Simple and General Statistical Profiling With
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction to Debugging the Freebsd Kernel
Introduction to Debugging the FreeBSD Kernel John H. Baldwin Yahoo!, Inc. Atlanta, GA 30327 [email protected], http://people.FreeBSD.org/˜jhb Abstract used either directly by the user or indirectly via other tools such as kgdb [3]. Just like every other piece of software, the The Kernel Debugging chapter of the FreeBSD kernel has bugs. Debugging a ker- FreeBSD Developer’s Handbook [4] covers nel is a bit different from debugging a user- several details already such as entering DDB, land program as there is nothing underneath configuring a system to save kernel crash the kernel to provide debugging facilities such dumps, and invoking kgdb on a crash dump. as ptrace() or procfs. This paper will give a This paper will not cover these topics. In- brief overview of some of the tools available stead, it will demonstrate some ways to use for investigating bugs in the FreeBSD kernel. FreeBSD’s kernel debugging tools to investi- It will cover the in-kernel debugger DDB and gate bugs. the external debugger kgdb which is used to perform post-mortem analysis on kernel crash dumps. 2 Kernel Crash Messages 1 Introduction The first debugging service the FreeBSD kernel provides is the messages the kernel prints on the console when the kernel crashes. When a userland application encounters a When the kernel encounters an invalid condi- bug the operating system provides services for tion (such as an assertion failure or a memory investigating the bug. For example, a kernel protection violation) it halts execution of the may save a copy of the a process’ memory current thread and enters a “panic” state also image on disk as a core dump. -

Software Process Validation: Quantitatively Measuring the Correspondence of a Process to a Model
Software Process Validation: Quantitatively Measuring the Correspondence of a Process to a Model JONATHAN E. COOK New Mexico State University and ALEXANDER L. WOLF University of Colorado To a great extent, the usefulness of a formal model of a software process lies in its ability to accurately predict the behavior of the executing process. Similarly, the usefulness of an executing process lies largely in its ability to fulfill the requirements embodied in a formal model of the process. When process models and process executions diverge, something significant is happening. We have developed techniques for uncovering and measuring the discrepancies between models and executions, which we call process validation. Process validation takes a process execution and a process model, and measures the level of correspon- dence between the two. Our metrics are tailorable and give process engineers control over determining the severity of different types of discrepancies. The techniques provide detailed information once a high-level measurement indicates the presence of a problem. We have applied our process validation methods in an industrial case study, of which a portion is described in this article. Categories and Subject Descriptors: D.2.6 [Software Engineering]: Programming Environ- ments; K.6.3 [Management of Computing and Information Systems]: Software Manage- ment—software development; software maintenance General Terms: Management Additional Key Words and Phrases: Balboa, process validation, software process, tools This work was supported in part by the National Science Foundation under grants CCR-93- 02739 and CCR-9804067, and the Air Force Materiel Command, Rome Laboratory, and the Defense Advanced Research Projects Agency under Contract Number F30602-94-C-0253. -

Oracle® Developer Studio 12.5
® Oracle Developer Studio 12.5: C User's Guide Part No: E60745 June 2017 Oracle Developer Studio 12.5: C User's Guide Part No: E60745 Copyright © 2016, 2017, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -

Using the GNU Compiler Collection (GCC)
Using the GNU Compiler Collection (GCC) Using the GNU Compiler Collection by Richard M. Stallman and the GCC Developer Community Last updated 23 May 2004 for GCC 3.4.6 For GCC Version 3.4.6 Published by: GNU Press Website: www.gnupress.org a division of the General: [email protected] Free Software Foundation Orders: [email protected] 59 Temple Place Suite 330 Tel 617-542-5942 Boston, MA 02111-1307 USA Fax 617-542-2652 Last printed October 2003 for GCC 3.3.1. Printed copies are available for $45 each. Copyright c 1988, 1989, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with the Invariant Sections being \GNU General Public License" and \Funding Free Software", the Front-Cover texts being (a) (see below), and with the Back-Cover Texts being (b) (see below). A copy of the license is included in the section entitled \GNU Free Documentation License". (a) The FSF's Front-Cover Text is: A GNU Manual (b) The FSF's Back-Cover Text is: You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development. i Short Contents Introduction ...................................... 1 1 Programming Languages Supported by GCC ............ 3 2 Language Standards Supported by GCC ............... 5 3 GCC Command Options ......................... -

