Public-Key Cryptosystems Provably Secure Against Chosen Ciphertext Attacks∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Classical Encryption Techniques
CPE 542: CRYPTOGRAPHY & NETWORK SECURITY Chapter 2: Classical Encryption Techniques Dr. Lo’ai Tawalbeh Computer Engineering Department Jordan University of Science and Technology Jordan Dr. Lo’ai Tawalbeh Fall 2005 Introduction Basic Terminology • plaintext - the original message • ciphertext - the coded message • key - information used in encryption/decryption, and known only to sender/receiver • encipher (encrypt) - converting plaintext to ciphertext using key • decipher (decrypt) - recovering ciphertext from plaintext using key • cryptography - study of encryption principles/methods/designs • cryptanalysis (code breaking) - the study of principles/ methods of deciphering ciphertext Dr. Lo’ai Tawalbeh Fall 2005 1 Cryptographic Systems Cryptographic Systems are categorized according to: 1. The operation used in transferring plaintext to ciphertext: • Substitution: each element in the plaintext is mapped into another element • Transposition: the elements in the plaintext are re-arranged. 2. The number of keys used: • Symmetric (private- key) : both the sender and receiver use the same key • Asymmetric (public-key) : sender and receiver use different key 3. The way the plaintext is processed : • Block cipher : inputs are processed one block at a time, producing a corresponding output block. • Stream cipher: inputs are processed continuously, producing one element at a time (bit, Dr. Lo’ai Tawalbeh Fall 2005 Cryptographic Systems Symmetric Encryption Model Dr. Lo’ai Tawalbeh Fall 2005 2 Cryptographic Systems Requirements • two requirements for secure use of symmetric encryption: 1. a strong encryption algorithm 2. a secret key known only to sender / receiver •Y = Ek(X), where X: the plaintext, Y: the ciphertext •X = Dk(Y) • assume encryption algorithm is known •implies a secure channel to distribute key Dr. -

Anna Lysyanskaya Curriculum Vitae
Anna Lysyanskaya Curriculum Vitae Computer Science Department, Box 1910 Brown University Providence, RI 02912 (401) 863-7605 email: [email protected] http://www.cs.brown.edu/~anna Research Interests Cryptography, privacy, computer security, theory of computation. Education Massachusetts Institute of Technology Cambridge, MA Ph.D. in Computer Science, September 2002 Advisor: Ronald L. Rivest, Viterbi Professor of EECS Thesis title: \Signature Schemes and Applications to Cryptographic Protocol Design" Massachusetts Institute of Technology Cambridge, MA S.M. in Computer Science, June 1999 Smith College Northampton, MA A.B. magna cum laude, Highest Honors, Phi Beta Kappa, May 1997 Appointments Brown University, Providence, RI Fall 2013 - Present Professor of Computer Science Brown University, Providence, RI Fall 2008 - Spring 2013 Associate Professor of Computer Science Brown University, Providence, RI Fall 2002 - Spring 2008 Assistant Professor of Computer Science UCLA, Los Angeles, CA Fall 2006 Visiting Scientist at the Institute for Pure and Applied Mathematics (IPAM) Weizmann Institute, Rehovot, Israel Spring 2006 Visiting Scientist Massachusetts Institute of Technology, Cambridge, MA 1997 { 2002 Graduate student IBM T. J. Watson Research Laboratory, Hawthorne, NY Summer 2001 Summer Researcher IBM Z¨urich Research Laboratory, R¨uschlikon, Switzerland Summers 1999, 2000 Summer Researcher 1 Teaching Brown University, Providence, RI Spring 2008, 2011, 2015, 2017, 2019; Fall 2012 Instructor for \CS 259: Advanced Topics in Cryptography," a seminar course for graduate students. Brown University, Providence, RI Spring 2012 Instructor for \CS 256: Advanced Complexity Theory," a graduate-level complexity theory course. Brown University, Providence, RI Fall 2003,2004,2005,2010,2011 Spring 2007, 2009,2013,2014,2016,2018 Instructor for \CS151: Introduction to Cryptography and Computer Security." Brown University, Providence, RI Fall 2016, 2018 Instructor for \CS 101: Theory of Computation," a core course for CS concentrators. -

