A Point-Mass Mixture Random Effects Model for Pitching Metrics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A's News Clips, Friday, July 9, 2010 Oakland A's Pitcher Vin
A’s News Clips, Friday, July 9, 2010 Oakland A's pitcher Vin Mazzaro teeming with confidence By Joe Stiglich, Oakland Tribune The depth of the A's young starting pitching is an asset for the organization. For Vin Mazzaro, it's a hurdle. Mazzaro is among that group of talented young pitchers, and when the right-hander didn't make Oakland's roster out of spring training, it was unclear when his next chance might arrive. The opportunity came quickly because of injuries in the rotation, and Mazzaro is taking full advantage. He's looking for his third straight victory tonight against the Los Angeles Angels, who arrive in Oakland for a three-game series. As the A's try to right their ship after being swept in three games by the New York Yankees, Mazzaro's recent emergence offers a sliver of sunshine. "Once you have a good game in you, it kind of gives you a big boost," Mazzaro said. "You see yourself achieving your goals in between starts with what you're working on. I'm just feeling good, strong, healthy. I've just got all the confidence in the world right now." If Mazzaro, 23, is feeding off his positive vibes, he also knows the other end of the spectrum. After getting called up in June 2009 and throwing back-to-back scoreless outings in his first two major league starts, his joy ride came to a screeching halt. Mazzaro went 0-8 with a 7.22 ERA over his next 10 starts and he missed the final month with shoulder tendinitis. -

Tribute to Champions
HLETIC C AT OM M A IS M S O I C O A N T Tribute to Champions May 30th, 2019 McGavick Conference Center, Lakewood, WA FEATURING CONNELLY LAW OFFICES EXCELLENCE IN OFFICIATING AWARD • Boys Basketball–Mike Stephenson • Girls Basketball–Hiram “BJ” Aea • Football–Joe Horn • Soccer–Larry Baughman • Softball–Scott Buser • Volleyball–Peter Thomas • Wrestling–Chris Brayton FROSTY WESTERING EXCELLENCE IN COACHING AWARD Patty Ley, Cross Country Coach, Gig Harbor HS Paul Souza, Softball & Volleyball Coach, Washington HS FIRST FAMILY OF SPORTS AWARD The McPhee Family—Bill and Georgia (parents) and children Kathy, Diane, Scott, Colleen, Brad, Mark, Maureen, Bryce and Jim DOUG MCARTHUR LIFETIME ACHIEVEMENT AWARD Willie Stewart, Retired Lincoln HS Principal Dan Watson, Retired Lincoln HS Track Coach DICK HANNULA MALE & FEMALE AMATEUR ATHLETE OF THE YEAR AWARD Jamie Lange, Basketball and Soccer, Sumner/Univ. of Puget Sound Kaleb McGary, Football, Fife/Univ. of Washington TACOMA-PIERCE COUNTY SPORTS HALL OF FAME INDUCTEES • Baseball–Tony Barron • Basketball–Jim Black, Jennifer Gray Reiter, Tim Kelly and Bob Niehl • Bowling–Mike Karch • Boxing–Emmett Linton, Jr. and Bobby Pasquale • Football–Singor Mobley • Karate–Steve Curran p • Media–Bruce Larson (photographer) • Snowboarding–Liz Daley • Swimming–Dennis Larsen • Track and Field–Pat Tyson and Joel Wingard • Wrestling–Kylee Bishop 1 2 The Tacoma Athletic Commission—Celebrating COMMITTEE and Supporting Students and Amateur Athletics Chairman ������������������������������Marc Blau for 76 years in Pierce -

Seattle Mariners Opening Day Record Book
SEATTLE MARINERS OPENING DAY RECORD BOOK 1977-2012 All-Time Openers Year Date Day Opponent Att. Time Score D/N 1977 4/6 Wed. CAL 57,762 2:40 L, 0-1 N 1978 4/5 Wed. MIN 45,235 2:15 W, 3-2 N 1979 4/4 Wed. CAL 37,748 2:23 W, 5-4 N 1980 4/9 Wed. TOR 22,588 2:34 W, 8-6 N 1981 4/9 Thurs. CAL 33,317 2:14 L, 2-6 N 1982 4/6 Tue. at MIN 52,279 2:32 W, 11-7 N 1983 4/5 Tue. NYY 37,015 2:53 W, 5-4 N 1984 4/4 Wed. TOR 43,200 2:50 W, 3-2 (10) N 1985 4/9 Tue. OAK 37,161 2:56 W, 6-3 N 1986 4/8 Tue. CAL 42,121 3:22 W, 8-4 (10) N 1987 4/7 Tue. at CAL 37,097 2:42 L, 1-7 D 1988 4/4 Mon. at OAK 45,333 2:24 L, 1-4 N 1989 4/3 Mon. at OAK 46,163 2:19 L, 2-3 N 1990 4/9 Mon. at CAL 38,406 2:56 W, 7-4 N 1991 4/9 Tue. CAL 53,671 2:40 L, 2-3 N 1992 4/6 Mon. TEX 55,918 3:52 L, 10-12 N 1993 4/6 Tue. TOR 56,120 2:41 W, 8-1 N 1994 4/4 Mon. at CLE 41,459 3:29 L, 3-4 (11) D 1995 4/27 Thurs. -

