Modern Perl, Fourth Edition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reflection, Zips, and Generalised Casts Abstract
Scrap More Boilerplate: Reflection, Zips, and Generalised Casts Ralf L a¨mmel Vrije Universiteit & CWI, Amsterdam Abstract Writing boilerplate code is a royal pain. Generic programming promises to alleviate this pain b y allowing the programmer to write a generic #recipe$ for boilerplate code, and use that recipe in many places. In earlier work we introduced the #Scrap y our boilerplate$ approach to generic p rogramming, which exploits Haskell%s exist- ing type-class mechanism to support generic transformations and queries. This paper completes the picture. We add a few extra #introspec- tive$ or #reflective$ facilities, that together support a r ich variety of serialisation and de-serialisation. We also show how to perform generic #zips$, which at first appear to be somewhat tricky in our framework. Lastly, we generalise the ability to over-ride a generic function with a type-specific one. All of this can be supported in Haskell with independently-useful extensions: higher-rank types and type-safe cast. The GHC imple- mentation of Haskell readily derives the required type classes for user-defined data types. Categories and Subject Descriptors D.2. 13 [Software Engineering]: Reusable Software; D.1.1 [Programming Techniques]: Functional Programming; D.3. 1 [Programming Languages]: Formal Definitions and Theory General Terms Design, Languages Keywords Generic p rogramming, reflection, zippers, type cast 1 Introduction It is common to find that large slabs of a program consist of #boil- erplate$ code, which conceals b y its b ulk a smaller amount of #in- teresting$ code. So-called generic p rogramming techniques allow Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or c ommercial advantage and that copies b ear this notice and the full citation on the first page. -

Template Meta-Programming for Haskell
Template Meta-programming for Haskell Tim Sheard Simon Peyton Jones OGI School of Science & Engineering Microsoft Research Ltd Oregon Health & Science University [email protected] [email protected] Abstract C++, albeit imperfectly... [It is] obvious to functional programmers what the committee did not realize until We propose a new extension to the purely functional programming later: [C++] templates are a functional language evalu- language Haskell that supports compile-time meta-programming. ated at compile time...” [12]. The purpose of the system is to support the algorithmic construction of programs at compile-time. Robinson’s provocative paper identifies C++ templates as a ma- The ability to generate code at compile time allows the program- jor, albeit accidental, success of the C++ language design. De- mer to implement such features as polytypic programs, macro-like spite the extremely baroque nature of template meta-programming, expansion, user directed optimization (such as inlining), and the templates are used in fascinating ways that extend beyond the generation of supporting data structures and functions from exist- wildest dreams of the language designers [1]. Perhaps surprisingly, ing data structures and functions. in view of the fact that templates are functional programs, func- tional programmers have been slow to capitalize on C++’s success; Our design is being implemented in the Glasgow Haskell Compiler, while there has been a recent flurry of work on run-time meta- ghc. programming, much less has been done on compile-time meta- This version is very slightly modified from the Haskell Workshop programming. The Scheme community is a notable exception, as 2002 publication; a couple of typographical errors are fixed in Fig- we discuss in Section 10. -

MANNING Greenwich (74° W
Object Oriented Perl Object Oriented Perl DAMIAN CONWAY MANNING Greenwich (74° w. long.) For electronic browsing and ordering of this and other Manning books, visit http://www.manning.com. The publisher offers discounts on this book when ordered in quantity. For more information, please contact: Special Sales Department Manning Publications Co. 32 Lafayette Place Fax: (203) 661-9018 Greenwich, CT 06830 email: [email protected] ©2000 by Manning Publications Co. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the publisher. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in the book, and Manning Publications was aware of a trademark claim, the designations have been printed in initial caps or all caps. Recognizing the importance of preserving what has been written, it is Manning’s policy to have the books we publish printed on acid-free paper, and we exert our best efforts to that end. Library of Congress Cataloging-in-Publication Data Conway, Damian, 1964- Object oriented Perl / Damian Conway. p. cm. includes bibliographical references. ISBN 1-884777-79-1 (alk. paper) 1. Object-oriented programming (Computer science) 2. Perl (Computer program language) I. Title. QA76.64.C639 1999 005.13'3--dc21 99-27793 CIP Manning Publications Co. Copyeditor: Adrianne Harun 32 Lafayette -

