments. However, because of the research and/or experimental nature of this work the client undertakes the sole responsibility for the consequence of any use or misuse of, or inability to use, any information, apparatus, process or result obtained from Battelle, and Battelle, its employees, officers, or Trustees have no legal liability for the accuracy, adequacy, or efficacy thereof. Contents Executive Summary ....................................................................................................... 1 Key Findings on Utah’s Technology‐based Industry Clusters Performance and Linkages with Core Technology Competencies Found in Utah ................................. 2 Recommended Strategic Initiatives to Realize the Full Potential of Utah’s Innovation Economy ................................................................................................ 10 Knowledge Initiative – Encourage Greater Industry University Collaboration ........ 11 Capital -
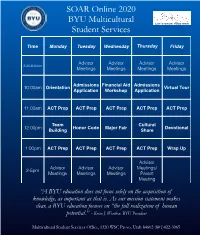
SOAR Online 2020 BYU Multicultural Student Services
SOAR Online 2020 Y BYU Multicultural Let’s grow together Student Services Time Monday Tuesday Wednesday Thursday Friday Advisor Advisor Advisor Advisor 8:30-9:30am Meetings Meetings Meetings Meetings Admissions Financial Aid Admissions 10:00am Orientation Virtual Tour Application Workshop Application 11:00am ACT Prep ACT Prep ACT Prep ACT Prep ACT Prep Team Cultural 12:00pm Honor Code Major Fair Devotional Building Share 1:00pm ACT Prep ACT Prep ACT Prep ACT Prep Wrap Up Advisor Advisor Advisor Advisor Meetings/ 2-5pm Meetings Meetings Meetings Parent Meeting “A BYU education does not focus solely on the acquisition of knowledge, as important as that is. As our mission statement makes clear, a BYU education focuses on “the full realization of human potential.” - Kevin J. Worthen, BYU President Multicultural Student Services Office, 1320 WSC Provo, Utah 84602 (801)422-3065 MY INFORMATION .................................................................................. 1 Identification ....................................................................................................... 1 SOAR 2020 ACT Instructors ........................................................................... 1 Personal Action Plan ......................................................................................... 2 FOUNDATIONAL DOCUMENTS .......................................................... 3 SOAR Mission & Objectives ........................................................................... 3 SOAR Standards ............................................................................................... -

SCMS 2019 Conference Program
CELEBRATING SIXTY YEARS SCMS 1959-2019 SCMSCONFERENCE 2019PROGRAM Sheraton Grand Seattle MARCH 13–17 Letter from the President Dear 2019 Conference Attendees, This year marks the 60th anniversary of the Society for Cinema and Media Studies. Formed in 1959, the first national meeting of what was then called the Society of Cinematologists was held at the New York University Faculty Club in April 1960. The two-day national meeting consisted of a business meeting where they discussed their hope to have a journal; a panel on sources, with a discussion of “off-beat films” and the problem of renters returning mutilated copies of Battleship Potemkin; and a luncheon, including Erwin Panofsky, Parker Tyler, Dwight MacDonald and Siegfried Kracauer among the 29 people present. What a start! The Society has grown tremendously since that first meeting. We changed our name to the Society for Cinema Studies in 1969, and then added Media to become SCMS in 2002. From 29 people at the first meeting, we now have approximately 3000 members in 38 nations. The conference has 423 panels, roundtables and workshops and 23 seminars across five-days. In 1960, total expenses for the society were listed as $71.32. Now, they are over $800,000 annually. And our journal, first established in 1961, then renamed Cinema Journal in 1966, was renamed again in October 2018 to become JCMS: The Journal of Cinema and Media Studies. This conference shows the range and breadth of what is now considered “cinematology,” with panels and awards on diverse topics that encompass game studies, podcasts, animation, reality TV, sports media, contemporary film, and early cinema; and approaches that include affect studies, eco-criticism, archival research, critical race studies, and queer theory, among others. -

Fifth Annual Conference October 24–26, 2019 Letter Andwelcome Brief Schedule
share light your Fifth Annual Conference October 24–26, 2019 letter andwelcome brief schedule Members and Friends, Thursday, October 24, 2019 8:00 a.m.–12:00 p.m. Workshops I hope you’re as excited about this conference as I am. At the close of 12:00 p.m.–1:00 p.m. Off-Campus Lunch last year’s conference, I wondered whether we could possibly top it 1:00 p.m.–5:00 p.m. Workshops with this year’s conference. Well, I’m confident that we have, thanks to our devoted conference committee, board of directors, and other 5:30 p.m.–6:30 p.m. Tour of BYU Press volunteers. They’ve already put the conference’s theme—”Share Your Light”—into practice. As you attend conference sessions, I hope you’ll Friday, October 25, 2019 likewise share your light, such as by reaching out to other partici- pants to make new connections and to contribute your knowledge 9:00 a.m.–10:00 a.m. Keynote Session and expertise to discussions. 10:10 a.m.–12:00 p.m. Breakout Sessions After you return home, look for ways to share this light with those 12:00 p.m.–1:00 p.m. Lunch around you in the workplace, on social media, and wherever else you may be. As members of the publishing and media industries, we 1:00 p.m.–3:50 p.m. Breakout Sessions have the amazing opportunity to be a source of light in an ever-dark- 4:00 p.m.–5:00 p.m. -

