Zookeeper.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Scalable Cloud Computing
Scalable Cloud Computing Keijo Heljanko Department of Computer Science and Engineering School of Science Aalto University [email protected] 2.10-2013 Mobile Cloud Computing - Keijo Heljanko (keijo.heljanko@aalto.fi) 1/57 Guest Lecturer I Guest Lecturer: Assoc. Prof. Keijo Heljanko, Department of Computer Science and Engineering, Aalto University, I Email: [email protected] I Homepage: https://people.aalto.fi/keijo_heljanko I For more info into today’s topic, attend the course: “T-79.5308 Scalable Cloud Computing” Mobile Cloud Computing - Keijo Heljanko (keijo.heljanko@aalto.fi) 2/57 Business Drivers of Cloud Computing I Large data centers allow for economics of scale I Cheaper hardware purchases I Cheaper cooling of hardware I Example: Google paid 40 MEur for a Summa paper mill site in Hamina, Finland: Data center cooled with sea water from the Baltic Sea I Cheaper electricity I Cheaper network capacity I Smaller number of administrators / computer I Unreliable commodity hardware is used I Reliability obtained by replication of hardware components and a combined with a fault tolerant software stack Mobile Cloud Computing - Keijo Heljanko (keijo.heljanko@aalto.fi) 3/57 Cloud Computing Technologies A collection of technologies aimed to provide elastic “pay as you go” computing I Virtualization of computing resources: Amazon EC2, Eucalyptus, OpenNebula, Open Stack Compute, . I Scalable file storage: Amazon S3, GFS, HDFS, . I Scalable batch processing: Google MapReduce, Apache Hadoop, PACT, Microsoft Dryad, Google Pregel, Spark, ::: I Scalable datastore: Amazon Dynamo, Apache Cassandra, Google Bigtable, HBase,. I Distributed Coordination: Google Chubby, Apache Zookeeper, . I Scalable Web applications hosting: Google App Engine, Microsoft Azure, Heroku, . -

Zookeeper Administrator's Guide
ZooKeeper Administrator's Guide A Guide to Deployment and Administration by Table of contents 1 Deployment........................................................................................................................ 2 1.1 System Requirements....................................................................................................2 1.2 Clustered (Multi-Server) Setup.....................................................................................2 1.3 Single Server and Developer Setup..............................................................................4 2 Administration.................................................................................................................... 4 2.1 Designing a ZooKeeper Deployment........................................................................... 5 2.2 Provisioning.................................................................................................................. 6 2.3 Things to Consider: ZooKeeper Strengths and Limitations..........................................6 2.4 Administering................................................................................................................6 2.5 Maintenance.................................................................................................................. 6 2.6 Supervision....................................................................................................................7 2.7 Monitoring.....................................................................................................................8 -

Talend Open Studio for Big Data Release Notes
Talend Open Studio for Big Data Release Notes 6.0.0 Talend Open Studio for Big Data Adapted for v6.0.0. Supersedes previous releases. Publication date July 2, 2015 Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks and service marks are the properties of their respective owners. License Agreement The software described in this documentation is licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.html. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. This product includes software developed at AOP Alliance (Java/J2EE AOP standards), ASM, Amazon, AntlR, Apache ActiveMQ, Apache Ant, Apache Avro, Apache Axiom, Apache Axis, Apache Axis 2, Apache Batik, Apache CXF, Apache Cassandra, Apache Chemistry, Apache Common Http Client, Apache Common Http Core, Apache Commons, Apache Commons Bcel, Apache Commons JxPath, Apache -

HDP 3.1.4 Release Notes Date of Publish: 2019-08-26
Release Notes 3 HDP 3.1.4 Release Notes Date of Publish: 2019-08-26 https://docs.hortonworks.com Release Notes | Contents | ii Contents HDP 3.1.4 Release Notes..........................................................................................4 Component Versions.................................................................................................4 Descriptions of New Features..................................................................................5 Deprecation Notices.................................................................................................. 6 Terminology.......................................................................................................................................................... 6 Removed Components and Product Capabilities.................................................................................................6 Testing Unsupported Features................................................................................ 6 Descriptions of the Latest Technical Preview Features.......................................................................................7 Upgrading to HDP 3.1.4...........................................................................................7 Behavioral Changes.................................................................................................. 7 Apache Patch Information.....................................................................................11 Accumulo........................................................................................................................................................... -

