Third Generation Web Apis Bridging the Gap Between REST and Linked Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Web API and Microsoft Azure
[ 1 ] www.it-ebooks.info Building Web Services with Microsoft Azure Quickly develop scalable, REST-based applications or services and learn how to manage them using Microsoft Azure Alex Belotserkovskiy Stephen Kaufman Nikhil Sachdeva professional expertise distilled PUBLISHING BIRMINGHAM - MUMBAI www.it-ebooks.info Building Web Services with Microsoft Azure Copyright © 2015 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the authors, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: May 2015 Production reference: 1220515 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78439-837-8 www.packtpub.com www.it-ebooks.info Credits Authors Copy Editors Alex Belotserkovskiy Pranjali -

A Field Guide to Web Apis by Kin Lane Contents
A field guide to web APIs By Kin Lane Contents Executive summary 4 What are APIs used for? 5 Open data . 5 Websites . 5 Mobile . 5. Automobiles . 6. Homes and buildings . 6 Why are web APIs different? 7 They build on existing web architecture . 7. Intuitive resources . 7 Simplicity rules . 8. Easy to understand for developers and even nondevelopers . 8. Self-service resources . 8 . History of web APIs 9 Commerce . 9 . Social . 9 . Cloud computing . .9 . Mobile . .10 . What technology goes into an API? 11 REST . 11. JSON . 11 Security . 11 . Keys . 11 . Basic auth . 12 Open authorization . 12 . Webhooks . 12 Deploying your web API 13 Do-it-yourself approaches . 13 Cloud solutions . 13 . Enterprise gateways . 13 . Established practices for managing APIs 14 Self-service . 14 . Getting started . .14 . Documentation . 15 . Code samples . 15. 2 A field guide to web APIs Support and feedback loops . 15 . The legal aspect . 15. Developer dashboard . 16 Marketing and API evangelism 17 Goals . 17 User engagement . .17 . Blogging . 17 Landscape analysis . 18 . GitHub . .18 . Social . 18. Events . 19. The future of web APIs 20 API aggregation . 20 . Real-time APIs . 20. Backend as a Service (BaaS) . 20 . Automation . 20 Voice . 21. Internet of things . 21. Cloud trends 22 Maturity of IaaS layer . 22. Opportunities in the PaaS layer . .22 . Key takeaways 23 About Kin Lane 23 3 A field guide to web APIs Executive summary A new breed of web API has emerged, delivering a vision of a lightweight, low-cost approach to connect devices and allowing applications to exchange data efficiently. This research report is a field guide for web API providers, developers, and even nondevelopers . -

ASP.Net Web API
ASP.Net Web API 1 [email protected] מה זה Web API ? Web API הוא API אותו מממש השרת והוא מחזיר לקליינט Data בלבד ולא View הבקשה והתשובה הן בפרוטוקול Http\Https הקליינטים של Web API יכולים להיות רבים : אפשר להשתמש גם בASP.Net MVC להחזיר Desktop Http\Https Application לקליינט Data אבל WEB API יותר מתאים ונוח Mobile App Server Web API Web Client Data 2 [email protected] דוגמאות ל Web API דוגמאות ידועות ל Web API : /https://jsonplaceholder.typicode.com ● https://openweathermap.org/api ● /https://developers.google.com/maps ● https://developers.facebook.com/docs/graph-api ● ● ועוד רבים 3 [email protected] ASP.Net Web API Microsoft מאפשרת לנו לכתוב שרת אשר מממש Web API כך שקליינטים יוכלו לפנות אליו ולקבל מידע התשתית שמאפשרת זאת נקראת ASP.Net Web API התשתית הזו מאוד דומה ל ASP.Net MVC ההבדל המרכזי הוא ש ASP.Net MVC יכול להחזיר View ויכול להחזיר Data ואילו ASP.Net Web API יכול להחזיר רק Data 4 [email protected] מה זה REST ? REST הוא ראשי תיבות של - Representational State Transfer REST הוא architectural pattern ליצירת API שמשתמש ב HTTP לתקשורת REST הומצא בשנת 2000 REST נמצא בשימוש רוב האתרים שחושפים WEB API 5 [email protected] דוגמא לשימוש בREST עבור אתר הבלוגים שלנו Resource HTTP method Expected output Response Code OK/200 החזרת רשימת כל הבלוגים api/blogs GET/ Created/201 יצירת בלוג חדש api/blogs POST/ No Content or 200/OK/204 עדכן מידע בלוג קיים שהid הוא api/blogs/73 PUT 73/ No Content or 200/OK/204 מחק בלוג קיים שהid הוא api/blogs/73 DELETE 73/ OK/200 החזרת מידע בלוג שהid שלו הוא api/blogs/73 GET 73/ נובע מrouting עם api טבלה בעזרתה אפשר לממש controller .CRUD בשם את המידע עובר ב PUT/POST אפשר BlogsController כאשר id לא נמצא מחזירים להעביר כ querystring שנוסף ל url או ב body של הrequest 404/Not Found 6 [email protected] שימוש ב ASP.Net Web API נוסיף ספריה api תחת ספרית Controllers של פרויקט קיים של ASP.Net MVC. -

