SMACK Stack.Key
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

YOSEMITE NATIONAL PARK O C Y Lu H M Tioga Pass Entrance 9945Ft C Glen Aulin K T Ne Ee 3031M E R Hetc C Gaylor Lakes R H H Tioga Road Closed
123456789 il 395 ra T Dorothy Lake t s A Bond C re A Pass S KE LA c i f i c IN a TW P Tower Peak Barney STANISLAUS NATIONAL FOREST Mary Lake Lake Buckeye Pass Twin Lakes 9572ft EMIGRANT WILDERNESS 2917m k H e O e O r N V C O E Y R TOIYABE NATIONAL FOREST N Peeler B A Lake Crown B C Lake Haystack k Peak e e S Tilden r AW W Schofield C TO Rock Island OTH IL Peak Lake RI Pass DG D Styx E ER s Matterhorn Pass l l Peak N a Slide E Otter F a Mountain S Lake ri e S h Burro c D n Pass Many Island Richardson Peak a L Lake 9877ft R (summer only) IE 3010m F LE Whorl Wilma Lake k B Mountain e B e r U N Virginia Pass C T O Virginia S Y N Peak O N Y A Summit s N e k C k Lake k c A e a C i C e L C r N r Kibbie d YO N C n N CA Lake e ACK AI RRICK K J M KE ia in g IN ir A r V T e l N k l U e e pi N O r C S O M Y Lundy Lake L Piute Mountain N L te I 10541ft iu A T P L C I 3213m T Smedberg k (summer only) Lake e k re e C re Benson Benson C ek re Lake Lake Pass C Vernon Creek Mount k r e o Gibson e abe Upper an r Volunteer McC le Laurel C McCabe E Peak rn Lake u Lake N t M e cCa R R be D R A Lak D NO k Rodgers O I es e PLEASANT EA H N EL e Lake I r l Frog VALLEY R i E k G K C E LA e R a e T I r r Table Lake V North Peak T T C N Pettit Peak A INYO NATIONAL FOREST O 10788ft s Y 3288m M t ll N Fa s Roosevelt ia A e Mount Conness TILT r r Lake Saddlebag ILL VALLEY e C 12590ft (summer only) h C Lake ill c 3837m Lake Eleanor ilt n Wapama Falls T a (summer only) N S R I Virginia c A R i T Lake f N E i MIGUEL U G c HETCHY Rancheria Falls O N Highway 120 D a MEADOW -

Factors Contributing to the Formation of Sheeting Joints
FACTORS CONTRIBUTING TO THE FORMATION OF SHEETING JOINTS: A STUDY OF SHEETING JOINTS ON A DOME IN YOSEMITE NATIONAL PARK A THESIS SUBMITTED TO THE GRADUATE DIVISION OF THE UNIVERSITY OF HAWAI„I AT MĀNOA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTERS OF SCIENCE IN GEOLOGY AND GEOPHYSICS AUGUST 2010 By Kelly J. Mitchell Thesis Committee: Steve Martel, Chairperson Fred Duennebier Paul Wessel Keywords: sheeting joints, exfoliation joints, topographic stresses, curvature, mechanics, spectral filtering, Yosemite Acknowledgements I would like to extend my sincerest gratitude to those who helped make this thesis possible. Thanks to the National Science Foundation for funding this research. Thank you to my graduate advisor, Dr. Steve Martel, for your advice and support through the past few years. This has been a long and difficult project but you have been patient and supportive through it all. Special thanks to my committee, Dr. Fred Duennebier and Dr. Paul Wessel for their advice and contributions; without your help I do not think this project would have been possible. I appreciate the time all of you have spent discussing the project with me. Thank you to Chris Hurren, Shay Chapman, and Carolyn Parcheta for your hard work and moral support in the field; you kept a great attitude during the field season. Special thanks to the National Park Service staff in Yosemite, particularly Dr. Greg Stock and Brian Huggett for their assistance. I wish to thank NCALM, Ole Kaven, Nicholas VanDerElst, and Emily Brodsky for LIDAR data collection. Thank you to Carolina Anchietta Fermin, Lisa Swinnard, and Darwina Griffin for their moral support. -

