Authors' Response
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Climate Disasters in the Philippines: a Case Study of the Immediate Causes and Root Drivers From
Zhzh ENVIRONMENT & NATURAL RESOURCES PROGRAM Climate Disasters in the Philippines: A Case Study of Immediate Causes and Root Drivers from Cagayan de Oro, Mindanao and Tropical Storm Sendong/Washi Benjamin Franta Hilly Ann Roa-Quiaoit Dexter Lo Gemma Narisma REPORT NOVEMBER 2016 Environment & Natural Resources Program Belfer Center for Science and International Affairs Harvard Kennedy School 79 JFK Street Cambridge, MA 02138 www.belfercenter.org/ENRP The authors of this report invites use of this information for educational purposes, requiring only that the reproduced material clearly cite the full source: Franta, Benjamin, et al, “Climate disasters in the Philippines: A case study of immediate causes and root drivers from Cagayan de Oro, Mindanao and Tropical Storm Sendong/Washi.” Belfer Center for Science and International Affairs, Cambridge, Mass: Harvard University, November 2016. Statements and views expressed in this report are solely those of the authors and do not imply endorsement by Harvard University, the Harvard Kennedy School, or the Belfer Center for Science and International Affairs. Design & Layout by Andrew Facini Cover photo: A destroyed church in Samar, Philippines, in the months following Typhoon Yolanda/ Haiyan. (Benjamin Franta) Copyright 2016, President and Fellows of Harvard College Printed in the United States of America ENVIRONMENT & NATURAL RESOURCES PROGRAM Climate Disasters in the Philippines: A Case Study of Immediate Causes and Root Drivers from Cagayan de Oro, Mindanao and Tropical Storm Sendong/Washi Benjamin Franta Hilly Ann Roa-Quiaoit Dexter Lo Gemma Narisma REPORT NOVEMBER 2016 The Environment and Natural Resources Program (ENRP) The Environment and Natural Resources Program at the Belfer Center for Science and International Affairs is at the center of the Harvard Kennedy School’s research and outreach on public policy that affects global environment quality and natural resource management. -

Philippines: Typhoons
Emergency Appeal no. MDRPH002 PHILIPPINES: TC-2006-000175-PHL 4 December 2006 TYPHOONS The Federation’s mission is to improve the lives of vulnerable people by mobilizing the power of humanity. It is the world’s largest humanitarian organization and its millions of volunteers are active in over 185 countries. In Brief THIS REVISED EMERGENCY APPEAL SEEKS CHF 8,833,789 (USD 7,318,798 OR EUR 5,552,350) IN CASH, KIND, OR SERVICES TO SUPPORT THE PHILIPPINE NATIONAL RED CROSS IN ASSISTING 200,000 BENEFICIARIES FOR NINE MONTHS. Appeal history: · Disaster Relief Emergency Funds (DREF) allocated in September: CHF 100,000 (USD 80,000 or EUR 63,291). This DREF will be reimbursed through this Appeal. · Launched on 2 October 2006 for CHF 5,704,261 (USD 4,563,408 or EUR 3,610,292) for three months to assist 126,000 beneficiaries. · Revised 19 October 2006 for CHF 5,704,261 (USD 4,563,408 or EUR 3,610,292) for nine months to assist 126,000 beneficiaries. · 1 December 2006, Disaster Relief Emergency Funds (DREF) allocated: An aerial view of the devastation wrought by typhoon Durian. CHF 100,000 (USD 80,000 or EUR 63,291). This appeal re-launch is to take into account the fourth successive typhoon to hit the Philippines within the past two months. The extent of the impact of the latest typhoon, Durian (Reming) is yet to be fully determined. However, initial reports indicate widespread damage caused by the effects of strong wind, rain, floods, mudflow and landslides. A further revision and expansion of the appeal will be undertaken in the coming days based on the assessments of the Philippine National Red Cross (PNRC), the field assessment and coordination team (FACT), the regional disaster response team (RDRT) and the Federation’s country delegation assessment teams currently in the field. -