Malicious Cryptography: Kleptographic Aspects
Malicious Cryptography: Kleptographic Aspects Adam Young1 and Moti Yung2 1 Cigital Labs [email protected] 2 Dept. of Computer Science, Columbia University [email protected] Abstract. In the last few years we have concentrated our research ef- forts on new threats to the computing infrastructure that are the result of combining malicious software (malware) technology with modern cryp- tography. At some point during our investigation we ended up asking ourselves the following question: what if the malware (i.e., Trojan horse) resides within a cryptographic system itself? This led us to realize that in certain scenarios of black box cryptography (namely, when the code is inaccessible to scrutiny as in the case of tamper proof cryptosystems or when no one cares enough to scrutinize the code) there are attacks that employ cryptography itself against cryptographic systems in such a way that the attack possesses unique properties (i.e., special advantages that attackers have such as granting the attacker exclusive access to crucial information where the exclusive access privelege holds even if the Trojan is reverse-engineered). We called the art of designing this set of attacks “kleptography.” In this paper we demonstrate the power of kleptography by illustrating a carefully designed attack against RSA key generation. Keywords: RSA, Rabin, public key cryptography, SETUP, kleptogra- phy, random oracle, security threats, attacks, malicious cryptography. 1 Introduction Robust backdoor attacks against cryptosystems have received the attention of the cryptographic research community, but to this day have not influenced in- dustry standards and as a result the industry is not as prepared for them as it could be. -

Chapter 2: an Implementation of Cryptoviral Extortion Using Microsoft's Crypto API∗
Chapter 2: An Implementation of Cryptoviral Extortion Using Microsoft's Crypto API∗ Adam L. Young and Moti M. Yung Abstract This chapter presents an experimental implementation of cryptovi- ral extortion, an attack that we devised and presented at the 1996 IEEE Symposium on Security & Privacy [16] and that was recently covered in Malicious Cryptography [17]. The design is based on Mi- crosoft's Cryptographic API and the salient aspects of the implemen- tation were presented at ISC '05 [14] and were later refined in the International Journal of Information Security [15]. Cryptoviral extor- tion is a 2-party protocol between an attacker and a victim that is carried out by a cryptovirus, cryptoworm, or cryptotrojan. In a cryp- toviral extortion attack the malware hybrid encrypts the plaintext of the victim using the public key of the attacker. The attacker extorts some form of payment from the victim in return for the plaintext that is held hostage. In addition to providing hands-on experience with this cryptographic protocol, this chapter gives readers a chance to: (1) learn the basics of hybrid encryption that is commonly used in every- thing from secure e-mail applications to secure socket connections, and (2) gain a basic understanding of how to use Microsoft's Cryptographic API that is present in modern MS Windows operating systems. The chapter only provides an experimental version of the payload, no self- replicating code is given. We conclude with proactive measures that can be taken by computer users and computer manufacturers alike to minimize the threat posed by this type of cryptovirology attack. -

Cyber Security Cryptography and Machine Learning
Lecture Notes in Computer Science 12716 Founding Editors Gerhard Goos Karlsruhe Institute of Technology, Karlsruhe, Germany Juris Hartmanis Cornell University, Ithaca, NY, USA Editorial Board Members Elisa Bertino Purdue University, West Lafayette, IN, USA Wen Gao Peking University, Beijing, China Bernhard Steffen TU Dortmund University, Dortmund, Germany Gerhard Woeginger RWTH Aachen, Aachen, Germany Moti Yung Columbia University, New York, NY, USA More information about this subseries at http://www.springer.com/series/7410 Shlomi Dolev · Oded Margalit · Benny Pinkas · Alexander Schwarzmann (Eds.) Cyber Security Cryptography and Machine Learning 5th International Symposium, CSCML 2021 Be’er Sheva, Israel, July 8–9, 2021 Proceedings Editors Shlomi Dolev Oded Margalit Ben-Gurion University of the Negev Ben-Gurion University of the Negev Be’er Sheva, Israel Be’er Sheva, Israel Benny Pinkas Alexander Schwarzmann Bar-Ilan University Augusta University Tel Aviv, Israel Augusta, GA, USA ISSN 0302-9743 ISSN 1611-3349 (electronic) Lecture Notes in Computer Science ISBN 978-3-030-78085-2 ISBN 978-3-030-78086-9 (eBook) https://doi.org/10.1007/978-3-030-78086-9 LNCS Sublibrary: SL4 – Security and Cryptology © Springer Nature Switzerland AG 2021 This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. The use of general descriptive names, registered names, trademarks, service marks, etc. -

