Chapter 5. Inner Product Spaces and Linear Operators
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Estimations of the Trace of Powers of Positive Self-Adjoint Operators by Extrapolation of the Moments∗
Electronic Transactions on Numerical Analysis. ETNA Volume 39, pp. 144-155, 2012. Kent State University Copyright 2012, Kent State University. http://etna.math.kent.edu ISSN 1068-9613. ESTIMATIONS OF THE TRACE OF POWERS OF POSITIVE SELF-ADJOINT OPERATORS BY EXTRAPOLATION OF THE MOMENTS∗ CLAUDE BREZINSKI†, PARASKEVI FIKA‡, AND MARILENA MITROULI‡ Abstract. Let A be a positive self-adjoint linear operator on a real separable Hilbert space H. Our aim is to build estimates of the trace of Aq, for q ∈ R. These estimates are obtained by extrapolation of the moments of A. Applications of the matrix case are discussed, and numerical results are given. Key words. Trace, positive self-adjoint linear operator, symmetric matrix, matrix powers, matrix moments, extrapolation. AMS subject classifications. 65F15, 65F30, 65B05, 65C05, 65J10, 15A18, 15A45. 1. Introduction. Let A be a positive self-adjoint linear operator from H to H, where H is a real separable Hilbert space with inner product denoted by (·, ·). Our aim is to build estimates of the trace of Aq, for q ∈ R. These estimates are obtained by extrapolation of the integer moments (z, Anz) of A, for n ∈ N. A similar procedure was first introduced in [3] for estimating the Euclidean norm of the error when solving a system of linear equations, which corresponds to q = −2. The case q = −1, which leads to estimates of the trace of the inverse of a matrix, was studied in [4]; on this problem, see [10]. Let us mention that, when only positive powers of A are used, the Hilbert space H could be infinite dimensional, while, for negative powers of A, it is always assumed to be a finite dimensional one, and, obviously, A is also assumed to be invertible. -

5 the Dirac Equation and Spinors
5 The Dirac Equation and Spinors In this section we develop the appropriate wavefunctions for fundamental fermions and bosons. 5.1 Notation Review The three dimension differential operator is : ∂ ∂ ∂ = , , (5.1) ∂x ∂y ∂z We can generalise this to four dimensions ∂µ: 1 ∂ ∂ ∂ ∂ ∂ = , , , (5.2) µ c ∂t ∂x ∂y ∂z 5.2 The Schr¨odinger Equation First consider a classical non-relativistic particle of mass m in a potential U. The energy-momentum relationship is: p2 E = + U (5.3) 2m we can substitute the differential operators: ∂ Eˆ i pˆ i (5.4) → ∂t →− to obtain the non-relativistic Schr¨odinger Equation (with = 1): ∂ψ 1 i = 2 + U ψ (5.5) ∂t −2m For U = 0, the free particle solutions are: iEt ψ(x, t) e− ψ(x) (5.6) ∝ and the probability density ρ and current j are given by: 2 i ρ = ψ(x) j = ψ∗ ψ ψ ψ∗ (5.7) | | −2m − with conservation of probability giving the continuity equation: ∂ρ + j =0, (5.8) ∂t · Or in Covariant notation: µ µ ∂µj = 0 with j =(ρ,j) (5.9) The Schr¨odinger equation is 1st order in ∂/∂t but second order in ∂/∂x. However, as we are going to be dealing with relativistic particles, space and time should be treated equally. 25 5.3 The Klein-Gordon Equation For a relativistic particle the energy-momentum relationship is: p p = p pµ = E2 p 2 = m2 (5.10) · µ − | | Substituting the equation (5.4), leads to the relativistic Klein-Gordon equation: ∂2 + 2 ψ = m2ψ (5.11) −∂t2 The free particle solutions are plane waves: ip x i(Et p x) ψ e− · = e− − · (5.12) ∝ The Klein-Gordon equation successfully describes spin 0 particles in relativistic quan- tum field theory. -