Analysis and Detection of Anomalies in Mobile Devices
Master’s Degree in Informatics Engineering Dissertation Final Report Analysis and detection of anomalies in mobile devices António Carlos Lagarto Cabral Bastos de Lima [email protected] Supervisor: Prof. Dr. Tiago Cruz Co-Supervisor: Prof. Dr. Paulo Simões Date: September 1, 2017 Master’s Degree in Informatics Engineering Dissertation Final Report Analysis and detection of anomalies in mobile devices António Carlos Lagarto Cabral Bastos de Lima [email protected] Supervisor: Prof. Dr. Tiago Cruz Co-Supervisor: Prof. Dr. Paulo Simões Date: September 1, 2017 i Acknowledgements I strongly believe that both nature and nurture playing an equal part in shaping an in- dividual, and that in the end, it is what you do with the gift of life that determines who you are. However, in order to achieve great things motivation alone might just not cut it, and that’s where surrounding yourself with people that want to watch you succeed and better yourself comes in. It makes the trip easier and more enjoyable, and there is a plethora of people that I want to acknowledge for coming this far. First of all, I’d like to thank professor Tiago Cruz for giving me the support, motivation and resources to work on this project. The idea itself started over one of our then semi- regular morning coffee conversations and from there it developed into a full-fledged concept quickly. But this acknowledgement doesn’t start there, it dates a few years back when I first had the pleasure of having him as my teacher in one of the introductory courses. -

Open Source and Third Party Documentation
Open Source and Third Party Documentation Verint.com Twitter.com/verint Facebook.com/verint Blog.verint.com Content Introduction.....................2 Licenses..........................3 Page 1 Open Source Attribution Certain components of this Software or software contained in this Product (collectively, "Software") may be covered by so-called "free or open source" software licenses ("Open Source Components"), which includes any software licenses approved as open source licenses by the Open Source Initiative or any similar licenses, including without limitation any license that, as a condition of distribution of the Open Source Components licensed, requires that the distributor make the Open Source Components available in source code format. A license in each Open Source Component is provided to you in accordance with the specific license terms specified in their respective license terms. EXCEPT WITH REGARD TO ANY WARRANTIES OR OTHER RIGHTS AND OBLIGATIONS EXPRESSLY PROVIDED DIRECTLY TO YOU FROM VERINT, ALL OPEN SOURCE COMPONENTS ARE PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. Any third party technology that may be appropriate or necessary for use with the Verint Product is licensed to you only for use with the Verint Product under the terms of the third party license agreement specified in the Documentation, the Software or as provided online at http://verint.com/thirdpartylicense. You may not take any action that would separate the third party technology from the Verint Product. Unless otherwise permitted under the terms of the third party license agreement, you agree to only use the third party technology in conjunction with the Verint Product. -

Hortonworks Data Platform Date of Publish: 2018-09-21
Release Notes 3 Hortonworks Data Platform Date of Publish: 2018-09-21 http://docs.hortonworks.com Contents HDP 3.0.1 Release Notes..........................................................................................3 Component Versions.............................................................................................................................................3 New Features........................................................................................................................................................ 3 Deprecation Notices..............................................................................................................................................4 Terminology.............................................................................................................................................. 4 Removed Components and Product Capabilities.....................................................................................4 Unsupported Features........................................................................................................................................... 4 Technical Preview Features......................................................................................................................4 Upgrading to HDP 3.0.1...................................................................................................................................... 5 Before you begin..................................................................................................................................... -