April 1999 SCREE
October, 2007 Peak Climbing Section, Loma Prieta Chapter, Sierra Club Vol. 41 No. 10 World Wide Web Address: http://lomaprieta.sierraclub.org/pcs/ General Meeting Editor’s Notes Date: October 9, 2007 Winter made a brief appearance last week with snow falling in the mountains (see the Highland Peak report). Expect a gorgeous time of the year for outside activity Time: 7:30 pm in the wilderness using skis, snowshoes or just feet. Where: Peninsula Conservation Center This year we introduce a new kind of trip for those who 3921 E. Bayshore Rd. are more ambitious than the would-be tripper that curls Palo Alto, CA up by the fire with a good book. Called the BSS, Backcountry Ski Series, the offering is a day trip into the backcountry once a month, typically in the Tahoe Program: Canyoneering - area. The trips are scheduled for Friday because North Fork of the Kaweah River Thursday night traffic after 7 pm is quick and smooth while Friday is terrible. Also a Friday outing allows the leaders to recover enough to race in the citizen class Presenter: Toinette Hartshorne races each Sunday or Monday. People may attend one or all trips. Tips on Telemark and Randonee skiing will be available, but participants need to have advanced This past summer, Jef Levin and Toinette skiing skills. Typically there will be anywhere from completed the first descent of the North Fork of good to great powder. the Kaweah River. Several weekends were spent scouting and rigging the technical sections in the Avalanche beacons as well as shovels and probes are beautiful granite canyons carved by this river. -

Yosemite Conservancy Spring.Summer 2016 :: Volume 07.Issue 01
YOSEMITE CONSERVANCY SPRING.SUMMER 2016 :: VOLUME 07.ISSUE 01 Keeping Yosemite “Wild” INSIDE Preserving Yosemite’s Wilderness A Guide to Leave No Trace Expert Insights on Preserving Ackerson Meadow Q&A with a Yosemite Botanist PHOTO: (RIGHT) © KARL KROEBER. PHOTO: MISSION Providing for Yosemite’s future is our passion. We inspire people to support projects and programs that preserve and protect Yosemite National Park’s resources and enrich the visitor experience. PRESIDENT’S NOTE YOSEMITE CONSERVANCY COUNCIL MEMBERS Yosemite’s Wilderness CHAIR PRESIDENT & CEO Philip L. Pillsbury Jr.* Frank Dean* he word wilderness might sound VICE CHAIR VICE PRESIDENT, forbidding, or it might conjure up a Bob Bennitt* CFO & COO Jerry Edelbrock sense of adventure. In an increasingly crowded world, national parks — and their protected Wilderness areas — provide COUNCIL important space, solace, and a refuge for both Hollis & Matt Adams* Jean Lane Jeanne & Michael Adams Walt Lemmermann* wildlife and humans. Some years ago, I had Gretchen Augustyn Melody & Bob Lind the privilege to ski with good friends into a Susan & Bill Baribault Sam & Cindy Livermore snowed-under Tuolumne Meadows. We had Meg & Bob Beck Anahita & Jim Lovelace Suzy & Bob Bennitt* Mark Marion & the meadows to ourselves and enjoyed a full David Bowman & Sheila Grether-Marion moon that reflected off the snow to make it Gloria Miller Patsy & Tim Marshall almost as bright as daylight. It was an amazing experience. Tori & Bob Brant* Kirsten & Dan Miks Marilyn & Allan Brown Robyn & Joe Miller More than 95 percent of visitors to Yosemite spend their time in Yosemite Steve & Diane Ciesinski* Janet Napolitano Sandy & Bob Comstock Dick Otter Valley, Mariposa Grove, or along Tioga Road. -