Chapter Template
Copyright by Colleen Leigh Montgomery 2017 THE DISSERTATION COMMITTEE FOR COLLEEN LEIGH MONTGOMERY CERTIFIES THAT THIS IS THE APPROVED VERSION OF THE FOLLOWING DISSERTATION: ANIMATING THE VOICE: AN INDUSTRIAL ANALYSIS OF VOCAL PERFORMANCE IN DISNEY AND PIXAR FEATURE ANIMATION Committee: Thomas Schatz, Supervisor James Buhler, Co-Supervisor Caroline Frick Daniel Goldmark Jeff Smith Janet Staiger ANIMATING THE VOICE: AN INDUSTRIAL ANALYSIS OF VOCAL PERFORMANCE IN DISNEY AND PIXAR FEATURE ANIMATION by COLLEEN LEIGH MONTGOMERY DISSERTATION Presented to the Faculty of the Graduate School of The University of Texas at Austin in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY THE UNIVERSITY OF TEXAS AT AUSTIN AUGUST 2017 Dedication To Dash and Magnus, who animate my life with so much joy. Acknowledgements This project would not have been possible without the invaluable support, patience, and guidance of my co-supervisors, Thomas Schatz and James Buhler, and my committee members, Caroline Frick, Daniel Goldmark, Jeff Smith, and Janet Staiger, who went above and beyond to see this project through to completion. I am humbled to have to had the opportunity to work with such an incredible group of academics whom I respect and admire. Thank you for so generously lending your time and expertise to this project—your whose scholarship, mentorship, and insights have immeasurably benefitted my work. I am also greatly indebted to Lisa Coulthard, who not only introduced me to the field of film sound studies and inspired me to pursue my intellectual interests but has also been an unwavering champion of my research for the past decade. -

CHAPTER ONE 1.0 INTRODUCTION 1.1 PROJECT BACKGROUND 1.1.1 Computer Graphics
CHAPTER ONE 1.0 INTRODUCTION 1.1 PROJECT BACKGROUND Computer graphics and animation is a very broad and wide aspect of computer science, and has effects on our everyday living. Dissemination of information with good graphical user interface becomes very important when very important information have to be passed across. This project would be split into the two aspects (graphics and animation) sometimes during the course of discussion. 1.1.1 Computer Graphics Computers have become a powerful tool for the rapid and economical production of pictures. There is virtually no area in which graphical displays cannot be used to some advantage, and so it is not surprising to find the use of computer graphics so widespread. Although early applications in engineering and science had to rely on expensive and cumbersome equipment, advances in computer technology have made interactive computer graphics a practical tool. Today, we find computer graphics used routinely in such diverse areas as science, Engineering, medicine, business, industry, government, art, entertainment, advertising, Education and training. Before we get into the details of how to do computer graphics, we first take a short tour through a gallery of graphics applications. A major use of computer graphics is in design processes, particularly for engineering and architectural systems, but almost all products are now computer designed. Generally referred to as CAD, computer-aided design methods are now routinely used in the design of buildings, automobiles, aircraft, watercraft, spacecraft, computers, textiles, and many, many other products. For some design applications; object are first displayed in a wireframe outline form that shows the overall sham and internal features of objects. -
22 VII. the New Golden Age Then Something Wonderful Happened. Just When Everything Was Looking As Grim As It Could for the Art O
VII. The New Golden Age Then something wonderful happened. Just when everything was looking as grim as it could for the art of animation, technology came to the rescue. Here was an art form born only because technology made it possible, almost died when the human costs in time and effort became too high, and now was rescued by technology again. The computer age saved animation. Since computers first came on the scene in the 50s, there have been people who have tried to create machinery and programs to make animation faster, easier and cheaper to both make and distribute. From machines like copiers and scanners, to computers that can draw and render, to the distribution of animation by cable, Internet, phones, tablets and video games - as one character says, “To infinity and beyond” - animation has been totally reborn. As the old animators of the Golden Age were dying off, the new technologies created a huge demand for the old craft. Fortunately, many of the old men were able to pass on their skills to a younger generation, which has helped the quality of today's animation meet and exceed the animation of the Golden Age. In 1985, Girard and Maciejewski at OSU publish a paper describing the use of inverse kinematics and dynamics for animation.! The first live-action film to feature a complete computer-animated character is released, "YOUNG SHERLOCK HOLMES."! Ken Perlin at NYU publishes a paper on noise functions for textures. He later applied this technique to add realism to character animations. In 1986, "A GREEK TRAGEDY" wins the Academy Award. -