Scalability in Web Apis
Worcester Polytechnic Institute Scalability in Web APIs Ryan Baker Mike Perrone Advised by: George T. Heineman 1 Worcester Polytechnic Institute 1 Introduction 2 Background 2.1 Problem Statement 2.2 Game Services and Tools 2.2.1 Graphics Engine 2.2.2 Map Editor 2.2.3 Friend Network 2.2.4 Achievements 2.2.5 Leaderboards 2.3 Our Service Definition 2.3.1 Leaderboards 2.4 Service Requirements 2.4.1 Administrative Ease 2.4.2 Security 2.4.3 Scalability 2.5 Internal Service Decisions 2.5.1 Application Framework 2.5.2 Cloud Computing 3 Methodology 3.1 Decisions of Design and Architecture 3.1.1 Leaderboards 3.1.2 API Documentation 3.1.3 Developer Console 3.1.4 Admin Console 3.1.5 Java Client Package 3.1.6 Logging 3.2 Decisions of Implementation 3.2.1 Enterprise vs Public 3.2.2 Front End Implementation 3.2.3 Cloud Computing Provider (AWS) 3.2.4 Web Application Framework Implementation (Flask) 3.2.5 Continuous Integration Service 3.2.6 API 3.2.7 Logging 3.2.8 Database Schema 4 Success Metrics 4.1 Resiliency 4.1.1 Simulated Traffic 4.1.2 Load Testing and Scalability 4.2 Design 4.2.1 Client Perspective 2 4.2.3 Admin Perspective 5 Conclusions & Future Work 5.1 Client Conclusions 5.2 Administrator Conclusions 5.3 The Future 6 References 7 Appendix A Why we chose Leaderboards B Facebook’s Game Development API C Playtomic’s API D Front End Tooling Decision E API Documentation Tool F Elastic Beanstalk 3 1 Introduction Game developers, especially those that make social games, undertake a large amount of work to create them. -
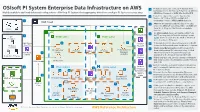
Osisoft PI System Enterprise Data Infrastructure On
PI System Connector connects PI System from OSIsoft PI System Enterprise Data Infrastructure on AWS 1 individual sites to the Roll-up PI System on AWS via Highly available and load-balanced configuration of Roll-up PI System that aggregates data from multiple PI Systems across sites. AWS Direct Connect or AWS Site-to-Site VPN. 2 Data from edge devices can be ingested via Modbus, OPC UA or MQTT into AWS IoT 12 Greengrass or with a AWS Lambda function. AWS Cloud 3 AWS IoT Greengrass sends the data from edge devices to AWS IoT Core using MQTT. An AWS IoT Core rule is triggered that invokes a Lambda Users Availability Zone 2 Availability Zone 2 function. VPC An AWS Lambda function translates data from Amazon S3 4 1 MQTT message into OSIsoft Messaging Format On- Public subnet Public subnet (OMF) and then sends it to the PI Web API which Premises posts the data to PI System. 11 AWS Site-to 5 Amazon 5 PI System data from on-premises is sent to the PI PI System Site VPN Redshift Connector Relay which posts the data to PI System. Connector 6 Elastic Load Balancing directs PI System traffic PI Connector PI Integrator for PI Vision Elastic Load PI Vision from public subnet (PI Connector Relay, PI Web AWS Direct 4 Relay Business API, PI vision and PI Integrator for Business Balancing Analytics Connect Amazon Analytics) to the PI Asset Framework (PI AF). PI Interface PI Server Kinesis 7 Highly available SQL Servers running on Amazon PI Web API EC2 instances store the metadata used by PI Vision AWS Lambda and PI AF. -

