A Review on Big Data Analytics in the Field of Agriculture
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Horn: a System for Parallel Training and Regularizing of Large-Scale Neural Networks
Horn: A System for Parallel Training and Regularizing of Large-Scale Neural Networks Edward J. Yoon [email protected] I Am ● Edward J. Yoon ● Member and Vice President of Apache Software Foundation ● Committer, PMC, Mentor of ○ Apache Hama ○ Apache Bigtop ○ Apache Rya ○ Apache Horn ○ Apache MRQL ● Keywords: big data, cloud, machine learning, database What is Apache Software Foundation? The Apache Software Foundation is an Non-profit foundation that is dedicated to open source software development 1) What Apache Software Foundation is, 2) Which projects are being developed, 3) What’s HORN? 4) and How to contribute them. Apache HTTP Server (NCSA HTTPd) powers nearly 500+ million websites (There are 644 million websites on the Internet) And Now! 161 Top Level Projects, 108 SubProjects, 39 Incubating Podlings, 4700+ Committers, 550 ASF Members Unknown number of developers and users Domain Diversity Programming Language Diversity Which projects are being developed? What’s HORN? ● Oct 2015, accepted as Apache Incubator Project ● Was born from Apache Hama ● A System for Deep Neural Networks ○ A neuron-level abstraction framework ○ Written in Java :/ ○ Works on distributed environments Apache Hama 1. K-means clustering Hama is 1,000x faster than Apache Mahout At UT Arlington & Oracle 2013 2. PageRank on 10 Billion edges Graph Hama is 3x faster than Facebook’s Giraph At Samsung Electronics (Yoon & Kim) 2015 3. Top-k Set Similarity Joins on Flickr Hama is clearly faster than Apache Spark At IEEE 2015 (University of Melbourne) Why we do this? 1. How to parallelize the training of large models? 2. How to avoid overfitting due to large size of the network, even with large datasets? JonathanNet Distributed Training Parameter Server Parameter Server Parameter Swapping Task 5 Each group performs Task 2 Task 4 Task 3 .. -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Projects – Other Than Hadoop! Created By:-Samarjit Mahapatra [email protected]
Projects – other than Hadoop! Created By:-Samarjit Mahapatra [email protected] Mostly compatible with Hadoop/HDFS Apache Drill - provides low latency ad-hoc queries to many different data sources, including nested data. Inspired by Google's Dremel, Drill is designed to scale to 10,000 servers and query petabytes of data in seconds. Apache Hama - is a pure BSP (Bulk Synchronous Parallel) computing framework on top of HDFS for massive scientific computations such as matrix, graph and network algorithms. Akka - a toolkit and runtime for building highly concurrent, distributed, and fault tolerant event-driven applications on the JVM. ML-Hadoop - Hadoop implementation of Machine learning algorithms Shark - is a large-scale data warehouse system for Spark designed to be compatible with Apache Hive. It can execute Hive QL queries up to 100 times faster than Hive without any modification to the existing data or queries. Shark supports Hive's query language, metastore, serialization formats, and user-defined functions, providing seamless integration with existing Hive deployments and a familiar, more powerful option for new ones. Apache Crunch - Java library provides a framework for writing, testing, and running MapReduce pipelines. Its goal is to make pipelines that are composed of many user-defined functions simple to write, easy to test, and efficient to run Azkaban - batch workflow job scheduler created at LinkedIn to run their Hadoop Jobs Apache Mesos - is a cluster manager that provides efficient resource isolation and sharing across distributed applications, or frameworks. It can run Hadoop, MPI, Hypertable, Spark, and other applications on a dynamically shared pool of nodes. -

Optimizing Resource Utilization in Distributed Computing Systems For
