Hibernating in the Cloud – Implementation And
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

JDO Getting Started Guide (V5.0) Table of Contents
JDO Getting Started Guide (v5.0) Table of Contents Key Points. 2 Understanding the JARs . 3 JDO Tutorial (v5.0) . 4 Background . 4 Step 0 : Download DataNucleus AccessPlatform . 4 Step 1 : Take your model classes and mark which are persistable . 4 Step 2 : Define the 'persistence-unit' . 7 Step 3 : Enhance your classes . 8 Step 4 : Write the code to persist objects of your classes . 10 Step 5 : Run your application . 12 Step 6 : Controlling the schema . 14 Step 7 : Generate any schema required for your domain classes . 17 Any questions? . 18 Developing applications is, in general, a complicated task, involving many components. Developing all of these components can be very time consuming. The Java Data Objects API (JDO) was designed to alleviate some of this time spent, providing an API to allow java developers to persist object-oriented data into any database, and providing a query language using the same Java syntax as the developer is already familiar with. DataNucleus JDO provides an implementation of this JDO standard, allowing you, the user, to persist your object-oriented data to not only the RDBMS datastores the standard was intended for, but also to a wide range of other datastores. These include popular map stores such as Cassandra and HBase, the Neo4j graph store, spreadsheets in Excel or OpenDocument formats, JSON formatted Amazon and Google Storage options, the popular MongoDB JSON-like document store, as well as ubiquitous LDAP and more besides. DataNucleus doesn’t purport to be the best solution to every problem. For example, where you want to bulk persist large amounts of data then other solutions that get closer to the datastore API would be more appropriate. -

Java LDAP Persistence with Datanucleus
Java LDAP Persistence with DataNucleus Stefan Seelmann [email protected] Java LDAP Persistence with DataNucleus • Stefan Seelmann • Freelancer – Software Development with Java – LDAP, Identity- and Access-Management • Open Source Developer – Apache Directory Project – DataNucleus LDAP Store Java LDAP Persistence with DataNucleus Agenda • Motivation • Java Persistence, JDO and DataNucleus • Basic Demo • DataNucleus LDAP Store • Advanced Demo • Status and Conclusion Java LDAP Persistence with DataNucleus Java LDAP Development • Java APIs for LDAP – Mature: Netscape LDAP SDK, JLDAP (Novell/OL) – Modern: Unbound ID, Apache Directory, OpenDS • Hopefully a common Java LDAP API soon? – JNDI, Spring-LDAP • Drawback: – Developer has to deal with LDAP • DN, RDN, filters, modification items, error codes – Boiler-Plate code, exception handling Java LDAP Persistence with DataNucleus Java Persistence • Standards – JPA (Java Persistence API): JSR 220, RDBMS only – SDO (Service Data Objects): JSR 235 – JDO: (Java Data Object): JSR-12 and JSR-243 • Products – O/R Mapper: Hibernate, TopLink/EclipseLink, ... – Apache iBATIS, Cayenne, OpenJPA, Tuscany, ... – DataNucleus – ... Java LDAP Persistence with DataNucleus JDO • Java-centric API to access persistent data • Datastore independent • Started by Sun, now driven by Apache JDO • Versions 1.0, 2.0, 2.1, 2.2, 2.3 in progress • Three main parts – Persistence definition (metadata) – Persistence API – Query language/API Java LDAP Persistence with DataNucleus DataNucleus • Reference implementation of JDO • Apache -