![Yosemite National Park [PDF]](https://docslib.b-cdn.net/cover/4323/yosemite-national-park-pdf-1784323.webp)
Yosemite National Park [PDF]
To Carson City, Nev il 395 ra T Emigrant Dorothy L ake Lake t s Bond re C Pass HUMBOLDT-TOIYABE Maxwell NATIONAL FOREST S E K Lake A L c i f i c IN a Mary TW P Lake Tower Peak Barney STANISLAUS NATIONAL FOREST Lake Buckeye Pass Huckleberry Twin Lakes 9572 ft EMIGRANT WILDERNESS Lake 2917 m HO O k N e V e O E r Y R C N Peeler A W Lake Crown C I Lake L D Haystack k e E Peak e S R r A Tilden W C TO N Schofield OT Rock Island H E Lake R Peak ID S Pass G E S s Styx l l Matterhorn Pass a F Peak Slide Otter ia Mountain Lake r e Burro h Green c Pass D n Many Island Richardson Peak a Lake L Lake 9877 ft R (summer only) IE 3010 m F E L Whorl Wilma Lake k B Mountain e B e r U N Virginia Pass C T O Virginia S Y N Peak O N Y A Summit s N e k C k Lake k A e a ic L r C e Kibbie N r d YO N C Lake n N A I C e ACK A RRICK J M KE ia K in N rg I i A r V T e l N k l i U e e p N O r C S M O Lundy Lake Y L Piute Mountain N L te I 10541 ft iu A T P L C I 3213 m T (summer only) Smedberg Benson k Lake e Pass k e e r e C r Benson C Lake k Lake ee Cree r Vernon k C r o e Upper n Volunteer cCab a M e McCabe l Mount Peak E Laurel k n r Lake Lake Gibson e u e N t r e McC C a R b R e L R a O O A ke Rodgers I s N PLEASANT A E H N L Lake I k E VALLEY R l Frog e i E k G K e E e a LA r R e T I r C r Table Lake V T T North Peak C Pettit Peak N A 10788 ft INYO NATIONAL FOREST O Y 3288 m M t ls Saddlebag al N s Roosevelt F A e Lake TIL a r Lake TILL ri C VALLEY (summer only) e C l h Lake Eleanor il c ilt n Mount Wapama Falls T a (summer only) N S Conness R I Virginia c HALL -

OSEMITE Rature NOTES • OLUME XXXIII • NUMBER 10 ,Tiober 1954
OSEMITE rATURE NOTES • OLUME XXXIII • NUMBER 10 ,TiOBER 1954 Echo Peaks, Yosemite National Park. —Ralph Anderson CLirn,LU Sri, Aerial view of Yosemite Valley and the Yosemite high Sierra . The thinking that lay behin the various interpretations of the origin of this valley, as reviewed in " Early Theories r Yosemite ' s Formation, " may better be appraised through reference to the above comps hensive scene . Yosemite Nature Notes THE MONTHLY PUBLICATION OF THE YOSEMITE NATURALIST DIVISION AND THE YOSEMITE NATURAL HISTORY ASSOCIATION, INC. john C. Preston, Superintendent D. E. McHenry, Park Naturalist D. H. Hubbard, Assoc . Park Naturalist N . B . Herkenham, Asst . Park Naturalist W . W. Bryant, Junior Park Naturalist I_VOL . XXXIII OCTOBER 1954 NO. 10 EARLY THEORIES OF YOSEMITE'S FORMATION By Richard J. Hartesveldt, Ranger Naturalist Before the excellent geological toric expedition, was the person most Studies of Yosemite Valley were likely to be given to such thoughts; Made by Francois Matthes : several however, no mention is made of Conflicting theories were advanced them in his book Discovery of the Yo- scientists and laymen concern- senzite. Published in 1880, this valu- V the origin of the famed chasm . able report does carry a discussion her reading Matthes' clear-cut, of the later controversy between John Widely accepted geologic history of Muir and the geologist Josiah D. Ibe valley, one finds difficulty under- Whitney over the mode of the val- nding why so many erroneous ley 's evolution. hypotheses were formulated . Yet, Because of his position as Cali- field of geology was young at fornia state geologist, Whitney 's ehe time of the Yosemite discovery mistaken concept did much to in- Ind the age of believing is cata- fluence the thinking of others . -

James D. Savage, the Key Figure in the Story of Yosemite Valley's Discovery, Has Over Come to Light
tosem,re Nature S VOL. XXX NOVEMBER, 1951 NO. 11 102 YOSEMITE NATURE NOTES Drawn by Lloyd D . Moore, ltnnycr NoInrnllet An impression of lames D . Savage No photograph or picture of Mal . James D. Savage, the key figure in the story of Yosemite Valley's discovery, has over come to light . The above impression of his probable likeness is based on the excellent description appearing in "A White Medicine-Man" beg inning on the opposite page. Cover Photo: Aerial view of Half Dome and part of the Yosemite high Sierra, vicinity of Yosemite Valley . Made and donated to Yosemite Museum by Mr . Clarence Srock of Aptos, California. See back cover for outline key . Yosemite Nature Notes THE MONTHLY PUBLICATION OF THE YOSEMITE NATURALIST DIVISION AND THE YOSEMITE NATURAL HISTORY ASSOCIATION, INC. C . P. Russell, Superintendent D . E . McHenry, Park Naturalist H. C . Parker, Assoc. Park Naturalist N. B . Herkenham, Asst. Park Naturalist W. W . Bryant, Junior Park Naturalist VOL. XXX NOVEMBER, 1951 NO. 1I _he A WHITE MEDICINE-MAN1 By James O'Meara Of the early life of the subject of nose, a strong, firm mouth, with lips this sketch, very little is known . It thin and denoting great decision, a is only of his career in. California that well-rounded and prominent chin, mention will be made . He was a and heavy, powerful jaws---all be- pioneer of the Territory before the tokening the indomitable will of this period of Statehood ; and the vast master of his kind : and his com- region then included in the bound- plexion was of that hearty bronze aries of Mariposa was his broad which robust health and constant ex- field of action . -

Yosemite Guide
G 83 after a major snowfall. major a after Note: Service to stops 15, 16, 17, and 18 may stop stop may 18 and 17, 16, 15, stops to Service Note: Third Class Mail Class Third Postage and Fee Paid Fee and Postage US Department Interior of the December 17, 2008 - February 17, 2009 17, February - 2008 17, December Guide Yosemite Park National Yosemite America Your Experience US Department Interior of the Service Park National 577 PO Box CA 95389 Yosemite, Experience Your America Yosemite National Park Vol. 34, Issue No.1 Inside: 01 Welcome to Yosemite 05 Programs and Events 06 Services and Facilities 10 Special Feature: Lincoln & Yosemite Dec ‘08 - Feb ‘09 Yosemite Falls. Photo by Christine White Loberg Where to Go and What to Do in Yosemite National Park December 17, 2008 - February 17, 2009 Yosemite Guide Experience Your America Yosemite National Park Yosemite Guide December 17, 2008 - February 17, 2009 Welcome to Yosemite Keep this Guide with You to Get the Most Out of Your Trip to Yosemite National Park information on topics such as camping and hiking. Keep this guide with you as you make your way through the park. Pass it along to friends and family when you get home. Save it as a memento of your trip. This guide represents the collaborative energy of the National Park Service, The Yosemite Fund, DNC Parks & Resorts at Yosemite, Yosemite Association, The Ansel Adams Gallery, and Yosemite Institute—organizations dedicated to Yosemite and to making Illustration by Lawrence W. Duke your visit enjoyable and inspiring (see page 11). -

The Museum of Modern Art Momaexh 1273 Masterchecklist
The Museum of Modern Art 11 West 53 Street, New York, N. Y. 10019 Tel. 956-6100 Cable: Modernart ,L ADAMS AJ.'lDTHEWEST exhibition organized by The Museum of Modern Art, New York, New York ;KLrST: 153 photographs Title and text panel Acknowledgement panel All photographs have Security plates on frames. MoMAExh_1273_MasterChecklist Dimensions Museum Unframed Box Number Title/Date/Proeess/Credit Framed No. 1979.53 Apple Orchard, Winter, Yosemite National 5 15/16 x 7 13/16" 5 Park, California. 12 x 15" n, 1920; p .c , 1927. Lent by the photographer. 1979.63 Diamond Cascade, Lyell Fork of the Merced 2 7/8 x 3 7/8" 5 Canyon, Yosemite National P0rk, California. 8 1/2 x 11" n, 1920; p .c , 1920. Lent by the photographer. 1979.62 Fall in Upper Tenaya Canyon, Yosemite 4 1/16 x 2 7/8" 5 National Park, California. 11 x 8 1/2" n v c , 1920; p ;c . 1920. Lent by the photographer. 1979.66 Merced Peak from Red Peak, Sierra ~evada, 2 7/8 x 3 7/8" 5 California. 8 1/2 x 11" n.e. 1920; p.e. 1920. Lent by the photographer. 1979.65 Summit of Red Peak, Sierra Nevada, 27/8x37/8" 5 California. 8 1/2 x 11" n i c , 1920; p .c , 1920. Lent by the photographer. 1979.67 The Back of Half Dome, Yosemite National 3 3/4 x 2 13/16" 5 Park, California. 11 x 8 1/2" n.e. 1920; p.e. 1920. Lent by the photographer. 1979.64 Vernal Fall and Liberty Cap from the north 3 13/16 x 2 13/16" 5 bank of the Merced River, Yosemite National 11 x 8 1/2" Park, California. -

Yosemit Nate" E Notes
YOSEMIT NATE" E NOTES SEPTEMBER, 1931 Volume X Number 9 Yosemite Nature Notes THE PUBLICATION OF THE YOSEMITE EDUCATIONAL DEPARTMENT AND THE YOSEMITE NATURAL HISTORY ASSOCIATION Published Monthly Volume X September 1931 Number 9 Comments on the Naturalist Work at Tuolumne Meadows RANGER-NATURALIST CARL SHARSMITH Tuolumne Meadows is a unique abound and are close at hand and and valuable station for the natur- easily accessible on short hikes. alist service . An ideal camping The Conness glacier, easily the place, it is attracting an ever in- most accessible and active glacier creasing number of campers, most in the park, giving opportunity to of whom stay four to five days, a examine moraines, crevasses, etc .. good many as long as ten days, is but a half hour's drive and three several who stay practically the en- miles' walk from the ranger station. tire season . The number of camp- The wild flower exhibit which is ers returning to the meadows to easily maintained gives evidence of camp year after year is steadily the richness of the flora ; the prox- growing. imity of the "contact" zone with its The Tuolumne Meadows region is mineralogical and geological inter- a center for the Yosemite High est, mountain peaks of varying de- Sierra . Innumerable hikes and nn- grees of difficulty to climb, timber- ture walks rich in interest are pas- line forests and alpine flora and sible and available to the naturalist fauna, the delightful summer cli- to suit the great width of interest mate ; above all the great numbers in the large followings of the past of responsive and enthusiastic season . -
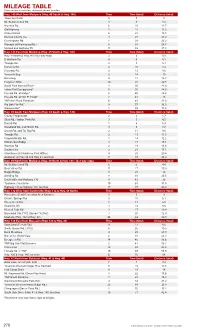
MILEAGE TABLE Time Shown in Minutes; Distance Shown in Miles Hwy
MILEAGE TABLE Time shown in minutes; distance shown in miles Hwy. 140 West from Mariposa (Hwy. 49 South & Hwy. 140) Time Time (total) Distance (total) Yaqui Gulch Rd. 5 5 4 Mt. Bullion Cutoff Rd. 4 9 7.2 Hornitos Rd. 6 15 11.7 Old Highway 3 18 14.2 Chase Ranch 6 24 18.8 Merced County line 4 28 21.2 Cunningham Rd. 1 29 22.2 Planada (at Plainsburg Rd.) 5 34 28.8 Merced and Highway 99 11 45 37.4 Hwy. 140 East from Mariposa (Hwy. 49 South & Hwy. 140) Time Time (total) Distance (total) Hwy. 49 North & Hwy.140 (four way stop) 2 2 0.9 E Whitlock Rd. 4 6 4.1 Triangle Rd. 2 8 5.1 Carstens Rd. 2 10 7.2 Colorado Rd. 2 12 8.6 Yosemite Bug 2 14 10 Briceburg 4 18 12.7 Ferguson Slide 10 28 20.8 South Fork Merced River* 2 30 21.9 Indian Flat Campground* 5 35 24.5 Foresta Rd. at bridge* 5 40 26.8 Foresta Rd. at 'old' El Portal* 2 42 28 YNP Arch Rock Entrance* 6 48 31.5 Big Oak Flat Rd.* 9 57 36.5 Wawona Rd.* 2 59 37.4 Hwy. 49 South from Mariposa (Hwy. 49 South & Hwy. 140) Time Time (total) Distance (total) County Fairgrounds 2 2 1.7 Silva Rd. / Indian Peak Rd. 3 5 4.5 Darrah Rd. 1 6 5.3 Woodland Rd. and Hirsch Rd. 3 9 7.7 Usona Rd. and Tip Top Rd. 2 11 9.6 Triangle Rd. -

The Sierra Club Pictorial Collections at the Bancroft Library Call Number Varies
The Sierra Club Pictorial Collections at The Bancroft Library Call Number Varies Chiefly: BANC PIC 1971.031 through BANC PIC 1971.038 and BANC PIC 1971.073 through 1971.120 The Bancroft Library U.C. Berkeley This is a DRAFT collection guide. It may contain errors. Some materials may be unavailable. Draft guides might refer to material whose location is not confirmed. Direct questions and requests to [email protected] Preliminary listing only. Contents unverified. Direct questions about availability to [email protected] The Sierra Club Pictorial Collections at The Bancroft Library Sierra Club Wilderness Cards - Series 1 BANC PIC 1971.026.001 ca. 24 items. DATES: 19xx Item list may be available at library COMPILER: Sierra Club DONOR: SIZE: PROVENANCE: GENERAL NOTE No Storage Locations: 1971.026.001--A Sierra Club Wilderness Cards - Series 1 24 items Index Terms: Places Represented Drakes Bay (Calif.) --A Echo Park, Dinosaur National Monument (Colo.) --A Northern Cascades (Wash.) --A Point Reyes (Calif.) --A Sawtooth Valley (Idaho) --A Sequoia National Forest (Calif.) --A Volcanic Cascades (Or.) --A Waldo Lake (Or.) --A Wind River (Wyo.) --A Photographer Blaisdell, Lee --A Bradley, Harold C. --A Brooks, Dick --A Douglas, Larry --A Faulconer,DRAFT Philip W. --A Heald, Weldon Fairbanks, 1901-1967 --A Hessey, Charles --A Hyde, Philip --A Litton, Martin --A Riley, James --A Simons, David R., (David Ralph) --A Tepfer, Sanford A. --A Warth, John --A Worth, Don --A Wright, Cedric --A Page 1 of 435 Preliminary listing only. Contents unverified. Direct questions about availability to [email protected] The Sierra Club Pictorial Collections at The Bancroft Library "Discover our outdoors" BANC PIC 1971.026.002 ca.