Perl Baseless Myths & Startling Realities
http://xkcd.com/224/ 1 Perl Baseless Myths & Startling Realities by Tim Bunce, February 2008 2 Parrot and Perl 6 portion incomplete due to lack of time (not lack of myths!) Realities - I'm positive about Perl Not negative about other languages - Pick any language well suited to the task - Good developers are always most important, whatever language is used 3 DISPEL myths UPDATE about perl Who am I? - Tim Bunce - Author of the Perl DBI module - Using Perl since 1991 - Involved in the development of Perl 5 - “Pumpkin” for 5.4.x maintenance releases - http://blog.timbunce.org 4 Perl 5.4.x 1997-1998 Living on the west coast of Ireland ~ Myths ~ 5 http://www.bleaklow.com/blog/2003/08/new_perl_6_book_announced.html ~ Myths ~ - Perl is dead - Perl is hard to read / test / maintain - Perl 6 is killing Perl 5 6 Another myth: Perl is slow: http://www.tbray.org/ongoing/When/200x/2007/10/30/WF-Results ~ Myths ~ - Perl is dead - Perl is hard to read / test / maintain - Perl 6 is killing Perl 5 7 Perl 5 - Perl 5 isn’t the new kid on the block - Perl is 21 years old - Perl 5 is 14 years old - A mature language with a mature culture 8 How many times Microsoft has changed developer technologies in the last 14 years... 9 10 You can guess where thatʼs leading... From “The State of the Onion 10” by Larry Wall, 2006 http://www.perl.com/pub/a/2006/09/21/onion.html?page=3 Buzz != Jobs - Perl5 hasn’t been generating buzz recently - It’s just getting on with the job - Lots of jobs - just not all in web development 11 Web developers tend to have a narrow focus. -
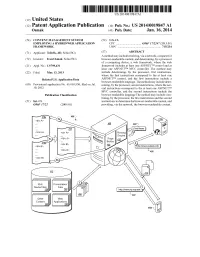
(12) Patent Application Publication (10) Pub. No.: US 2014/0019847 A1 Osmak (43) Pub
US 20140019847A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2014/0019847 A1 OSmak (43) Pub. Date: Jan. 16, 2014 (54) CONTENT MANAGEMENT SYSTEM (52) U.S. Cl. EMPLOYINGA HYBRD WEB APPLICATION CPC .................................. G06F 17/2247 (2013.01) FRAMEWORK USPC .......................................................... 71.5/234 (71) Applicant: Telerik, AD, Sofia (BG) (57) ABSTRACT A method may include receiving, via a network, a request for (72) Inventor: Ivan Osmak, Sofia (BG) browser-renderable content, and determining, by a processor of a computing device, a web framework, where the web (21) Appl. No.: 13/799,431 framework includes at least one ASP.NETTM control and at least one ASP.NETTM MVC controller. The method may (22) Filed: Mar 13, 2013 include determining, by the processor, first instructions, where the first instructions correspond to the at least one Related U.S. Application Data ASP.NETTM control, and the first instructions include a browser-renderable language. The method may include deter (60) Provisional application No. 61/669,930, filed on Jul. mining, by the processor, second instructions, where the sec 10, 2012. ond instructions correspond to the at least one ASP.NETTM MVC controller, and the second instructions include the Publication Classification browser-renderable language The method may include com bining, by the processor, the first instructions and the second (51) Int. Cl. instructions to determine the browser-renderable content, and G06F 7/22 (2006.01) providing, via the network, the browser-renderable content. Routing Engine Ric Presentation Media Fies : Fies 22 Applications 28 Patent Application Publication Jan. 16, 2014 Sheet 1 of 8 US 2014/001.9847 A1 Patent Application Publication Jan. -

A Call-By-Need Lambda Calculus
A CallByNeed Lamb da Calculus Zena M Ariola Matthias Fel leisen Computer Information Science Department Department of Computer Science University of Oregon Rice University Eugene Oregon Houston Texas John Maraist and Martin Odersky Philip Wad ler Institut fur Programmstrukturen Department of Computing Science Universitat Karlsruhe UniversityofGlasgow Karlsruhe Germany Glasgow Scotland Abstract arguments value when it is rst evaluated More pre cisely lazy languages only reduce an argument if the The mismatchbetween the op erational semantics of the value of the corresp onding formal parameter is needed lamb da calculus and the actual b ehavior of implemen for the evaluation of the pro cedure b o dy Moreover af tations is a ma jor obstacle for compiler writers They ter reducing the argument the evaluator will remember cannot explain the b ehavior of their evaluator in terms the resulting value for future references to that formal of source level syntax and they cannot easily com parameter This technique of evaluating pro cedure pa pare distinct implementations of dierent lazy strate rameters is called cal lbyneed or lazy evaluation gies In this pap er we derive an equational characteri A simple observation justies callbyneed the re zation of callbyneed and prove it correct with resp ect sult of reducing an expression if any is indistinguish to the original lamb da calculus The theory is a strictly able from the expression itself in all p ossible contexts smaller theory than the lamb da calculus Immediate Some implementations attempt -

