Backups and Recovery Backups W
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tape Drive Technology Comparison Sony AIT · Exabyte Mammoth · Quantum DLT by Roger Pozak Boulder, CO (303) 786-7970 Roger [email protected] Updated April 1999
Tape Drive Technology Comparison Sony AIT · Exabyte Mammoth · Quantum DLT By Roger Pozak Boulder, CO (303) 786-7970 [email protected] Updated April 1999 1 Introduction Tape drives have become the preferred device for backing up hard disk data files, storing data and protecting against data loss. This white paper examines three leading mid-range tape drives technologies available today: Sony AIT, Exabyte Mammoth and Quantum DLT. These three technologies employ distinctly different recording formats and exhibit different performance characteristics. Therefore, choosing among and investing in one of these technologies calls for a complete understanding of their respective strengths and weaknesses. Evolution of Three Midrange Tape Drive Technologies Exabyte introduced the 8mm helical scan tape drive in 1985. The 8mm drive mechanical sub-assembly was designed and manufactured by Sony while Exabyte supplied the electronics, firmware, cosmetics and marketing expertise. Today, Exabyte’s Mammoth drive is designed and manufactured entirely by Exabyte. Sony, long a leading innovator in tape technology, produces the AIT (Advance Intelligent Tape) drives. The AIT drive is designed and manufactured entirely by Sony. Although the 8mm helical scan recording method is used, the AIT recording format is new and incompatible with 8mm drives from Exabyte. Quantum Corporation is the manufacturer of DLT (Digital Linear Tape) drives. Quantum purchased the DLT technology from Digital Equipment Corporation in 1994 and has successfully developed and marketed several generations of DLT drive technology including the current DLT- 7000 product. Helical Scan vs Linear Serpentine Recording Sony AIT and Exabyte Mammoth employ a helical scan recording style in which data tracks are written at an angle with respect to the edge of the tape. -

IT Media Product Overview
storage IT Media Product Overview www.sonybiz.net/storage-media Magnetic Product Overview 2008 S-AIT Super Advanced Intelligent Tape • Ideal for automation solutions • Remote Memory In Cassette (R-MIC) • Excellent reliability requiring extraordinary capacities memory chip for extremely rapid data • SAIT-1 available in WORM version and high performance access • Tremendous storage capacity • High-speed data transfer rates SAP Packaging Short description Qty/SC** Qty/MC** UPC / EAN Material name name (pcs) (pcs) Code (piece) SAIT1500N SAIT1-500 S-AIT1, 1.3TB compressed* (500GB native), Remote-MIC 64Kbit 5 20 0 27242 64148 8 SAIT1500N-LABEL SAIT-1500 S-AIT1, 1.3TB compr.* (500GB native), R-MIC 64Kbit pre-labelled 5 20 0 27242 64148 8 S-AIT 1 SAIT1500W SAIT1-500W S-AIT1, 1.3TB compr.* (500GB native), R-MIC 64Kbit, WORM 5 20 0 27242 64444 1 SAIT1500W-LABEL SAIT1-500W S-AIT1, 1.3TB compr.* (500GB native), R-MIC 64Kbit, WORM pre-labelled 5 20 0 27242 64444 1 SAIT2800N SAIT2-800 S-AIT2, 2.0TB compressed* (800GB native), R-MIC 64Kbit 5 20 0 27242 69920 5 S-AIT2 SAIT1CL SAIT1-CL Cleaning cartridge for SAIT-1, provides approx. 50 cleaning cycles 5 20 0 27242 64158 7 SAIT1CLN-LABEL SAIT1-CL Cleaning cartridge for SAIT-1, provides approx. 50 cleaning cycles, pre-labelled 5 20 0 27242 64158 7 CLEANING SAIT2CL SAIT2-CL Cleaning cartridge for SAIT-2 drives, will provide approx. 50 cleaning cycles 5 20 0 27242 69982 3 AIT Advanced Intelligent Tape • Ideal for fast and reliable storage of • Extremely rapid data transfer rates of • Complete read / write compatibility -

