Master's Thesis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lightweight Django USING REST, WEBSOCKETS & BACKBONE
Lightweight Django USING REST, WEBSOCKETS & BACKBONE Julia Elman & Mark Lavin Lightweight Django LightweightDjango How can you take advantage of the Django framework to integrate complex “A great resource for client-side interactions and real-time features into your web applications? going beyond traditional Through a series of rapid application development projects, this hands-on book shows experienced Django developers how to include REST APIs, apps and learning how WebSockets, and client-side MVC frameworks such as Backbone.js into Django can power the new or existing projects. backend of single-page Learn how to make the most of Django’s decoupled design by choosing web applications.” the components you need to build the lightweight applications you want. —Aymeric Augustin Once you finish this book, you’ll know how to build single-page applications Django core developer, CTO, oscaro.com that respond to interactions in real time. If you’re familiar with Python and JavaScript, you’re good to go. “Such a good idea—I think this will lower the barrier ■ Learn a lightweight approach for starting a new Django project of entry for developers ■ Break reusable applications into smaller services that even more… the more communicate with one another I read, the more excited ■ Create a static, rapid prototyping site as a scaffold for websites and applications I am!” —Barbara Shaurette ■ Build a REST API with django-rest-framework Python Developer, Cox Media Group ■ Learn how to use Django with the Backbone.js MVC framework ■ Create a single-page web application on top of your REST API Lightweight ■ Integrate real-time features with WebSockets and the Tornado networking library ■ Use the book’s code-driven examples in your own projects Julia Elman, a frontend developer and tech education advocate, started learning Django in 2008 while working at World Online. -
(12) Patent Application Publication (10) Pub. No.: US 2014/0019847 A1 Osmak (43) Pub
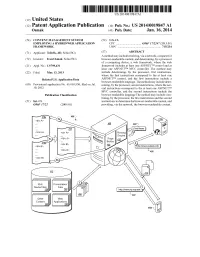
US 20140019847A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2014/0019847 A1 OSmak (43) Pub. Date: Jan. 16, 2014 (54) CONTENT MANAGEMENT SYSTEM (52) U.S. Cl. EMPLOYINGA HYBRD WEB APPLICATION CPC .................................. G06F 17/2247 (2013.01) FRAMEWORK USPC .......................................................... 71.5/234 (71) Applicant: Telerik, AD, Sofia (BG) (57) ABSTRACT A method may include receiving, via a network, a request for (72) Inventor: Ivan Osmak, Sofia (BG) browser-renderable content, and determining, by a processor of a computing device, a web framework, where the web (21) Appl. No.: 13/799,431 framework includes at least one ASP.NETTM control and at least one ASP.NETTM MVC controller. The method may (22) Filed: Mar 13, 2013 include determining, by the processor, first instructions, where the first instructions correspond to the at least one Related U.S. Application Data ASP.NETTM control, and the first instructions include a browser-renderable language. The method may include deter (60) Provisional application No. 61/669,930, filed on Jul. mining, by the processor, second instructions, where the sec 10, 2012. ond instructions correspond to the at least one ASP.NETTM MVC controller, and the second instructions include the Publication Classification browser-renderable language The method may include com bining, by the processor, the first instructions and the second (51) Int. Cl. instructions to determine the browser-renderable content, and G06F 7/22 (2006.01) providing, via the network, the browser-renderable content. Routing Engine Ric Presentation Media Fies : Fies 22 Applications 28 Patent Application Publication Jan. 16, 2014 Sheet 1 of 8 US 2014/001.9847 A1 Patent Application Publication Jan. -