Software Analysis Handbook: Software Complexity Analysis and Software Reliability Estimation and Prediction
Technical Memorandum 104799 Software Analysis Handbook: Software Complexity Analysis and Software Reliability Estimation and Prediction Alice T. Lee Todd Gunn (NASA-TM-I04799) SOFTWARE ANALYSIS N95-I1914 Tuan Pham HANDBOOK: SOFTWARE COMPLEXITY Ron Ricaldi ANALYSIS AND SOFTWARE RELIABILITY ESTIMATION AND PREDICTION (NASA. Unclas Johnson Space Center) 96 p G3159 0023056 August 1994 ..0 National Aeronautics and Space Administration Technical Memorandum 104799 Software Analysis Handbook: Software Complexity Analysis and Software Reliability Estimation and Prediction Alice T. Lee Safety, Reliability, & Quaflty Assurance Office Lyndon B. Johnson Space Center Houston, Texas Todd Gunn, Tuan Pham, and Ron Ricaldi Loral Space Information Systems Houston, Texas National Aeronautics and Space Administration Thispublication is available from the NASA Center for AeroSpace Information, 800 Elkridge Landing Road, Linthicum Heights, MD 21090-2934, (301) 621-0390. Summary The purpose of this handbook is to document the software analysis process as it is performed by the Analysis and Risk Assessment Branch of the Safety, Reliability, and Quality Assurance Office at the Johnson Space Center. The handbook also provides a summary of the tools and methodologies used to perform software analysis. This handbook is comprised of two sepa- rate sections describing aspects of software complexity and software reliability estimation and prediction. The body of this document will delineate the background, theories, tools, and analysis procedures of these approaches. Software complexity analysis can provide quantitative information on code to the designing, testing, and maintenance organizations throughout the software life cycle. Diverse information on code structure, critical components, risk areas, testing deficiencies, and opportunities for improvement can be obtained using software complexity analysis. -

Drilling Network Stacks with Packetdrill
Drilling Network Stacks with packetdrill NEAL CARDWELL AND BARATH RAGHAVAN Neal Cardwell received an M.S. esting and troubleshooting network protocols and stacks can be in Computer Science from the painstaking. To ease this process, our team built packetdrill, a tool University of Washington, with that lets you write precise scripts to test entire network stacks, from research focused on TCP and T the system call layer down to the NIC hardware. packetdrill scripts use a Web performance. He joined familiar syntax and run in seconds, making them easy to use during develop- Google in 2002. Since then he has worked on networking software for google.com, the ment, debugging, and regression testing, and for learning and investigation. Googlebot web crawler, the network stack in Have you ever had the experience of staring at a long network trace, trying to figure out what the Linux kernel, and TCP performance and on earth went wrong? When a network protocol is not working right, how might you find the testing. [email protected] problem and fix it? Although tools like tcpdump allow us to peek under the hood, and tools like netperf help measure networks end-to-end, reproducing behavior is still hard, and know- Barath Raghavan received a ing when an issue has been fixed is even harder. Ph.D. in Computer Science from UC San Diego and a B.S. from These are the exact problems that our team used to encounter on a regular basis during UC Berkeley. He joined Google kernel network stack development. Here we describe packetdrill, which we built to enable in 2012 and was previously a scriptable network stack testing. -

