The Complete View of Reading
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reading in the Twentieth Century. INSTITUTION Center for the Improvement of Early Reading Achievement, Ann Arbor, MI
DOCUMENT RESUME ED 479 530 CS 512 338 AUTHOR Pearson, P. David TITLE Reading in the Twentieth Century. INSTITUTION Center for the Improvement of Early Reading Achievement, Ann Arbor, MI. SPONS AGENCY Office of Educational Research and Improvement (ED), Washington, DC. PUB DATE 2000-08-00 NOTE 46p.; CIERA Archive #01-08. CONTRACT R305R70004 AVAILABLE FROM CIERA/University of Michigan, 610 E. University Ave., 1600 SEB, Ann Arbor, MI 48109-1259. Tel: 734-647-6940; Fax: 734- 763 -1229. For full text: http://www.ciera.org/library/archive/ 2001-08/0108pdp.pdf. PUB TYPE Information Analyses (070). Reports Research (143) EDRS PRICE EDRS Price MF01/PCO2 Plus Postage. DESCRIPTORS *Educational History; *Educational Practices; Futures (of Society); Instructional Materials; *Reading Instruction; *Reading Processes; *Reading Research; Reading Skills; Teaching Methods IDENTIFIERS *Reading Theories ABSTRACT This paper discusses reading instruction in the 20th century. The paper begins with a tour of the historical pathways that have led people, at the century's end, to the "rocky and highly contested terrain educators currently occupy in reading pedagogy." After the author/educator unfolds his version of a map of that terrain in the paper, he speculates about pedagogical journeys that lie ahead in a new century and a new millennium. Although the focus is reading pedagogy, the paper seeks to connect the pedagogy to the broader scholarly ideas of each period. According to the paper, developments in reading pedagogy over the last century suggest that it is most useful to divide the century into thirds, roughly 1900-1935, 1935- 1970, and 1970-2000. The paper states that, as a guide in constructing a map of past and present, a legend is needed, a common set of criteria for examining ideas and practices in each period--several candidates suggest themselves, such as the dominant materials used by teachers in each period and the dominant pedagogical practices. -

Practices News SARA G
Direct Instruction Effective School Practices news SARA G. TARVER, Editor, University of Wisconsin, Madison that cognitive scientists have deter- Practice: A Key to Success mined beyond any shadow of a doubt that students will only remember what they have practiced extensively and that they will remember for the long The number of DI success stories con- to all members of ADI, and indeed to term only that which they have prac- tinues to grow. This issue of DI News all who seek excellence in education, ticed in a sustained way over many includes (a) the stories of two schools by writing many articles about DI and years. This article supports Zig’s long- that received Wesley Becker Excellent generously sharing his many reference standing insistence on firming, firm- School Awards at the 2004 ADI Con- lists with those who seek references for ing, firming and mastery, mastery, ference—Buford Elementary School in various purposes. When you want to mastery. It also highlights the impor- Buford, Georgia and Eisenhut Elemen- find out what is known about a particu- tance of a particular feature of all DI tary School in Modesto, California; (b) lar topic related to DI, just ask Kerry. programs—massed to distributed prac- the story of Mountain View Academy tice. Intensive massed practice of new in Greeley, Colorado; and (c) the sto- All of these success stories rest on the ries of three schools that received shoulders of a group of Oregon profes- continued on page 3 Golden Apple Awards from Educa- sors who have been instrumental in tional Resources, Inc. -
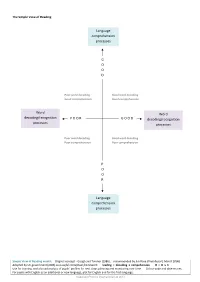
'Simple View of Reading Model'
The Simple View of Reading Language comprehension processes G O O D Poor word decoding Good word decoding Good comprehension Good comprehension Word Word decoding/recognition P O O R G O O D decoding/recognition processes processes Poor word decoding Good word decoding Poor comprehension Poor comprehension P O O R Language comprehension processes Simple View of Reading model: Original concept ‐ Gough and Tunmer (1986), recommended by Jim Rose (Final Report, March 2006) Adopted by UK government (2006) as a useful conceptual framework: reading = decoding x compehension R = D x C Use for training; and a broad analysis of pupils’ profiles for next steps planning and monitoring over time. Colour‐code and date entries. For pupils with English as an additional or new language, plot for English and for the first language. Copyright Phonics International Ltd 2012 The Simple View of Writing Composition: articulating and structuring ideas G O O D Poor transcription Good transcription Good composition Good composition Transcription: Transcription: spelling P O O R G O O D spelling handwriting handwriting Poor transcription Good transcription Poor composition Poor composition P O O R Composition: articulating and structuring ideas Simple View of Writing model: Adaptation of the SVoR model (Gough and Tunmer 1986) by Debbie Hepplewhite – for training, analysis and planning. Note: Spelling includes: knowledge of the alphabetic code (spelling alternatives) and encoding skill, high‐frequency tricky words, spelling word banks, etymology (word origins), morphology (word structures), some spelling rules. ‘Teach pupils to plan, revise and evaluate their writing – knowledge which is not required for reading’ (DfE National Curriculum for English, Key Stages 1 and 2 – Draft, 2012). -