Chemplugin™ User's Guide
The Geochemist’s Workbench® Release 15 ChemPlugin™ User’s Guide The Geochemist’s Workbench® Release 15 ChemPlugin™ User’s Guide Craig M. Bethke Aqueous Solutions, LLC Champaign, Illinois Printed August 31, 2021 This document © Copyright 2021 by Aqueous Solutions LLC. All rights reserved. Earlier editions copyright 2000–2020. This document may be reproduced freely to support any licensed use of the GWB software package. Software copyright notice: Programs GSS, Rxn, Act2, Tact, SpecE8, Gtplot, TEdit, React, Phase2, P2plot, X1t, X2t, Xtplot, and ChemPlugin © Copyright 1983–2021 by Aqueous Solutions LLC. An unpublished work distributed via trade secrecy license. All rights reserved under the copyright laws. The Geochemist’s Workbench®, ChemPlugin, We put bugs in our software, and The Geochemist’s Spreadsheet are a registered trademark and trademarks of Aqueous Solutions LLC; Microsoft®, MS®, Windows XP®, Windows Vista®, Windows 7®, Windows 8®, and Windows 10® are registered trademarks of Microsoft Corporation; PostScript® is a registered trademark of Adobe Systems, Inc. Other products mentioned in this document are identified by the trademarks of their respective companies; the authors disclaim responsibility for specifying which marks are owned by which companies. The software uses zlib © 1995-2005 Jean-Loup Gailly and Mark Adler, and Expat © 1998-2006 Thai Open Source Center Ltd. and Clark Cooper. The GWB software was originally developed by the students, staff, and faculty of the Hydrogeology Program in the Department of Geology at the University of Illinois Urbana-Champaign. The package is currently developed and maintained by Aqueous Solutions LLC at the University of Illinois Research Park. Address inquiries to Aqueous Solutions LLC 301 North Neil Street, Suite 400 Champaign, IL 61820 USA Warranty: The Aqueous Solutions LLC warrants only that it has the right to convey license to the GWB software. -

NU-Prolog Reference Manual
NU-Prolog Reference Manual Version 1.5.24 edited by James A. Thom & Justin Zobel Technical Report 86/10 Machine Intelligence Project Department of Computer Science University of Melbourne (Revised November 1990) Copyright 1986, 1987, 1988, Machine Intelligence Project, The University of Melbourne. All rights reserved. The Technical Report edition of this publication is given away free subject to the condition that it shall not, by the way of trade or otherwise, be lent, resold, hired out, or otherwise circulated, without the prior consent of the Machine Intelligence Project at the University of Melbourne, in any form or cover other than that in which it is published and without a similar condition including this condition being imposed on the subsequent user. The Machine Intelligence Project makes no representations or warranties with respect to the contents of this document and specifically disclaims any implied warranties of merchantability or fitness for any particular purpose. Furthermore, the Machine Intelligence Project reserves the right to revise this document and to make changes from time to time in its content without being obligated to notify any person or body of such revisions or changes. The usual codicil that no part of this publication may be reproduced, stored in a retrieval system, used for wrapping fish, or transmitted, in any form or by any means, electronic, mechanical, photocopying, paper dart, recording, or otherwise, without someone's express permission, is not imposed. Enquiries relating to the acquisition of NU-Prolog should be made to NU-Prolog Distribution Manager Machine Intelligence Project Department of Computer Science The University of Melbourne Parkville, Victoria 3052 Australia Telephone: (03) 344 5229. -

3.0 Installation Guide
Oratio® 3.0 installation Guide Summary • Requirements • Installation o Installation of files o Configurating Apache o Permission on files • Installing and configurating PostgreSQL database • Installing Perl modules • Configurating the environment for JasperReports • Configurating Oratio® o First installation o Launch the Software Requirements Oratio® is an ERP distributed with GPL licence. Oratio® uses PostgresSQL database and works in CGI modality, therefore it is accessible through an internet browser. Therefore, before the use of Oratio® it is necessary to make sure yourself that the instruments used by Oratio® are present on the server where Oratio® will be installed. List of programs 1. Perl, version 5 or above (Perl) 2. An http server Apache 3. A database system PostgreSQL, version 7.4 or above 4. The following Perl Libraries: DBD-Pg and DBI, downloadable from CPAN website 5. The following Perl Libraries downloadable from CPAN website XML::Parser XML::Writer XML::Writer::String XML::Encoding HTML::Template Text::Template CGI::session Unicode::String 6. For ready to print documents: - Java JDK version 1.5 and above - "Inline" and "Inline-Java" modules - JasperReports and related libraries (included in Oratio® download) - Optional: iReport for creating and editing reports in graphic modality Installation File installation: • Decompress .tar.gz file in /usr/local folder of your Linux server: tar xzvf oratio-x.x.x.tar.gz • you can find all files in /usr/local/oratio/ folder or /var/www/oratio/ Windows only • Download oratio3-windows.zip -

