View of the CLEO3 Detector
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

BABAR Studies Matter-Antimatter Asymmetry in Τ Lepton Decays
BABAR studies matter-antimatter asymmetry in τττ lepton decays Humans have wondered about the origin of matter since the dawn of history. Physicists address this age-old question by using particle accelerators to recreate the conditions that existed shortly after the Big Bang. At an accelerator, energy is converted into matter according to Einstein’s famous energy-mass relation, E = mc 2 , which offers an explanation for the origin of matter. However, matter is always created in conjunction with the same amount of antimatter. Therefore, the existence of matter – and no antimatter – in the universe indicates that there must be some difference, or asymmetry, between the properties of matter and antimatter. Since 1999, physicists from the BABAR experiment at SLAC National Accelerator Laboratory have been studying such asymmetries. Their results have solidified our understanding of the underlying micro-world theory known as the Standard Model. Despite its great success in correctly predicting the results of laboratory experiments, the Standard Model is not the ultimate theory. One indication for this is that the matter-antimatter asymmetry allowed by the Standard Model is about a billion times too small to account for the amount of matter seen in the universe. Therefore, a primary quest in particle physics is to search for hard evidence for “new physics”, evidence that will point the way to the more complete theory beyond the Standard Model. As part of this quest, BABAR physicists also search for cracks in the Standard Model. In particular, they study matter-antimatter asymmetries in processes where the Standard Model predicts that asymmetries should be very small or nonexistent. -

Reconstruction of Semileptonic K0 Decays at Babar
Reconstruction of Semileptonic K0 Decays at BaBar Henry Hinnefeld 2010 NSF/REU Program Physics Department, University of Notre Dame Advisor: Dr. John LoSecco Abstract The oscillations observed in a pion composed of a superposition of energy states can provide a valuable tool with which to examine recoiling particles produced along with the pion in a two body decay. By characterizing these oscillation in the D+ ! π+ K0 decay we develop a technique that can be applied to other similar decays. The neutral kaons produced in the D+ ! π+ K0 decay are generated in flavor eigenstates due to their production via the weak force. Kaon flavor eigenstates differ from kaon mass eigenstates so the K0 can be equally represented as a superposition of mass 0 0 eigenstates, labelled KS and KL. Conservation of energy and momentum require that the recoiling π also be in an entangled superposition of energy states. The K0 flavor can be determined by 0 measuring the lepton charge in a KL ! π l ν decay. A central difficulty with this method is the 0 accurate reconstruction of KLs in experimental data without the missing information carried off by the (undetected) neutrino. Using data generated at the Stanford Linear Accelerator (SLAC) and software created as part of the BaBar experiment I developed a set of kinematic, geometric, 0 and statistical filters that extract lists of KL candidates from experimental data. The cuts were first developed by examining simulated Monte Carlo data, and were later refined by examining 0 + − 0 trends in data from the KL ! π π π decay. -

A Successful Start to Preparations for the Babar Experiment
In June this year, the first part of new collider A successful called PEP-II was commissioned. It will be used in an experiment to observe a rare effect start to in particle physics that could explain why there appears to be only matter and not antimatter in the Universe. The effect is preparations called CP violation, and the experiment will measure for the first time subtle differences in for the BaBar the way fundamental particles called B mesons and their antiparticles decay. experiment According to theory, particles and their antimatter partners should behave like exact mirror images of each other. However, the B by Professor Mike Green mesons and their antiparticles are predicted Royal Holloway, University of London to break this mirror symmetry by a tiny amount. Extract taken from the PPARC Annual Report 1996-97 The so-called BaBar experiment (so named because the symbol for the anti-B meson is a letter 'B' with a bar across the top, and permission was obtained from the author of Babar the Elephant for the use of his name!) takes advantage of the 3-kilometre-long Stanford Linear Accelerator in California which creates and accelerates beams of electrons and their antiparticles, positrons. The beams are then injected into PEP-II. This consists of two concentric rings, 2 kilometres across, which will store the separate beams of electrons and positrons. In the rings, the beams travel close to the speed of light under the influence of electric and magnetic fields which accelerate, guide and focus the beams. The ring being used to store electrons was already in existence, and that is the one which has just been commissioned. -

