Automatic Builds of Large Software Repositories
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Vuln4real: a Methodology for Counting Actually Vulnerable Dependencies
This is the author's version of an article that has been published in this journal. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TSE.2020.3025443 1 Vuln4Real: A Methodology for Counting Actually Vulnerable Dependencies Ivan Pashchenko, Henrik Plate, Serena Elisa Ponta, Antonino Sabetta, and Fabio Massacci Abstract— Vulnerable dependencies are a known problem in today’s free open-source software ecosystems because FOSS libraries are highly interconnected, and developers do not always update their dependencies. Our paper proposes Vuln4Real, the methodology for counting actually vulnerable dependencies, that addresses the over-inflation problem of academic and industrial approaches for reporting vulnerable dependencies in FOSS software, and therefore, caters to the needs of industrial practice for correct allocation of development and audit resources. To understand the industrial impact of a more precise methodology, we considered the 500 most popular FOSS Java libraries used by SAP in its own software. Our analysis included 25767 distinct library instances in Maven. We found that the proposed methodology has visible impacts on both ecosystem view and the individual library developer view of the situation of software dependencies: Vuln4Real significantly reduces the number of false alerts for deployed code (dependencies wrongly flagged as vulnerable), provides meaningful insights on the exposure to third-parties (and hence vulnerabilities) of a library, and automatically predicts when dependency maintenance starts lagging, so it may not receive updates for arising issues. Index Terms—Vulnerable Dependency; Free Open Source Software; Mining Software Repositories F 1 INTRODUCTION (they may belong to the same project), and therefore, should be treated as a single unit, when constructing dependency The inclusion of free open-source software (FOSS) com- trees and reporting results of a dependency study. -

Characters and Numbers A
Index ■Characters and Numbers by HTTP request type, 313–314 #{ SpEL statement } declaration, SpEL, 333 by method, 311–312 #{bean_name.order+1)} declaration, SpEL, overview, 310 327 @Required annotation, checking ${exception} variable, 330 properties with, 35 ${flowExecutionUrl} variable, 257 @Resource annotation, auto-wiring beans with ${newsfeed} placeholder, 381 all beans of compatible type, 45–46 ${resource(dir:'images',file:'grails_logo.pn g')} statement, 493 by name, 48–49 ${today} variable, 465 overview, 42 %s placeholder, 789 single bean of compatible type, 43–45 * notation, 373 by type with qualifiers, 46–48 * wildcard, Unix, 795 @Value annotation, assigning values in controller with, 331–333 ;%GRAILS_HOME%\bin value, PATH environment variable, 460 { } notation, 373 ? placeholder, 624 ~.domain.Customer package, 516 @Autowired annotation, auto-wiring 23505 error code, 629–631 beans with all beans of compatible type, 45–46 ■A by name, 48–49 a4j:outputPanel component, 294 overview, 42 AboutController class, 332 single bean of compatible type, 43–45 abstract attribute, 49, 51 by type with qualifiers, 46–48 AbstractAnnotationAwareTransactionalTe @PostConstruct annotation, 80–82 sts class, 566 @PreDestroy annotation, 80–82 AbstractAtomFeedView class, 385–386 @RequestMapping annotation, mapping AbstractController class, 298 requests with AbstractDependencyInjectionSpringConte by class, 312–313 xtTests class, 551–552, 555 985 ■ INDEX AbstractDom4jPayloadEndpoint class, AbstractTransactionalTestNGSpringConte 745, 747 xtTests class, 555, -

Dependency Management and How to Single and Multi-Projects Are Structured and Confi Gured
BOOKS FOR PROFESSIONALS BY PROFESSIONALS® Varanasi Belida RELATED Introducing Gradle Introducing Gradle is a quick start-up primer on the Gradle build automation tool. You will learn about Gradle and how to set it up to use. You will learn the basics of Groovy, the language used for creating Gradle build fi les. Also, you will learn about tasks, plugins and build lifecycle. Furthermore, you will learn how to create and use a custom plugin. After reading and using Introducing Gradle, you will have an understanding of Gradle’s dependency management and how to single and multi-projects are structured and confi gured. You will learn how to use Gradle for publishing artifacts to local and Nexus remote repository. Finally, you will learn Jenkins support for Gradle. You will learn: • What Gradle is and how it compares with Ant, Maven and more • How to set up and test Gradle • What tasks and projects are • How to use out of the box plugins • How to create a custom plugin • Gradle’s support for dependency management • How to publish artifacts to local and remote repos • How to confi gure Jenkins to work with Gradle • How multi-projects are organized • Basic Groovy language features ISBN 978-1-4842-1032-1 Shelve in: 52999 Programming Languages/Java User level: Beginning SOURCE CODE ONLINE 9781484 210321 www.apress.com Introducing Gradle Balaji Varanasi Sudha Belida Introducing Gradle Copyright © 2015 by Balaji Varanasi and Sudha Belida This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Matthew Jason Benson Email: Mbenson@Apache
Matthew Jason Benson Email: [email protected] AIM: gudnabrsam Professional Objective My ideal position is quite simply one in which my talents are used to develop, or develop build systems for, useful and/or interesting software. General Skills Strong written communications, Ability to learn quickly and independently, Always willing to help peers. Computer Skills Programming Languages: Java, Javascript, SQL, Unix shell scripts, Windows/DOS command scripts aka batch files, COBOL. Java/Java EE: Apache Ant, Apache Commons (various), Bean Validation/Apache BVal, Therian, JBoss Forge, Morph, Jenkins, Spring framework, Hibernate ORM, Android, asm, cglib, javassist, AspectJ, JSF 2/Facelets, MyFaces, MyFaces Extensions Validator, Jackson, PrettyFaces, JUnit 3.x/4.x, Mockito, Spring Web Flow, ANTLR 2.x, Freemarker, JSP, Hamcrest, DWR AJAX library, Drools, iText PDF library, Struts 1.x, Threading/Concurrency, Servlets, JDBC, JMS, Swing. DBMS: Oracle, DB2, Pervasive/Btrieve v6.0-8.5. Data Formats: HP-PCL, XML, XHTML, Commons flatfile DSL. Operating Environments: Microsoft Windows, OS X, Linux, Solaris, Cygwin, MS-DOS, Novell Netware 3.x-4.x. Software: Apache Ant, Apache Maven, Apache Ivy, Subversion (user/admin), Eclipse, JIRA (user/admin), Jenkins (nee Hudson) CI, Sonatype Nexus (user/admin), git, JBoss Forge, ViewVC (user/admin), CVS (user/admin), Bugzilla (user/ admin), PGP/GnuPG, ghostScript, ghostPcl, Image Alchemy, PVCS. Miscellaneous: RTFM, STFW. Interests • Software Build Systems • Java Object Transformation • Language Parsing / Domain-specific Languages • Aspect-Oriented Programming • Java Classfile Instrumentation • Dynamic Java Programming • Integration of Enterprise and Legacy Systems • Imaging • Document Generation Employment History Senior Program Analyst - Internet The General October 2005–Present Projects: • Lead for conversion to Apache Maven-based software builds. -