November, 2006
By the Numbers Volume 16, Number 4 The Newsletter of the SABR Statistical Analysis Committee November, 2006 Review Academic Research: Errors and Official Scorers Charlie Pavitt The author describes a recent academic study investigating the change in error rates over time, and speculating on the role of the official scorer in the “home field advantage” for errors. This is one of a series of reviews of sabermetric articles published in academic journals. It is part of a project of mine to collect and catalog sabermetric research, and I would appreciate learning of and receiving copies of any studies of which I am unaware. Please visit the Statistical Baseball Research Bibliography at www.udel.edu/communication/pavitt/biblioexplan.htm . Use it for your research, and let me know what is missing. per game, used as a proxy for team speed, were positively related David E. Kalist and Stephen J. Spurr, Baseball with errors; others have previously noticed the speed/error Errors, Journal of Quantitative Analysis in association. Sports, Volume 2, Issue 4, Article 3 Interestingly, the National League has consistently “boasted” more errors than the American League; the authors are unsure In its short existence, JQAS has shown a tendency to present why, but comparisons both before and after the appearance of the articles that are long on method but short on interesting designated hitter in the junior circuit indicate that this is probably substance (case in point, another piece in Volume 2 Issue 4 not the reason. relevant to the tired old topic of within-league parity). Kalist and Spurr’s effort is a welcome change. -

San Francisco Giants
SAN FRANCISCO GIANTS 2016 END OF SEASON NOTES 24 Willie Mays Plaza • San Francisco, CA 94107 • Phone: 415-972-2000 sfgiants.com • sfgigantes.com • sfgiantspressbox.com • @SFGiants • @SFGigantes • @SFG_Stats THE GIANTS: Finished the 2016 campaign (59th in San Francisco and 134th GIANTS BY THE NUMBERS overall) with a record of 87-75 (.537), good for second place in the National NOTE 2016 League West, 4.0 games behind the first-place Los Angeles Dodgers...the 2016 Series Record .............. 23-20-9 season marked the 10th time that the Dodgers and Giants finished in first and Series Record, home ..........13-7-6 second place (in either order) in the NL West...they also did so in 1971, 1994 Series Record, road ..........10-13-3 (strike-shortened season), 1997, 2000, 2003, 2004, 2012, 2014 and 2015. Series Openers ...............24-28 Series Finales ................29-23 OCTOBER BASEBALL: San Francisco advanced to the postseason for the Monday ...................... 7-10 fourth time in the last sevens seasons and for the 26th time in franchise history Tuesday ....................13-12 (since 1900), tied with the A's for the fourth-most appearances all-time behind Wednesday ..................10-15 the Yankees (52), Dodgers (30) and Cardinals (28)...it was the 12th postseason Thursday ....................12-5 appearance in SF-era history (since 1958). Friday ......................14-12 Saturday .....................17-9 Sunday .....................14-12 WILD CARD NOTES: The Giants and Mets faced one another in the one-game April .......................12-13 wild-card playoff, which was added to the MLB postseason in 2012...it was the May .........................21-8 second time the Giants played in this one-game playoff and the second time that June ...................... -