JPA Query Guide (V5.2) Table of Contents
JPA Query Guide (v5.2) Table of Contents Query API . 2 setFirstResult(), setMaxResults(). 2 setHint() . 2 setParameter(). 3 getResultList() . 3 getSingleResult(). 3 executeUpdate() . 4 setFlushMode() . 4 setLockMode(). 4 Large Result Sets : Loading Results at Commit(). 4 Result Set : Caching of Results. 5 Large Result Sets : Size . 5 RDBMS : Result Set Type. 5 RDBMS : Result Set Control . 6 JPQL . 7 SELECT Syntax . 7 FROM Clause . 7 Fetched Fields . 11 WHERE clause (filter) . 11 GROUP BY/HAVING clauses . 11 ORDER BY clause . 12 Fields/Properties . 13 Operators . 13 Literals . 13 Parameters. 14 CASE expressions . 15 JPQL Functions . 15 Collection Fields . 30 Map Fields . 30 Subqueries. 30 Specify candidates to query over . 31 Range of Results . 32 Query Result . 32 Query Execution. 34 Named Query . 35 JPQL : SQL Generation for RDBMS. 36 JPQL DELETE Queries . 37 JPQL UPDATE Queries . 37 JPQL Syntax Strictness . 38 JPQL Syntax BNF Notation. 38 Criteria . 43 Creating a Criteria query . 43 JPQL equivalent of the Criteria query. 43 Criteria API : Result clause. 44 Criteria API : FROM clause joins. 44 Criteria API : WHERE clause . 44 Criteria API : Ordering . 46 Criteria API : Parameters . 47 Criteria API : Subqueries . .. -

JPA Persistence Guide (V5.2) Table of Contents
JPA Persistence Guide (v5.2) Table of Contents EntityManagerFactory. 2 Create an EMF in JavaSE . 2 Create an EMF in JavaEE . 2 Persistence Unit . 3 EntityManagerFactory Properties . 6 Closing EntityManagerFactory . 27 Level 2 Cache. 27 Datastore Schema. 34 Schema Generation for persistence-unit . 34 Schema Auto-Generation at runtime . 35 Schema Generation : Validation . 36 Schema Generation : Naming Issues . 36 Schema Generation : Column Ordering . 37 Schema : Read-Only. 37 SchemaTool . 38 Schema Adaption . 44 RDBMS : Datastore Schema SPI . 44 EntityManager. 48 Opening/Closing an EntityManager. 48 Persisting an Object. 49 Persisting multiple Objects in one call . 49 Finding an object by its identity . 50 Finding an object by its class and unique key field value(s) . 50 Deleting an Object . 51 Deleting multiple Objects. 51 Modifying a persisted Object. 52 Modifying multiple persisted Objects . 52 Refreshing a persisted Object . 52 Getting EntityManager for an object. 53 Cascading Operations . 53 Orphans . 54 Managing Relationships . 54 Level 1 Cache. 56 Object Lifecycle. 58 Transaction PersistenceContext . 58 Extended PersistenceContext . 58 Detachment . 58 Helper Methods . 59 Transactions . 60 Locally-Managed Transactions. 60 JTA Transactions. 61 Container-Managed Transactions . 63 Spring-Managed Transactions . 63 No Transactions . 63 Transaction Isolation . 64 Read-Only Transactions . 64 Flushing . 65 Transactions with lots of data. 66 Transaction Savepoints . 67 Locking . 68 Optimistic Locking. 68 Pessimistic (Datastore) Locking . 69 Datastore. -

Performance Evaluation of Jpa Based Orm Techniques
Proceedings of 2nd International Conference on Computer Science Networks and Information Technology, Held on 27th - 28th Aug 2016, in Montreal, Canada, ISBN: 9788193137369 PERFORMANCE EVALUATION OF JPA BASED ORM TECHNIQUES Neha Dhingra Dr. Emad Abdelmoghith Department of Electrical Engineering and Computer Department of Electrical Engineering and Computer Science, University Of Ottawa, Ottawa, Canada Science, University Of Ottawa, Ottawa, Canada Dr. Hussein T. Mouftah Department of Electrical Engineering and Computer Science, University Of Ottawa, Ottawa, Canada Abstract— Persistence and Performance are an integral coding is depleted, programming costs reduced, JPA part of a Java API. This paper studies the performance prevalence has rapidly improved, coupled with performance analysis of different JPA implementations based on the breakdowns, there is enough momentum for a developer to ORM framework. Large Enterprises working on JPA perform a performance analysis in order sustain JPA have become concerned about the potential pressures programming indefinitely in the near future. Furthermore, and overloads that a JPA implementations i.e. in today’s software market, there is increasing pressure on Hibernate, EclipseLink, OpenJPA and Data Nucleus the developers and enterprise to adopt API that reduce the can endure. Java Persistence API (JPA) represents a development time and programming cost in order to be significant role in the efficient performance of the API considered more sustainable technology. because the persistence process can be coordinated with JPA implementations come in many variants which have the advanced features used to sustain the heavy loaded lead to a myriad of acronyms that are worth summariz-ing. applications. Therefore, an analysis would demonstrate Currently, Hibernate, OpenJPA, and EclipseLink are the impacts of different queries in various scenarios deemed as the most successful performance oriented JPA such as I/O, CPU, Garbage collection and other implementations based Lazy Load concept. -

