An Empirical Study of References to People in News Summaries
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
WAU - Whereabouts Unknown Account Information
WAU - Whereabouts Unknown Account Information GREAT PLAINS REGION 3 July 2018 Name Tribe ROSEBUD AGENCY ABBENHAUS, EDWARD L ROSEBUD SIOUX TRIBE ACHTIZIGER, LARRY D ROSEBUD SIOUX TRIBE ACOSTA, DEVONE* ROSEBUD SIOUX TRIBE ACOSTA, ROBERT* ROSEBUD SIOUX TRIBE ADAM, ROBERT DAVID LEE ROSEBUD SIOUX TRIBE ADAMS, JUSTIN J ROSEBUD SIOUX TRIBE ALEXANDER, MARY JOAN* ROSEBUD SIOUX TRIBE ALLEN, JOSEPH J ROSEBUD SIOUX TRIBE ALLEN, MARTHA M ROSEBUD SIOUX TRIBE ALLEN, SUSAN L ROSEBUD SIOUX TRIBE ALVAREZ, OLIVE M ROSEBUD SIOUX TRIBE ALVEREZ, ROBERT* ROSEBUD SIOUX TRIBE AMIOTTE, DARRELL F* ROSEBUD SIOUX TRIBE ANDERSON, ANGELINE SCHERR* ROSEBUD SIOUX TRIBE ANDERSON, ANTIONE ROSEBUD SIOUX TRIBE ANDERSON, RONALD RAY ROSEBUD SIOUX TRIBE ANDREWS, TANYA* ROSEBUD SIOUX TRIBE ANDREWS HANSON, JUDY ROSEBUD SIOUX TRIBE ANGLIN, CHERRI J ROSEBUD SIOUX TRIBE ANTELOPE, TANYA R ROSEBUD SIOUX TRIBE ANTOINE, CHERYL J ROSEBUD SIOUX TRIBE ANTOINE, MURIEL ROSEBUD SIOUX TRIBE ANTOINE JR, WALLACE V ROSEBUD SIOUX TRIBE APPLE, LORENZO JAMES ROSEBUD SIOUX TRIBE AQUALLO, DANIELLE ROSEBUD SIOUX TRIBE Page 1 of 65 WAU - Whereabouts Unknown Account Information GREAT PLAINS REGION 3 July 2018 Name Tribe AQUASH, BARRY ROSEBUD SIOUX TRIBE AQUASH, SAMANTHA ROSEBUD SIOUX TRIBE ARAGON, RUDY R ROSEBUD SIOUX TRIBE ARCOREN, JASON ROSEBUD SIOUX TRIBE ARCOREN, TIMOTHY ROSEBUD SIOUX TRIBE ARIAS, CHARLENE M ROSEBUD SIOUX TRIBE ARROW (LASLEY), DELMA RAE* ROSEBUD SIOUX TRIBE ARTICHOKER, MARY L ROSEBUD SIOUX TRIBE ASHLEY, ASHLEY A ROSEBUD SIOUX TRIBE AT THE STRAIGHT, ROYCE A* ROSEBUD SIOUX TRIBE ATKINS, -
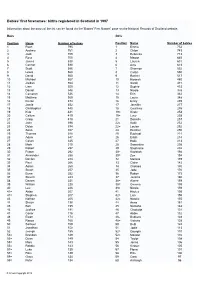
Babies' First Forenames: Births Registered in Scotland in 1997
Babies' first forenames: births registered in Scotland in 1997 Information about the basis of the list can be found via the 'Babies' First Names' page on the National Records of Scotland website. Boys Girls Position Name Number of babies Position Name Number of babies 1 Ryan 795 1 Emma 752 2 Andrew 761 2 Chloe 743 3 Jack 759 3 Rebecca 713 4 Ross 700 4 Megan 645 5 James 638 5 Lauren 631 6 Connor 590 6 Amy 623 7 Scott 586 7 Shannon 552 8 Lewis 568 8 Caitlin 550 9 David 560 9 Rachel 517 10 Michael 557 10 Hannah 480 11 Jordan 554 11 Sarah 471 12 Liam 550 12 Sophie 433 13 Daniel 546 13 Nicole 378 14 Cameron 526 14 Erin 362 15 Matthew 509 15 Laura 348 16 Kieran 474 16 Emily 289 17 Jamie 452 17 Jennifer 277 18 Christopher 440 18 Courtney 276 19 Kyle 421 19= Kirsty 258 20 Callum 419 19= Lucy 258 21 Craig 418 21 Danielle 257 22 John 396 22= Katie 252 23 Dylan 394 22= Louise 252 24 Sean 367 24 Heather 250 25 Thomas 348 25 Rachael 221 26 Adam 347 26 Eilidh 214 27 Calum 335 27 Holly 213 28 Mark 310 28 Samantha 208 29 Robert 297 29 Stephanie 202 30 Fraser 292 30= Kayleigh 194 31 Alexander 288 30= Zoe 194 32 Declan 284 32 Melissa 189 33 Paul 266 33 Claire 182 34 Aaron 260 34 Chelsea 180 35 Stuart 257 35 Jade 176 36 Euan 252 36 Robyn 173 37 Steven 243 37 Jessica 160 38 Darren 231 38= Aimee 159 39 William 228 38= Gemma 159 40 Lee 226 38= Nicola 159 41= Aidan 207 41 Hayley 156 41= Stephen 207 42= Lisa 155 43 Nathan 205 42= Natalie 155 44 Shaun 198 44 Anna 151 45 Ben 195 45 Natasha 148 46 Joshua 191 46 Charlotte 134 47 Conor 176 47 Abbie 132 48 Ewan 174 -