RAYS CLIPS August 20, 2010
RAYS CLIPS August 20, 2010 Tampa Bay Rays are doing the right thing by protecting Jeremy Hellickson's arm By John Romano, Times Sports Columnist With Jeremy Hellickson, the future takes precedence over the present. ST. PETERSBURG After his first three big-league starts, the rookie pitcher in Washington had a 2-0 record. His ERA was 1.86, and opponents were batting .149 against him. Stephen Strasburg ended up on the cover of Sports Illustrated. After his first three big-league starts, the rookie pitcher in Tampa Bay had a 3-0 record. His ERA was 1.35, and opponents were batting .136 against him. Jeremy Hellickson could very well end up in Triple A after his next start tonight. Kind of makes you wonder if the Rays are - how shall I put this - insane? In the ramshackle history of an expansion franchise, no Rays starting pitcher has ever made such a dramatic entrance. Hellickson has been poised, he has been efficient, he has, by far, been better than anyone could have reasonably expected. So are the Rays making a huge mistake by not taking advantage of Hellickson while fighting for first place? No, they're not. At least, not at this point. Certainly, we can all agree on the notion of seizing the day in a pennant race. We wouldn't mind spending more of ownership's money, and we might be willing to trade a prospect at the right price. But risking a young player's future? That should be nonnegotiable. And that's why this story is not as simple as it seems. -

Houston Astros (4-4) at Seattle Mariners (2-6) RHP Joe Musgrove (0-0, 3.60) Vs
Houston Astros (4-4) at seattle mariners (2-6) RHP Joe Musgrove (0-0, 3.60) vs. LHP Ariel Miranda (0-0, 3.60) tuesday, april 11, 2017 • safeco field • seattle, wa • 9:10 p.M. ct • root sports sw • kbme 790 am • la nueva 94.1 fm GAME #9 ..........................road #2 tonight’s matchup: The Astros and Mariners climbing charts: OF Carlos Beltrán, who has ABOUT THE RECORD will continue this three-game series tonight with a first played in parts of 20 Major League season, ranks in Overall Record: .................................4-4 pitch set for 9:10 p.m. CT...the pitching matchup is a the top 50 all-time in doubles and RBI in MLB history. Home Record: ..................................4-3 rematch from last Thursday in Houston with RHP Joe Doubles (mlb history) rbi (mlb history) --with Roof Open: .............................3-3 Musgrove (0-0) starting for the Astros opposite LHP T35. Joe Medwick - 540 47. Willie Stargell - 1540 --with Roof Closed: ...........................1-0 Ariel Miranda (0-0) and the Mariners. T35 - Dave Winfield - 540 48. Harry Heilman - 1539 --with Roof Open/Closed: .................0-0 37. Al Simmons - 539 T49. Carlos Beltrán - 1537 Road Record: ...................................0-1 about the rematch: 38. Carlos Beltrán - 538 T49. Joe DiMaggio - 1537 Current Streak: ............................ Lost 1 Tonight’s starters, RHP Joe Last Homestand: ..............................4-3 Musgrove and LHP Ariel Miranda, posted nearly Current Road Trip: ............................0-1 identical pitching lines in their last matchup on Thurs- the 200 club: 2B Jose Altuve sits at 200 career Last 5 Games: ..................................1-4 day in Houston...they both went 5.0 innings, allowing stolen bases, which ranks seventh in Astros history. -

2020 MLB Ump Media Guide
the 2020 Umpire media gUide Major League Baseball and its 30 Clubs remember longtime umpires Chuck Meriwether (left) and Eric Cooper (right), who both passed away last October. During his 23-year career, Meriwether umpired over 2,500 regular season games in addition to 49 Postseason games, including eight World Series contests, and two All-Star Games. Cooper worked over 2,800 regular season games during his 24-year career and was on the feld for 70 Postseason games, including seven Fall Classic games, and one Midsummer Classic. The 2020 Major League Baseball Umpire Guide was published by the MLB Communications Department. EditEd by: Michael Teevan and Donald Muller, MLB Communications. Editorial assistance provided by: Paul Koehler. Special thanks to the MLB Umpiring Department; the National Baseball Hall of Fame and Museum; and the late David Vincent of Retrosheet.org. Photo Credits: Getty Images Sport, MLB Photos via Getty Images Sport, and the National Baseball Hall of Fame and Museum. Copyright © 2020, the offiCe of the Commissioner of BaseBall 1 taBle of Contents MLB Executive Biographies ...................................................................................................... 3 Pronunciation Guide for Major League Umpires .................................................................. 8 MLB Umpire Observers ..........................................................................................................12 Umps Care Charities .................................................................................................................14 -