Bull System Manager Server Add-Ons Installation and Administrator's Guide
BSM 2.1 Server Add-ons Installation and Administrator's Guide REFERENCE 86 A2 59FA 07 BSM 2.1 Server Add-ons Installation and Administrator's Guide Software June 2012 BULL CEDOC 357 AVENUE PATTON B.P.20845 49008 ANGERS CEDEX 01 FRANCE REFERENCE 86 A2 59FA 07 The following copyright notice protects this book under Copyright laws which prohibit such actions as, but not limited to, copying, distributing, modifying, and making derivative works. Copyright © Bull SAS 2008-2012 Printed in France Trademarks and Acknowledgements We acknowledge the rights of the proprietors of the trademarks mentioned in this manual. All brand names and software and hardware product names are subject to trademark and/or patent protection. Quoting of brand and product names is for information purposes only and does not represent trademark misuse. The information in this document is subject to change without notice. Bull will not be liable for errors contained herein, or for incidental or consequential damages in connection with the use of this material. Table of Contents Preface.........................................................................................................................................................ix Intended Readers.........................................................................................................................ix Highlighting Conventions .............................................................................................................ix Related Publications......................................................................................................................x -

End-To-End Perl Solutions
END-TO-END PERL SOLUTIONS: ACTIVEPERL AND KOMODO IDE FOR PERL MILLIONS OF DEVELOPERS TRUST PERL FOR COMPUTATIONAL AND INTEGRATION TASKS— SYSTEM ADMINISTRATION, SCRIPTING, RUNNING DATABASE APPLICATIONS, AND MORE As an open source programming language, Perl immedi- FAIL-SAFE ACTIVEPERL FOR BUSINESS AND ately reduces up-front project costs. However, Perl alone MISSION-CRITICAL APPLICATIONS may not help you meet your business goals. With ActiveState commercial-grade technical support and consulting you don’t need to depend on overworked Like most open source projects, Perl isn’t quality assured internal resources or public Perl communities to solve or commercially supported. So, it may not be safe for development issue. business or mission-critical applications that must run effectively daily, weekly, even hourly. Don’t let Perl be a ActivePerl Enterprise Edition is designed for busi- point of failure for your internal systems and cost your nesses with large Perl deployments in essential, mission- business in lost revenue. Or worse, don’t let it compro- critical applications that, when down, could cost your mise relationships with your customers. CA, Siemens and business in lost revenue and a damaged reputation. Boeing are just a few Fortune 1000 companies that trust Deploy Perl with confidence knowing you’re using the ActiveState for end-to-end development, management most secure, enterprise-grade builds for platforms like and distribution solutions for fail-safe Perl. WORLD’S BEST PERL DISTRIBUTION “ActiveState’s trusted version of Perl has allowed us ActivePerl is the industry-standard, commercial-grade to continuously raise the bar on quality as well as Perl distribution used by millions of developers around cut the cost of expanding our product matrix.” the world for easy Perl installation and quality-assured Lawrence Backman, VP at CA code. -

Bachelorarbeit
BACHELORARBEIT Realisierung von verzögerungsfreien Mehrbenutzer Webapplikationen auf Basis von HTML5 WebSockets Hochschule Harz University of Applied Sciences Wernigerode Fachbereich Automatisierung und Informatik im Fach Medieninformatik Erstprüfer: Prof. Jürgen K. Singer, Ph.D. Zweitprüfer: Prof. Dr. Olaf Drögehorn Erstellt von: Lars Häuser Datum: 16.06.2011 Einleitung Inhaltsverzeichnis 1 Einleitung ................................................................................................................. 5 1.1 Zielsetzung ..................................................................................................... 5 1.2 Aufbau der Arbeit ........................................................................................... 6 2 Grundlagen .............................................................................................................. 8 2.1 TCP/IP ............................................................................................................ 8 2.2 HTTP .............................................................................................................. 9 2.3 Request-Response-Paradigma (HTTP-Request-Cycle) .............................. 10 2.4 Klassische Webanwendung: Synchrone Datenübertragung ....................... 11 2.5 Asynchrone Webapplikationen .................................................................... 11 2.6 HTML5 ......................................................................................................... 12 3 HTML5 WebSockets .............................................................................................