Flavour Physics
May 21, 2015 0:29 World Scientific Review Volume - 9in x 6in submit page 1 TASI Lectures on Flavor Physics Zoltan Ligeti Ernest Orlando Lawrence Berkeley National Laboratory, University of California, Berkeley, CA 94720 ∗E-mail: [email protected] These notes overlap with lectures given at the TASI summer schools in 2014 and 2011, as well as at the European School of High Energy Physics in 2013. This is primarily an attempt at transcribing my hand- written notes, with emphasis on topics and ideas discussed in the lec- tures. It is not a comprehensive introduction or review of the field, nor does it include a complete list of references. I hope, however, that some may find it useful to better understand the reasons for excitement about recent progress and future opportunities in flavor physics. Preface There are many books and reviews on flavor physics (e.g., Refs. [1; 2; 3; 4; 5; 6; 7; 8; 9]). The main points I would like to explain in these lectures are: • CP violation and flavor-changing neutral currents (FCNC) are sen- sitive probes of short-distance physics, both in the standard model (SM) and in beyond standard model (BSM) scenarios. • The data taught us a lot about not directly seen physics in the past, and are likely crucial to understand LHC new physics (NP) signals. • In most FCNC processes BSM/SM ∼ O(20%) is still allowed today, the sensitivity will improve to the few percent level in the future. arXiv:1502.01372v2 [hep-ph] 19 May 2015 • Measurements are sensitive to very high scales, and might find unambiguous signals of BSM physics, even outside the LHC reach. -

Incomplete Document
Improved measurement of the Pseudoscalar Decay Constants fDS from D∗+ γµ+ ν data sample s → Abstract + − Determination of fDS using 14 million e e cc¯ events obtained with the CLEO → II and CLEO II.V detector is presented. New measurement of the branching ratio gives Γ (D+ µ+ν)/Γ (D+ φπ+) = 0.137 0.013 0.022. Using Γ (D+ µ+ν) = 0.036 S → S → ± ± S → 0.09, fDS was calculated and found to be (247 12 20 31) MeV. Comparison ± ± ± ± of these results with other theoretical and experimental results are also presented. 1 Introduction Purely leptonic decay modes of heavy mesons predict their decay constants, which is connected with measured quantities such as CKM matrix elements. Currently it is not possible to measure fB experimentally, but measurements of the Cabibbo-flavor pseudoscalar decay constants such as fDS is possible. This measurement provides a check of these theoretical calculations and helps to establish different theoretical models. + The decay width of Ds is given by [1] G2 m2 Γ(D+ ℓ+ν)= F f 2 m2M 1 ℓ V 2 (1) s 6π DS ℓ DS 2 cs → − MDS ! | | where MDS is the Ds mass, mℓ is the mass of the final state lepton, Vcs is a CKM matrix element equal to 0.974 [2] and GF is the Fermi coupling constant. Various theoretical predictions of fDS range from 190 MeV to 350 MeV. The relative widths of three lepton flavors are 10 : 1 : 10−5 for tau, muon and electron respectively. Helicity suppression reduces smaller width for low mass electron. -

Design and Application of the Reconstruction Software for the Babar Calorimeter
Design and application of the reconstruction software for the BaBar calorimeter Philip David Strother Imperial College, November 1998 A thesis submitted for the degree of Doctor of Philosophy of the University of London, and Diploma of Imperial College 2 Abstract + The BaBar high energy physics experiment will be in operation at the PEP-II asymmetric e e− collider in Spring 1999. The primary purpose of the experiment is the investigation of CP violation in the neutral B meson system. The electromagnetic calorimeter forms a central part of the experiment and new techniques are employed in data acquisition and reconstruction software to maximise the capability of this device. The use of a matched digital filter in the feature extraction in the front end electronics is presented. The performance of the filter in the presence of the expected high levels of soft photon background from the machine is evaluated. The high luminosity of the PEP-II machine and the demands on the precision of the calorimeter require reliable software that allows for increased physics capability. BaBar has selected C++ as its primary programming language and object oriented analysis and design as its coding paradigm. The application of this technology to the reconstruction software for the calorimeter is presented. The design of the systems for clustering, cluster division, track matching, particle identification and global calibration is discussed with emphasis on the provisions in the design for increased physics capability as levels of understanding of the detector increase. The CP violating channel Bo J=ΨKo has been studied in the two lepton, two π0 final state. -