Espresso: Brewing Java for More Non-Volatility with Non-Volatile Memory
Espresso: Brewing Java For More Non-Volatility with Non-volatile Memory Mingyu Wu, Ziming Zhao, Haoyu Li, Heting Li, Haibo Chen, Binyu Zang, Haibing Guan Shanghai Key Laboratory of Scalable Computing and Systems Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University Abstract straction brought by the language virtual machine (e.g., JVM) Fast, byte-addressable non-volatile memory (NVM) em- complicates the persistence management. braces both near-DRAM latency and disk-like persistence, The mainstream persistent programming model leverages a which has generated considerable interests to revolutionize coarse-grained abstraction like Java Persistence API (JPA)[9] system software stack and programming models. However, it to provide easy-to-use transactional APIs for programmers to is less understood how NVM can be combined with managed persist their data. However, it does not consider the emer- runtime like Java virtual machine (JVM) to ease persistence gence of NVM, and creates unnecessary transformation over- management. This paper proposes Espresso1, a holistic ex- head between Java objects and native serialized data. In tension to Java and its runtime, to enable Java programmers contrast, the recent proposed Persistent Collections for Java to exploit NVM for persistence management with high perfor- (PCJ) [14] provides a fine-grained programming model to en- mance. Espresso first provides a general persistent heap de- able users to manipulate persistent data in object level. How- sign called Persistent Java Heap (PJH) to manage persistent ever, it has built an independent type system against the orig- data as normal Java objects. The heap is then strengthened inal one in Java, which makes it hard to be compatible with with a recoverable mechanism to provide crash consistency existing Java programs since it mandates the use of the collec- for heap metadata. -

JDO Getting Started Guide (V5.1) Table of Contents
JDO Getting Started Guide (v5.1) Table of Contents Key Points. 2 Understanding the JARs . 3 JDO Tutorial (v5.1) . 4 Background . 4 Step 0 : Download DataNucleus AccessPlatform . 4 Step 1 : Take your model classes and mark which are persistable . 4 Step 2 : Define the 'persistence-unit' . 7 Step 3 : Enhance your classes . 8 Step 4 : Write the code to persist objects of your classes . 10 Step 5 : Run your application . 12 Step 6 : Controlling the schema . 14 Step 7 : Generate any schema required for your domain classes . 17 Any questions? . 18 Developing applications is, in general, a complicated task, involving many components. Developing all of these components can be very time consuming. The Java Data Objects API (JDO) was designed to alleviate some of this time spent, providing an API to allow java developers to persist object-oriented data into any database, and providing a query language using the same Java syntax as the developer is already familiar with. DataNucleus JDO provides an implementation of this JDO standard, allowing you, the user, to persist your object-oriented data to not only the RDBMS datastores the standard was intended for, but also to a wide range of other datastores. These include popular map stores such as Cassandra and HBase, the Neo4j graph store, spreadsheets in Excel or OpenDocument formats, JSON formatted Amazon and Google Storage options, the popular MongoDB JSON-like document store, as well as ubiquitous LDAP and more besides. DataNucleus doesn’t purport to be the best solution to every problem. For example, where you want to bulk persist large amounts of data then other solutions that get closer to the datastore API would be more appropriate. -