CHURP: Dynamic-Committee Proactive Secret Sharing
CHURP: Dynamic-Committee Proactive Secret Sharing Sai Krishna Deepak Maram∗† Cornell Tech Fan Zhang∗† Lun Wang∗ Andrew Low∗ Cornell Tech UC Berkeley UC Berkeley Yupeng Zhang∗ Ari Juels∗ Dawn Song∗ Texas A&M Cornell Tech UC Berkeley ABSTRACT most important resources—money, identities [6], etc. Their loss has We introduce CHURP (CHUrn-Robust Proactive secret sharing). serious and often irreversible consequences. CHURP enables secure secret-sharing in dynamic settings, where the An estimated four million Bitcoin (today worth $14+ Billion) have committee of nodes storing a secret changes over time. Designed for vanished forever due to lost keys [69]. Many users thus store their blockchains, CHURP has lower communication complexity than pre- cryptocurrency with exchanges such as Coinbase, which holds at vious schemes: O¹nº on-chain and O¹n2º off-chain in the optimistic least 10% of all circulating Bitcoin [9]. Such centralized key storage case of no node failures. is also undesirable: It erodes the very decentralization that defines CHURP includes several technical innovations: An efficient new blockchain systems. proactivization scheme of independent interest, a technique (using An attractive alternative is secret sharing. In ¹t;nº-secret sharing, asymmetric bivariate polynomials) for efficiently changing secret- a committee of n nodes holds shares of a secret s—usually encoded sharing thresholds, and a hedge against setup failures in an efficient as P¹0º of a polynomial P¹xº [73]. An adversary must compromise polynomial commitment scheme. We also introduce a general new at least t +1 players to steal s, and at least n−t shares must be lost technique for inexpensive off-chain communication across the peer- to render s unrecoverable. -

Improved Threshold Signatures, Proactive Secret Sharing, and Input Certification from LSS Isomorphisms
Improved Threshold Signatures, Proactive Secret Sharing, and Input Certification from LSS Isomorphisms Diego F. Aranha1, Anders Dalskov2, Daniel Escudero1, and Claudio Orlandi1 1 Aarhus University, Denmark 2 Partisia, Denmark Abstract. In this paper we present a series of applications steming from a formal treatment of linear secret-sharing isomorphisms, which are linear transformations between different secret-sharing schemes defined over vector spaces over a field F and allow for efficient multiparty conversion from one secret-sharing scheme to the other. This concept generalizes the folklore idea that moving from a secret-sharing scheme over Fp to a secret sharing \in the exponent" can be done non-interactively by multiplying the share unto a generator of e.g., an elliptic curve group. We generalize this idea and show that it can also be used to compute arbitrary bilinear maps and in particular pairings over elliptic curves. We include the following practical applications originating from our framework: First we show how to securely realize the Pointcheval-Sanders signature scheme (CT-RSA 2016) in MPC. Second we present a construc- tion for dynamic proactive secret-sharing which outperforms the current state of the art from CCS 2019. Third we present a construction for MPC input certification using digital signatures that we show experimentally to outperform the previous best solution in this area. 1 Introduction A(t; n)-secure secret-sharing scheme allows a secret to be distributed into n shares in such a way that any set of at most t shares are independent of the secret, but any set of at least t + 1 shares together can completely reconstruct the secret. -