A Some Basic Rules of Tensor Calculus
A Some Basic Rules of Tensor Calculus The tensor calculus is a powerful tool for the description of the fundamentals in con- tinuum mechanics and the derivation of the governing equations for applied prob- lems. In general, there are two possibilities for the representation of the tensors and the tensorial equations: – the direct (symbolic) notation and – the index (component) notation The direct notation operates with scalars, vectors and tensors as physical objects defined in the three dimensional space. A vector (first rank tensor) a is considered as a directed line segment rather than a triple of numbers (coordinates). A second rank tensor A is any finite sum of ordered vector pairs A = a b + ... +c d. The scalars, vectors and tensors are handled as invariant (independent⊗ from the choice⊗ of the coordinate system) objects. This is the reason for the use of the direct notation in the modern literature of mechanics and rheology, e.g. [29, 32, 49, 123, 131, 199, 246, 313, 334] among others. The index notation deals with components or coordinates of vectors and tensors. For a selected basis, e.g. gi, i = 1, 2, 3 one can write a = aig , A = aibj + ... + cidj g g i i ⊗ j Here the Einstein’s summation convention is used: in one expression the twice re- peated indices are summed up from 1 to 3, e.g. 3 3 k k ik ik a gk ∑ a gk, A bk ∑ A bk ≡ k=1 ≡ k=1 In the above examples k is a so-called dummy index. Within the index notation the basic operations with tensors are defined with respect to their coordinates, e. -

18.700 JORDAN NORMAL FORM NOTES These Are Some Supplementary Notes on How to Find the Jordan Normal Form of a Small Matrix. Firs
18.700 JORDAN NORMAL FORM NOTES These are some supplementary notes on how to find the Jordan normal form of a small matrix. First we recall some of the facts from lecture, next we give the general algorithm for finding the Jordan normal form of a linear operator, and then we will see how this works for small matrices. 1. Facts Throughout we will work over the field C of complex numbers, but if you like you may replace this with any other algebraically closed field. Suppose that V is a C-vector space of dimension n and suppose that T : V → V is a C-linear operator. Then the characteristic polynomial of T factors into a product of linear terms, and the irreducible factorization has the form m1 m2 mr cT (X) = (X − λ1) (X − λ2) ... (X − λr) , (1) for some distinct numbers λ1, . , λr ∈ C and with each mi an integer m1 ≥ 1 such that m1 + ··· + mr = n. Recall that for each eigenvalue λi, the eigenspace Eλi is the kernel of T − λiIV . We generalized this by defining for each integer k = 1, 2,... the vector subspace k k E(X−λi) = ker(T − λiIV ) . (2) It is clear that we have inclusions 2 e Eλi = EX−λi ⊂ E(X−λi) ⊂ · · · ⊂ E(X−λi) ⊂ .... (3) k k+1 Since dim(V ) = n, it cannot happen that each dim(E(X−λi) ) < dim(E(X−λi) ), for each e e +1 k = 1, . , n. Therefore there is some least integer ei ≤ n such that E(X−λi) i = E(X−λi) i . -

Trace Inequalities for Matrices
Bull. Aust. Math. Soc. 87 (2013), 139–148 doi:10.1017/S0004972712000627 TRACE INEQUALITIES FOR MATRICES KHALID SHEBRAWI ˛ and HUSSIEN ALBADAWI (Received 23 February 2012; accepted 20 June 2012) Abstract Trace inequalities for sums and products of matrices are presented. Relations between the given inequalities and earlier results are discussed. Among other inequalities, it is shown that if A and B are positive semidefinite matrices then tr(AB)k ≤ minfkAkk tr Bk; kBkk tr Akg for any positive integer k. 2010 Mathematics subject classification: primary 15A18; secondary 15A42, 15A45. Keywords and phrases: trace inequalities, eigenvalues, singular values. 1. Introduction Let Mn(C) be the algebra of all n × n matrices over the complex number field. The singular values of A 2 Mn(C), denoted by s1(A); s2(A);:::; sn(A), are the eigenvalues ∗ 1=2 of the matrix jAj = (A A) arranged in such a way that s1(A) ≥ s2(A) ≥ · · · ≥ sn(A). 2 ∗ ∗ Note that si (A) = λi(A A) = λi(AA ), so for a positive semidefinite matrix A, we have si(A) = λi(A)(i = 1; 2;:::; n). The trace functional of A 2 Mn(C), denoted by tr A or tr(A), is defined to be the sum of the entries on the main diagonal of A and it is well known that the trace of a Pn matrix A is equal to the sum of its eigenvalues, that is, tr A = j=1 λ j(A). Two principal properties of the trace are that it is a linear functional and, for A; B 2 Mn(C), we have tr(AB) = tr(BA). -