THESE` DE DOCTORAT DE L’ETABLISSEMENT´ UNIVERSITE´ BOURGOGNE FRANCHE-COMTE´ PREPAR´ EE´ A` L’UNIVERSITE´ DE FRANCHE-COMTE´ Ecole´ doctorale n°37 Sciences Pour l’Ingenieur´ et Microtechniques Doctorat d’Informatique par ANTHONY NASSAR Optimizing Resource Utilization in Distributed Computing Systems for Automotive Applications Optimisation de l’utilisation des ressources dans les systemes` informatiques distribues´ pour les applications automobiles These` present´ ee´ et soutenue publiquement le 04-02-2021 a` Belfort, devant le Jury compose´ de : MR CERIN CHRISTOPHE Professeur a` l’Universite´ Sorbonne Paris Nord President´ MR CHBEIR RICHARD Professeur a` l’Universite´ de Pau et des Pays de l’Adour Rapporteur MME BENBERNOU SALIMA Professeur a` l’Universite´ Paris-Descartes Rapporteur MR MOSTEFAOUI AHMED Maˆıtre de conferences´ a` l’Universite´ de Franche-Comte´ Directeur de these` MR DESSABLES FRANC¸ OIS Ingenieur´ chez Groupe PSA Codirecteur de these` DOCTORAL THESIS OF THE UNIVERSITY BOURGOGNE FRANCHE-COMTE´ INSTITUTION PREPARED AT UNIVERSITE´ DE FRANCHE-COMTE´ Doctoral school n°37 Engineering Sciences and Microtechnologies Computer Science Doctorate by ANTHONY NASSAR Optimizing Resource Utilization in Distributed Computing Systems for Automotive Applications Optimisation de l’utilisation des ressources dans les systemes` informatiques distribues´ pour les applications automobiles Thesis presented and publicly defended in Belfort, on 04-02-2021 Composition of the Jury : CERIN CHRISTOPHE Professor at Universite´ Sorbonne Paris Nord President -

Graft: a Debugging Tool for Apache Giraph
Graft: A Debugging Tool For Apache Giraph Semih Salihoglu, Jaeho Shin, Vikesh Khanna, Ba Quan Truong, Jennifer Widom Stanford University {semih, jaeho.shin, vikesh, bqtruong, widom}@cs.stanford.edu ABSTRACT optional master.compute() function is executed by the Master We address the problem of debugging programs written for Pregel- task between supersteps. like systems. After interviewing Giraph and GPS users, we devel- We have tackled the challenge of debugging programs written oped Graft. Graft supports the debugging cycle that users typically for Pregel-like systems. Despite being a core component of pro- go through: (1) Users describe programmatically the set of vertices grammers’ development cycles, very little work has been done on they are interested in inspecting. During execution, Graft captures debugging in these systems. We interviewed several Giraph and the context information of these vertices across supersteps. (2) Us- GPS programmers (hereafter referred to as “users”) and studied vertex.compute() ing Graft’s GUI, users visualize how the values and messages of the how they currently debug their functions. captured vertices change from superstep to superstep,narrowing in We found that the following three steps were common across users: suspicious vertices and supersteps. (3) Users replay the exact lines (1) Users add print statements to their code to capture information of the vertex.compute() function that executed for the sus- about a select set of potentially “buggy” vertices, e.g., vertices that picious vertices and supersteps, by copying code that Graft gener- are assigned incorrect values, send incorrect messages, or throw ates into their development environments’ line-by-line debuggers. -
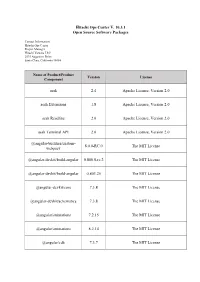
Open Source Software Packages
Hitachi Ops Center V. 10.3.1 Open Source Software Packages Contact Information: Hitachi Ops Center Project Manager Hitachi Vantara LLC 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component aesh 2.4 Apache License, Version 2.0 aesh Extensions 1.8 Apache License, Version 2.0 aesh Readline 2.0 Apache License, Version 2.0 aesh Terminal API 2.0 Apache License, Version 2.0 @angular-builders/custom- 8.0.0-RC.0 The MIT License webpack @angular-devkit/build-angular 0.800.0-rc.2 The MIT License @angular-devkit/build-angular 0.803.25 The MIT License @angular-devkit/core 7.3.8 The MIT License @angular-devkit/schematics 7.3.8 The MIT License @angular/animations 7.2.15 The MIT License @angular/animations 8.2.14 The MIT License @angular/cdk 7.3.7 The MIT License Name of Product/Product Version License Component @angular/cli 8.0.0 The MIT License @angular/cli 8.3.25 The MIT License @angular/common 7.2.15 The MIT License @angular/common 8.2.14 The MIT License @angular/compiler 7.2.15 The MIT License @angular/compiler 8.2.14 The MIT License @angular/compiler-cli 8.2.14 The MIT License @angular/core 7.2.15 The MIT License @angular/forms 7.2.13 The MIT License @angular/forms 7.2.15 The MIT License @angular/forms 8.2.14 The MIT License @angular/forms 8.2.7 The MIT License @angular/language-service 8.2.14 The MIT License @angular/platform-browser 7.2.15 The MIT License @angular/platform-browser 8.2.14 The MIT License Name of Product/Product Version License Component @angular/platform-browser- 7.2.15 The MIT License -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Apache Hbase ™ Reference Guide