Introducing Gradle Introducing Gradle Is a Quick Start-Up Primer on the Gradle Build Automation Tool
BOOKS FOR PROFESSIONALS BY PROFESSIONALS® Varanasi Belida RELATED Introducing Gradle Introducing Gradle is a quick start-up primer on the Gradle build automation tool. You will learn about Gradle and how to set it up to use. You will learn the basics of Groovy, the language used for creating Gradle build fi les. Also, you will learn about tasks, plugins and build lifecycle. Furthermore, you will learn how to create and use a custom plugin. After reading and using Introducing Gradle, you will have an understanding of Gradle’s dependency management and how to single and multi-projects are structured and confi gured. You will learn how to use Gradle for publishing artifacts to local and Nexus remote repository. Finally, you will learn Jenkins support for Gradle. You will learn: • What Gradle is and how it compares with Ant, Maven and more • How to set up and test Gradle • What tasks and projects are • How to use out of the box plugins • How to create a custom plugin • Gradle’s support for dependency management • How to publish artifacts to local and remote repos • How to confi gure Jenkins to work with Gradle • How multi-projects are organized • Basic Groovy language features ISBN 978-1-4842-1032-1 Shelve in: 52999 Programming Languages/Java User level: Beginning SOURCE CODE ONLINE 9781484 210321 www.apress.com Introducing Gradle Balaji Varanasi Sudha Belida Introducing Gradle Copyright © 2015 by Balaji Varanasi and Sudha Belida This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. -
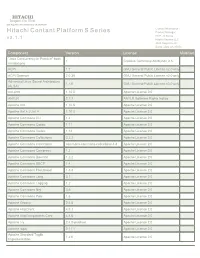
Hitachi Contant Platform S Series Product Manager HCP - S Series V 3
HITACHI Inspire the Next 2535 Augustine Drive Santa Clara, CA 95054 USA Contact Information : Hitachi Contant Platform S Series Product Manager HCP - S Series v 3 . 1 . 1 Hitachi Vantara LLC 2535 Augustine Dr. Santa Clara CA 95054 Component Version License Modified "Java Concurrency in Practice" book 1 Creative Commons Attribution 2.5 annotations ACPI 1.7 GNU General Public License v2.0 only ACPI Daemon 2.0.30 GNU General Public License v2.0 only Advanced Linux Sound Architecture 1.1.6 GNU General Public License v3.0 only (ALSA) ant-antlr 1.10.5 Apache License 2.0 ANTLR 2.7.7 ANTLR Software Rights Notice Apache Ant 1.10.5 Apache License 2.0 Apache Ant + JUnit 4 1.10.5 Apache License 2.0 Apache Commons CLI 1.4 Apache License 2.0 Apache Commons Codec 1.11 Apache License 2.0 Apache Commons Codec 1.14 Apache License 2.0 Apache Commons Collections 3.2.2 Apache License 2.0 Apache Commons Collections commons-commons-collections-4.4 Apache License 2.0 Apache Commons Compress 1.2 Apache License 2.0 Apache Commons Daemon 1.2.2 Apache License 2.0 Apache Commons DBCP 1.4 Apache License 2.0 Apache Commons FileUpload 1.3.3 Apache License 2.0 Apache Commons Lang 3.1 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 Apache Commons Net 3.6 Apache License 2.0 Apache Commons Pool 1.6 Apache License 2.0 Apache Groovy 2.4.8 Apache License 2.0 Apache HttpClient 4.5.3 Apache License 2.0 Apache HttpComponents Core 4.4.6 Apache License 2.0 Apache Ivy 2.4.0-patched Apache License 2.0 Apache log4j 2.11.1 Apache License 2.0 Apache Standard Taglib -

TECHNOLOGICAL EDUCATIONAL INSTITUTE of CRETE Thesis
TECHNOLOGICAL EDUCATIONAL INSTITUTE OF CRETE School of Applied Technology Department of Informatics Engineering Thesis Title: Application-Website Portal for parents of kids with epilepsy Marinakis Ioannis (4244) Advisor: Papadourakis Georgios ACKNOWLEDGEMENTS I would first like to thank my professor and thesis advisor, Dr. Georgios Papadourakis for giving me the opportunity to participate in Blended Academic International Mobility project and for his guidance during it. It was a great experience which provided me with many skills that will be useful in the future. Also, I would like to thank the students and the professors of the Blended AIM 2018 for the great experience of working as a team on a big project for a company. A special thanks to Tim Buckinx founder and CEO of Epihunter, who gave us the opportunity to work on a special project that, it’s going to make a great impact on many people’s lives. Finally, I would like to thank the thesis committee members Gareth Owens and Athanasios Malamos for their valuable input on my thesis. - 2 - DEDICATION This thesis is dedicated to parents and family for their endless love, support and continuous encouragement throughout my years of study and through the development and writing of this thesis. This would not have been possible without them. - 3 - ABSTRACT The purpose of this thesis is the designing and development of an application for people that suffer from epilepsy. People with epilepsy are threatened by social isolation as seizures come unexpected. In this project, we envision a concept that allows people with epilepsy to go out with their friends and family safely and without stigmatization. -

