A Survey of GPU-Based Large- Scale Volume Visualization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Catalogue Description
INF 454: Data Visualization and User Interface Design Spring 2016 Syllabus Day/Times: TBD (4 Units) Location: TBD Instructor: Dr. Luciano Nocera Email: [email protected] Phone: (213) 740-9819 Office: PHE 412 Course TA: TBD Email: TBD Office Hours: TBD IT Support: TBD Email: TBD Office Hours: TBD Instructor’s Office Hours: TBD; other hours by appointment only. Students are advised to make appointments ahead of time in any event and be specific with the subject matter to be discussed. Students should also be prepared for their appointment by bringing all applicable materials and information. Catalogue Description One of the cornerstones of analytics is presenting the data to customers in a usable fashion. When considering the design of systems that will perform data analytic functions, both the interface for the user and the graphical depictions of data are of utmost importance, as it allows for more efficient and effective processing, leading to faster and more accurate results. To foster the best tools possible, it is important for designers to understand the principles of user interfaces and data visualization as the tools they build are used by many people - with technical and non-technical background - to perform their work. In this course, students will apply the fundamentals and techniques in a semester-long group project where they design, build and test a responsive application that runs on mobile devices and desktops and that includes graphical depictions of data for communication, analysis, and decision support. Short description: Foundational course focusing on the design, creation, understanding, application, and evaluation of data visualization and user interface design for communicating, interacting and exploring data. -

Volume Rendering
Volume Rendering 1.1. Introduction Rapid advances in hardware have been transforming revolutionary approaches in computer graphics into reality. One typical example is the raster graphics that took place in the seventies, when hardware innovations enabled the transition from vector graphics to raster graphics. Another example which has a similar potential is currently shaping up in the field of volume graphics. This trend is rooted in the extensive research and development effort in scientific visualization in general and in volume visualization in particular. Visualization is the usage of computer-supported, interactive, visual representations of data to amplify cognition. Scientific visualization is the visualization of physically based data. Volume visualization is a method of extracting meaningful information from volumetric datasets through the use of interactive graphics and imaging, and is concerned with the representation, manipulation, and rendering of volumetric datasets. Its objective is to provide mechanisms for peering inside volumetric datasets and to enhance the visual understanding. Traditional 3D graphics is based on surface representation. Most common form is polygon-based surfaces for which affordable special-purpose rendering hardware have been developed in the recent years. Volume graphics has the potential to greatly advance the field of 3D graphics by offering a comprehensive alternative to conventional surface representation methods. The object of this thesis is to examine the existing methods for volume visualization and to find a way of efficiently rendering scientific data with commercially available hardware, like PC’s, without requiring dedicated systems. 1.2. Volume Rendering Our display screens are composed of a two-dimensional array of pixels each representing a unit area. -

Introduction to Geospatial Data Visualization
Introduction to Geospatial Data Visualization Lecturers: Viktor Lagutov, Katalin Szende, Joszef Laszlovsky. Ruben Mnatsakanian Duration: Fall term (September – December) Credits: 2 Course level: PhD / MA Maximum number of students: 15 Pre-requisites: none Software: GoogleEarthPro, qGIS, online mapping tools (e.g. GoogleMaps, ArcGISonline) Rapidly growing cross-disciplinary recognition and availability made Geospatial Methods in general, and Mapping, in particular, a popular approach in many research areas. Till recently, maps development had been a prerogative of cartographers and, later, experts in specialized mapping packages. Latest advances in hardware and software have opened this area to researchers in other disciplines and allowed them to enhance traditional research methods. The wide spectrum of such technologies and approaches is often referred as Geographic Information Systems (GIS) and includes, among others, mapping packages, geospatial analysis, crowdsourcing with mobile technologies, drones, online interactive data publishing. The geospatial literacy is becoming not an optional advantage for researchers and policy officers, but a basic requirement for many employers. The aim of the course is to develop basic understanding of spatially referenced data use and to explore potential applications of GIS in various research areas. The sessions provide both theoretical understanding and practical use of geospatial data and technologies for mapping societal and environmental phenomena. Students will learn basic features of GIS packages and the ways to utilize them for own research. The course is focused on practical skills in geospatial data visualization (mapping) and consists of • Theoretical sessions on principles of geospatial data visualization, cartography and GIS basics; • Practicals on learning GIS methods and getting mapping skills using free open source packages; • Supervised and independent students’ work on individual course projects. -