Carlos Subero Manager, Birmingham Barons Chicago White Sox
seasons in the Majors as a second baseman, managed 14 seasons in the Majors and led the New York Mets to a World Series Championship in 1986. The 1987 National League Manager of the Year will lead the U.S. Baseball Team at the Beijing Olympics in August. Coaches for the U.S. and World Team are as follows: U.S. Team (2008 Summer Olympics Trial Team) Coaches: Davey Johnson Manager, 2008 U.S. Olympic Team Marcel Lachemann Pitching Coach, 2008 U.S. Olympic Team Reggie Smith Hitting Coach, 2008 U.S. Olympic Team Rick Eckstein Third Base/Bench Coach, 2008 U.S. Olympic Team Dick Cooke Auxiliary Coach, 2008 U.S. Olympic Team World Team Coaches: Pat Listach Manager, Iowa Cubs Chicago Cubs Pacific Coast League/AAA Scott Little Manager, Frisco Rough Riders Texas Rangers Texas League/AA Larry Parrish Manager, Toledo Mud Hens Detroit Tigers International League/AAA John Stearns Manager, Harrisburg Senators Washington Nationals Eastern League/AA Carlos Subero Manager, Birmingham Barons Chicago White Sox Southern League/AA Rafael Chaves Pitching Coach, Scranton/Wilkes-Barre Yankees New York Yankees International League/AAA Thirty-nine players have competed in both the XM All-Star Futures Game and the Major League Baseball All-Star Game. In 2007, a record 22 Major League All-Stars were alumni of the XM All-Star Futures Game, doubling the previous mark of 11 set in 2006. The full list of players who competed in both games are as follows: Player Current Team Position All-Star Game Futures Game Josh Beckett Red Sox RHP 2007 2000 Lance Berkman Astros INF 2001-02, 2004 1999 Hank Blalock Rangers INF 2003-04 2001 Mark Buehrle White Sox LHP 2002, 2005 2000 Miguel Cabrera Tigers INF 2004, 2007 2001-02 Robinson Cano Yankees INF 2006 2003-04 Francisco Cordero Reds RHP 2004, 2007 1999 Carl Crawford Rays OF 2004, 2007 2002 Adam Dunn Reds OF 2002 2001 Prince Fielder Brewers INF 2007 2004 Rafael Furcal Dodgers INF 2003 1999 Marcus Giles --- INF 2003 1999 J.J. -

2017 Information & Record Book
2017 INFORMATION & RECORD BOOK OWNERSHIP OF THE CLEVELAND INDIANS Paul J. Dolan John Sherman Owner/Chairman/Chief Executive Of¿ cer Vice Chairman The Dolan family's ownership of the Cleveland Indians enters its 18th season in 2017, while John Sherman was announced as Vice Chairman and minority ownership partner of the Paul Dolan begins his ¿ fth campaign as the primary control person of the franchise after Cleveland Indians on August 19, 2016. being formally approved by Major League Baseball on Jan. 10, 2013. Paul continues to A long-time entrepreneur and philanthropist, Sherman has been responsible for establishing serve as Chairman and Chief Executive Of¿ cer of the Indians, roles that he accepted prior two successful businesses in Kansas City, Missouri and has provided extensive charitable to the 2011 season. He began as Vice President, General Counsel of the Indians upon support throughout surrounding communities. joining the organization in 2000 and later served as the club's President from 2004-10. His ¿ rst startup, LPG Services Group, grew rapidly and merged with Dynegy (NYSE:DYN) Paul was born and raised in nearby Chardon, Ohio where he attended high school at in 1996. Sherman later founded Inergy L.P., which went public in 2001. He led Inergy Gilmour Academy in Gates Mills. He graduated with a B.A. degree from St. Lawrence through a period of tremendous growth, merging it with Crestwood Holdings in 2013, University in 1980 and received his Juris Doctorate from the University of Notre Dame’s and continues to serve on the board of [now] Crestwood Equity Partners (NYSE:CEQP). -