Secure Data Storage – White Paper Storage Technologies 2008
1 Secure Data Storage – White Paper Storage Technologies 2008 Secure Data Storage - An overview of storage technology - Long time archiving from extensive data supplies requires more then only big storage capacity to be economical. Different requirements need different solutions! A technology comparison repays. Author: Dr. Klaus Engelhardt Dr. K. Engelhardt 2 Secure Data Storage – White Paper Storage Technologies 2008 Secure Data Storage - An overview of storage technology - Author: Dr. Klaus Engelhardt Audit-compliant storage of large amounts of data is a key task in the modern business world. It is a mistake to see this task merely as a matter of storage technology. Instead, companies must take account of essential strategic and economic parameters as well as legal regulations. Often one single technology alone is not sufficient to cover all needs. Thus storage management is seldom a question of one solution verses another, but a combination of solutions to achieve the best possible result. This can frequently be seen in the overly narrow emphasis in many projects on hard disk-based solutions, an approach that is heavily promoted in advertising, and one that imprudently neglects the considerable application benefits of optical storage media (as well as those of tape-based solutions). This overly simplistic perspective has caused many professional users, particularly in the field of long-term archiving, to encounter unnecessary technical difficulties and economic consequences. Even a simple energy efficiency analysis would provide many users with helpful insights. Within the ongoing energy debate there is a simple truth: it is one thing to talk about ‘green IT’, but finding and implementing a solution is a completely different matter. -

Unix Profession Webcast October 2007
Common Disaster Recovery Tools In Unix and Linux* © 2008 Dusan Baljevic The information contained herein is subject to change without notice Business Continuity Plans and Backups • People make IT support a complex issue! • Disaster Recovery must be based on Business Continuity Plans and meet the requirements as set in the following question: What is the cost of downtime per hour? February 1, 2016 Webinar 2 Loss of Data - Most Feared Threat Human error 35 Systems failure 31 s Supply chain disruption t n 29 e Virus, worm or other malicious attack on IT systems d n 28 o Employee malfeasance (e.g. theft or fraud) p s 25 e r Natural disasters, such as fires or floods f o 22 Unplanned downtime of online systems % 22 Terrorism 16 Power outage 13 Pandemic 13 Application failure 12 Industrial Action 8 February 1, 2016 Webinar 3 Bootable System Images in Unix and Linux Many tools available. For the sake of brevity, the following will be discussed: AIX mksysb, Network Installation Manager (NIM) HP make_tape_recovery/make_net_recovery, Dynamic Root Disk (DRD)* Linux Mondo Rescue, Clonezilla Solaris ufsdump, fssnap+ufsdump, flash/JumpStart Tru64 btcreate February 1, 2016 Webinar 4 Tape Drives Limitations inherent with tape media: • A tape drive must be available on each system to be archived. • Must remove old tapes and insert new ones for new backups. • If an archive exceeds the capacity of a tape, you must swap tapes for both creation and extraction. • Must check log files and run dummy restores to ensure data consistency. • Tape drives are more error-prone than a local network or CD- ROM and DVD. -

Dell Digital Data Storage/Digital Audio Tape Media Handbook (DDS/DAT)
DellTM Digital Data Storage/Digital Audio Tape Media Handbook (DDS/DAT) Version 1.0 Last Modified 08/17/05 Information in this document is subject to change without notice. © 2005 Dell Inc. All rights reserved. Reproduction in any manner whatsoever without the written permission of Dell Inc. is strictly forbidden. Trademarks used in this text: Dell, the DELL logo, PowerEdge, and PowerVault are trademarks of Dell Inc.; Microsoft and Windows are registered trademarks of Microsoft Corporation. Other trademarks and trade names may be used in this document to refer to either the entities claiming the marks and names or their products. Dell Inc. disclaims any proprietary interest in trademarks and trade names other than its own. 1 Introduction...............................................................................................5 2 Dell PowerVault DDS/DAT Drives and Media .........................................6 2.1 Drive Types and Basic Characteristics – DDS/DAT Drives...................................................... 6 2.2 Media types used in Dell PowerVault DDS/DAT drives........................................................... 7 2.3 Media Color Schemes and description ....................................................................................... 8 2.4 Invalid Media Symptoms............................................................................................................ 8 2.5 Migrating DDS/DAT media ...................................................................................................... -