Lecture 28: Eigenvalues Allowing Complex Eigenvalues Is Really a Blessing
Math 19b: Linear Algebra with Probability Oliver Knill, Spring 2011 cos(t) sin(t) 2 2 For a rotation A = the characteristic polynomial is λ − 2 cos(α)+1 − sin(t) cos(t) which has the roots cos(α) ± i sin(α)= eiα. Lecture 28: Eigenvalues Allowing complex eigenvalues is really a blessing. The structure is very simple: Fundamental theorem of algebra: For a n × n matrix A, the characteristic We have seen that det(A) = 0 if and only if A is invertible. polynomial has exactly n roots. There are therefore exactly n eigenvalues of A if we count them with multiplicity. The polynomial fA(λ) = det(A − λIn) is called the characteristic polynomial of 1 n n−1 A. Proof One only has to show a polynomial p(z)= z + an−1z + ··· + a1z + a0 always has a root z0 We can then factor out p(z)=(z − z0)g(z) where g(z) is a polynomial of degree (n − 1) and The eigenvalues of A are the roots of the characteristic polynomial. use induction in n. Assume now that in contrary the polynomial p has no root. Cauchy’s integral theorem then tells dz 2πi Proof. If Av = λv,then v is in the kernel of A − λIn. Consequently, A − λIn is not invertible and = =0 . (1) z =r | | | zp(z) p(0) det(A − λIn)=0 . On the other hand, for all r, 2 1 dz 1 2π 1 For the matrix A = , the characteristic polynomial is | | ≤ 2πrmax|z|=r = . (2) z =r 4 −1 | | | zp(z) |zp(z)| min|z|=rp(z) The right hand side goes to 0 for r →∞ because 2 − λ 1 2 det(A − λI2) = det( )= λ − λ − 6 . -

Approximating Spectral Sums of Large-Scale Matrices Using Stochastic Chebyshev Approximations∗
Approximating Spectral Sums of Large-scale Matrices using Stochastic Chebyshev Approximations∗ Insu Han y Dmitry Malioutov z Haim Avron x Jinwoo Shin { March 10, 2017 Abstract Computation of the trace of a matrix function plays an important role in many scientific com- puting applications, including applications in machine learning, computational physics (e.g., lat- tice quantum chromodynamics), network analysis and computational biology (e.g., protein fold- ing), just to name a few application areas. We propose a linear-time randomized algorithm for approximating the trace of matrix functions of large symmetric matrices. Our algorithm is based on coupling function approximation using Chebyshev interpolation with stochastic trace estima- tors (Hutchinson’s method), and as such requires only implicit access to the matrix, in the form of a function that maps a vector to the product of the matrix and the vector. We provide rigorous approximation error in terms of the extremal eigenvalue of the input matrix, and the Bernstein ellipse that corresponds to the function at hand. Based on our general scheme, we provide algo- rithms with provable guarantees for important matrix computations, including log-determinant, trace of matrix inverse, Estrada index, Schatten p-norm, and testing positive definiteness. We experimentally evaluate our algorithm and demonstrate its effectiveness on matrices with tens of millions dimensions. 1 Introduction Given a symmetric matrix A 2 Rd×d and function f : R ! R, we study how to efficiently compute d X Σf (A) = tr(f(A)) = f(λi); (1) i=1 arXiv:1606.00942v2 [cs.DS] 9 Mar 2017 where λ1; : : : ; λd are eigenvalues of A. -