2019 Sec Baseball Tournament May 21-26 | Hoover Metropolitan Stadium | Hoover, Ala
2019 SEC BASEBALL TOURNAMENT MAY 21-26 | HOOVER METROPOLITAN STADIUM | HOOVER, ALA. GAME 14 | LSU 12, Mississippi State 2 | NOTES AND QUOTES POST-GAME NOTES • LSU’s win advances the Tigers to the semifinals to face No. 1 Vanderbilt. • The Tigers have advanced to the semifinals in the SEC Tournament 10 out of the last 11 years. • Defeating the No. 4 RPI-ranked Bulldogs improved LSU to 12 wins vs. the RPI Top 25. • LSU won by a 10-run rule after the seventh, which is the second run rule to occur this tournament (Vanderbilt-Auburn). • The Tigers improved their league-best record to 88-43 all-time in the SEC Tournament. • LSU has bested Mississippi State 13 out of the last 16 matchups, chipping away at the 206- 189-1 all-time record led by the Bulldogs. • LSU’s 12 runs are the most scored for a single team in the SEC Tournament since Arkansas scored 13 last year. • LSU hitters combined for 12 hits, with seven different batters earning a hit and nine different batters scoring. The Tigers combined for 45 hits in the first four games of the contest. • LSU racked up double-digit hits for the 24th time this season. • Four Tiger batters extended their hitting streaks with Josh Smith (8), Saul Garza (7), Brandt Broussard (5) and Zach Watson (4). • Five LSU batters had multi-hit games including Josh Smith (27th; leads team), Antoine Duplantis (22nd), Daniel Cabrera (16th), Saul Garza (10th) and Chris Reid (8th). • Zach Watson batted in his eighth multi-RBI game of the season and has reached base for eight-consecutive games. -
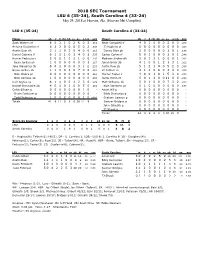
Hoover Met Complex)
2018 SEC Tournament LSU 6 (35-24), South Carolina 4 (33-24) May 24, 2018 at Hoover, Ala. (Hoover Met Complex) LSU 6 (35-24) South Carolina 4 (33-24) Player ab r h rbi bb so po a lob avg Player ab r h rbi bb so po a lob avg Zach Watson cf 6 0 2 1 0 2 6 0 3 .312 Noah Campbell lf 4 0 1 0 0 0 2 0 0 .280 Antoine Duplantis rf 6 2 2 0 0 0 5 0 2 .336 TJ Hopkins cf 0 0 0 0 0 0 0 0 0 .345 Austin Bain dh 3 1 1 0 3 0 4 0 0 .315 Danny Blair ph 2 0 0 0 0 0 1 0 1 .186 Daniel Cabrera lf 6 1 2 1 0 1 4 0 1 .335 Carlos Cortes rf 6 0 1 0 0 0 1 0 1 .244 Hunter Feduccia c 2 0 0 1 1 2 1 0 0 .243 Madison Stokes dh 5 0 1 1 1 0 0 0 1 .342 Beau Jordan ph 1 0 0 0 0 0 0 0 1 .307 Jonah Bride 3b 4 1 0 0 1 2 1 3 1 .302 Jake Slaughter 3b 6 0 1 0 0 0 3 1 2 .253 Justin Row 2b 5 1 2 1 0 0 5 2 3 .338 Bryce Jordan 1b 1 1 0 0 3 0 7 0 0 .262 LT Tolbert ss 4 1 1 0 0 0 3 4 0 .320 Nick Webre pr 0 0 0 0 0 0 0 0 0 .294 Hunter Taylor c 4 0 0 1 0 1 5 3 0 .273 Nick Coomes 1b 1 0 0 0 0 0 4 0 0 .250 Jacob Olson cf 5 0 1 1 0 0 11 0 0 .223 Hal Hughes ss 4 1 1 0 0 1 2 3 0 .229 Matt Williams 1b 5 0 1 0 0 0 7 3 2 .234 Brandt Broussard 2b 4 0 1 0 1 0 0 5 0 .261 Kyle Jacobsen pr 0 1 0 0 0 0 0 0 0 .158 Caleb Gilbert p 0 0 0 0 0 0 0 1 0 - Adam Hill p 0 0 0 0 0 0 0 0 0 - Devin Fontenot p 0 0 0 0 0 0 0 0 0 - Eddy Demurias p 0 0 0 0 0 0 0 0 0 - Todd Peterson p 1 0 1 2 0 0 0 1 0 1000 Graham Lawson p 0 0 0 0 0 0 0 0 0 - Totals 41 6 11 5 8 6 36 11 9 Sawyer Bridges p 0 0 0 0 0 0 0 0 0 - John Gilreath p 0 0 0 0 0 0 0 0 0 - TJ Shook p 0 0 0 0 0 0 0 0 0 - Totals 44 4 8 4 2 3 36 15 9 Score by Innings 1 2 3 4 5 6 7 8 9 10 11 12 R H E LSU 0 2 0 0 0 0 0 1 0 0 0 3 6 11 1 South Carolina 0 0 0 1 0 1 0 0 1 0 0 1 4 8 2 E - Hughes(9); Tolbert(6); Hill(1).