Interop.Jar Activation
Resource name License name License reference Usage Type a-j-interop.jar Eclipse 1.0 http://www.j-interop.org/license.html Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/javax/activation/act activation-1.1.jar CDDL 1.0 ivation/1.1/activation-1.1.pom Dynamic library activation.jar LGPL 2.1 https://github.com/wildfly/wildfly/blob/master/README.md Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/activem activemq-all-5.7.0.jar Apache 2.0 q/activemq-all/5.7.0/activemq-all-5.7.0.pom Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/activem activemq-core-5.7.0.jar Apache 2.0 q/activemq-core/5.7.0/activemq-core-5.7.0.pom Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/activem activemq-pool-5.7.0.jar Apache 2.0 q/activemq-pool/5.7.0/activemq-pool-5.7.0.pom Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/activem activemq-protobuf-1.1.jar Apache 2.0 q/protobuf/activemq-protobuf/1.1/activemq-protobuf-1.1.pom Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/axis2/a addressing-1.6.2.jar Apache 2.0 ddressing/1.6.2/addressing-1.6.2.pom Dynamic library advancedPersistentLookupLib-1.0.jar Commercial http://www.talend.com Dynamic library aether-api-1.11.jar Eclipse 1.0 https://www.eclipse.org/aether/download/ Dynamic library aether-connector-asynchttpclient-1.11.jar Eclipse 1.0 https://www.eclipse.org/aether/download/ Dynamic library aether-connector-wagon-1.11.jar Eclipse 1.0 https://www.eclipse.org/aether/download/ Dynamic -

4.2 Using Spring IO Platform with Gradle
Spring IO Platform Reference Guide 1.0.1.RELEASE Copyright © 2014 Copies of this document may be made for your own use and for distribution to others, provided that you do not charge any fee for such copies and further provided that each copy contains this Copyright Notice, whether distributed in print or electronically. Spring IO Platform Reference Guide Table of Contents I. Spring IO Platform Documentation ............................................................................................ 1 1. About the documentation ................................................................................................ 2 2. Getting help .................................................................................................................... 3 II. Getting Started ....................................................................................................................... 4 3. Introducing Spring IO Platform ........................................................................................ 5 4. Using Spring IO Platform ................................................................................................ 6 4.1. Using Spring IO Platform with Maven .................................................................... 6 4.2. Using Spring IO Platform with Gradle .................................................................... 7 III. Appendices ............................................................................................................................ 9 A. Dependency versions ................................................................................................... -

Eyeglass Search OSS Licenses and Packages V9
ECA 15.1 opensuse https://en.opensuse.org/openSUSE:License Package Licence Name Version Type Key Licence Name opensuse 15.1 OS annogen:annogen 0.1.0 JAR Not Found antlr:antlr 2.7.7 JAR BSD Berkeley Software Distribution (BSD) aopalliance:aopalliance 1 JAR Public DomainPublic Domain asm:asm 3.1 JAR Not Found axis:axis 1.4 JAR Apache-2.0 The Apache Software License, Version 2.0 axis:axis-wsdl4j 1.5.1 JAR Not Found backport-util-concurrent:backport-util-concurrent3.1 JAR Public DomainPublic Domain com.amazonaws:aws-java-sdk 1.1.7.1 JAR Apache-2.0 The Apache Software License, Version 2.0 com.beust:jcommander 1.72 JAR Apache-2.0 The Apache Software License, Version 2.0 com.carrotsearch:hppc 0.6.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.clearspring.analytics:stream 2.7.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.drewnoakes:metadata-extractor 2.4.0-beta-1JAR Public DomainPublic Domain com.esotericsoftware:kryo-shaded 3.0.3 JAR BSD Berkeley Software Distribution (BSD) com.esotericsoftware:minlog 1.3.0 JAR BSD Berkeley Software Distribution (BSD) com.fasterxml.jackson.core:jackson-annotations2.6.1 JAR Apache-2.0 The Apache Software License, Version 2.0 com.fasterxml.jackson.core:jackson-annotations2.5.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.fasterxml.jackson.core:jackson-annotations2.2.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.fasterxml.jackson.core:jackson-annotations2.9.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.fasterxml.jackson.core:jackson-annotations2.6.0