Inner Product Spaces Isaiah Lankham, Bruno Nachtergaele, Anne Schilling (March 2, 2007)
MAT067 University of California, Davis Winter 2007 Inner Product Spaces Isaiah Lankham, Bruno Nachtergaele, Anne Schilling (March 2, 2007) The abstract definition of vector spaces only takes into account algebraic properties for the addition and scalar multiplication of vectors. For vectors in Rn, for example, we also have geometric intuition which involves the length of vectors or angles between vectors. In this section we discuss inner product spaces, which are vector spaces with an inner product defined on them, which allow us to introduce the notion of length (or norm) of vectors and concepts such as orthogonality. 1 Inner product In this section V is a finite-dimensional, nonzero vector space over F. Definition 1. An inner product on V is a map ·, · : V × V → F (u, v) →u, v with the following properties: 1. Linearity in first slot: u + v, w = u, w + v, w for all u, v, w ∈ V and au, v = au, v; 2. Positivity: v, v≥0 for all v ∈ V ; 3. Positive definiteness: v, v =0ifandonlyifv =0; 4. Conjugate symmetry: u, v = v, u for all u, v ∈ V . Remark 1. Recall that every real number x ∈ R equals its complex conjugate. Hence for real vector spaces the condition about conjugate symmetry becomes symmetry. Definition 2. An inner product space is a vector space over F together with an inner product ·, ·. Copyright c 2007 by the authors. These lecture notes may be reproduced in their entirety for non- commercial purposes. 2NORMS 2 Example 1. V = Fn n u =(u1,...,un),v =(v1,...,vn) ∈ F Then n u, v = uivi. -

Math 217: True False Practice Professor Karen Smith 1. a Square Matrix Is Invertible If and Only If Zero Is Not an Eigenvalue. Solution Note: True
(c)2015 UM Math Dept licensed under a Creative Commons By-NC-SA 4.0 International License. Math 217: True False Practice Professor Karen Smith 1. A square matrix is invertible if and only if zero is not an eigenvalue. Solution note: True. Zero is an eigenvalue means that there is a non-zero element in the kernel. For a square matrix, being invertible is the same as having kernel zero. 2. If A and B are 2 × 2 matrices, both with eigenvalue 5, then AB also has eigenvalue 5. Solution note: False. This is silly. Let A = B = 5I2. Then the eigenvalues of AB are 25. 3. If A and B are 2 × 2 matrices, both with eigenvalue 5, then A + B also has eigenvalue 5. Solution note: False. This is silly. Let A = B = 5I2. Then the eigenvalues of A + B are 10. 4. A square matrix has determinant zero if and only if zero is an eigenvalue. Solution note: True. Both conditions are the same as the kernel being non-zero. 5. If B is the B-matrix of some linear transformation V !T V . Then for all ~v 2 V , we have B[~v]B = [T (~v)]B. Solution note: True. This is the definition of B-matrix. 21 2 33 T 6. Suppose 40 2 05 is the matrix of a transformation V ! V with respect to some basis 0 0 1 B = (f1; f2; f3). Then f1 is an eigenvector. Solution note: True. It has eigenvalue 1. The first column of the B-matrix is telling us that T (f1) = f1. -

5-7 the Pythagorean Theorem 5-7 the Pythagorean Theorem
55-7-7 TheThe Pythagorean Pythagorean Theorem Theorem Warm Up Lesson Presentation Lesson Quiz HoltHolt McDougal Geometry Geometry 5-7 The Pythagorean Theorem Warm Up Classify each triangle by its angle measures. 1. 2. acute right 3. Simplify 12 4. If a = 6, b = 7, and c = 12, find a2 + b2 2 and find c . Which value is greater? 2 85; 144; c Holt McDougal Geometry 5-7 The Pythagorean Theorem Objectives Use the Pythagorean Theorem and its converse to solve problems. Use Pythagorean inequalities to classify triangles. Holt McDougal Geometry 5-7 The Pythagorean Theorem Vocabulary Pythagorean triple Holt McDougal Geometry 5-7 The Pythagorean Theorem The Pythagorean Theorem is probably the most famous mathematical relationship. As you learned in Lesson 1-6, it states that in a right triangle, the sum of the squares of the lengths of the legs equals the square of the length of the hypotenuse. a2 + b2 = c2 Holt McDougal Geometry 5-7 The Pythagorean Theorem Example 1A: Using the Pythagorean Theorem Find the value of x. Give your answer in simplest radical form. a2 + b2 = c2 Pythagorean Theorem 22 + 62 = x2 Substitute 2 for a, 6 for b, and x for c. 40 = x2 Simplify. Find the positive square root. Simplify the radical. Holt McDougal Geometry 5-7 The Pythagorean Theorem Example 1B: Using the Pythagorean Theorem Find the value of x. Give your answer in simplest radical form. a2 + b2 = c2 Pythagorean Theorem (x – 2)2 + 42 = x2 Substitute x – 2 for a, 4 for b, and x for c. x2 – 4x + 4 + 16 = x2 Multiply. -