Tree-Map: a Visualization Tool for Large Data
TREE-MAP: A VISUALIZATION TOOL FOR LARGE DATA Mahipal Jadeja Kesha Shah DA-IICT DA-IICT Gandhinagar,Gujarat Gandhinagar,Gujarat India India Tel:+91-9173535506 Tel:+91-7405217629 [email protected] [email protected] ABSTRACT 1. INTRODUCTION Traditional approach to represent hierarchical data is to use Tree-Maps are used to present hierarchical information on directed tree. But it is impractical to display large (in terms 2-D[1] (or 3-D [2]) displays. Tree-maps offer many features: of size as well complexity) trees in limited amount of space. based upon attribute values users can specify various cate- In order to render large trees consisting of millions of nodes gories, users can visualize as well as manipulate categorized efficiently, the Tree-Map algorithm was developed. Even file information and saving of more than one hierarchy is also system of UNIX can be represented using Tree-Map. Defi- supported [3]. nition of Tree-Maps is recursive: allocate one box for par- Various tiling algorithms are known for tree-maps namely: ent node and children of node are drawn as boxes within Binary tree, mixed treemaps, ordered, slice and dice, squar- it. Practically, it is possible to render any tree within prede- ified and strip. Transition from traditional representation fined space using this technique. It has applications in many methods to Tree-Maps are shown below. In figure 1 given fields including bio-informatics, visualization of stock port- hierarchical data and equivalent tree representation of given folio etc. This paper supports Tree-Map method for data data are shown. One can consider nodes as sets, children integration aspect of knowledge graph. -

Connected 2D and 3D Visualizations for the Interactive Exploration of Spatial Information
CONNECTED 2D AND 3D VISUALIZATIONS FOR THE INTERACTIVE EXPLORATION OF SPATIAL INFORMATION S. Bleisch *, S. Nebiker FHNW, University of Applied Sciences Northwestern Switzerland, Institute of Geomatics Engineering, CH-4132 Muttenz, Switzerland - (susanne.bleisch, stephan.nebiker)@fhnw.ch KEY WORDS: Geovisualization, Three-dimensional representation, Interactive, Spatial Data Exploration, Virtual globe, Development ABSTRACT: This paper describes the concepts and the successful prototypal implementation of interactively connected 2D information visualizations and data displays in 3D virtual environments for the interactive exploration of spatial data and information. Virtual globes or earth viewers such as Google Earth have become very popular over the last few years. They are used for looking at holiday destinations but more importantly also for scientific visualizations. From a geovisualization point of view we might regard 3D data or information displays as yet another representation type that adds to the multitude of information visualization methods. Combining 3D views of data sets with traditional 2D displays offers the advantage of being able to use 3D if and when this type of representation is considered useful or effective for finding new insights into a data set. The traditional and newer displays of mainly 2D information visualization may be enhanced and new insights into the data may be generated by displays of the data in a 3D virtual environment. On the other hand, data in 3D displays might be better understood by simultaneously reading and querying connected 2D representations.The paper presents a prototypal implementation of the interactively connected visualizations of spatial information in 2D views and 3D virtual environments using the brushing technique. -

From Surface Rendering to Volume
What is Computer Graphics? • Computational process of generating images from models and/or datasets using computers • This is called rendering (computer graphics was traditionally considered as a rendering method) • A rendering algorithm converts a geometric model and/or dataset into a picture Department of Computer Science CSE564 Lectures STNY BRK Center for Visual Computing STATE UNIVERSITY OF NEW YORK What is Computer Graphics? This process is also called scan conversion or rasterization How does Visualization fit in here? Department of Computer Science CSE564 Lectures STNY BRK Center for Visual Computing STATE UNIVERSITY OF NEW YORK Computer Graphics • Computer graphics consists of : 1. Modeling (representations) 2. Rendering (display) 3. Interaction (user interfaces) 4. Animation (combination of 1-3) • Usually “computer graphics” refers to rendering Department of Computer Science CSE564 Lectures STNY BRK Center for Visual Computing STATE UNIVERSITY OF NEW YORK Computer Graphics Components Department of Computer Science CSE364 Lectures STNY BRK Center for Visual Computing STATE UNIVERSITY OF NEW YORK Surface Rendering • Surface representations are good and sufficient for objects that have homogeneous material distributions and/or are not translucent or transparent • Such representations are good only when object boundaries are important (in fact, only boundary geometric information is available) • Examples: furniture, mechanical objects, plant life • Applications: video games, virtual reality, computer- aided design Department of -