Space Station Freedom Data Management System Growth and Evolution Report
NASA Technical Memorandum 103869 Space Station Freedom Data Management System Growth and Evolution Report R. Bartlett, G. Davis, T. L. Grant, J. Gibson, R. Hedges, M. J. Johnson, Y. K. Liu, A. Patterson-Hine, N. Sliwa, H. Sowizral, and J. Yan N93-15k77 (NASA-TM- I03869) SPACE STATION FREEDOM DATA MANAGEMENT SYSTEM GROWTH ANO EVOLU TIr}N REPORT (NASA) Uncl as September 1992 66 P G3/17 0178407 National Aeronautics and Space Administration Z NASA Technical Memorandum 103869 Space Station Freedom Data Management System Growth and Evolution Report T. L. Grant and J. Yan, Ames Research Center, Moffett Field, California September 1992 RIASA National Aeronauticsand Space Administration Ames Research Center MoffettField, CaJifomia94035-1000 The Study Team The Data Management System (DMS) analysis team Digital Equipment Corporation, Moffett Field, CA consists of civil servants and contractors at NASA Ames Roger Bartlett Research Center, Information Sciences Division. Prof. Joanne Bechta Dugan provided the reliability Intelligent Systems Technology Branch, Ames analysis of the DMS network reported in appendix B; she Research Center, Moffett Field, CA used the HARP code and the work was sponsored by Gloria Davis Langley Research Center (LaRC). Members of the Failure Terry Grant Tolerance/Redundancy Management Working Group Bob Hedges provided network failure information and preliminary Y. K. Liu models that aided our study of the failure tolerance of the Dr. Ann Patterson-Hine DMS network. Nancy Sliwa We also acknowledge the following individuals for Sterling Federal Systems, Inc., Palo Alto, CA reviewing early versions of the manuscripts: Dr. Jerry Yah Gregg Swietek (NASA Headquarters), Mike Pasciuto (NASA), Donald Woods (McDonnell Douglas Space Research Institute for Advanced Computational Systems Company (MDSSC)) and George Ganoe Science, Moffett Field, CA (NASA LaRC). -
Information Storage and Spintronics 03
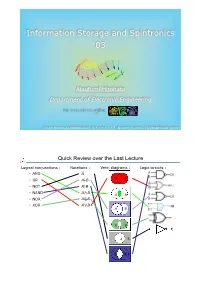
Information Storage and Spintronics 03 Atsufumi Hirohata Department of Electronic Engineering 13:30 Monday, 12/October/2020 (B/B 006 & online) & 12:00 Thursday, 15/October/2020 (online) Quick Review over the Last Lecture Logical conjunctions : Notations : Venn diagrams : Logic circuits : • AND • Ā A B • OR • A¯B • NOT • A↑B • NAND • A∧B A B • NOR • A⊕B • XOR • A∨B A B A B A Ā A B 03 Magnetic Tape Storage • Advantages • Development • Linear recording • Helical recording • 1 / 2 reel • Linear tape open Access Patterns to a Hard Disk Drive Research on access patterns on network attached storages (NAS) : * * http://www.oracle.com/ Origins of Data Loss Information storage is required : * * http://www.oracle.com/ Why Tape Storage ? Magnetic tape media : * -times-more data are stored as compared with a hard disk drives (HDD). Almost EB data are stored in tape media ® Almost tapes ! Tapes * http://home.jeita.or.jp/ Data Transfer Speed Magnetic tape media : * Without compression, MB / sec. ( GB / h). Almost comparable with a HDD HDD Tapes Optical disks * http://home.jeita.or.jp/ Where are Magnetic Storages Used ? World-wide enterprise disk storage consumption : * * http://home.jeita.or.jp/ Energy Consumption Energy costs : * Tape media : LTO-5 without compression Initial 3 PB data + 45 % annual increase for 12 years ® Total cost of ownership (TCO) : 1/ of HDD ® Energy cost : 1/ of HDD * http://home.jeita.or.jp/ First Magnetic Tape Drive In 1951, Remington Rand introduced the first tape drive for a computer : * UNIVAC (Universal automatic computer) I uses a tape drive, UNISERVO. • ½-inch wide tape • Nickel-plated phosphor bronze (Vicalloy) • 1,200 feet long • 8 channels ( for data, for parity and for timing) • inch / sec. -