Apache HBase ™ Reference Guide Apache HBase Team Version 2.1.9 Contents Preface. 1 Getting Started. 3 1. Introduction . 4 2. Quick Start - Standalone HBase . 5 Apache HBase Configuration. 18 3. Configuration Files . 19 4. Basic Prerequisites . 21 5. HBase run modes: Standalone and Distributed . 27 6. Running and Confirming Your Installation. 31 7. Default Configuration . 32 8. Example Configurations. 72 9. The Important Configurations . 74 10. Dynamic Configuration . 82 Upgrading. 85 11. HBase version number and compatibility. 86 12. Rollback . 92 13. Upgrade Paths . 96 The Apache HBase Shell . 108 14. Scripting with Ruby . 109 15. Running the Shell in Non-Interactive Mode . 110 16. HBase Shell in OS Scripts. 111 17. Read HBase Shell Commands from a Command File . 113 18. Passing VM Options to the Shell. 115 19. Overriding configuration starting the HBase Shell. 116 20. Shell Tricks . 117 Data Model. 123 21. Conceptual View . 124 22. Physical View . 126 23. Namespace . 127 24. Table . 129 25. Row . 130 26. Column Family . 131 27. Cells. 132 28. Data Model Operations . 133 29. Versions . 135 30. Sort Order . 140 31. Column Metadata . 141 32. Joins . 142 33. ACID . 143 HBase and Schema Design . 144 34. Schema Creation . 145 35. Table Schema Rules Of Thumb . 146 RegionServer Sizing Rules of Thumb . 147 36. On the number of column families. 148 37. Rowkey Design . 149 38. Number of Versions . 156 39. Supported Datatypes . 157 40. Joins . 158 41. Time To Live (TTL) . 159 42. Keeping Deleted Cells . 160 43. Secondary Indexes and Alternate Query Paths . 164 44. Constraints . .. -

Classifying, Evaluating and Advancing Big Data Benchmarks
Classifying, Evaluating and Advancing Big Data Benchmarks Dissertation zur Erlangung des Doktorgrades der Naturwissenschaften vorgelegt beim Fachbereich 12 Informatik der Johann Wolfgang Goethe-Universität in Frankfurt am Main von Todor Ivanov aus Stara Zagora Frankfurt am Main 2019 (D 30) vom Fachbereich 12 Informatik der Johann Wolfgang Goethe-Universität als Dissertation angenommen. Dekan: Prof. Dr. Andreas Bernig Gutachter: Prof. Dott. -Ing. Roberto V. Zicari Prof. Dr. Carsten Binnig Datum der Disputation: 23.07.2019 Abstract The main contribution of the thesis is in helping to understand which software system parameters mostly affect the performance of Big Data Platforms under realistic workloads. In detail, the main research contributions of the thesis are: 1. Definition of the new concept of heterogeneity for Big Data Architectures (Chapter 2); 2. Investigation of the performance of Big Data systems (e.g. Hadoop) in virtual- ized environments (Section 3.1); 3. Investigation of the performance of NoSQL databases versus Hadoop distribu- tions (Section 3.2); 4. Execution and evaluation of the TPCx-HS benchmark (Section 3.3); 5. Evaluation and comparison of Hive and Spark SQL engines using benchmark queries (Section 3.4); 6. Evaluation of the impact of compression techniques on SQL-on-Hadoop engine performance (Section 3.5); 7. Extensions of the standardized Big Data benchmark BigBench (TPCx-BB) (Section 4.1 and 4.3); 8. Definition of a new benchmark, called ABench (Big Data Architecture Stack Benchmark), that takes into account the heterogeneity of Big Data architectures (Section 4.5). The thesis is an attempt to re-define system benchmarking taking into account the new requirements posed by the Big Data applications. -

Harp: Collective Communication on Hadoop
HHarp:arp: CollectiveCollective CommunicationCommunication onon HadooHadoopp Judy Qiu, Indiana University SA OutlineOutline • Machine Learning on Big Data • Big Data Tools • Iterative MapReduce model • MDS Demo • Harp SA MachineMachine LearningLearning onon BigBig DataData • Mahout on Hadoop • https://mahout.apache.org/ • MLlib on Spark • http://spark.apache.org/mllib/ • GraphLab Toolkits • http://graphlab.org/projects/toolkits.html • GraphLab Computer Vision Toolkit SA World Data DAG Model MapReduce Model Graph Model BSP/Collective Mode Hadoop MPI HaLoop Giraph Twister Hama or GraphLab ions/ ions/ Spark GraphX ning Harp Stratosphere Dryad/ Reef DryadLIN Q Pig/PigLatin Hive Query Tez Drill Shark MRQL S4 Storm or ming Samza Spark Streaming