Oracle® Developer Studio 12.6
® Oracle Developer Studio 12.6: C++ User's Guide Part No: E77789 July 2017 Oracle Developer Studio 12.6: C++ User's Guide Part No: E77789 Copyright © 2017, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -
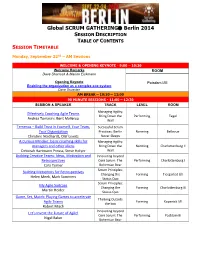
Global SCRUM GATHERING® Berlin 2014
Global SCRUM GATHERING Berlin 2014 SESSION DESCRIPTION TABLE OF CONTENTS SESSION TIMETABLE Monday, September 22nd – AM Sessions WELCOME & OPENING KEYNOTE - 9:00 – 10:30 Welcome Remarks ROOM Dave Sharrock & Marion Eickmann Opening Keynote Potsdam I/III Enabling the organization as a complex eco-system Dave Snowden AM BREAK – 10:30 – 11:00 90 MINUTE SESSIONS - 11:00 – 12:30 SESSION & SPEAKER TRACK LEVEL ROOM Managing Agility: Effectively Coaching Agile Teams Bring Down the Performing Tegel Andrea Tomasini, Bent Myllerup Wall Temenos – Build Trust in Yourself, Your Team, Successful Scrum Your Organization Practices: Berlin Norming Bellevue Christine Neidhardt, Olaf Lewitz Never Sleeps A Curious Mindset: basic coaching skills for Managing Agility: managers and other aliens Bring Down the Norming Charlottenburg II Deborah Hartmann Preuss, Steve Holyer Wall Building Creative Teams: Ideas, Motivation and Innovating beyond Retrospectives Core Scrum: The Performing Charlottenburg I Cara Turner Bohemian Bear Scrum Principles: Building Metaphors for Retrospectives Changing the Forming Tiergarted I/II Helen Meek, Mark Summers Status Quo Scrum Principles: My Agile Suitcase Changing the Forming Charlottenburg III Martin Heider Status Quo Game, Set, Match: Playing Games to accelerate Thinking Outside Agile Teams Forming Kopenick I/II the box Robert Misch Innovating beyond Let's Invent the Future of Agile! Core Scrum: The Performing Postdam III Nigel Baker Bohemian Bear Monday, September 22nd – PM Sessions LUNCH – 12:30 – 13:30 90 MINUTE SESSIONS - 13:30 -

ARM Assembly Shellcode from Zero to ARM Assembly Bind Shellcode
Lab: ARM Assembly Shellcode From Zero to ARM Assembly Bind Shellcode HITBSecConf2018 - Amsterdam 1 Learning Objectives • ARM assembly basics • Writing ARM Shellcode • Registers • System functions • Most common instructions • Mapping out parameters • ARM vs. Thumb • Translating to Assembly • Load and Store • De-Nullification • Literal Pool • Execve() shell • PC-relative Addressing • Reverse Shell • Branches • Bind Shell HITBSecConf2018 - Amsterdam 2 Outline – 120 minutes • ARM assembly basics • Reverse Shell • 15 – 20 minutes • 3 functions • Shellcoding steps: execve • For each: • 10 minutes • 10 minutes exercise • Getting ready for practical part • 5 minutes solution • 5 minutes • Buffer[10] • Bind Shell • 3 functions • 25 minutes exercise HITBSecConf2018 - Amsterdam 3 Mobile and Iot bla bla HITBSecConf2018 - Amsterdam 4 It‘s getting interesting… HITBSecConf2018 - Amsterdam 5 Benefits of Learning ARM Assembly • Reverse Engineering binaries on… • Phones? • Routers? • Cars? • Intel x86 is nice but.. • Internet of Things? • Knowing ARM assembly allows you to • MACBOOKS?? dig into and have fun with various • SERVERS?? different device types HITBSecConf2018 - Amsterdam 6 Benefits of writing ARM Shellcode • Writing your own assembly helps you to understand assembly • How functions work • How function parameters are handled • How to translate functions to assembly for any purpose • Learn it once and know how to write your own variations • For exploit development and vulnerability research • You can brag that you can write your own shellcode instead -

Hardware-Driven Evolution in Storage Software by Zev Weiss A
Hardware-Driven Evolution in Storage Software by Zev Weiss A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Computer Sciences) at the UNIVERSITY OF WISCONSIN–MADISON 2018 Date of final oral examination: June 8, 2018 ii The dissertation is approved by the following members of the Final Oral Committee: Andrea C. Arpaci-Dusseau, Professor, Computer Sciences Remzi H. Arpaci-Dusseau, Professor, Computer Sciences Michael M. Swift, Professor, Computer Sciences Karthikeyan Sankaralingam, Professor, Computer Sciences Johannes Wallmann, Associate Professor, Mead Witter School of Music i © Copyright by Zev Weiss 2018 All Rights Reserved ii To my parents, for their endless support, and my cousin Charlie, one of the kindest people I’ve ever known. iii Acknowledgments I have taken what might be politely called a “scenic route” of sorts through grad school. While Ph.D. students more focused on a rapid graduation turnaround time might find this regrettable, I am glad to have done so, in part because it has afforded me the opportunities to meet and work with so many excellent people along the way. I owe debts of gratitude to a large cast of characters: To my advisors, Andrea and Remzi Arpaci-Dusseau. It is one of the most common pieces of wisdom imparted on incoming grad students that one’s relationship with one’s advisor (or advisors) is perhaps the single most important factor in whether these years of your life will be pleasant or unpleasant, and I feel exceptionally fortunate to have ended up iv with the advisors that I’ve had. -