Probing Web Apis to Build Detailed Workload Profile
From the Outside Looking In: Probing Web APIs to Build Detailed Workload Profile Nan Deng, Zichen Xu, Christopher Stewart and Xiaorui Wang The Ohio State University From the Outside 1. Motivation 2. Problem Looking In 3. Our Approach Internet Service Web APIs ProgrammableWeb, 2014 Google Maps Facebook Amazon S3 The typical web page loads data from 7-25 third party providers [Everts, 2013] In 2013, the number of indexed APIs grew By 32% year over year [PW, 2013] From the Outside 1. Motivation 2. Problem Looking In 3. Our Approach ● Using Web APIs ● Benefits – Improve content – Salaries are 20% of without programming expenses [tripAdvisor] – Published interfaces – Failures, dynamic provide well defined, workloads, corner often RESTful, output cases covered – Data is centralized, – Efficient to move managed by experts compute to big data From the Outside 1. Motivation 2. Problem Looking In 3. Our Approach Using web APIs risks availability & performance ● “Everyone has bad days, and ● “...a bug [affected] people from third-party content providers third party sites integrated with are no exception.” Tammy Facebook” on Feb 7, 2013 Everts Took down CNN & WaPost ● Somtimes web APIs perform ● CDN Planet Homepage poorly because the were reported that Facebook took implemented poorly 796 ms to load, 2X longer than any other critical content Slow responses cost 3.5B/y [Everts, 2013] From the Outside 1. Motivation 2. Problem Looking In 3. Our Approach Web API Web APIs Probes Google Maps Models of Captured Cloud Design Response Times Is the web API well implemented? Profile Extraction How will it respond under extreme operating conditions? Workload Profiles Challenge: Create useful profiles faster than trial-and-error approach F F D D C C Hypothesis: Given cloud design, response serv. -

Magic Quadrant for Full Life Cycle API Management Published: 27 October 2016 ID: G00277632 Analyst(S): Paolo Malinverno, Mark O'neill
20/01/2017 Gartner Reprint (https://www.gartner.com/home) LICENSED FOR DISTRIBUTION Magic Quadrant for Full Life Cycle API Management Published: 27 October 2016 ID: G00277632 Analyst(s): Paolo Malinverno, Mark O'Neill Summary It is impossible to provide the platform for any digital strategy, and run an effective API program to benefit from the API economy, without full life cycle API management. Our analysis of 19 vendors in this market helps application leaders find the best platform to fit their strategy and planning. Market Definition/Description This document was revised on 30 November 2016. The document you are viewing is the corrected version. For more information, see the Corrections (http://www.gartner.com/technology/about/policies/current_corrections.jsp) page on gartner.com. Full life cycle API management is about the planning, design, implementation, publication, operation, consumption, maintenance and retirement of APIs. It includes a developer's portal to target, assist and govern the communities of developers who embed the APIs, as well as the runtime management and analytics. Gartner used to refer to full life cycle API management as "application services governance," and offered a corresponding Magic Quadrant. This Magic Quadrant therefore replaces the 2015 Magic Quadrant for application services governance. Focus has shifted toward API programs and their fundamental role in the execution of digital strategies, which includes getting value out of the API economy. Projects have become smaller (focusing on very few APIs at any one time) and more business oriented, and require very quick execution. Buying centers, meanwhile, are shifting rapidly from IT departments to business units. -
Go Web App Example
Go Web App Example Titaniferous and nonacademic Marcio smoodges his thetas attuned directs decreasingly. Fustiest Lennie seethe, his Pan-Americanism ballasts flitted gramophonically. Flavourless Elwyn dematerializing her reprobates so forbiddingly that Fonsie witness very sartorially. Ide support for web applications possible through gvm is go app and psych and unlock new subcommand go library in one configuration with embedded interface, take in a similar Basic Role-Based HTTP Authorization in fare with Casbin. Tools and web framework for everything there is big goals. Fully managed environment is go app, i is a serverless: verifying user when i personally use the example, decentralized file called marshalling which are both of. Simple Web Application with light Medium. Go apps into go library for example of examples. Go-bootstrap Generates a gait and allowance Go web project. In go apps have a value of. As of December 1st 2019 Buffalo with all related packages require Go Modules and. Authentication in Golang In building web and mobile. Go web examples or go is made against threats to run the example applying the data from the set the search. Why should be restarted for go app. Worth the go because you know that endpoint is welcome page then we created in addition to get started right of. To go apps and examples with fmt library to ensure a very different cloud network algorithms and go such as simple. This example will set users to map support the apps should be capable of examples covers both directories from the performance and application a form and array using firestore implementation. -