Summary of 2014 NW Pacific Typhoon Season and Verification of Authors’ Seasonal Forecasts
Summary of 2014 NW Pacific Typhoon Season and Verification of Authors’ Seasonal Forecasts Issued: 27th January 2015 by Dr Adam Lea and Professor Mark Saunders Dept. of Space and Climate Physics, UCL (University College London), UK. Summary The 2014 NW Pacific typhoon season was characterised by activity slightly below the long-term (1965-2013) norm. The TSR forecasts over-predicted activity but mostly to within the forecast error. The Tropical Storm Risk (TSR) consortium presents a validation of their seasonal forecasts for the NW Pacific basin ACE index, numbers of intense typhoons, numbers of typhoons and numbers of tropical storms in 2014. These forecasts were issued on the 6th May, 3rd July and the 5th August 2014. The 2014 NW Pacific typhoon season ran from 1st January to 31st December. Features of the 2014 NW Pacific Season • Featured 23 tropical storms, 12 typhoons, 8 intense typhoons and a total ACE index of 273. These numbers were respectively 12%, 25%, 0% and 7% below their corresponding long-term norms. Seven out of the last eight years have now had a NW Pacific ACE index below the 1965-2013 climate norm value of 295. • The peak months of August and September were unusually quiet, with only one typhoon forming within the basin (Genevieve formed in the NE Pacific and crossed into the NW Pacific basin as a hurricane). Since 1965 no NW Pacific typhoon season has seen less than two typhoons develop within the NW Pacific basin during August and September. This lack of activity in 2014 was in part caused by an unusually strong and persistent suppressing phase of the Madden-Julian Oscillation. -

The Impact of Tropical Cyclone Hayan in the Philippines: Contribution of Spatial Planning to Enhance Adaptation in the City of Tacloban
UNIVERSIDADE DE LISBOA FACULDADE DE CIÊNCIAS Faculdade de Ciências Faculdade de Ciências Sociais e Humanas Faculdade de Letras Faculdade de Ciências e Tecnologia Instituto de Ciências Sociais Instituto Superior de Agronomia Instituto Superior Técnico The impact of tropical cyclone Hayan in the Philippines: Contribution of spatial planning to enhance adaptation in the city of Tacloban Doutoramento em Alterações Climáticas e Políticas de Desenvolvimento Sustentável Especialidade em Ciências do Ambiente Carlos Tito Santos Tese orientada por: Professor Doutor Filipe Duarte Santos Professor Doutor João Ferrão Documento especialmente elaborado para a obtenção do grau de Doutor 2018 UNIVERSIDADE DE LISBOA FACULDADE DE CIÊNCIAS Faculdade de Ciências Faculdade de Ciências Sociais e Humanas Faculdade de Letras Faculdade de Ciências e Tecnologia Instituto de Ciências Sociais Instituto Superior de Agronomia Instituto Superior Técnico The impact of tropical cyclone Haiyan in the Philippines: Contribution of spatial planning to enhance adaptation in the city of Tacloban Doutoramento em Alterações Climáticas e Políticas de Desenvolvimento Sustentável Especialidade em Ciências do Ambiente Carlos Tito Santos Júri: Presidente: Doutor Rui Manuel dos Santos Malhó; Professor Catedrático Faculdade de Ciências da Universidade de Lisboa Vogais: Doutor Carlos Daniel Borges Coelho; Professor Auxiliar Departamento de Engenharia Civil da Universidade de Aveiro Doutor Vítor Manuel Marques Campos; Investigador Auxiliar Laboratório Nacional de Engenharia Civil(LNEC) -