Animação Digital 2D: Simulando O Fazer Tradicional Através Da Ferramenta Do Computador
Simon Pedro Brethé ANIMAÇÃO DIGITAL 2D: SIMULANDO O FAZER TRADICIONAL ATRAVÉS DA FERRAMENTA DO COMPUTADOR Escola de Belas Artes Universidade Federal de Minas Gerais Belo Horizonte, dezembro de 2010. Simon Pedro Brethé ANIMAÇÃO DIGITAL 2D: SIMULANDO O FAZER TRADICIONAL ATRAVÉS DA FERRAMENTA DO COMPUTADOR Dissertação apresentada ao programa de Pós- Graduação em Artes da Escola de Belas Artes da Universidade Federal de Minas Gerais, como requisito parcial à obtenção do título de Mestre em Artes. Área de Concentração: Arte e Tecnologia da Imagem. Orientadora: Profª. Drª. Ana Lúcia Andrade EBA / UFMG Belo Horizonte Escola de Belas Artes /UFMG 2010 FICHA CATALOGRÁFICA Brethé, Simon, 1978- Animação digital 2D: simulando o fazer tradicional através da ferramenta do computador / Simon Pedro Brethé. – 2011. 176 f.: il. Orientadora: Ana Lúcia Andrade Dissertação (mestrado) – Universidade Federal de Minas Gerais, Escola de Belas Artes. 1. Animação (Cinematografia) – Teses 2. Animação por computador – Teses 3. Animação (Cinematografia) – Técnica – Teses 4. Animação por computador – Técnica – Teses I. Andrade, Ana Lúcia, 1969 – II. Universidade Federal de Minas Gerais. Escola de Belas Artes. III. Título. CDD 778.5347 AGRADECIMENTOS A todas as pessoas próximas pelo apoio e carinho. A Patrícia Martins pela paciência e companheirismo. À minha orientadora Ana pela orientação, apoio e amizade. A todos aqueles que acreditam no meu trabalho como animador: Antônio Fialho Maurício Gino Chico Marinho Jalver Bethônico Ricardo Souza E a todos os amantes da sétima arte. “A arte é enriquecida pela sutil exploração da técnica” Alberto Lucena Júnior Resumo: Esta pesquisa tem como objetivo demonstrar como a tecnologia do computador vem, ao longo de sua evolução gráfica e tecnológica, possibilitando o desenvolvimento de recursos capazes de representar virtualmente e fisicamente as técnicas, instrumentos e procedimentos tradicionais de desenho e pintura voltados para a animação 2D. -

87Th Oscars Nominations Announced
MEDIA CONTACT Natalie Kojen [email protected] Gail Silverman [email protected] January 15, 2015 FOR IMMEDIATE RELEASE 87TH OSCARS® NOMINATIONS ANNOUNCED LOS ANGELES, CA — Directors Alfonso Cuarón and J.J. Abrams, actor Chris Pine and Academy President Cheryl Boone Isaacs announced the nominations for the 87th Academy Awards® today (January 15). For the first time, nominees in all 24 categories were announced live. Cuarón and Abrams announced the nominees in 11 categories at 5:30 a.m. PT, followed by Pine and Boone Isaacs for the remaining 13 categories at 5:38 a.m. PT, at the live news conference attended by more than 400 international media representatives. For a complete list of nominees, visit the official Oscars website, www.oscar.com. Academy members from each of the 17 branches vote to determine the nominees in their respective categories – actors nominate actors, film editors nominate film editors, etc. In the Animated Feature Film and Foreign Language Film categories, nominees are selected by a vote of multi-branch screening committees. All voting members are eligible to select the Best Picture nominees. Official screenings of all motion pictures with one or more nominations will begin for members on Saturday, January 24, at the Academy's Samuel Goldwyn Theater. Screenings also will be held at the Academy’s Linwood Dunn Theater in Hollywood and in London, New York and the San Francisco Bay Area. Active members of the Academy are eligible to vote for the winners in all categories. To access the complete nominations press kit, visit www.oscars.org/press/press-kits.