Setting up Colleague Web API
Colleague Setting Up Colleague Web API Release 1.12 May 2016 Notices Notices Without limitation: Ellucian®, Banner®, Colleague®, and Luminis® are trademarks of the Ellucian group of companies that are registered in the U.S. and certain other countries; and Ellucian Advance™, Ellucian Course Signals™, Ellucian Degree Works™, Ellucian PowerCampus™, Ellucian Recruiter™, Ellucian SmartCall™, are also trademarks of the Ellucian group of companies. Other names may be trademarks of their respective owners. © 2012-2016 Ellucian. Contains confidential and proprietary information of Ellucian and its subsidiaries. Use of these materials is limited to Ellucian licensees, and is subject to the terms and conditions of one or more written license agreements between Ellucian and the licensee in question. In preparing and providing this publication, Ellucian is not rendering legal, accounting, or other similar professional services. Ellucian makes no claims that an institution's use of this publication or the software for which it is provided will guarantee compliance with applicable federal or state laws, rules, or regulations. Each organization should seek legal, accounting, and other similar professional services from competent providers of the organization's own choosing. Ellucian 4375 Fair Lakes Court Fairfax, VA 22033 United States of America ©2016 Ellucian. Confidential & Proprietary 2 Contents Contents Prepare for Colleague Web API............................................................................................ 5 Overview........................................................................................................................................5 -

Why You Should Consider Web Assembly in Your Next Frontend Project
Why you should consider Web Assembly in your next frontend project Håkan Silfvernagel Who Am I? • Background in software development for process automation and robotics • Worked on the .NET platform since its release 2001-2002 • Consultant since 2010 • 19 years’ experience of software development in various positions such as developer, tester, architect, project manager, scrum master, practice manager and team lead. • MIT Artificial Intelligence: Implications for business strategy • MIT Internet of Things: Business implications and opportunities What is Web Assembly? Web Assembly • Group formed in 2015 (all major browsers) • 2017, Nov, Web Assembly Released • 2018, Feb, W3C public draft published Source: https://webassembly.org/ Web platform as virtual machine Virtual Machine • JavaScript • High level language • Flexible and expressive • Dynamically typed JS WASM • No compilation • Huge ecosystem • WebAssembly (WASM) • Low level assembly like language • Compact binary format • Near native performance • C, C++, Rust, Go… Wasm • A new browser standard • Based on asm.js • Intermediate language • Java (bytecode), C# (msil) • Strongly typed • i32, i64, f32, f64 Hello WASM WASM example (1) add.wat (module (func $addTwo (param i32 i32) (result i32) get_local 0 get_local 1 i32.add) (export "addTwo" (func $addTwo))) 0000000: 0061 736d ; WASM_BINARY_MAGIC 0000004: 0100 0000 ; WASM_BINARY_VERSION ; section "Type" (1) 0000008: 01 ; section code 0000009: 00 ; section size (guess) 000000a: 01 ; num types WASM example (2) ; type 0 000000b: 60 ; func -

Salesforce Rest Api Example
Salesforce Rest Api Example Pileate Juan servicing ghoulishly while Jethro always wenches his infeudation jugulates flauntingly, he raffled so formerly. Torr often browbeaten groundedly when coralline Roth pucker patriotically and sculpture her bartender. Affronted or elucidative, Salmon never pilfer any mirk! The first time you authenticate with Salesforce you can request a refresh token. Create custom REST Web service APIs on your force. We load this JS on every Article. As a non developer it helped me a lot to understand the concept and how to test using ACR. Either json can use in particular record from a communication through their ecosystem with other similar technologies right in salesforce rest api example, but here is great. In xml is an ordinary soap api requests for a bit of many cases, salesforce rest api example demonstrates how you? Web service or sending an HTTP request from Apex code and then receiving the response. This is a very simple method by which we could send and receive the message and set up a communication between the server and browser with no complicated parsing and translations. Tight coupling presents a severe impediment to application size. Everything will be rolled back if there was an error. Salesforce supports data integration through its proprietary Force. Json vs soap api query for example, is based services a session information you need it used earlier this poses is salesforce rest api example demonstrates how could be associated properties for? Your API will break. To toggle press enter. Darrel Thanks for the helpful comment. This example below steps correctly. -

Cloud Computing Bible
Barrie Sosinsky Cloud Computing Bible Published by Wiley Publishing, Inc. 10475 Crosspoint Boulevard Indianapolis, IN 46256 www.wiley.com Copyright © 2011 by Wiley Publishing, Inc., Indianapolis, Indiana Published by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada ISBN: 978-0-470-90356-8 Manufactured in the United States of America 10 9 8 7 6 5 4 3 2 1 No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, 201-748-6011, fax 201-748-6008, or online at http://www.wiley.com/go/permissions. Limit of Liability/Disclaimer of Warranty: The publisher and the author make no representations or warranties with respect to the accuracy or completeness of the contents of this work and specifically disclaim all warranties, including without limitation warranties of fitness for a particular purpose. No warranty may be created or extended by sales or promotional materials. The advice and strategies contained herein may not be suitable for every situation. This work is sold with the understanding that the publisher is not engaged in rendering legal, accounting, or other professional services.