Argest® Backup User Guide
ArGest ® Backup User’s Guide Version 4.0 Copyright © 2020, TOLIS Group, Inc. ArGest® Backup User’s Guide TOLIS Group, Inc.., et al Copyright © 2008-2020, TOLIS Group, Inc., All rights reserved Notice of rights All rights reserved. No part of this book may be reproduced or transmitted in any form by any means without the prior written permission of TOLIS Group, Inc.. For information on getting permission for reprints and excerpts, contact [email protected]. Notice of Liability The information in this manual is distributed “as is” and without warranty. While every precaution has been taken in the preparation of the manual, TOLIS Group, Inc. nor its resellers and representatives shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the information and instructions contained in the manual or by the computer software described within. Trademarks Throughout this book trademarked names may be used. TOLIS Group, Inc. states that we are using any and all trademarked names in an editorial fashion and to the benefit of the trademark owner with no intention of infringement of the trademark. Update Information TOLIS Group, Inc. will always work to insure that the data contained in this manual is kept up to date. You can always find the latest version at our website at http://www.tolisgroup.com/documentation.html ArGest® Backup User’s Guide Table of Contents - 3 Email Settings ...............................................................................32 Table -

The Future of Data Storage Technologies
International Technology Research Institute World Technology (WTEC) Division WTEC Panel Report on The Future of Data Storage Technologies Sadik C. Esener (Panel Co-Chair) Mark H. Kryder (Panel Co-Chair) William D. Doyle Marvin Keshner Masud Mansuripur David A. Thompson June 1999 International Technology Research Institute R.D. Shelton, Director Geoffrey M. Holdridge, WTEC Division Director and ITRI Series Editor 4501 North Charles Street Baltimore, Maryland 21210-2699 WTEC Panel on the Future of Data Storage Technologies Sponsored by the National Science Foundation, Defense Advanced Research Projects Agency and National Institute of Standards and Technology of the United States government. Dr. Sadik C. Esener (Co-Chair) Dr. Marvin Keshner Dr. David A. Thompson Prof. of Electrical and Computer Director, Information Storage IBM Fellow Engineering & Material Sciences Laboratory Research Division Dept. of Electrical & Computer Hewlett-Packard Laboratories International Business Machines Engineering 1501 Page Mill Road Corporation University of California, San Diego Palo Alto, CA 94304-1126 Almaden Research Center 9500 Gilman Drive Mail Stop K01/802 La Jolla, CA 92093-0407 Dr. Masud Mansuripur 650 Harry Road Optical Science Center San Jose, CA 95120-6099 Dr. Mark H. Kryder (Co-Chair) University of Arizona Director, Data Storage Systems Center Tucson, AZ 85721 Carnegie Mellon University Roberts Engineering Hall, Rm. 348 Pittsburgh, PA 15213-3890 Dr. William D. Doyle Director, MINT Center University of Alabama Box 870209 Tuscaloosa, AL 35487-0209 INTERNATIONAL TECHNOLOGY RESEARCH INSTITUTE World Technology (WTEC) Division WTEC at Loyola College (previously known as the Japanese Technology Evaluation Center, JTEC) provides assessments of foreign research and development in selected technologies under a cooperative agreement with the National Science Foundation (NSF). -