Magnetic Silica Particles Functionalized with Guanidine Derivatives For
www.nature.com/scientificreports OPEN Magnetic silica particles functionalized with guanidine derivatives for microwave‑assisted transesterifcation of waste oil Petre Chipurici1,6, Alexandru Vlaicu1,2,6, Ioan Călinescu1, Mircea Vînătoru1, Cristina Busuioc1, Adrian Dinescu3, Adi Ghebaur1,4, Edina Rusen1, Georgeta Voicu1, Maria Ignat5 & Aurel Diacon1* This study aimed to develop a facile synthesis procedure for heterogeneous catalysts based on organic guanidine derivatives superbases chemically grafted on silica‑coated Fe3O4 magnetic nanoparticles. Thus, the three organosilanes that were obtained by reacting the selected carbodiimides (N,N′‑ dicyclohexylcarbodiimide (DCC), N,N′‑diisopropylcarbodiimide (DIC), respectively 1‑ethyl‑3‑(3‑ dimethylaminopropyl) carbodiimide (EDC) with 3‑aminopropyltriethoxysilane (APTES) were used in a one‑pot synthesis stage for the generation of a catalytic active protective shell through the simultaneous hydrolysis/condensation reaction with tetraethyl orthosilicate (TEOS). The catalysts were characterized by FTIR, TGA, SEM, BET and XRD analysis confrming the successful covalent attachment of the organic derivatives in the silica shell. The second aim was to highlight the capacity of microwaves (MW) to intensify the transesterifcation process and to evaluate the activity, stability, and reusability characteristics of the catalysts. Thus, in MW‑assisted transesterifcation reactions, all catalysts displayed FAME yields of over 80% even after 5 reactions/activation cycles. Additionally, the infuence of FFA content on the catalytic activity was investigated. As a result, in the case of Fe3O4@ SiO2‑EDG, a higher tolerance towards the FFA content can be noticed with a FAME yield of over 90% (for a 5% (weight) vs oil catalyst content) and 5% weight FFA content. Biodiesel can represent a suitable renewable alternative for the direct replacement of standard diesel fuels derived from petroleum sources1,2. -

Flask Documentation Release 0.7Dev July 14, 2014
Flask Documentation Release 0.7dev July 14, 2014 Contents I User’s Guide1 1 Foreword3 1.1 What does “micro” mean?...........................3 1.2 A Framework and an Example........................4 1.3 Web Development is Dangerous.......................4 1.4 The Status of Python 3.............................4 2 Installation7 2.1 virtualenv....................................7 2.2 System Wide Installation...........................8 2.3 Living on the Edge...............................9 2.4 easy_install on Windows............................9 3 Quickstart 11 3.1 A Minimal Application............................ 11 3.2 Debug Mode.................................. 12 3.3 Routing..................................... 13 3.4 Static Files.................................... 17 3.5 Rendering Templates.............................. 17 3.6 Accessing Request Data............................ 19 3.7 Redirects and Errors.............................. 22 3.8 Sessions..................................... 22 3.9 Message Flashing................................ 23 3.10 Logging..................................... 24 3.11 Hooking in WSGI Middlewares....................... 24 4 Tutorial 25 4.1 Introducing Flaskr............................... 25 4.2 Step 0: Creating The Folders......................... 26 4.3 Step 1: Database Schema........................... 27 4.4 Step 2: Application Setup Code........................ 27 i 4.5 Step 3: Creating The Database........................ 29 4.6 Step 4: Request Database Connections.................... 30 4.7 Step -

Wepgw003 High-Level Applications for the Sirius Accelerator Control System
10th Int. Particle Accelerator Conf. IPAC2019, Melbourne, Australia JACoW Publishing ISBN: 978-3-95450-208-0 doi:10.18429/JACoW-IPAC2019-WEPGW003 HIGH-LEVEL APPLICATIONS FOR THE SIRIUS ACCELERATOR CONTROL SYSTEM X. R. Resende ∗, F. H. de Sá, G. do Prado, L. Liu, A. C. Oliveira, Brazilian Synchrotron Light Laboratory (LNLS), Campinas, Brazil Abstract the sequence we detail the architecture of the HLA and its Sirius is the new 3 GeV low-emittance Brazilian Syn- current development status. Finally we describe how the chrotron Light source under installation and commissioning integration of the CS has been evolving during machine at LNLS. The machine control system is based on EPICS commissioning and end the paper with conclusion remarks and when the installation is complete it should have a few on what the next steps are in HLA development and testing. hundred thousand process variables in use. For flexible inte- gration and intuitive control of such sizable system a con- CONTROL SYSTEM OVERVIEW siderable number of high-level applications, input/output The Sirius accelerator control system (SCS) is based on controllers and graphical user interfaces have been devel- EPICS [3], version R3.15. All SCS software components oped, mostly in Python, using a variety of libraries, such are open-source solutions developed collaboratively using as PyEpics, PCASPy and PyDM. Common support service git version control and are publicly available in the Sirius applications (Archiver Appliance, Olog, Apache server, a organization page [4] at Github. mongoDB-based configuration server, etc) are used. Matlab The naming system used in Sirius for devices and CS prop- Middle Layer is also an available option to control EPICS erties is based on ESS naming system [5]. -