Infovis and Statistical Graphics: Different Goals, Different Looks1
Infovis and Statistical Graphics: Different Goals, Different Looks1 Andrew Gelman2 and Antony Unwin3 20 Jan 2012 Abstract. The importance of graphical displays in statistical practice has been recognized sporadically in the statistical literature over the past century, with wider awareness following Tukey’s Exploratory Data Analysis (1977) and Tufte’s books in the succeeding decades. But statistical graphics still occupies an awkward in-between position: Within statistics, exploratory and graphical methods represent a minor subfield and are not well- integrated with larger themes of modeling and inference. Outside of statistics, infographics (also called information visualization or Infovis) is huge, but their purveyors and enthusiasts appear largely to be uninterested in statistical principles. We present here a set of goals for graphical displays discussed primarily from the statistical point of view and discuss some inherent contradictions in these goals that may be impeding communication between the fields of statistics and Infovis. One of our constructive suggestions, to Infovis practitioners and statisticians alike, is to try not to cram into a single graph what can be better displayed in two or more. We recognize that we offer only one perspective and intend this article to be a starting point for a wide-ranging discussion among graphics designers, statisticians, and users of statistical methods. The purpose of this article is not to criticize but to explore the different goals that lead researchers in different fields to value different aspects of data visualization. Recent decades have seen huge progress in statistical modeling and computing, with statisticians in friendly competition with researchers in applied fields such as psychometrics, econometrics, and more recently machine learning and “data science.” But the field of statistical graphics has suffered relative neglect. -

Data Visualization: an Exploratory Study Into the Software Tools Used by Businesses
Journal of Instructional Pedagogies Volume 18 Data visualization: an exploratory study into the software tools used by businesses Michael Diamond Jacksonville University Angela Mattia Jacksonville University Abstract Data visualization is a key component to business and data analytics, allowing analysts in businesses to create tools such as dashboards for business executives. Various software packages allow businesses to create these tools in order to manipulate data for making informed business decisions. The focus is to examine what skills employers are looking for in potential job candidates, and compare with the ability to include those technological skills in a business school curriculum. The researchers explored a variety of software tools, and reported their initial results and conclusions. Keywords: data visualization, business analytics, dashboards Copyright statement: Authors retain the copyright to the manuscripts published in AABRI journals. Please see the AABRI Copyright Policy at http://www.aabri.com/copyright.html Data Visualization 1 Journal of Instructional Pedagogies Volume 18 Introduction The visualization and interpretation of data is becoming an important skill in today’s business world. Indeed, the inclusion of data visualizations and dashboards allows executives to make decisions in a short amount of time given the information which is needed (Eigner, 2013). This is a critical part of the evolution of business intelligence to what is now known as the area of business analytics (Negash, 2004). Furthermore, the growing importance of ‘big data’ has created a shortage of employees with data and business analytics skills, with the expectations of a need of close to 1.8 million jobs in these areas (Manyika et al., 2012; Lohr, 2012). -

What Is Interaction for Data Visualization? Evanthia Dimara, Charles Perin
What is Interaction for Data Visualization? Evanthia Dimara, Charles Perin To cite this version: Evanthia Dimara, Charles Perin. What is Interaction for Data Visualization?. IEEE Transactions on Visualization and Computer Graphics, Institute of Electrical and Electronics Engineers, 2020, 26 (1), pp.119 - 129. 10.1109/TVCG.2019.2934283. hal-02197062 HAL Id: hal-02197062 https://hal.archives-ouvertes.fr/hal-02197062 Submitted on 30 Jul 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. What is Interaction for Data Visualization? Evanthia Dimara and Charles Perin∗ Abstract—Interaction is fundamental to data visualization, but what “interaction” means in the context of visualization is ambiguous and confusing. We argue that this confusion is due to a lack of consensual definition. To tackle this problem, we start by synthesizing an inclusive view of interaction in the visualization community – including insights from information visualization, visual analytics and scientific visualization, as well as the input of both senior and junior visualization researchers. Once this view takes shape, we look at how interaction is defined in the field of human-computer interaction (HCI). By extracting commonalities and differences between the views of interaction in visualization and in HCI, we synthesize a definition of interaction for visualization. -
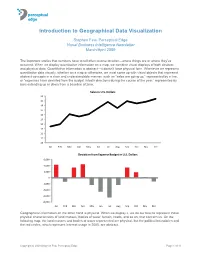
Introduction to Geographical Data Visualization
perceptual edge Introduction to Geographical Data Visualization Stephen Few, Perceptual Edge Visual Business Intelligence Newsletter March/April 2009 The important stories that numbers have to tell often involve location—where things are or where they’ve occurred. When we display quantitative information on a map, we combine visual displays of both abstract and physical data. Quantitative information is abstract—it doesn’t have physical form. Whenever we represent quantitative data visually, whether on a map or otherwise, we must come up with visual objects that represent abstract concepts in a clear and understandable manner, such as “sales are going up,” represented by a line, or “expenses have deviated from the budget in both directions during the course of the year,” represented by bars extending up or down from a baseline of zero. Sales in U.S. Dollars 20 19 18 17 16 15 14 13 12 11 10 Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec Deviaon from Expense Budget in U.S. Dollars 6,000 4,000 2,000 0 -2,000 -4,000 -6,000 -8,000 Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec Geographical information on the other hand is physical. When we display it, we do our best to represent those physical characteristics of land masses, bodies of water, terrain, roads, and so on, that concern us. On the following map, the land masses and bodies of water represented are physical, but the political boundaries and the red circles, which represent Internet usage in 2005, are abstract. -