Talend ESB Development Guide
Talend ESB Development Guide 7.0.1 Talend ESB Adapted for v7.0.1. Supersedes previous releases. Publication date: April 13, 2018 Copyright © 2018 Talend Inc. All rights reserved. Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ This document may include documentation produced at The Apache Software Foundation which is licensed under The Apache License 2.0. Notices Talend and Talend ESB are trademarks of Talend, Inc. Apache CXF, CXF, Apache Karaf, Karaf, Apache Cellar, Cellar, Apache Camel, Camel, Apache Maven, Maven, Apache Archiva, Archiva, Apache Syncope, Syncope, Apache ActiveMQ, ActiveMQ, Apache Log4j, Log4j, Apache Felix, Felix, Apache ServiceMix, ServiceMix, Apache Ant, Ant, Apache Derby, Derby, Apache Tomcat, Tomcat, Apache ZooKeeper, ZooKeeper, Apache Jackrabbit, Jackrabbit, Apache Santuario, Santuario, Apache DS, DS, Apache Avro, Avro, Apache Abdera, Abdera, Apache Chemistry, Chemistry, Apache CouchDB, CouchDB, Apache Kafka, Kafka, Apache Lucene, Lucene, Apache MINA, MINA, Apache Velocity, Velocity, Apache FOP, FOP, Apache HBase, HBase, Apache Hadoop, Hadoop, Apache Shiro, Shiro, Apache Axiom, Axiom, Apache Neethi, Neethi, Apache WSS4J, WSS4J are trademarks of The Apache Foundation. Eclipse Equinox is a trademark of the Eclipse Foundation, Inc. SoapUI is a trademark of SmartBear Software. Hyperic is a trademark -

Securekeeper: Confidential Zookeeper Using Intel
SecureKeeper: Confidential ZooKeeper using Intel SGX Stefan Brenner Colin Wulf David Goltzsche TU Braunschweig, Germany TU Braunschweig, Germany TU Braunschweig, Germany [email protected] [email protected] [email protected] Nico Weichbrodt Matthias Lorenz Christof Fetzer TU Braunschweig, Germany TU Braunschweig, Germany TU Dresden, Germany [email protected] [email protected] [email protected] Peter Pietzuch Rüdiger Kapitza Imperial College London, UK TU Braunschweig, Germany [email protected] [email protected] ABSTRACT 1. INTRODUCTION Cloud computing, while ubiquitous, still suffers from trust Cloud computing has become ubiquitous due to its bene- issues, especially for applications managing sensitive data. fits to both cloud customers and providers [1]. Using public Third-party coordination services such as ZooKeeper and cloud resources, however, requires customers to fully trust Consul are fundamental building blocks for cloud applica- the provided software and hardware stacks as well as the tions, but are exposed to potentially sensitive application cloud administrators. This forms an inhibitor when sensi- data. Recently, hardware trust mechanisms such as Intel's tive data must be processed [2, 3]. Software Guard Extensions (SGX) offer trusted execution With Software Guard Extensions (SGX), Intel recently re- environments to shield application data from untrusted soft- leased a new technology [4] for addressing trust issues that ware, including the privileged Operating System (OS) and customers face when outsourcing services to off-site loca- hypervisors. Such hardware support suggests new options tions. Based on an instruction set extension, it allows the for securing third-party coordination services. -

Technology Overview
Big Data Technology Overview Term Description See Also Big Data - the 5 Vs Everyone Must Volume, velocity and variety. And some expand the definition further to include veracity 3 Vs Know and value as well. 5 Vs of Big Data From Wikipedia, “Agile software development is a group of software development methods based on iterative and incremental development, where requirements and solutions evolve through collaboration between self-organizing, cross-functional teams. Agile The Agile Manifesto It promotes adaptive planning, evolutionary development and delivery, a time-boxed iterative approach, and encourages rapid and flexible response to change. It is a conceptual framework that promotes foreseen tight iterations throughout the development cycle.” A data serialization system. From Wikepedia, Avro Apache Avro “It is a remote procedure call and serialization framework developed within Apache's Hadoop project. It uses JSON for defining data types and protocols, and serializes data in a compact binary format.” BigInsights Enterprise Edition provides a spreadsheet-like data analysis tool to help Big Insights IBM Infosphere Biginsights organizations store, manage, and analyze big data. A scalable multi-master database with no single points of failure. Cassandra Apache Cassandra It provides scalability and high availability without compromising performance. Cloudera Inc. is an American-based software company that provides Apache Hadoop- Cloudera Cloudera based software, support and services, and training to business customers. Wikipedia - Data Science Data science The study of the generalizable extraction of knowledge from data IBM - Data Scientist Coursera Big Data Technology Overview Term Description See Also Distributed system developed at Google for interactively querying large datasets. Dremel Dremel It empowers business analysts and makes it easy for business users to access the data Google Research rather than having to rely on data engineers. -