Bachelorarbeit
BACHELORARBEIT Realisierung von verzögerungsfreien Mehrbenutzer Webapplikationen auf Basis von HTML5 WebSockets Hochschule Harz University of Applied Sciences Wernigerode Fachbereich Automatisierung und Informatik im Fach Medieninformatik Erstprüfer: Prof. Jürgen K. Singer, Ph.D. Zweitprüfer: Prof. Dr. Olaf Drögehorn Erstellt von: Lars Häuser Datum: 16.06.2011 Einleitung Inhaltsverzeichnis 1 Einleitung ................................................................................................................. 5 1.1 Zielsetzung ..................................................................................................... 5 1.2 Aufbau der Arbeit ........................................................................................... 6 2 Grundlagen .............................................................................................................. 8 2.1 TCP/IP ............................................................................................................ 8 2.2 HTTP .............................................................................................................. 9 2.3 Request-Response-Paradigma (HTTP-Request-Cycle) .............................. 10 2.4 Klassische Webanwendung: Synchrone Datenübertragung ....................... 11 2.5 Asynchrone Webapplikationen .................................................................... 11 2.6 HTML5 ......................................................................................................... 12 3 HTML5 WebSockets ............................................................................................. -

Scalability in Web Apis
Worcester Polytechnic Institute Scalability in Web APIs Ryan Baker Mike Perrone Advised by: George T. Heineman 1 Worcester Polytechnic Institute 1 Introduction 2 Background 2.1 Problem Statement 2.2 Game Services and Tools 2.2.1 Graphics Engine 2.2.2 Map Editor 2.2.3 Friend Network 2.2.4 Achievements 2.2.5 Leaderboards 2.3 Our Service Definition 2.3.1 Leaderboards 2.4 Service Requirements 2.4.1 Administrative Ease 2.4.2 Security 2.4.3 Scalability 2.5 Internal Service Decisions 2.5.1 Application Framework 2.5.2 Cloud Computing 3 Methodology 3.1 Decisions of Design and Architecture 3.1.1 Leaderboards 3.1.2 API Documentation 3.1.3 Developer Console 3.1.4 Admin Console 3.1.5 Java Client Package 3.1.6 Logging 3.2 Decisions of Implementation 3.2.1 Enterprise vs Public 3.2.2 Front End Implementation 3.2.3 Cloud Computing Provider (AWS) 3.2.4 Web Application Framework Implementation (Flask) 3.2.5 Continuous Integration Service 3.2.6 API 3.2.7 Logging 3.2.8 Database Schema 4 Success Metrics 4.1 Resiliency 4.1.1 Simulated Traffic 4.1.2 Load Testing and Scalability 4.2 Design 4.2.1 Client Perspective 2 4.2.3 Admin Perspective 5 Conclusions & Future Work 5.1 Client Conclusions 5.2 Administrator Conclusions 5.3 The Future 6 References 7 Appendix A Why we chose Leaderboards B Facebook’s Game Development API C Playtomic’s API D Front End Tooling Decision E API Documentation Tool F Elastic Beanstalk 3 1 Introduction Game developers, especially those that make social games, undertake a large amount of work to create them. -