Simple View of Reading Webcast – Text and Slides Welcome to This Webcast on the Simple View of Reading and Some Strategies to Support Teaching and Learning
SVoR Strategies webcast text and slides Simple View of Reading webcast – text and slides Welcome to this webcast on the Simple View of Reading and some strategies to support teaching and learning. 1. The simple view of reading (Rose 2006) with the two interacting dimensions, word recognition and language comprehension, is seen as essential to pupils becoming skilled readers. Understanding and applying the Simple View of Reading can inform and enhance high quality universal teaching. 2. From your earlier training you have been introduced to the Simple View of Reading. This webcast will suggest some strategies informed by using the Simple View of Reading model. WWW.patoss-dyslexia.org page 1 SVoR Strategies webcast text and slides First let’s briefly look at the Graduated Approach. The Graduated Approach embraces the Assess, Plan, Do and Review cycle. This model is crucial in judging which pupils will benefit from a targeted intervention and those who need a more intensive and individualised approach, usually delivered and/or overseen by a specialist teacher. [IfL 3. website] This ‘layered approach’ to intervention enables schools to plan their provision using pupil progress data and the Assess, Plan, Do and Review model to ensure additional provision at targeted and specialist levels is matched to the needs of their learners. Review impact on learner’s progress, ‘what is the outcome’, set specific date for review and adapt/ change intervention or seek further advice. The Simple View of Reading (Rose 2006) with the two interacting dimensions, word recognition and language comprehension, is seen as essential to pupils becoming skilled readers. -

Teaching Sight Words According to Science ODE Literacy Academy 2019 Why Are We D O in G T H Is ? Alig N Men T W It H Ohio’S Plan T O Raise Literacy Achievement
Teaching Sight Words According to Science ODE Literacy Academy 2019 Why are we d o in g t h is ? Alig n men t w it h Ohio’s Plan t o Raise Literacy Achievement 3 Why are we here? Ac c o r d in g t o t h e 2 0 17 Na t io n a l Assessment of Educational Progress (NAEP) scores, 37% of our nation’s fou rth - grade students were proficient readers. Why are we here? ● Nearly 30 percent of Ohio’s K- 3 students are reading below grade level. ● Nearly 40 percent of students in grades 3- 8 are not proficient on the OST in ELA. ● More than 50 percent of graduating seniors taking the ACT do not meet the college and career readiness benchmark for reading. Today’s Outcomes P a r t ic ip a n t s w ill… ● Ap p ly t h e t h e o r e t ic a l m o d e ls o f t h e S im p le Vie w o f Re a d in g and Seidenburg’s 4 Part Processing System for Word Recognition to instructional practices to teach words “by s ig h t .” ● Understand the connection between phonology and orthography when storing words for automatic retrieval. ● Demonstrate instructional strategies. Word Language Reading Recognition X Comprehension = Comprehension Phonological Background Awareness Knowledge Decoding (Phonics, Vocabulary Advanced Phonics) Language Sight Word Based on the Simple View of Recognition Verbal Reasoning Reading by Gough and Tunmer, 1986 Th e Simple View of Read in g 7 Wh a t is a Sig h t Wo r d ? A sight word is any word that is recognized in s t a n t ly a n d e ffo r t le s s ly , b y s ig h t , w h e t h e r it is s p e lle d r e g u la r ly o r ir r e g u la r ly BeAr bear bEaR bear Bear bear bear bEa r Sig h t w or d vocabulary is NOT based on visu al memory / visu al sk ills! - Dr . -

Final Conference Program
Society for the Scientific Study of Reading Brighton, United Kingdom Conference Program WEDNESDAY, JULY 18, 2018 Refreshments during breaks – Sandringham 09:00–04:00 Student and Early Careers Preconference Ambassador Room 01:00-03:30 Board Meeting Chartwell 04:00-05:00 Business Meeting (ST&D Keynote) Osborne Suite 05:00-07:00 Welcome Reception (Joint with ST&D) Oxford Gallery Wednesday POSTER SESSION I (JOINT with ST&D) Authors Oxford Gallery 05:30-07:00 Katherine Binder, Mount Holyoke College: Assessing vocabulary depth and breadth and their role in adult 1 [email protected]; An Tran; Kathryn literacy reading comprehension Tremblay Why do better readers have larger vocabularies? Exploring the roles Laura Shapiro, Aston University: 2 of reading ability and reading experience in developing vocabulary [email protected]; Jessie Ricketts; Adrian knowledge Burgess Amélie Bourcier, University of Montreal: The effect of a vocabulary intervention on the spelling, reading and 3 [email protected]; Rachel lexical skills of French-speaking grade 4 students Berthiaume; Daniel Daigle; Dominic Anctil Mary Requa, San Francisco State University: Vocabulary development through shared storybook reading with 4 [email protected]; Yi-Jui (Iva) Chen; Anne E. preschool parents Cunningham How phonological and morphological awareness interact for Erin Robertson, Cape Breton University: 5 children with dyslexia [email protected]; Helene Deacon An examination of a morpheme-based training and its effects on Irit Bar-Kochva, German Institute -

The Simple View of Reading: Research of Importance to All Educators by Linda Farrell, Marcia Davidson, Michael Hunter, Tina Osenga
The Simple View of Reading: Research of Importance to All Educators By Linda Farrell, Marcia Davidson, Michael Hunter, Tina Osenga Introduction In spite of its importance in the world of reading research, many practicing educators do not know about the Simple View of Reading. It is a formula based on the widely accepted view that reading has two basic components: word recognition (decoding) and comprehension. The Simple View formula has been supported and validated by a number of research studies. Understanding the formula can help educators with assessing reading weaknesses and providing appropriate instruction. The Simple View formula presented by Gough and Tunmer in 1986 is: Decoding (D) x Language Comprehension (LC) = Reading Comprehension (RC) The Simple View formula and supporting studies show that a student’s reading comprehension (RC) score can be predicted if decoding (D) skills and language comprehension (LC) abilities are known. Notice that D and LC are not added together to predict RC. They are multiplied. In the Simple View formula, the values of D and LC must be between 0 and 1 (or 0% and 100%). A score of 0 means no skill or ability at all and 1 indicates perfection. (Examples of how the formula works are presented later in this article.) Gough and Tunmer (1986) proposed the Simple View of Reading to clarify the role of decoding in reading. Many educators believe that strong decoding skills are not necessary to achieve reading comprehension. Beginning and struggling readers are often taught to compensate for weak decoding by guessing an unfamiliar word based on the first letter or the picture, then asking themselves if the word makes sense after reading the sentence. -