Geometry Ch 5 Exterior Angles & Triangle Inequality December 01, 2014
Geometry Ch 5 Exterior Angles & Triangle Inequality December 01, 2014 The “Three Possibilities” Property: either a>b, a=b, or a<b The Transitive Property: If a>b and b>c, then a>c The Addition Property: If a>b, then a+c>b+c The Subtraction Property: If a>b, then a‐c>b‐c The Multiplication Property: If a>b and c>0, then ac>bc The Division Property: If a>b and c>0, then a/c>b/c The Addition Theorem of Inequality: If a>b and c>d, then a+c>b+d The “Whole Greater than Part” Theorem: If a>0, b>0, and a+b=c, then c>a and c>b Def: An exterior angle of a triangle is an angle that forms a linear pair with an angle of the triangle. A In ∆ABC, exterior ∠2 forms a linear pair with ∠ACB. The other two angles of the triangle, ∠1 (∠B) and ∠A are called remote interior angles with respect to ∠2. 1 2 B C Theorem 12: The Exterior Angle Theorem An Exterior angle of a triangle is greater than either remote interior angle. Find each of the following sums. 3 4 26. ∠1+∠2+∠3+∠4 2 1 6 7 5 8 27. ∠1+∠2+∠3+∠4+∠5+∠6+∠7+ 9 12 ∠8+∠9+∠10+∠11+∠12 11 10 28. ∠1+∠5+∠9 31. What does the result in exercise 30 indicate about the sum of the exterior 29. ∠3+∠7+∠11 angles of a triangle? 30. ∠2+∠4+∠6+∠8+∠10+∠12 1 Geometry Ch 5 Exterior Angles & Triangle Inequality December 01, 2014 After proving the Exterior Angle Theorem, Euclid proved that, in any triangle, the sum of any two angles is less than 180°. -
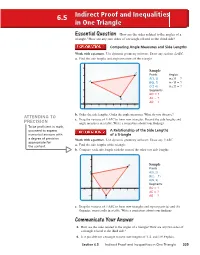
Indirect Proof and Inequalities in One Triangle
6.5 Indirect Proof and Inequalities in One Triangle EEssentialssential QQuestionuestion How are the sides related to the angles of a triangle? How are any two sides of a triangle related to the third side? Comparing Angle Measures and Side Lengths Work with a partner. Use dynamic geometry software. Draw any scalene △ABC. a. Find the side lengths and angle measures of the triangle. 5 Sample C 4 Points Angles A(1, 3) m∠A = ? A 3 B(5, 1) m∠B = ? C(7, 4) m∠C = ? 2 Segments BC = ? 1 B AC = ? AB = 0 ? 01 2 34567 b. Order the side lengths. Order the angle measures. What do you observe? ATTENDING TO c. Drag the vertices of △ABC to form new triangles. Record the side lengths and PRECISION angle measures in a table. Write a conjecture about your fi ndings. To be profi cient in math, you need to express A Relationship of the Side Lengths numerical answers with of a Triangle a degree of precision Work with a partner. Use dynamic geometry software. Draw any △ABC. appropriate for the content. a. Find the side lengths of the triangle. b. Compare each side length with the sum of the other two side lengths. 4 C Sample 3 Points A A(0, 2) 2 B(2, −1) C 1 (5, 3) Segments 0 BC = ? −1 01 2 3456 AC = ? −1 AB = B ? c. Drag the vertices of △ABC to form new triangles and repeat parts (a) and (b). Organize your results in a table. Write a conjecture about your fi ndings.