Western Peripherals ™ Division of ~
MODEL TC-120/128 TAPE CONTROLLER HARDHARE MANUAL western peripherals ™ Division of ~ 14321 New Myford Hoad • Tustin, California 92680 • (714) 730·6250 • TWX: 910 595·1775 • Cable: WESPER MODEL TC-120/128 TAPE CONTROLLER HARDHARE MANUAL PUBLICATION NUMBER 01200146 C western peripherals 14321 MYFORD ROAD TUSTIN~ CALIFORNIA 92680 © 198:1:. by Westem Peripherals, Inc. All Rights Reserved PRINTED IN U.S.A. PREFACE This manual provides information necessary for the installation and maintenance of the Western Peripherals Model TC-120/l28 Tape Controller, used with Data General or Data General-emulating computers. The manual is divided into the following sections: Section I General Description Section II Installation Section III Programming Section IV Theory of Operation SECTION I GENERAL DESCRIPTION • • TABLE OF CONTENTS PARAGRAPH PAGE • 1.1 DESCRIPTION OF EQUIPMENT 1-1 1.3 DRIVE COMPATIBILITY 1-1 1.6 OTHER FEATURES 1-2 • 1.12 SPECIFICATIONS 1-4 • • .' • • • • SECTION I • GENERAL DESCRIPTION • 1.1 DESCRIPTION OF EQUIPMENT 1.2 The Western peripherals Model TC-120/128 is a universal mag netic tape controller/formatter which is hardware and software • compatible with the Data General family of computer systems, pro viding both NRZI and phase encoded (PE) format capability in a single embedded printed circuit board. The controller is also I compatible with all other computers emulating the Data General computer family, using the standard-sized 15 inch x 15 inch cir cuit boards. The controller contains all interface, control, • status, and formatting electronics to emulate the Data General tape subsystem and installs directly into any available card slot in the computer or expansion chassis. -

Data Protection and Recovery in the Small and Mid-Sized Business (SMB)
Data Protection and Recovery in the Small and Mid-sized Business (SMB) An Outlook Report from Storage Strategies NOW By Deni Connor, Patrick H. Corrigan and James E. Bagley Intern: Emily Hernandez October 11, 2010 Storage Strategies NOW 8815 Mountain Path Circle Austin, Texas 78759 Note: The information and recommendations made by Storage Strategies NOW, Inc. are based upon public information and sources and may also include personal opinions both of Storage Strategies NOW and others, all of which we believe are accurate and reliable. As market conditions change however and not within our control, the information and recommendations are made without warranty of any kind. All product names used and mentioned herein are the trademarks of their respective owners. Storage Strategies NOW, Inc. assumes no responsibility or liability for any damages whatsoever (including incidental, consequential or otherwise), caused by your use of, or reliance upon, the information and recommendations presented herein, nor for any inadvertent errors which may appear in this document. This report is purchased by Geminare, who understands and agrees that the report is furnished solely for its internal use only and may not be furnished in whole or in part to any other person other than its directors, officers and employees, without the prior written consent of Storage Strategies NOW. Copyright 2010. All rights reserved. Storage Strategies NOW, Inc. 1 Sponsor 2 Table of Contents Sponsor .................................................................................................................................................................. -

Fedora 7 Unleashed / Andrew Hudson, Paul Hudson
Andrew Hudson and Paul Hudson Fedora™ 7 UNLEASHED 800 East 96th Street, Indianapolis, Indiana 46240 USA Fedora™ 7 Unleashed Acquisitions Editor Copyright © 2008 by Sams Publishing Damon Jordan All rights reserved. No part of this book shall be reproduced, stored in a retrieval system, or transmitted by any means, electronic, mechanical, photocopying, recording, Development Editor or otherwise, without written permission from the publisher. No patent liability is Michael Thurston assumed with respect to the use of the information contained herein. Although every precaution has been taken in the preparation of this book, the publisher and author Managing Editor assume no responsibility for errors or omissions. Nor is any liability assumed for Gina Kanouse damages resulting from the use of the information contained herein. ISBN-13: 978-0-672-32942-5 Project Editor ISBN-10: 0-672-32942-5 George E. Nedeff Library of Congress Cataloging-in-Publication Data Copy Editor Margo Catts Hudson, Andrew, 1978- Indexer Fedora 7 unleashed / Andrew Hudson, Paul Hudson. Brad Herriman p. cm. ISBN 978-0-672-32942-5 (pbk. w/dvd) Proofreader 1. Linux. 2. Operating systems (Computers) I. Hudson, Paul, 1979- II. Title. Heather Waye Arle Technical Editor QA76.76.O63H794 2007 Dallas Releford 005.4’32—dc22 2007030725 Publishing Coordinator Printed in the United States on America Vanessa Evans First Printing: August 2007 Multimedia Developer Trademarks Dan Scherf All terms mentioned in this book that are known to be trademarks or service marks have been appropriately capitalized. Sams Publishing cannot attest to the accuracy of Book Designer this information. Use of a term in this book should not be regarded as affecting the Gary Adair validity of any trademark or service mark.