Towards Standard-Based (Healthcare) Ecosystems Of
Department of Computer Science Overskrift her Towards Standard-Based (Healthcare) Ecosystems of Systems Navn på oplægsholder Navn på KU- enhed Konstantinos Manikas 1st Scandinavian Workshop on the Engineering of Systems-of-Systems (SWESoS 2015) For at ændre ”Enhedens”Enhedens navn”navn” og ”Sted”Sted og dato”:dato”: (Work presented in collaboration with Klaus Marius Hansen, Henrik Bærbak Christensen, Morten Kyng, Jens Knodel) Klik i menulinjen, vælg ”Indsæt””Indsæt” >> ”Sidehoved”Sidehoved / SidefodSidefod”.”. Indføj ”Sted”Sted og datodato”” i feltet for dato og ”Enhedens”Enhedens Slide 1 navnnavn”” i Sidefod Department of Computer Science Overskrift her Overview Tekst starter uden Investigate intersection of software ecosystems and punktopstilling systems of systems For at få punkt- opstilling på teksten, brug Propose: Standard-based ecosystem of systems forøg indrykning Facilitated by For at få venstre- stillet tekst uden Reference architecture punktopstilling, brug formindsk indrykning Explicit orchestration (governance, certification) Standards only means to value creation For at ændre ”Enhedens”Enhedens navn”navn” og ”Sted”Sted og dato”:dato”: Klik i menulinjen, vælg ”Indsæt””Indsæt” >> ”Sidehoved”Sidehoved / SidefodSidefod”.”. Indføj ”Sted”Sted og datodato”” i feltet for dato og ”Enhedens”Enhedens Slide 2 navnnavn”” i Sidefod Department of Computer Science Overskrift her Background Tekst starter uden punktopstilling PhD thesis on software ecosystems for telemedicine services For at få punkt- opstilling på teksten, brug Problem: forøg indrykning Low incentives for TM development For at få venstre- although potential benefits stillet tekst uden High requirements on interoperability punktopstilling, brug formindsk Data sharing indrykning “Silo” solution For at ændre Telemedicine domain: ” ” ”EnhedensEnhedens navn”navn Mission-critical nature og ”Sted”Sted og dato”:dato”: regulated Klik i menulinjen, vælg ”Indsæt””Indsæt” >> requirements on safety, security, privacy ”Sidehoved”Sidehoved / SidefodSidefod”.”. -

JDO Query Guide (V5.2) Table of Contents
JDO Query Guide (v5.2) Table of Contents Query API . 2 Creating a query . 2 Closing a query . 3 Named Query . 3 Query Extensions . 5 Setting query parameters. 6 Compiling a query . 6 Executing a query . 6 Controlling the execution : FetchPlan . 7 ignoreCache(), setIgnoreCache(). 9 Control over locking of fetched objects . 9 Timeout on query execution for reads . 9 Timeout on query execution for writes . 10 Extension: Loading Large Result Sets at Commit() . 10 Extension: Caching of Results . 10 Extension: Size of Large Result Sets . 10 Extension: Type of Result Set (RDBMS). 11 Extension: Result Set Control (RDBMS). 11 JDOQL . 13 JDOQL Single-String syntax . 13 Candidate Class. 14 Filter . 15 Fields/Properties . 16 Methods . 17 Literals . 35 Parameters. 35 Variables. 37 Imports . 38 IF ELSE expressions. 39 Operators . 39 instanceof. 40 casting. 40 Subqueries. 40 Result clause . 43 Result Class . 44 Grouping of Results . 45 Ordering of Results . 46 Range of Results . 46 JDOQL In-Memory queries . 47 Update/Delete queries. 48 Deletion by Query . 48 Bulk Delete. 48 Bulk Update . 48 JDOQL Strictness . 49 JDOQL : SQL Generation for RDBMS . 49 JDOQL Typed . 50 Preparation . 50 Query Classes . 51 Query API - Filtering . .. -