Charged Particle Tracking in the CLEO II Detector
Charged Particle Tracking in the CLEO II Detector for Neutrino Reconstruction Michell Morgan Computer Science Department, Wayne State University, Detroit, Michigan, 48204 Abstract In neutrino reconstruction analyses, we rely on information from tracks from other particles in the event to determine the neutrino momentum. It is very important to nd out as much information as possible about those tracks for neutrino reconstruction. Currently, events with one or more tracks with no z t are not used, leading to an ineciency of about 15%. However, such tracks do have hits with z information on charge division wires which are ignored by the tracking program, because charge division hits z information has been observed to be very inaccurate on occasion. We have traced the inaccuracies to the z calibration which was performed only for central tracks and involved tting with a cubic polynomial. However, for forward tracks, the cubic leads to hits with z positions very far from the actual path of the track. We have investigated solutions to this problem so that we may be able to recover some z information on tracks in events that we currently throw away and use them in neutrino reconstruction. Introduction Neutrinos are neutral particles that pass through the detector at the speed of light. Because neutrinos are neutral and weakly interacting, they do not leave tracks in the detector nor hits in the calorimeter. Thus, for neutrino reconstruction, we have to know the energy and momentum of the other particles in the event. The total momentum of the colliding system is zero and thus the nal particles in the event must balance. -
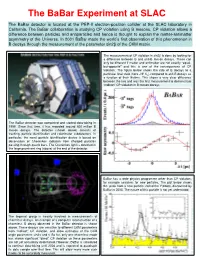
The Babar Experiment at SLAC the Babar Detector Is Located at the PEP-II Electron-Positron Collider at the SLAC Laboratory in California
The BaBar Experiment at SLAC The BaBar detector is located at the PEP-II electron-positron collider at the SLAC laboratory in California. The BaBar collaboration is studying CP violation using B mesons. CP violation allows a difference between particles and antiparticles and hence is thought to explain the matter-antimatter asymmetry of the Universe. In 2001 BaBar made the world’s first observation of this phenomenon in B decays through the measurement of the parameter sin2β of the CKM matrix. The measurement of CP violation in sin2β is done by looking for a difference between B and anti-B meson decays. These can only be different if matter and antimatter are not exactly “equal- but-opposite” and this is one of the consequences of CP violation. The figure below shows the rate of B decays to a particular final state (here J/Ψ KS) compared to anti-B decays as a function of their lifetime. This shows a very clear difference between the two and was the first measurement to demonstrate “indirect” CP violation in B meson decays. The BaBar detector was completed and started data-taking in 1999. Since that time, it has recorded around 600 million B meson decays. The detector (shown above) consists of tracking, particle identification and calorimeter subdetectors. In particular, the novel particle identification device is based on observation of Cherenkov radiation from charged particles passing through quartz bars. The Cherenkov light is detected in the large prominent ring (above) at the end of the detector. BaBar has a wide physics programme other than CP violation, for example searches for new particles. -

Measurement of Production and Decay Properties of Bs Mesons Decaying Into J/Psi Phi with the CMS Detector at the LHC
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Doctoral Dissertations Graduate School 5-2012 Measurement of Production and Decay Properties of Bs Mesons Decaying into J/Psi Phi with the CMS Detector at the LHC Giordano Cerizza University of Tennessee - Knoxville, [email protected] Follow this and additional works at: https://trace.tennessee.edu/utk_graddiss Part of the Elementary Particles and Fields and String Theory Commons Recommended Citation Cerizza, Giordano, "Measurement of Production and Decay Properties of Bs Mesons Decaying into J/Psi Phi with the CMS Detector at the LHC. " PhD diss., University of Tennessee, 2012. https://trace.tennessee.edu/utk_graddiss/1279 This Dissertation is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Doctoral Dissertations by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a dissertation written by Giordano Cerizza entitled "Measurement of Production and Decay Properties of Bs Mesons Decaying into J/Psi Phi with the CMS Detector at the LHC." I have examined the final electronic copy of this dissertation for form and content and recommend that it be accepted in partial fulfillment of the equirr ements for the degree of Doctor of Philosophy, with a major in Physics. Stefan M. Spanier, Major Professor We have read this dissertation and recommend its acceptance: Marianne Breinig, George Siopsis, Robert Hinde Accepted for the Council: Carolyn R. Hodges Vice Provost and Dean of the Graduate School (Original signatures are on file with official studentecor r ds.) Measurements of Production and Decay Properties of Bs Mesons Decaying into J/Psi Phi with the CMS Detector at the LHC A Thesis Presented for The Doctor of Philosophy Degree The University of Tennessee, Knoxville Giordano Cerizza May 2012 c by Giordano Cerizza, 2012 All Rights Reserved. -