The Science of Reading Part 1
The Science of Reading —Part 1 Reading Comprehension Overview To copy or adapt this material, see OpportunityCulture.org/terms‐of‐use 2020 | 1 Objective of this slide: Welcome and frame purpose of this training. Estimated time: 2 minutes Facilitator says: • Welcome to this training on reading comprehension! • We hope that you found our introductory training and study guide on the simple view of reading useful to yourselves and your teams. • This additional set of resources is part of our advanced series on teaching reading. • This slide deck was designed by Public Impact and draws on the latest research in reading comprehension, grounded in the science of reading. The complete training consists of three parts: Reading Comprehension Overview, Explicit Comprehension Instruction, and MCL/Team Leader Study and Action Guide. Each part is designed to take you about an hour to review, with the goal of supporting you and your team teachers to move to research‐based instruction that helps more students become better readers. • This does not include all research on reading. It focuses on supporting reading comprehension—a key element of reading instruction once students have mastered the component skills of the simple view of reading. Future slide decks will address additional research for further enhancing students’ reading. • The language you’ll see here refers to teaching teams, as this was built for Multi‐ Classroom Leadership teams to use for improving instruction. But any teacher or teaching team can use this resource! 1 Objectives Define the elements of reading comprehension Identify ways teachers across content areas can develop students’ comprehension skills Focus on a critical research‐based approach: explicit comprehension instruction Identify next steps for learning more and systematically improving instruction together 2020 | 2 Objective of this slide: To introduce the objectives of this training. -

Lexile Framework for Listening White Paper
LEXILE FRAMEWORK® FOR LISTENING Building Tools for Success JANUARY 2020 BY: HEATHER KOONS, PH.D, DIRECTOR OF RESEARCH SERVICES, METAMETRICS® METAMETRICSINC.COM | LEXILE.COM THE LEXILE FRAMEWORK FOR LISTENING Listening is what most of us do for the majority of each day. We listen to family members, co-workers, classmates, teachers, the radio, television, podcasts and other forms of media on our computers and phones. Yet even though listening figures so prominently in our daily lives, and research has shown it to be critical to our academic and career success, a surprisingly small amount of time is devoted to teaching us how to listen well. In addition, few tools are currently available to support listening skill development. High-quality authentic audio material with lessons provided by Listenwise (listenwise.com) and audio book libraries such as those provided by Tales2Go (tales2go.com) are two examples of available products. To help address the need for a systematic way to measure student listening ability and evaluate the difficulty of audio materials, MetaMetrics, the developer of the Lexile Framework® for Reading, has developed the Lexile Framework® for Listening. This new framework provides a way for educators to assess student listening ability, monitor growth and provide appropriate audio materials to assist students in improving their listening skills. This white paper presents a brief description of key research findings on the importance of listening, a description of the Lexile Framework for Listening development, background on listening development and the relationship of listening to reading comprehension, and trends in listening assessment. About MetaMetrics MetaMetrics, founded in 1984, is an educational measurement and technology organization whose mission is to connect assessment with instruction. -

An Examination of Language and Reading Comprehension in Late Childhood and Early Adolescence
An Examination of Language and Reading Comprehension in Late Childhood and Early Adolescence DISSSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Margaret Beard Graduate Program in Education: Physical Activity and Education Services The Ohio State University 2017 Dissertation Committee: Kisha M. Radliff, Ph.D., Advisor Antoinette Miranda, Ph.D. Stephen A. Petrill, Ph.D. Copyrighted by Margaret E. Beard 2017 Abstract The simple view of reading suggests that proficient reading comprehension is the product of two factors, decoding (word recognition) and language comprehension (understanding spoken language), that are developmental in nature. Decoding accounts for more variance and predicts reading abilities in younger children, then as children age, language comprehension becomes more of a primary influence and predictor for comprehension ability. This study fills a gap by assessing the relationship between language ability and reading comprehension in older children. This study sample included participants in late childhood (n=582) and late adolescence (n=530) who were part of a larger longitudinal twin project. Results suggested significant positive correlations between decoding, vocabulary, language comprehension, and reading comprehension during both late childhood and early adolescence. Decoding and language comprehension explained 48.5% of the variance in reading comprehension in late childhood and 42.7% of the variance in early adolescence. Vocabulary made a unique contribution to reading comprehension above and beyond that made by decoding and language comprehension and significantly explained an additional 9.4% of the variance in late childhood and 17.3% in early adolescence. -