Fundamentals Table of Contents
Fundamentals Table of Contents 1. Fundamentals . 1 1.1. Other Guides . 1 2. Core Concepts . 2 2.1. Philosophy and Architecture . 2 2.2. Principles and Values . 12 2.3. Apache Isis vs … . 16 2.4. Deployment Options . 19 3. Building Blocks . 22 3.1. A MetaModel . 22 3.2. Type of Domain Objects . 22 3.3. Identifiers. 30 3.4. Object Members . 32 3.5. Events . 33 3.6. Modules . 35 4. Getting Started . 37 4.1. Prerequisites . 37 4.2. HelloWorld Archetype . 38 4.3. SimpleApp Archetype . 57 4.4. Datanucleus Enhancer . 66 5. Programming Model . 68 5.1. Domain Entities . 69 5.2. Domain Services . 73 5.3. Property . 80 5.4. Collections . 87 5.5. Actions . 89 5.6. Injecting services . 95 5.7. Properties vs Parameters . 97 5.8. View Models . 97 5.9. Mixins . 110 6. UI Hints . 117 6.1. Layout . 117 6.2. Object Titles and Icons . 117 6.3. Action Icons and CSS . 123 6.4. Names and Descriptions. 125 6.5. Eager rendering . 126 7. Object Management (CRUD) . 128 7.1. Instantiating . 128 7.2. Persisting . 129 7.3. Finding Objects . 130 7.4. Updating Objects . 131 7.5. Deleting Objects . 132 8. Business Rules . 133 8.1. Visibility ("see it"). 133 8.2. Usability ("use it") . 134 8.3. Validity ("do it") . 134 8.4. Actions . 135 8.5. Side effects . 135 9. Drop Downs and Defaults . 137 9.1. Choices and Default . .. -
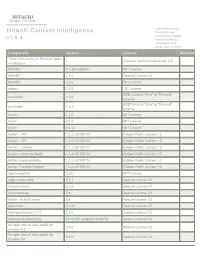
HCI OSS Licenses V1.6.4.Pdf
HITACHI Inspire the Next 2535 Augustine Drive Santa Clara, CA 95054 USA Contact Information : Hitachi Content Intelligence Product Manager Lumada Data Catalog v 1 . 6 . 4 Hitachi Vantara LLC 2535 Augustine Dr. Santa Clara CA 95054 Component Version License Modified "Java Concurrency in Practice" book 1 Creative Commons Attribution 2.5 annotations #NAME? 0.1.38-webpack MIT License #NAME? 2.3.0 Apache License 2.0 #NAME? 3.3.0 MIT License abbrev 1.0.9 ISC License BSD 3-clause "New" or "Revised" ace-builds 1.2.8 License BSD 3-clause "New" or "Revised" ace-builds 1.3.3 License Acorn 1.2.2 MIT License Acorn 2.7.0 MIT License Acorn 4.0.13 MIT License Aether :: API 1.0.2.v20150114 Eclipse Public License 1.0 Aether :: SPI 1.0.2.v20150114 Eclipse Public License 1.0 Aether :: Utilities 1.0.2.v20150114 Eclipse Public License 1.0 Aether Connector Basic 1.0.2.v20150114 Eclipse Public License 1.0 Aether Implementation 1.0.2.v20150114 Eclipse Public License 1.0 Aether Transport Wagon 1.0.2.v20150114 Eclipse Public License 1.0 agentkeepalive 2.2.0 MIT License aggs-matrix-stats 5.3.1 Apache License 2.0 airbnb/chronos 2.3.3 Apache License 2.0 aircompressor 0.8 Apache License 2.0 Airline - io.airlift:airline 0.6 Apache License 2.0 akka-actor 2.3.16 Apache License 2.0 akka-persistence_2.11 2.5.5 Apache License 2.0 alibaba/x-deeplearning 20181224-snapshot-ffc8b733 Apache License 2.0 An open source Java toolkit for 0.9.0 Apache License 2.0 Amazon S3 An open source Java toolkit for 0.9.4 Apache License 2.0 Amazon S3 HITACHI Inspire the Next 2535 Augustine Drive