Index-Of-Coincidence.Pdf
The Index of Coincidence William F. Friedman in the 1930s developed the index of coincidence. For a given text X, where X is the sequence of letters x1x2…xn, the index of coincidence IC(X) is defined to be the probability that two randomly selected letters in the ciphertext represent, the same plaintext symbol. For a given ciphertext of length n, let n0, n1, …, n25 be the respective letter counts of A, B, C, . , Z in the ciphertext. Then, the index of coincidence can be computed as 25 ni (ni −1) IC = ∑ i=0 n(n −1) We can also calculate this index for any language source. For some source of letters, let p be the probability of occurrence of the letter a, p be the probability of occurrence of a € b the letter b, and so on. Then the index of coincidence for this source is 25 2 Isource = pa pa + pb pb +…+ pz pz = ∑ pi i=0 We can interpret the index of coincidence as the probability of randomly selecting two identical letters from the source. To see why the index of coincidence gives us useful information, first€ note that the empirical probability of randomly selecting two identical letters from a large English plaintext is approximately 0.065. This implies that an (English) ciphertext having an index of coincidence I of approximately 0.065 is probably associated with a mono-alphabetic substitution cipher, since this statistic will not change if the letters are simply relabeled (which is the effect of encrypting with a simple substitution). The longer and more random a Vigenere cipher keyword is, the more evenly the letters are distributed throughout the ciphertext. -

Automating the Development of Chosen Ciphertext Attacks
Automating the Development of Chosen Ciphertext Attacks Gabrielle Beck∗ Maximilian Zinkus∗ Matthew Green Johns Hopkins University Johns Hopkins University Johns Hopkins University [email protected] [email protected] [email protected] Abstract In this work we consider a specific class of vulner- ability: the continued use of unauthenticated symmet- In this work we investigate the problem of automating the ric encryption in many cryptographic systems. While development of adaptive chosen ciphertext attacks on sys- the research community has long noted the threat of tems that contain vulnerable format oracles. Unlike pre- adaptive-chosen ciphertext attacks on malleable en- vious attempts, which simply automate the execution of cryption schemes [17, 18, 56], these concerns gained known attacks, we consider a more challenging problem: practical salience with the discovery of padding ora- to programmatically derive a novel attack strategy, given cle attacks on a number of standard encryption pro- only a machine-readable description of the plaintext veri- tocols [6,7, 13, 22, 30, 40, 51, 52, 73]. Despite repeated fication function and the malleability characteristics of warnings to industry, variants of these attacks continue to the encryption scheme. We present a new set of algo- plague modern systems, including TLS 1.2’s CBC-mode rithms that use SAT and SMT solvers to reason deeply ciphersuite [5,7, 48] and hardware key management to- over the design of the system, producing an automated kens [10, 13]. A generalized variant, the format oracle attack strategy that can entirely decrypt protected mes- attack can be constructed when a decryption oracle leaks sages. -
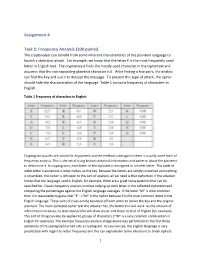
Assignment 4 Task 1: Frequency Analysis (100 Points)
Assignment 4 Task 1: Frequency Analysis (100 points) The cryptanalyst can benefit from some inherent characteristics of the plaintext language to launch a statistical attack. For example, we know that the letter E is the most frequently used letter in English text. The cryptanalyst finds the mostly-used character in the ciphertext and assumes that the corresponding plaintext character is E. After finding a few pairs, the analyst can find the key and use it to decrypt the message. To prevent this type of attack, the cipher should hide the characteristics of the language. Table 1 contains frequency of characters in English. Table 1 Frequency of characters in English Cryptogram puzzles are solved for enjoyment and the method used against them is usually some form of frequency analysis. This is the act of using known statistical information and patterns about the plaintext to determine it. In cryptograms, each letter of the alphabet is encrypted to another letter. This table of letter-letter translations is what makes up the key. Because the letters are simply converted and nothing is scrambled, the cipher is left open to this sort of analysis; all we need is that ciphertext. If the attacker knows that the language used is English, for example, there are a great many patterns that can be searched for. Classic frequency analysis involves tallying up each letter in the collected ciphertext and comparing the percentages against the English language averages. If the letter "M" is most common then it is reasonable to guess that "E"-->"M" in the cipher because E is the most common letter in the English language. -