Hadoop Programming Options
"Web Age Speaks!" Webinar Series Hadoop Programming Options Introduction Mikhail Vladimirov Director, Curriculum Architecture [email protected] Web Age Solutions Providing a broad spectrum of regular and customized training classes in programming, system administration and architecture to our clients across the world for over ten years ©WebAgeSolutions.com 2 Overview of Talk Hadoop Overview Hadoop Analytics Systems HDFS and MapReduce v1 & v2 (YARN) Hive Sqoop ©WebAgeSolutions.com 3 Hadoop Programming Options Hadoop Ecosystem Hadoop Hadoop is a distributed fault-tolerant computing platform written in Java Modeled after shared-nothing, massively parallel processing (MPP) system design Hadoop's design was influenced by ideas published in Google File System (GFS) and MapReduce white papers Hadoop can be used as a data hub, data warehouse or an analytic platform ©WebAgeSolutions.com 5 Hadoop Core Components The Hadoop project is made up of three main components: Common • Contains Hadoop infrastructure elements (interfaces with HDFS, system libraries, RPC connectors, Hadoop admin scripts, etc.) Hadoop Distributed File System • Hadoop Distributed File System (HDFS) running on clusters of commodity hardware built around the concept: load once and read many times MapReduce • A distributed data processing framework used as data analysis system ©WebAgeSolutions.com 6 Hadoop Simple Definition In a nutshell, Hadoop is a distributed computing framework that consists of: Reliable data storage (provided via HDFS) Analysis system -
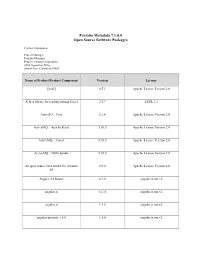
Pentaho Metadata 7.1.0.0 Open Source Software Packages
Pentaho Metadata 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho Metadata Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Component Version License [ini4j] 0.5.1 Apache License Version 2.0 A Java library for reading/writing Excel 2.5.7 LGPL 2.1 ActiveIO :: Core 3.1.4 Apache License Version 2.0 ActiveMQ :: Apache Karaf 5.10.0 Apache License Version 2.0 ActiveMQ :: Camel 5.10.0 Apache License Version 2.0 ActiveMQ :: OSGi bundle 5.10.0 Apache License Version 2.0 An open source Java toolkit for Amazon 0.9.0 Apache License Version 2.0 S3 Angular UI Router 0.3.0 angular.js.mit.v2 angular.js 1.2.15 angular.js.mit.v2 angular.js 1.5.8 angular.js.mit.v2 angular-animate-1.5.6 1.5.6 angular.js.mit.v2 Name of Product/Product Component Version License angular-route 1.5.6 angular.js.mit.v2 angular-sanitize-1.5.6 1.5.6 angular.js.mit.v2 angular-translate 2.3.0 angular.js.mit.v2 angular-translate-2.12.1 2.12.1 angular.bootstrap.mit.v2 angular-translate-2.12.1 2.12.1 angular.js.mit.v2 AngularUI Bootstrap 0.6.0 angular.bootstrap.mit.v2 AngularUI Bootstrap 1.3.3 angular.bootstrap.mit.v2 Annotation 1.0 1.1.1 Apache License Version 2.0 Annotation 1.1 1.0.1 Apache License Version 2.0 ANTLR 3 Complete 3.5.2 ANTLR License Antlr 3.4 Runtime 3.4 ANTLR License ANTLR, ANother Tool for Language 2.7.7 ANTLR License Recognition AOP Alliance (Java/J2EE AOP standard) 1.0 Public Domain Apache Ant Core 1.9.1 Apache License Version 2.0 Name of Product/Product Component Version License