Graphics Lies, Misleading Visuals
Chapter 5 Graphics Lies, Misleading Visuals Reflections on the Challenges and Pitfalls of Evidence-Driven Visual Communication Alberto Cairo Abstract The past two decades have witnessed an increased awareness of the power of information visualization to bring attention to relevant issues and to inform audiences. However, the mirror image of that awareness, the study of how graphs, charts, maps, and diagrams can be used to deceive, has remained within the boundaries of academic circles in statistics, cartography, and computer science. Visual journalists and information graphics designers—who we will call evidence- driven visual communicators—have been mostly absent of this debate. This has led to disastrous results in many cases, as those professions are—even in an era of shrinking news media companies—the main intermediaries between the complexity of the world and citizens of democratic nations. This present essay explains the scope of the problem and proposes tweaks in educational programs to overcome it. 5.1 Introduction Can information graphics (infographics) and visualizations1 lie? Most designers and journalists I know would yell a rotund “yes” and rush to present us with examples of outrageously misleading charts and maps. Watchdog organizations such as Media Matters for America have recently began collecting them (Groch-Begley and Shere 2012), and a few satirical Web sites have gained popularity criticizing them.2 Needless to say, they are all great fun. 1 I will be using the words “information graphics,”“infographics,” and “visualization” with the same meaning: Any visual representation based on graphs, charts, maps, diagrams, and pictorial illustrations designed to inform an audience, or to let that same audience explore data at will. -

Visualizing Big Data on Maps: Emerging Tools and Techniques
Visualizing Big Data on Maps: Emerging Tools and Techniques Ilir Bejleri, Sanjay Ranka Topics • Web GIS Visualization • Big Data GIS Performance • Maps in Data Visualization Platforms Next: • Web GIS Visualization • Big Data GIS Performance • Maps in Data Visualization Platforms Web GIS Visualization Platforms • Claud-based mapping platforms e.g. ArcGIS Online • Maps created on desktop & loaded on the cloud • Self-service capabilities and ready-to-use maps • Include spatial analytics capabilities • Possibilities for customization Visualization in Maps • Smart mapping – relevant information at appropriate scale • Vector Tiles – high-performance – re-styled to work in any map • 3D – add context to the story Custom Web GIS Visualization • More flexible • Mix and match various technologies • Integrate with relational and other databases • But require more time to build • Florida Signal Four Analytics – a web-based GIS centric crash data system Signal Four Analytics Crash and Traffic Citations Database Over 10 million crashes & citations Street Network– Florida Unified Basemap LINKS INTERSECTIONS CURVES 1.8 600,000600,000 200,000 million Chart Attributes Network Analysis Network Analysis Filters 39 Network Analysis Filters 40 Extract data out of the system To Get Access: • s4.geoplan.ufl.edu -> Request Access • Contact [email protected] 49 Next: • GIS Visualization • Big Data GIS Performance • Maps in Data Visualization Platforms Performance Evaluation of Big-Data GIS systems • Increase in use of networked, • New solutions for large-scale location aware, pervasive processing data try to exploit scalability computing devices for planning and provided by parallel, distributed computing systems. monitoring the transportation infrastructure has resulted in a huge • We try to evaluate the effectiveness of increase in the size of location- these distributed, parallel systems for aware datasets.