Chap 2. Basic Encryption and Decryption
Chap 2. Basic Encryption and Decryption H. Lee Kwang Department of Electrical Engineering & Computer Science, KAIST Objectives • Concepts of encryption • Cryptanalysis: how encryption systems are “broken” 2.1 Terminology and Background • Notations – S: sender – R: receiver – T: transmission medium – O: outsider, interceptor, intruder, attacker, or, adversary • S wants to send a message to R – S entrusts the message to T who will deliver it to R – Possible actions of O • block(interrupt), intercept, modify, fabricate • Chapter 1 2.1.1 Terminology • Encryption and Decryption – encryption: a process of encoding a message so that its meaning is not obvious – decryption: the reverse process • encode(encipher) vs. decode(decipher) – encoding: the process of translating entire words or phrases to other words or phrases – enciphering: translating letters or symbols individually – encryption: the group term that covers both encoding and enciphering 2.1.1 Terminology • Plaintext vs. Ciphertext – P(plaintext): the original form of a message – C(ciphertext): the encrypted form • Basic operations – plaintext to ciphertext: encryption: C = E(P) – ciphertext to plaintext: decryption: P = D(C) – requirement: P = D(E(P)) 2.1.1 Terminology • Encryption with key If the encryption algorithm should fall into the interceptor’s – encryption key: KE – decryption key: K hands, future messages can still D be kept secret because the – C = E(K , P) E interceptor will not know the – P = D(KD, E(KE, P)) key value • Keyless Cipher – a cipher that does not require the -

Shift Cipher Substitution Cipher Vigenère Cipher Hill Cipher
Lecture 2 Classical Cryptosystems Shift cipher Substitution cipher Vigenère cipher Hill cipher 1 Shift Cipher • A Substitution Cipher • The Key Space: – [0 … 25] • Encryption given a key K: – each letter in the plaintext P is replaced with the K’th letter following the corresponding number ( shift right ) • Decryption given K: – shift left • History: K = 3, Caesar’s cipher 2 Shift Cipher • Formally: • Let P=C= K=Z 26 For 0≤K≤25 ek(x) = x+K mod 26 and dk(y) = y-K mod 26 ʚͬ, ͭ ∈ ͔ͦͪ ʛ 3 Shift Cipher: An Example ABCDEFGHIJKLMNOPQRSTUVWXYZ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 • P = CRYPTOGRAPHYISFUN Note that punctuation is often • K = 11 eliminated • C = NCJAVZRCLASJTDQFY • C → 2; 2+11 mod 26 = 13 → N • R → 17; 17+11 mod 26 = 2 → C • … • N → 13; 13+11 mod 26 = 24 → Y 4 Shift Cipher: Cryptanalysis • Can an attacker find K? – YES: exhaustive search, key space is small (<= 26 possible keys). – Once K is found, very easy to decrypt Exercise 1: decrypt the following ciphertext hphtwwxppelextoytrse Exercise 2: decrypt the following ciphertext jbcrclqrwcrvnbjenbwrwn VERY useful MATLAB functions can be found here: http://www2.math.umd.edu/~lcw/MatlabCode/ 5 General Mono-alphabetical Substitution Cipher • The key space: all possible permutations of Σ = {A, B, C, …, Z} • Encryption, given a key (permutation) π: – each letter X in the plaintext P is replaced with π(X) • Decryption, given a key π: – each letter Y in the ciphertext C is replaced with π-1(Y) • Example ABCDEFGHIJKLMNOPQRSTUVWXYZ πBADCZHWYGOQXSVTRNMSKJI PEFU • BECAUSE AZDBJSZ 6 Strength of the General Substitution Cipher • Exhaustive search is now infeasible – key space size is 26! ≈ 4*10 26 • Dominates the art of secret writing throughout the first millennium A.D.