Proceedings of the Linux Symposium
Proceedings of the Linux Symposium Volume One June 27th–30th, 2007 Ottawa, Ontario Canada Contents The Price of Safety: Evaluating IOMMU Performance 9 Ben-Yehuda, Xenidis, Mostrows, Rister, Bruemmer, Van Doorn Linux on Cell Broadband Engine status update 21 Arnd Bergmann Linux Kernel Debugging on Google-sized clusters 29 M. Bligh, M. Desnoyers, & R. Schultz Ltrace Internals 41 Rodrigo Rubira Branco Evaluating effects of cache memory compression on embedded systems 53 Anderson Briglia, Allan Bezerra, Leonid Moiseichuk, & Nitin Gupta ACPI in Linux – Myths vs. Reality 65 Len Brown Cool Hand Linux – Handheld Thermal Extensions 75 Len Brown Asynchronous System Calls 81 Zach Brown Frysk 1, Kernel 0? 87 Andrew Cagney Keeping Kernel Performance from Regressions 93 T. Chen, L. Ananiev, and A. Tikhonov Breaking the Chains—Using LinuxBIOS to Liberate Embedded x86 Processors 103 J. Crouse, M. Jones, & R. Minnich GANESHA, a multi-usage with large cache NFSv4 server 113 P. Deniel, T. Leibovici, & J.-C. Lafoucrière Why Virtualization Fragmentation Sucks 125 Justin M. Forbes A New Network File System is Born: Comparison of SMB2, CIFS, and NFS 131 Steven French Supporting the Allocation of Large Contiguous Regions of Memory 141 Mel Gorman Kernel Scalability—Expanding the Horizon Beyond Fine Grain Locks 153 Corey Gough, Suresh Siddha, & Ken Chen Kdump: Smarter, Easier, Trustier 167 Vivek Goyal Using KVM to run Xen guests without Xen 179 R.A. Harper, A.N. Aliguori & M.D. Day Djprobe—Kernel probing with the smallest overhead 189 M. Hiramatsu and S. Oshima Desktop integration of Bluetooth 201 Marcel Holtmann How virtualization makes power management different 205 Yu Ke Ptrace, Utrace, Uprobes: Lightweight, Dynamic Tracing of User Apps 215 J. -

Practical and Effective Sandboxing for Non-Root Users
Practical and effective sandboxing for non-root users Taesoo Kim and Nickolai Zeldovich MIT CSAIL Abstract special tools. More importantly, all use cases neither re- quire root privilege nor require modification to the OS MBOX is a lightweight sandboxing mechanism for non- kernel and applications. root users in commodity OSes. MBOX’s sandbox usage model executes a program in the sandbox and prevents Overview MBOX aims to make running a program in a the program from modifying the host filesystem by layer- sandbox as easy as running the program itself. For exam- ing the sandbox filesystem on top of the host filesystem. ple, one can sandbox a program (say wget) by running as At the end of program execution, the user can examine below: changes in the sandbox filesystem and selectively com- mit them back to the host filesystem. MBOX implements $ mbox -- wget google.com ... this by interposing on system calls and provides a variety Network Summary: of useful applications: installing system packages as a > [11279] -> 173.194.43.51:80 > [11279] Create socket(PF_INET,...) non-root user, running unknown binaries safely without > [11279] -> a00::2607:f8b0:4006:803:0 network accesses, checkpointing the host filesystem in- ... Sandbox Root: stantly, and setting up a virtual development environment > /tmp/sandbox-11275 without special tools. Our performance evaluation shows > N:/tmp/index.html [c]ommit, [i]gnore, [d]iff, [l]ist, [s]hell, [q]uit ?> that MBOX imposes CPU overheads of 0.1–45.2% for var- ious workloads. In this paper, we present MBOX’s design, wget is a utility to download files from the web.