Evaluation and Optimization of ICOS Atmosphere Station Data As Part of the Labeling Process
Atmos. Meas. Tech., 14, 89–116, 2021 https://doi.org/10.5194/amt-14-89-2021 © Author(s) 2021. This work is distributed under the Creative Commons Attribution 4.0 License. Evaluation and optimization of ICOS atmosphere station data as part of the labeling process Camille Yver-Kwok1, Carole Philippon1, Peter Bergamaschi2, Tobias Biermann3, Francescopiero Calzolari4, Huilin Chen5, Sebastien Conil6, Paolo Cristofanelli4, Marc Delmotte1, Juha Hatakka7, Michal Heliasz3, Ove Hermansen8, Katerinaˇ Komínková9, Dagmar Kubistin10, Nicolas Kumps11, Olivier Laurent1, Tuomas Laurila7, Irene Lehner3, Janne Levula12, Matthias Lindauer10, Morgan Lopez1, Ivan Mammarella12, Giovanni Manca2, Per Marklund13, Jean-Marc Metzger14, Meelis Mölder15, Stephen M. Platt9, Michel Ramonet1, Leonard Rivier1, Bert Scheeren5, Mahesh Kumar Sha11, Paul Smith13, Martin Steinbacher16, Gabriela Vítková9, and Simon Wyss16 1Laboratoire des Sciences du Climat et de l’Environnement (LSCE-IPSL), CEA-CNRS-UVSQ, Université Paris-Saclay, 91191 Gif-sur-Yvette, France 2European Commission Joint Research Centre (JRC), Via E. Fermi 2749, 21027 Ispra, Italy 3Centre for Environmental and Climate Research, Lund University, Sölvegatan 37, 223 62, Lund, Sweden 4National Research Council of Italy, Institute of Atmospheric Sciences and Climate, Via Gobett 101, 40129 Bologna, Italy 5Centre for Isotope Research (CIO), Energy and Sustainability Research Institute Groningen (ESRIG), University of Groningen, Groningen, the Netherlands 6DRD/OPE, Andra, 55290 Bure, France 7Finnish Meteorological Institute, -
Monitoring Wilderness Stream Ecosystems
United States Department of Monitoring Agriculture Forest Service Wilderness Stream Rocky Mountain Ecosystems Research Station General Technical Jeffrey C. Davis Report RMRS-GTR-70 G. Wayne Minshall Christopher T. Robinson January 2001 Peter Landres Abstract Davis, Jeffrey C.; Minshall, G. Wayne; Robinson, Christopher T.; Landres, Peter. 2001. Monitoring wilderness stream ecosystems. Gen. Tech. Rep. RMRS-GTR-70. Ogden, UT: U.S. Department of Agriculture, Forest Service, Rocky Mountain Research Station. 137 p. A protocol and methods for monitoring the major physical, chemical, and biological components of stream ecosystems are presented. The monitor- ing protocol is organized into four stages. At stage 1 information is obtained on a basic set of parameters that describe stream ecosystems. Each following stage builds upon stage 1 by increasing the number of parameters and the detail and frequency of the measurements. Stage 4 supplements analyses of stream biotic structure with measurements of stream function: carbon and nutrient processes. Standard methods are presented that were selected or modified through extensive field applica- tion for use in remote settings. Keywords: bioassessment, methods, sampling, macroinvertebrates, production The Authors emphasize aquatic benthic inverte- brates, community dynamics, and Jeffrey C. Davis is an aquatic ecolo- stream ecosystem structure and func- gist currently working in Coastal Man- tion. For the past 19 years he has agement for the State of Alaska. He been conducting research on the received his B.S. from the University long-term effects of wildfires on of Alaska, Anchorage, and his M.S. stream ecosystems. He has authored from Idaho State University. His re- over 100 peer-reviewed journal ar- search has focused on nutrient dy- ticles and 85 technical reports. -

Pragmaticperl-Interviews-A4.Pdf
Pragmatic Perl Interviews pragmaticperl.com 2013—2015 Editor and interviewer: Viacheslav Tykhanovskyi Covers: Marko Ivanyk Revision: 2018-03-02 11:22 © Pragmatic Perl Contents 1 Preface .......................................... 1 2 Alexis Sukrieh (April 2013) ............................... 2 3 Sawyer X (May 2013) .................................. 10 4 Stevan Little (September 2013) ............................. 17 5 chromatic (October 2013) ................................ 22 6 Marc Lehmann (November 2013) ............................ 29 7 Tokuhiro Matsuno (January 2014) ........................... 46 8 Randal Schwartz (February 2014) ........................... 53 9 Christian Walde (May 2014) .............................. 56 10 Florian Ragwitz (rafl) (June 2014) ........................... 62 11 Curtis “Ovid” Poe (September 2014) .......................... 70 12 Leon Timmermans (October 2014) ........................... 77 13 Olaf Alders (December 2014) .............................. 81 14 Ricardo Signes (January 2015) ............................. 87 15 Neil Bowers (February 2015) .............................. 94 16 Renée Bäcker (June 2015) ................................ 102 17 David Golden (July 2015) ................................ 109 18 Philippe Bruhat (Book) (August 2015) . 115 19 Author .......................................... 123 i Preface 1 Preface Hello there! You have downloaded a compilation of interviews done with Perl pro- grammers in Pragmatic Perl journal from 2013 to 2015. Since the journal itself is in Russian -