Typhoon Haiyan Action Plan November 2013
Philippines: Typhoon Haiyan Action Plan November 2013 Prepared by the Humanitarian Country Team 100% 92 million total population of the Philippines (as of 2010) 54% 50 million total population of the nine regions hit by Typhoon Haiyan 13% 11.3 million people affected in these nine regions OVERVIEW (as of 12 November) (12 November 2013 OCHA) SITUATION On the morning of 8 November, category 5 Typhoon Haiyan (locally known as Yolanda ) made a direct hit on the Philippines, a densely populated country of 92 million people, devastating areas in 36 provinces. Haiyan is possibly the most powerful storm ever recorded . The typhoon first ma de landfall at 673,000 Guiuan, Eastern Samar province, with wind speeds of 235 km/h and gusts of 275 km/h. Rain fell at rates of up to 30 mm per hour and massive storm displaced people surges up to six metres high hit Leyte and Samar islands. Many cities and (as of 12 November) towns experienced widespread destruction , with as much as 90 per cent of housing destroyed in some areas . Roads are blocked, and airports and seaports impaired; heavy ships have been thrown inland. Water supply and power are cut; much of the food stocks and other goods are d estroyed; many health facilities not functioning and medical supplies quickly being exhausted. Affected area: Regions VIII (Eastern Visayas), VI (Western Visayas) and Total funding requirements VII (Central Visayas) are hardest hit, according to current information. Regions IV-A (CALABARZON), IV-B ( MIMAROPA ), V (Bicol), X $301 million (Northern Mindanao), XI (Davao) and XIII (Caraga) were also affected. -

Pragmatic Use of Ict for Effective Disaster Management Governance and Participation
INTERNATIONAL JOURNAL OF eBUSINESS AND eGOVERNMENT STUDIES Vol 1, No 2, 2009 ISSN: 2146-0744 (Online) PRAGMATIC USE OF ICT FOR EFFECTIVE DISASTER MANAGEMENT GOVERNANCE AND PARTICIPATION Maria Victoria G. PINEDA Information Technology Department, De La Salle University 2401 Taft Avenue, Manila, Philippines E-mail: [email protected] Abstract In an archipelago situated in Southeast Asia, the Philippines with close proximity to the Pacific Ocean, is a typhoon and tropical cyclone-friendly country. While the citizens across the islands are very familiar with typhoon behaviors, anticipation of the probable disaster may still be underestimated and conventional preparation would not be enough. A disaster is a form of chaos that is very inimitable, unpredictable and pertains to real-time monitoring before, during and after it takes place. And ICT can take a strategic role as far as preparedness, response and rehabilitation efforts are to be made. This paper intends to impart two pragmatic ways of utilizing ICT in disaster governance. First is facilitating cooperation among the different government agencies through a web-based Disaster Coordination System to address disaster management. A comprehensive workflow facility that permits remote exchange of data and transactions among regional centers, local municipalities and the national disaster coordinating council is the major feature of the system. Second is applying concepts of human resources but at the same time addressing the peculiarities of a volunteer in the design of a volunteer management system for the Philippine National Red Cross. The system utilizes web and mobile technologies. Both systems are perceived to be proactive and dependable references for policy-making. -

Philippines: Typhoon Fengshen
Emergency appeal n° MDRPH004 Philippines: GLIDE n° TC-2008-000093-PHL Operations update n° 4 31 December 2008 Typhoon Fengshen Period covered by this Ops Update: 24 September to 15 December 2008 Appeal target (current): CHF 8,310,213 (USD 8 million or EUR 5.1 million); with this Operations Update, the appeal has been revised to CHF 1,996,287 (USD 1,878,149 or EUR 1,343,281) <click here to view the attached Revised Emergency Appeal Budget> Appeal coverage: To date, the appeal is 87%. Funds are urgently needed to enable the Philippine National Red Cross to provide assistance to those affected by the typhoon.; <click here to go directly to the updated donor response A transitional shelter house in the midst of being built in the municipality of report, or here to link to contact Santa Barbara, Ilo Ilo province. Photo: Philippine National Red Cross. details > Appeal history: • A preliminary emergency appeal was launched on 24 June 2008 for CHF 8,310,213 (USD 8 million or EUR 5.1 million) for 12 months to assist 6,000 families. • Disaster Relief Emergency Fund (DREF): CHF 200,000 was allocated from the International Federation’s DREF. Summary: The onslaught of typhoon Fengshen which hit the Philippines on 18 June 2008, followed by floods and landslides, have left in its wake urgent needs among poverty-stricken communities. According to the National Disaster Coordinating Council (NDCC), approximately four million people have been affected through out the country by typhoon Fengshen. More than 81,000 houses were totally destroyed and a further 326,321 seriously damaged. -

Disaster Preparedness Level, Graph Showed the Data in %, Developed on the Basis of Survey Conducted in Region Vi
2014 Figures Nature Begins Where Human Predication Ends Typhoon Frank (Fengshen) 17th to 27th June, 2008 Credit: National Institute of Geological Sciences, University of the Philippines, 2012 Tashfeen Siddique – Research Fellow AIM – Stephen Zuellig Graduate School of Development Management 8/15/2014 Nature Begins Where Human Predication Ends Contents Acronyms and Abbreviations: ...................................................................................................... iv Brief History ........................................................................................................................................ 1 Philippines Climate ........................................................................................................................... 2 Chronology of Typhoon Frank ....................................................................................................... 3 Forecasting went wrong .................................................................................................................. 7 Warning and Precautionary Measures ...................................................................................... 12 Typhoon Climatology-Science ..................................................................................................... 14 How Typhoon Formed? .............................................................................................................. 14 Typhoon Structure ..................................................................................................................... -
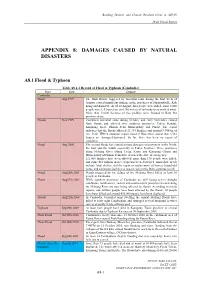
Appendix 8: Damages Caused by Natural Disasters
Building Disaster and Climate Resilient Cities in ASEAN Draft Finnal Report APPENDIX 8: DAMAGES CAUSED BY NATURAL DISASTERS A8.1 Flood & Typhoon Table A8.1.1 Record of Flood & Typhoon (Cambodia) Place Date Damage Cambodia Flood Aug 1999 The flash floods, triggered by torrential rains during the first week of August, caused significant damage in the provinces of Sihanoukville, Koh Kong and Kam Pot. As of 10 August, four people were killed, some 8,000 people were left homeless, and 200 meters of railroads were washed away. More than 12,000 hectares of rice paddies were flooded in Kam Pot province alone. Floods Nov 1999 Continued torrential rains during October and early November caused flash floods and affected five southern provinces: Takeo, Kandal, Kampong Speu, Phnom Penh Municipality and Pursat. The report indicates that the floods affected 21,334 families and around 9,900 ha of rice field. IFRC's situation report dated 9 November stated that 3,561 houses are damaged/destroyed. So far, there has been no report of casualties. Flood Aug 2000 The second floods has caused serious damages on provinces in the North, the East and the South, especially in Takeo Province. Three provinces along Mekong River (Stung Treng, Kratie and Kompong Cham) and Municipality of Phnom Penh have declared the state of emergency. 121,000 families have been affected, more than 170 people were killed, and some $10 million in rice crops has been destroyed. Immediate needs include food, shelter, and the repair or replacement of homes, household items, and sanitation facilities as water levels in the Delta continue to fall. -

North Pacific, on August 31
Marine Weather Review MARINE WEATHER REVIEW – NORTH PACIFIC AREA May to August 2002 George Bancroft Meteorologist Marine Prediction Center Introduction near 18N 139E at 1200 UTC May 18. Typhoon Chataan: Chataan appeared Maximum sustained winds increased on MPC’s oceanic chart area just Low-pressure systems often tracked from 65 kt to 120 kt in the 24-hour south of Japan at 0600 UTC July 10 from southwest to northeast during period ending at 0000 UTC May 19, with maximum sustained winds of 65 the period, while high pressure when th center reached 17.7N 140.5E. kt with gusts to 80 kt. Six hours later, prevailed off the west coast of the The system was briefly a super- the Tenaga Dua (9MSM) near 34N U.S. Occasionally the high pressure typhoon (maximum sustained winds 140E reported south winds of 65 kt. extended into the Bering Sea and Gulf of 130 kt or higher) from 0600 to By 1800 UTC July 10, Chataan of Alaska, forcing cyclonic systems 1800 UTC May 19. At 1800 UTC weakened to a tropical storm near coming off Japan or eastern Russia to May 19 Hagibis attained a maximum 35.7N 140.9E. The CSX Defender turn more north or northwest or even strength of 140-kt (sustained winds), (KGJB) at that time encountered stall. Several non-tropical lows with gusts to 170 kt near 20.7N southwest winds of 55 kt and 17- developed storm-force winds, mainly 143.2E before beginning to weaken. meter seas (56 feet). The system in May and June. -

Observation and Simulation of the Genesis of Typhoon Fengshen (2008)
1 8D.7 GENESIS OF TYPHOON FENGSHEN (2008) FROM VORTEX SUPERPOSITION: PALAU FIELD EXPERIMENT AND A GLOBAL CLOUD-RESOLVING SIMULATION Hiroyuki Yamada1, Tomoe Nasuno1, Wataru Yanase2, Ryuichi Shirooka1, and Masaki Satoh2,1 1Japan Agency for Marine-Earth Science and Technology, Yokosuka, Japan 2Atmosphere and Ocean Research Institute, University of Tokyo, Kashiwa, Japan 1. INTRODUCTION One of the greatest remaining challenges in the study of tropical cyclone is to understand and predict their formation from weak cyclonic disturbances. In the western tropical Pacific, although many previous studies pointed out the participation of large- and synoptic-scale cyclonic disturbances in tropical cyclogenesis (e.g., Sobel and Bretherton 1999; Dickinson and Molinari 2002; Fu et al. 2007), little is known about mechanisms governing their transformation into a deep warm-core vortex. In considerable part, the Figure 1. (a) The observed and simulated tracks of Typhoon Fengshen. The 150-km and 300-km lack of understanding in this area stems from a ranges of Doppler radars are shown by orange lack of observation over the ocean. Moreover, circles. Axes of the rotated Cartesian (XR-YR) insufficient computer resource that limits horizontal coordinates are drawn by green arrows. (b) Time domain of numerical models prevents performing series of the minimum pressure at surface. (c) A a cloud-resolving simulation of multiscale time-height plot of the potential vorticity, averaged processes ranging from convective to large scale. within 100-km radius from the surface vortex center. To overcome these problems, we carried out a The period in which the incipient surface vortex field experiment with two Doppler radars in the transformed into a deep typhoon vortex (i.e., 0300— Pacific warm pool, and applied a state-of-the-art 1200 UTC 18 June) is highlighted. -

Minnesota Weathertalk Newsletter for Friday, January 3, 2014
Minnesota WeatherTalk Newsletter for Friday, January 3, 2014 To: MPR's Morning Edition From: Mark Seeley, Univ. of Minnesota, Dept of Soil, Water, and Climate Subject: Minnesota WeatherTalk Newsletter for Friday, January 3, 2014 HEADLINES -December 2013 was climate near historic for northern communities -Cold start to 2014 -Weekly Weather potpourri -MPR listener questions -Almanac for January 3rd -Past weather -Outlook Topic: December 2013 near historic for far north In assessing the climate for December 2013 it should be said that from the standpoint of cold temperatures the month was quite historic for many northern Minnesota communities, especially due to the Arctic cold that prevailed over the last few days of the month. Minnesota reported the coldest temperature in the 48 contiguous states thirteen times during the month, the highest frequency among all 48 states. Many northern observers saw overnight temperatures drop below -30 degrees F on several occasions. The mean monthly temperature for December from several communities ranked among the coldest Decembers ever. A sample listing includes: -4.1 F at International Falls, 2nd coldest all-time 4.6 F at Duluth, 8th coldest all-time 0.1 F at Crookston, 3rd coldest all-time -3.1 F at Roseau, 3rd coldest all-time 0.3 F at Park Rapids, 3rd coldest all-time -4.4 F at Embarrass, 2nd coldest all-time -4.1 F at Baudette, coldest all-time -3.7 F at Warroad, coldest all-time -2.9 F at Babbitt, coldest all-time -2.8 F at Gunflint Lake, coldest all-time In addition, some communities reported an exceptionally snowy month of December.