A Realistic Evaluation of the Introduction of the Simple View of Reading in Primary Schools
A realistic evaluation of the introduction of the Simple View of Reading in primary schools A thesis submitted to the University of Manchester for the degree of Doctor in Educational Psychology In the Faculty of Humanities 2010 SUSAN CORNWELL School of Education 1 LIST OF CONTENTS Page Chapter 1 Introduction 1.1 Overview 15 1.2 Rationale for the study 15 1.3 Research Questions 18 1.4 Outline of the study 19 1.5 Structure of the Thesis 20 Chapter 2 Literacy Learning: Literature Review 2.1 Overview of the national and local context 22 2.2 Models of literacy learning 23 2.1.1 The Searchlights Model 23 2.1.2 The Simple View of Reading (SVOR) 25 2.3 Teacher identification of literacy learning needs 31 2.3.1 The need for assessment 31 2.3.2 A whole school approach 32 2.3.3 Approaches to assessment 34 2.4 The use of SVOR to aid assessment 40 2.5 Summary 41 2.6 How the preceding review informs the study 42 Chapter 3 Staff Development: Literature Review 3.1 Introduction 44 3.2 Models of staff development 45 3.2.1 Outside agency led change 45 3.2.2 Teacher led approaches 48 3.2.3 An eclectic approach 52 3.3 Models of individual teacher development 53 3.4 Conditions needed to facilitate staff development 57 3.5 Barriers to change 59 3.5.1 How our understanding has changed 59 3.5.2 Terminology 61 3.5.3 Teacher attitudes 61 3.5.4 Leadership 62 3.5.5 Lack of time 63 2 3.5.6 Application of research 63 3.5.7 Stage of teaching career 64 3.6 Summary 65 3.7 How the preceding literature review informs the 66 study Chapter 4: Methodology 4.1 Outline of chapter -

Reading Conprehension Is Much More Than Strategy Instruction
Reading Comprehension Is Much More Than Strategy Instruction You will find resources on our website www.tools4reading.com Like our Facebook page – Tools 4 Reading Follow us on Instagram – Tools 4 Reading Dr. Mary E. Dahlgren [email protected] 1 Warm Up – True or False? 1. We can predict silent passage reading comprehension in 3rd grade fairly well, using simple screening tests of speech sound awareness and letter knowledge in kindergarten. True/False 2. Many children who seem behind in reading readiness at the kindergarten level are late bloomers; if we wait a year or two, they will grow out of their problems. True/False 3. A 45-minute screening in kindergarten will be more reliable than a 10-15- minute screening for predicting long term outcomes in reading. True/False 4. Most reading problems emerge late, around the end of 3rd grade when children must shift from learning to read to reading to learn. True/False 5. Spelling errors and written language samples can provide valuable information for teachers about a student’s reading subskills. True/False 6. Students can no longer benefit from word study—including syllabication, word structure, and word origin—after the end of third grade. True/False 7. When difficulties in reading persist into middle school or high school, these students should be taught using a whole-word, sight-based approach to reading. True/False 8. The use of timed assessments is important because it is both the accuracy and the fluency of reading that matter for student progress. True/False 9. Specialists and outside evaluators are the only personnel who are qualified to gather assessment information on student reading progress.