BigBig DataData ToolsTools forfor HPCHPC andand SupercomputingSupercomputing • MPI(Message Passing Interface, 1992) • Provide standardized function interfaces for communication between parallel processes. • Collective communication operations • Broadcast, Scatter, Gather, Reduce, Allgather, Allreduce, Reduce‐scatter. • Popular implementations • MPICH (2001) • OpenMPI (2004) • http://www.open‐mpi.org/ SA MapReduceMapReduce ModelModel Google MapReduce (2004) • Jeffrey Dean et al. MapReduce: Simplified Data Processing on Large Clusters. OSDI 2004. Apache Hadoop (2005) • http://hadoop.apache.org/ • http://developer.yahoo.com/hadoop/tutorial/ Apache Hadoop 2.0 (2012) • Vinod Kumar Vavilapalli et al. Apache Hadoop YARN: Yet Another Resource Negotiator, SO 2013. • Separation between resource management and computation -

20-Graph-Computing-S
Distributed Systems 20. Other parallel frameworks Paul Krzyzanowski Rutgers University Fall 2017 November 20, 2017 © 2014-2017 Paul Krzyzanowski 1 Can we make MapReduce easier? 2 Apache Pig • Why? – Make it easy to use MapReduce via scripting instead of Java – Make it easy to use multiple MapReduce stages – Built-in common operations for join, group, filter, etc. • How to use? – Use Grunt – the pig shell – Submit a script directly to pig – Use the PigServer Java class – PigPen – Eclipse plugin • Pig compiles to several Hadoop MapReduce jobs 3 Apache Pig Count Job Pig Framework Hadoop (in Pig Latin) Execution • Parse A = LOAD ‘myfile’ AS (x, y, z); • Check • Map: Filter B = FILTER A by x>0; • Optimize • Reduce: Counter C = GROUP B by x; • Plan Execution D = FOREACH A GENERATE • Submit jar to Hadoop x, COUNT(B); • Monitor progress STORE D into ’output’; 4 Pig: Loading Data Load/store relations in the following formats: • PigStorage: field-delimited text • BinStorage: binary files • BinaryStorage: single-field tuples with a value of bytearray • TextLoader: plain-text • PigDump: stores using toString() on tuples, one per line 5 Example log = LOAD ‘test.log’ AS (user, timestamp, query); grpd = GROUP log by user; cntd = FOREACH grpd GENERATE group, COUNT(log); fltrd = FILTER cntd BY cnt > 50; srtd = ORDER fltrd BY cnt; STORE srtd INTO ‘output’; • Each statement defines a new dataset – Datasets can be given aliases to be used later • FOREACH iterates over the members of a ”bag” – Input is grpd: list of log entries grouped by user – Output is -

Project Dependencies file:///Home/Jhh/Onap/Git/Policy/Apex-Pdp/Package
Dependencies – Project Dependencies file:///home/jhh/onap/git/policy/apex-pdp/package... Project Dependencies compile The following is a list of compile dependencies for this project. These dependencies are required to compile and run the application: GroupId ArtifactId Version Type Licenses ch.qos.logback logback-classic 1.2.3 jar Eclipse Public License - v 1.0 GNU Lesser General Public License ch.qos.logback logback-core 1.2.3 jar Eclipse Public License - v 1.0 GNU Lesser General Public License org.onap.policy.apex-pdp.auth cli-editor 2.2.1- jar - SNAPSHOT org.onap.policy.apex-pdp.client client-deployment 2.2.1- war - SNAPSHOT org.onap.policy.apex-pdp.client client-editor 2.2.1- war - SNAPSHOT org.onap.policy.apex-pdp.client client-full 2.2.1- war - SNAPSHOT org.onap.policy.apex-pdp.client client-monitoring 2.2.1- war - SNAPSHOT org.onap.policy.apex-pdp.examples examples-aadm 2.2.1- jar - SNAPSHOT org.onap.policy.apex-pdp.examples examples-adaptive 2.2.1- jar - SNAPSHOT org.onap.policy.apex-pdp.examples examples- 2.2.1- jar - decisionmaker SNAPSHOT org.onap.policy.apex-pdp.examples examples- 2.2.1- jar - myfirstpolicy SNAPSHOT org.onap.policy.apex-pdp.examples examples-onap-bbs 2.2.1- jar - SNAPSHOT org.onap.policy.apex-pdp.examples examples-onap-vcpe 2.2.1- jar - SNAPSHOT org.onap.policy.apex-pdp.examples examples-pcvs 2.2.1- jar - SNAPSHOT org.onap.policy.apex-pdp.examples examples-periodic 2.2.1- jar - SNAPSHOT org.onap.policy.apex-pdp.examples examples-servlet 2.2.1- war - SNAPSHOT org.onap.policy.apex-pdp.plugins.plugins- plugins-context- 2.2.1- jar - context.plugins-context-distribution distribution-hazelcast SNAPSHOT org.onap.policy.apex-pdp.plugins.plugins- plugins-context- 2.2.1- jar - context.plugins-context-distribution distribution-infinispan SNAPSHOT 1 of 26 8/19/19, 6:29 PM Dependencies – Project Dependencies file:///home/jhh/onap/git/policy/apex-pdp/package..