What Is Perl
AdvancedAdvanced PerlPerl TechniquesTechniques DayDay 22 Dave Cross Magnum Solutions Ltd [email protected] Schedule 09:45 – Begin 11:15 – Coffee break (15 mins) 13:00 – Lunch (60 mins) 14:00 – Begin 15:30 – Coffee break (15 mins) 17:00 – End FlossUK 24th February 2012 Resources Slides available on-line − http://mag-sol.com/train/public/2012-02/ukuug Also see Slideshare − http://www.slideshare.net/davorg/slideshows Get Satisfaction − http://getsatisfaction.com/magnum FlossUK 24th February 2012 What We Will Cover Modern Core Perl − What's new in Perl 5.10, 5.12 & 5.14 Advanced Testing Database access with DBIx::Class Handling Exceptions FlossUK 24th February 2012 What We Will Cover Profiling and Benchmarking Object oriented programming with Moose MVC Frameworks − Catalyst PSGI and Plack FlossUK 24th February 2012 BenchmarkingBenchmarking && ProfilingProfiling Benchmarking Ensure that your program is fast enough But how fast is fast enough? premature optimization is the root of all evil − Donald Knuth − paraphrasing Tony Hoare Don't optimise until you know what to optimise FlossUK 24th February 2012 Benchmark.pm Standard Perl module for benchmarking Simple usage use Benchmark; my %methods = ( method1 => sub { ... }, method2 => sub { ... }, ); timethese(10_000, \%methods); Times 10,000 iterations of each method FlossUK 24th February 2012 Benchmark.pm Output Benchmark: timing 10000 iterations of method1, method2... method1: 6 wallclock secs \ ( 2.12 usr + 3.47 sys = 5.59 CPU) \ @ 1788.91/s (n=10000) method2: 3 wallclock secs \ ( 0.85 usr + 1.70 sys = 2.55 CPU) \ @ 3921.57/s (n=10000) FlossUK 24th February 2012 Timed Benchmarks Passing timethese a positive number runs each piece of code a certain number of times Passing timethese a negative number runs each piece of code for a certain number of seconds FlossUK 24th February 2012 Timed Benchmarks use Benchmark; my %methods = ( method1 => sub { .. -

Modern Perl, Fourth Edition
Prepared exclusively for none ofyourbusiness Prepared exclusively for none ofyourbusiness Early Praise for Modern Perl, Fourth Edition A dozen years ago I was sure I knew what Perl looked like: unreadable and obscure. chromatic showed me beautiful, structured expressive code then. He’s the right guy to teach Modern Perl. He was writing it before it existed. ➤ Daniel Steinberg President, DimSumThinking, Inc. A tour de force of idiomatic code, Modern Perl teaches you not just “how” but also “why.” ➤ David Farrell Editor, PerlTricks.com If I had to pick a single book to teach Perl 5, this is the one I’d choose. As I read it, I was reminded of the first time I read K&R. It will teach everything that one needs to know to write Perl 5 well. ➤ David Golden Member, Perl 5 Porters, Autopragmatic, LLC I’m about to teach a new hire Perl using the first edition of Modern Perl. I’d much rather use the updated copy! ➤ Belden Lyman Principal Software Engineer, MediaMath It’s not the Perl book you deserve. It’s the Perl book you need. ➤ Gizmo Mathboy Co-founder, Greater Lafayette Open Source Symposium (GLOSSY) Prepared exclusively for none ofyourbusiness We've left this page blank to make the page numbers the same in the electronic and paper books. We tried just leaving it out, but then people wrote us to ask about the missing pages. Anyway, Eddy the Gerbil wanted to say “hello.” Prepared exclusively for none ofyourbusiness Modern Perl, Fourth Edition chromatic The Pragmatic Bookshelf Dallas, Texas • Raleigh, North Carolina Prepared exclusively for none ofyourbusiness Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks.