Planetary Candidates Observed by Kepler. VIII. a Fully Automated Catalog with Measured Completeness and Reliability Based on Data Release 25
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Exploring Exoplanet Populations with NASA's Kepler Mission
SPECIAL FEATURE: PERSPECTIVE PERSPECTIVE SPECIAL FEATURE: Exploring exoplanet populations with NASA’s Kepler Mission Natalie M. Batalha1 National Aeronautics and Space Administration Ames Research Center, Moffett Field, 94035 CA Edited by Adam S. Burrows, Princeton University, Princeton, NJ, and accepted by the Editorial Board June 3, 2014 (received for review January 15, 2014) The Kepler Mission is exploring the diversity of planets and planetary systems. Its legacy will be a catalog of discoveries sufficient for computing planet occurrence rates as a function of size, orbital period, star type, and insolation flux.The mission has made significant progress toward achieving that goal. Over 3,500 transiting exoplanets have been identified from the analysis of the first 3 y of data, 100 planets of which are in the habitable zone. The catalog has a high reliability rate (85–90% averaged over the period/radius plane), which is improving as follow-up observations continue. Dynamical (e.g., velocimetry and transit timing) and statistical methods have confirmed and characterized hundreds of planets over a large range of sizes and compositions for both single- and multiple-star systems. Population studies suggest that planets abound in our galaxy and that small planets are particularly frequent. Here, I report on the progress Kepler has made measuring the prevalence of exoplanets orbiting within one astronomical unit of their host stars in support of the National Aeronautics and Space Admin- istration’s long-term goal of finding habitable environments beyond the solar system. planet detection | transit photometry Searching for evidence of life beyond Earth is the Sun would produce an 84-ppm signal Translating Kepler’s discovery catalog into one of the primary goals of science agencies lasting ∼13 h. -

The Discovery of Exoplanets
L'Univers, S´eminairePoincar´eXX (2015) 113 { 137 S´eminairePoincar´e New Worlds Ahead: The Discovery of Exoplanets Arnaud Cassan Universit´ePierre et Marie Curie Institut d'Astrophysique de Paris 98bis boulevard Arago 75014 Paris, France Abstract. Exoplanets are planets orbiting stars other than the Sun. In 1995, the discovery of the first exoplanet orbiting a solar-type star paved the way to an exoplanet detection rush, which revealed an astonishing diversity of possible worlds. These detections led us to completely renew planet formation and evolu- tion theories. Several detection techniques have revealed a wealth of surprising properties characterizing exoplanets that are not found in our own planetary system. After two decades of exoplanet search, these new worlds are found to be ubiquitous throughout the Milky Way. A positive sign that life has developed elsewhere than on Earth? 1 The Solar system paradigm: the end of certainties Looking at the Solar system, striking facts appear clearly: all seven planets orbit in the same plane (the ecliptic), all have almost circular orbits, the Sun rotation is perpendicular to this plane, and the direction of the Sun rotation is the same as the planets revolution around the Sun. These observations gave birth to the Solar nebula theory, which was proposed by Kant and Laplace more that two hundred years ago, but, although correct, it has been for decades the subject of many debates. In this theory, the Solar system was formed by the collapse of an approximately spheric giant interstellar cloud of gas and dust, which eventually flattened in the plane perpendicular to its initial rotation axis. -

Water, Habitability, and Detectability Steve Desch
Water, Habitability, and Detectability Steve Desch PI, “Exoplanetary Ecosystems” NExSS team School of Earth and Space Exploration, Arizona State University with Ariel Anbar, Tessa Fisher, Steven Glaser, Hilairy Hartnett, Stephen Kane, Susanne Neuer, Cayman Unterborn, Sara Walker, Misha Zolotov Astrobiology Science Strategy NAS Committee, Beckmann Center, Irvine, CA (remotely), January 17, 2018 How to look for life on (Earth-like) exoplanets: find oxygen in their atmospheres How Earth-like must an exoplanet be for this to work? Seager et al. (2013) How to look for life on (Earth-like) exoplanets: find oxygen in their atmospheres Oxygen on Earth overwhelmingly produced by photosynthesizing life, which taps Sun’s energy and yields large disequilibrium signature. Caveats: Earth had life for billions of years without O2 in its atmosphere. First photosynthesis to evolve on Earth was anoxygenic. Many ‘false positives’ recognized because O2 has abiotic sources, esp. photolysis (Luger & Barnes 2014; Harman et al. 2015; Meadows 2017). These caveats seem like exceptions to the ‘rule’ that ‘oxygen = life’. How non-Earth-like can an exoplanet be (especially with respect to water content) before oxygen is no longer a biosignature? Part 1: How much water can terrestrial planets form with? Part 2: Are Aqua Planets or Water Worlds habitable? Can we detect life on them? Part 3: How should we look for life on exoplanets? Part 1: How much water can terrestrial planets form with? Theory says: up to hundreds of oceans’ worth of water Trappist-1 system suggests hundreds of oceans, especially around M stars Many (most?) planets may be Aqua Planets or Water Worlds How much water can terrestrial planets form with? Earth- “snow line” Standard Sun distance models of distance accretion suggest abundant water. -
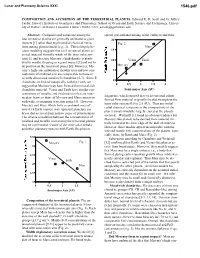
Composition and Accretion of the Terrestrial Planets
Lunar and Planetary Science XXXI 1546.pdf COMPOSITION AND ACCRETION OF THE TERRESTRIAL PLANETS. Edward R. D. Scott and G. Jeffrey Taylor, Hawai’i Institute of Geophysics and Planetology, School of Ocean and Earth Science and Technology, Univer- sity of Hawai’i at Manoa, Honolulu, Hawai’i 96822, USA; [email protected] Abstract: Compositional variations among the spread gravitational mixing of the embryos and their four terrestrial planets are generally attributed to giant 20 impacts [1] rather than to primordial chemical varia- Fig. 2 tions among planetesimals [e.g., 2]. This is largely be- Mars cause modeling suggests that each terrestrial planet ac- 15 creted material from the whole of the inner solar sys- tem [1], and because Mercury’s high density is attrib- 10 Venus Earth uted to mantle stripping in a giant impact [3] and not to its position as the innermost planet [4]. However, Mer- Mercury cury’s high concentration of metallic iron and low con- 5 centration of oxidized iron are comparable to those in recently discovered metal-rich chondrites [5-7]. Since E 0 chondrites are linked isotopically with the Earth, we 0 0.5 1 1.5 2 suggest that Mercury may have formed from metal-rich chondritic material. Venus and Earth have similar con- Semi-major Axis (AU) centrations of metallic and oxidized iron that are inter- fragments, which ensured that each terrestrial planet mediate between those of Mercury and Mars consistent formed from material originally located throughout the with wide, overlapping accretion zones [1]. However, inner solar system (0.5 to 2.5 AU). -

POSSIBLE STRUCTURE MODELS for the TRANSITING SUPER-EARTHS:KEPLER-10B and 11B
43rd Lunar and Planetary Science Conference (2012) 1290.pdf POSSIBLE STRUCTURE MODELS FOR THE TRANSITING SUPER-EARTHS:KEPLER-10b AND 11b. P. Futó1 1 Department of Physical Geography, University of West Hungary, Szombathely, Károlyi Gáspár tér, H- 9700, Hungary ([email protected]) Introduction:Up to january of 2012,10 super- The planet Kepler-11b has a large radius (1.97 R⊕) for Earths have been announced by Kepler-mission [1] its mass (4.3 M⊕),therefore this planet must have a that is designed to detect hundreds of transiting exo- spherical shell that is composed of low-density materi- planets.Kepler was launched on 6th March,2009 and the als.Considering the planet's average density,it must primary purpose of its scientific program is to search have a metallic core with different possible fractional for terrestrial-sized planets in the habitable zone of mass.Accordinghly,I have made a possible structure Solar-like stars.For the case of high number of discov- model for Kepler-11b in which the selected core mass eries we will be able to estimate the frequency of fraction is 32.59% (similarly to that of Earth) and the Earth-sized planets in our galaxy.Results of the Kepler- water ice layer has a relatively great fractional 's measurements show that the small-sized planets are volume.For case of the selected composition, the icy frequent in the spiral galaxies.A catalog of planetary surface sublimated to form a water vapor as the planet candidates,including objects with small-sized candidate moved inward the central star during its migration. -

Planetary Science
Scientific Research National Aeronautics and Space Administration Planetary Science MSFC planetary scientists are active in Peering into the history The centerpiece of the Marshall efforts is research at Marshall, building on a long history of the solar system the Marshall Noble Gas Research Laboratory of scientific support to NASA’s human explo- (MNGRL), a unique facility within NASA. Noble- ration program planning, whether focused Marshall planetary scientists use multiple anal- gas isotopes are a well-established technique on the Moon, asteroids, or Mars. Research ysis techniques to understand the formation, for providing detailed temperature-time histories areas of expertise include planetary sample modification, and age of planetary materials of rocks and meteorites. The MNGRL lab uses analysis, planetary interior modeling, and to learn about their parent planets. Sample Ar-Ar and I-Xe radioactive dating to find the planetary atmosphere observations. Scientists analysis of this type is well-aligned with the formation age of rocks and meteorites, and at Marshall are involved in several ongoing priorities for scientific research and analysis Ar/Kr/Ne cosmic-ray exposure ages to under- planetary science missions, including the Mars in NASA’s Planetary Science Division. Multiple stand when the meteorites were launched from Exploration Rovers, the Cassini mission to future missions are poised to provide new their parent planets. Saturn, and the Gravity Recovery and Interior sample-analysis opportunities. Laboratory (GRAIL) mission to the Moon. Marshall is the center for program manage- ment for the Agency’s Discovery and New Frontiers programs, providing programmatic oversight into a variety of missions to various planetary science destinations throughout the solar system, from MESSENGER’s investiga- tions of Mercury to New Frontiers’ forthcoming examination of the Pluto system. -

On the Use of Planetary Science Data for Studying Extrasolar Planets a Science Frontier White Paper Submitted to the Astronomy & Astrophysics 2020 Decadal Survey
On the Use of Planetary Science Data for Studying Extrasolar Planets A science frontier white paper submitted to the Astronomy & Astrophysics 2020 Decadal Survey Thematic Area: Planetary Systems Principal Author Daniel J. Crichton Jet Propulsion Laboratory, California Institute of Technology [email protected] 818-354-9155 Co-Authors: J. Steve Hughes, Gael Roudier, Robert West, Jeffrey Jewell, Geoffrey Bryden, Mark Swain, T. Joseph W. Lazio (Jet Propulsion Laboratory, California Institute of Technology) There is an opportunity to advance both solar system and extrasolar planetary studies that does not require the construction of new telescopes or new missions but better use and access to inter-disciplinary data sets. This approach leverages significant investment from NASA and international space agencies in exploring this solar system and using those discoveries as “ground truth” for the study of extrasolar planets. This white paper illustrates the potential, using phase curves and atmospheric modeling as specific examples. A key advance required to realize this potential is to enable seamless discovery and access within and between planetary science and astronomical data sets. Further, seamless data discovery and access also expands the availability of science, allowing researchers and students at a variety of institutions, equipped only with Internet access and a decent computer to conduct cutting-edge research. © 2019 California Institute of Technology. Government sponsorship acknowledged. Pre-decisional - For planning -

PDF— Granite-Greenstone Belts Separated by Porcupine-Destor
C G E S NT N A ER S e B EC w o TIO ok N Vol. 8, No. 10 October 1998 es st t or INSIDE Rel e • 1999 Section Meetings ea GSA TODAY Rocky Mountain, p. 25 ses North-Central, p. 27 A Publication of the Geological Society of America • Honorary Fellows, p. 8 Lithoprobe Leads to New Perspectives on 70˚ -140˚ 70˚ Continental Evolution -40˚ Ron M. Clowes, Lithoprobe, University -120˚ of British Columbia, 6339 Stores Road, -60˚ -100˚ -80˚ Vancouver, BC V6T 1Z4, Canada, 60˚ Wopmay 60˚ [email protected] Slave SNORCLE Fred A. Cook, Department of Geology & Thelon Rae Geophysics, University of Calgary, Calgary, Nain Province AB T2N 1N4, Canada 50˚ ECSOOT John N. Ludden, Centre de Recherches Hearne Pétrographiques et Géochimiques, Taltson Vandoeuvre-les-Nancy, Cedex, France AB Trans-Hudson Orogen SC THOT LE WS Superior Province ABSTRACT Cordillera AG Lithoprobe, Canada’s national earth KSZ o MRS 40 40 science research project, was established o Grenville Province in 1984 to develop a comprehensive Wyoming Penokean GL -60˚ understanding of the evolution of the -120˚ Yavapai Province Orogen Appalachians northern North American continent. With rocks representing 4 b.y. of Earth -100˚ -80˚ history, the Canadian landmass and off- Phanerozoic Proterozoic Archean shore margins provide an exceptional 200 Ma - present 1100 Ma 3200 - 2650 Ma opportunity to gain new perspectives on continental evolution. Lithoprobe’s 470 - 275 Ma 1300 - 1000 Ma 3400 - 2600 Ma 10 study areas span the country and 1800 - 1600 Ma 3800 - 2800 Ma geological time. A pan-Lithoprobe syn- 1900 - 1800 Ma 4000 - 2500 Ma thesis will bring the project to a formal conclusion in 2003. -

Exep Science Plan Appendix (SPA) (This Document)
ExEP Science Plan, Rev A JPL D: 1735632 Release Date: February 15, 2019 Page 1 of 61 Created By: David A. Breda Date Program TDEM System Engineer Exoplanet Exploration Program NASA/Jet Propulsion Laboratory California Institute of Technology Dr. Nick Siegler Date Program Chief Technologist Exoplanet Exploration Program NASA/Jet Propulsion Laboratory California Institute of Technology Concurred By: Dr. Gary Blackwood Date Program Manager Exoplanet Exploration Program NASA/Jet Propulsion Laboratory California Institute of Technology EXOPDr.LANET Douglas Hudgins E XPLORATION PROGRAMDate Program Scientist Exoplanet Exploration Program ScienceScience Plan Mission DirectorateAppendix NASA Headquarters Karl Stapelfeldt, Program Chief Scientist Eric Mamajek, Deputy Program Chief Scientist Exoplanet Exploration Program JPL CL#19-0790 JPL Document No: 1735632 ExEP Science Plan, Rev A JPL D: 1735632 Release Date: February 15, 2019 Page 2 of 61 Approved by: Dr. Gary Blackwood Date Program Manager, Exoplanet Exploration Program Office NASA/Jet Propulsion Laboratory Dr. Douglas Hudgins Date Program Scientist Exoplanet Exploration Program Science Mission Directorate NASA Headquarters Created by: Dr. Karl Stapelfeldt Chief Program Scientist Exoplanet Exploration Program Office NASA/Jet Propulsion Laboratory California Institute of Technology Dr. Eric Mamajek Deputy Program Chief Scientist Exoplanet Exploration Program Office NASA/Jet Propulsion Laboratory California Institute of Technology This research was carried out at the Jet Propulsion Laboratory, California Institute of Technology, under a contract with the National Aeronautics and Space Administration. © 2018 California Institute of Technology. Government sponsorship acknowledged. Exoplanet Exploration Program JPL CL#19-0790 ExEP Science Plan, Rev A JPL D: 1735632 Release Date: February 15, 2019 Page 3 of 61 Table of Contents 1. -

Exoplanetary Atmospheres: Key Insights, Challenges, and Prospects
AA57CH15_Madhusudhan ARjats.cls August 7, 2019 14:11 Annual Review of Astronomy and Astrophysics Exoplanetary Atmospheres: Key Insights, Challenges, and Prospects Nikku Madhusudhan Institute of Astronomy, University of Cambridge, Cambridge CB3 0HA, United Kingdom; email: [email protected] Annu. Rev. Astron. Astrophys. 2019. 57:617–63 Keywords The Annual Review of Astronomy and Astrophysics is extrasolar planets, spectroscopy, planet formation, habitability, atmospheric online at astro.annualreviews.org composition https://doi.org/10.1146/annurev-astro-081817- 051846 Abstract Copyright © 2019 by Annual Reviews. Exoplanetary science is on the verge of an unprecedented revolution. The All rights reserved thousands of exoplanets discovered over the past decade have most recently been supplemented by discoveries of potentially habitable planets around nearby low-mass stars. Currently, the field is rapidly progressing toward de- tailed spectroscopic observations to characterize the atmospheres of these planets. Various surveys from space and the ground are expected to detect numerous more exoplanets orbiting nearby stars that make the planets con- ducive for atmospheric characterization. The current state of this frontier of exoplanetary atmospheres may be summarized as follows. We have entered the era of comparative exoplanetology thanks to high-fidelity atmospheric observations now available for tens of exoplanets. Access provided by Florida International University on 01/17/21. For personal use only. Annu. Rev. Astron. Astrophys. 2019.57:617-663. Downloaded from www.annualreviews.org Recent studies reveal a rich diversity of chemical compositions and atmospheric processes hitherto unseen in the Solar System. Elemental abundances of exoplanetary atmospheres place impor- tant constraints on exoplanetary formation and migration histories. -

Download This Article in PDF Format
A&A 539, A28 (2012) Astronomy DOI: 10.1051/0004-6361/201118309 & c ESO 2012 Astrophysics Improved precision on the radius of the nearby super-Earth 55 Cnc e M. Gillon1, B.-O. Demory2, B. Benneke2, D. Valencia2,D.Deming3, S. Seager2, Ch. Lovis4, M. Mayor4,F.Pepe4,D.Queloz4, D. Ségransan4,andS.Udry4 1 Institut d’Astrophysique et de Géophysique, Université de Liège, Allée du 6 Août 17, Bˆat. B5C, 4000 Liège, Belgium e-mail: [email protected] 2 Department of Earth, Atmospheric and Planetary Sciences, Department of Physics, Massachusetts Institute of Technology, 77 Massachusetts Ave., Cambridge, MA 02139, USA 3 Department of Astronomy, University of Maryland, College Park, MD 20742-2421, USA 4 Observatoire de Genève, Université de Genève, 51 chemin des Maillettes, 1290 Sauverny, Switzerland Received 21 October 2011 / Accepted 28 December 2011 ABSTRACT We report on new transit photometry for the super-Earth 55 Cnc e obtained with Warm Spitzer/IRAC at 4.5 μm. An individual analysis . +0.15 of these new data leads to a planet radius of 2 21−0.16 R⊕, which agrees well with the values previously derived from the MOST and Spitzer transit discovery data. A global analysis of both Spitzer transit time-series improves the precision on the radius of the planet at 4.5 μmto2.20 ± 0.12 R⊕. We also performed an independent analysis of the MOST data, paying particular attention to the influence of the systematic effects of instrumental origin on the derived parameters and errors by including them in a global model instead of performing a preliminary detrending-filtering processing. -

On the Detection of Exoplanets Via Radial Velocity Doppler Spectroscopy
The Downtown Review Volume 1 Issue 1 Article 6 January 2015 On the Detection of Exoplanets via Radial Velocity Doppler Spectroscopy Joseph P. Glaser Cleveland State University Follow this and additional works at: https://engagedscholarship.csuohio.edu/tdr Part of the Astrophysics and Astronomy Commons How does access to this work benefit ou?y Let us know! Recommended Citation Glaser, Joseph P.. "On the Detection of Exoplanets via Radial Velocity Doppler Spectroscopy." The Downtown Review. Vol. 1. Iss. 1 (2015) . Available at: https://engagedscholarship.csuohio.edu/tdr/vol1/iss1/6 This Article is brought to you for free and open access by the Student Scholarship at EngagedScholarship@CSU. It has been accepted for inclusion in The Downtown Review by an authorized editor of EngagedScholarship@CSU. For more information, please contact [email protected]. Glaser: Detection of Exoplanets 1 Introduction to Exoplanets For centuries, some of humanity’s greatest minds have pondered over the possibility of other worlds orbiting the uncountable number of stars that exist in the visible universe. The seeds for eventual scientific speculation on the possibility of these "exoplanets" began with the works of a 16th century philosopher, Giordano Bruno. In his modernly celebrated work, On the Infinite Universe & Worlds, Bruno states: "This space we declare to be infinite (...) In it are an infinity of worlds of the same kind as our own." By the time of the European Scientific Revolution, Isaac Newton grew fond of the idea and wrote in his Principia: "If the fixed stars are the centers of similar systems [when compared to the solar system], they will all be constructed according to a similar design and subject to the dominion of One." Due to limitations on observational equipment, the field of exoplanetary systems existed primarily in theory until the late 1980s.