A Measurement of Neutral B Meson Mixing Using Dilepton Events with the BABAR Detector
A measurement of neutral B meson mixing using dilepton events with the BABAR detector Naveen Jeevaka Wickramasinghe Gunawardane Imperial College, London A thesis submitted for the degree of Doctor of Philosophy of the University of London and the Diploma of Imperial College December, 2000 A measurement of neutral B meson mixing using dilepton events with the BABAR detector Naveen Gunawardane Blackett Laboratory Imperial College of Science, Technology and Medicine Prince Consort Road London SW7 2BW December, 2000 ABSTRACT This thesis reports on a measurement of the neutral B meson mixing parameter, ∆md, at the BABAR experiment and the work carried out on the electromagnetic calorimeter (EMC) data acquisition (DAQ) system and simulation software. The BABAR experiment, built at the Stanford Linear Accelerator Centre, uses the PEP-II asymmetric storage ring to make precise measurements in the B meson system. Due to the high beam crossing rates at PEP-II, the DAQ system employed by BABAR plays a very crucial role in the physics potential of the experiment. The inclusion of machine backgrounds noise is an important consideration within the simulation environment. The BABAR event mixing software written for this purpose have the functionality to mix both simulated and real detector backgrounds. Due to the high energy resolution expected from the EMC, a matched digital filter is used. The performance of the filter algorithms could be improved upon by means of a polynomial fit. Application of the fit resulted in a 4-40% improvement in the energy resolution and a 90% improvement in the timing resolution. A dilepton approach was used in the measurement of ∆md where the flavour of the B was tagged using the charge of the lepton. -

QCD Studies in Two-Photon Collisions at CLEO Vladimir Savinov University of Pittsburgh, Pittsburgh
W03 hep-ex/0106013 QCD Studies in Two-Photon Collisions at CLEO Vladimir Savinov University of Pittsburgh, Pittsburgh We review the results of two-photon measurements performed up to date by the CLEO experiment at Cornell University, Ithaca, NY.These + − measurements provide an almost background-free virtual laboratory to study strong interactions in the process of the e e scattering. We discuss the measurements of two-photon partial widths of charmonium, cross sections for hadron pairs production, antisearch for glueballs ∗ and the measurements of γ γ → pseudoscalar meson transition form factors. We emphasize the importance of other possible analyses, favorable trigger conditions and selection criteria of the presently running experiment and the advantages of CLEOc—the future τ-charm factory with the existing CLEO III detector. 1. INTRODUCTION a time-of-flight (TOF) plastic scintillator system and a muon system (proportional counters embedded at various depths in One of the ways to study properties of strong interactions, the steel absorber). Two thirds of the data were taken with the surprisingly, is to collide high energy photons. Photons do not CLEO II.V configuration of the detector where the innermost interact strongly, however, in the presence of other photons drift chamber was replaced by a silicon vertex detector [4] and they can fluctuate into quark pairs that have a sizable probabil- the argon-ethane gas of the main drift chamber was changed ity to realize as hadrons. Space-like photons of relatively high to a helium-propane mixture. This upgrade led to improved energies can be obtained in the process of the e+e− scattering, resolutions in momentum and specific ionization energy loss that is, in the e+e− → e+e−hadrons reactions, where hadrons (dE/dx) measurements. -

Glueball Searches in Babar
' $ Glueball Searches in BaBar. Antimo Palano INFN and University of Bari, Italy Summary: • Introduction. • Experimental techniques. • The BaBar experiment. • Three body Dalitz plot analysis. • First experimental results. • Conclusions. & % 1 ' $ Introduction: Physics Motivations • New generation experiments, fixed target and B-factories, are accumulating high quality, large data samples on Beauty and Charm Physics. • Important information related to glueball searches can come from: • The Dalitz plot analysis of 3-body Charm and B decays. • The study of the process: b → sg • The Dalitz Plot Analysis of three-body decays is a relatively new powerful technique for studying Beauty and Charm Physics. • It is the most complete way of analyzing the data. • It allows to measure decay amplitudes and phases. • The final state is the result of the interference of all the intermediate states. & % 2 ' $ Introduction • One of the most important Motivations for continuing working on Light Meson Spectroscopy is the search for Glueballs and Exotic mesons. • From Lattice QCD, the lightest glueball, with J PC =0++ i s expected around 1.7 GeV. & % 3 ' $ • A variety of exotics is also expected below 2.5 GeV. Hybrids (¯qqg mesons) or 4-quark states. Some of them could be narrow enough to be detected. Some of them have quantum numbers forbidden for qq¯ mesons, such as: J PC =1−+,0−−, 0+−, etc. • The structure of the lowestqq ¯ multiplets is mostly still undefined and this prevents unique “exotic assignments” of gluonic candidates. • Strategy to find these states: they do not fit in the standard qq¯ nonet. They are extra states. • New inputs from heavy mesons decays could solve old and new puzzles in light meson spectroscopy.