ED311449.Pdf
DOCUMENT RESUME ED 311 449 CS 212 093 AUTHOR Baron, Dennis TITLE Declining Grammar--and Other Essays on the English Vocabulary. INSTITUTION National Council of Teachers of English, Urbana, Ill. REPORT NO ISBN-0-8141-1073-8 PUB DATE 89 NOTE :)31p. AVAILABLE FROM National Council of Teachers of English, 1111 Kenyon Rd., Urbana, IL 61801 (Stock No. 10738-3020; $9.95 member, $12.95 nonmember). PUB TYPE Books (010) -- Viewpoints (120) EDRS PRICE MF01/PC10 Plus Postage. DESCRIPTORS *English; Gr&mmar; Higher Education; *Language Attitudes; *Language Usage; *Lexicology; Linguistics; *Semantics; *Vocabulary IDENTIFIERS Words ABSTRACT This book contains 25 essays about English words, and how they are defined, valued, and discussed. The book is divided into four sections. The first section, "Language Lore," examines some of the myths and misconceptions that affect attitudes toward language--and towards English in particular. The second section, "Language Usage," examines some specific questions of meaning and usage. Section 3, "Language Trends," examines some controversial r trends in English vocabulary, and some developments too new to have received comment before. The fourth section, "Language Politics," treats several aspects of linguistic politics, from special attempts to deal with the ethnic, religious, or sex-specific elements of vocabulary to the broader issues of language both as a reflection of the public consciousness and the U.S. Constitution and as a refuge for the most private forms of expression. (MS) *********************************************************************** Reproductions supplied by EDRS are the best that can be made from the original document. *********************************************************************** "PERMISSION TO REPRODUCE THIS MATERIAL HAS BEEN GRANTED BY J. Maxwell TO THE EDUCATIONAL RESOURCES INFORMATION CENTER (ERIC)." U S. -

Economic Survey of Latin America and the Caribbean 2006-2007
Economic Survey of Latin America and the Caribbean • 2006-2007 1 2006-2007 Economic Survey of latin america and the caribbean 2 Economic Commission for Latin America and the Caribbean (ECLAC) The Economic Survey of Latin America and the Caribbean is issued annually by the Economic Development Division of the Economic Commission for Latin America and the Caribbean (ECLAC). This 2006-2007 edition was prepared under the supervision of Osvaldo Kacef, Officer-in-Charge of the Division; Jürgen Weller was responsible for its overall coordination. In the preparation of this edition, the Economic Development Division was assisted by the Statistics and Economic Projections Division, the Latin American and Caribbean Institute for Economic and Social Planning (ILPES), the Division of International Trade and Integration, the ECLAC subregional headquarters in Mexico City and Port of Spain and the country offices of the Commission in Bogotá, Brasilia, Buenos Aires and Montevideo. Chapter I, “Regional overview”, was prepared by Osvaldo Kacef with input from Omar Bello, Rodrigo Cárcamo, Filipa Correia, Juan Pablo Jiménez, Rafael López Monti, Sandra Manuelito, Andrew Mold and Jürgen Weller. The Economic Projections Centre of the Statistics and Economic Projections Division provided inputs on the outlook for economic growth in 2007 and 2008. Chapters II and III, “Investment, saving and growth in Latin America: Analytical and policy issues” and “Economic growth in Latin America and the Caribbean: Multiple growth transitions rather than steady states” are based on papers by Mario Gutiérrez, ECLAC consultant. Chapter IV, “Reflections of economic growth of Latin America and the Caribbean” was written by Omar Bello with the collaboration of Alejandra Acevedo and Filipa Correia. -

Scientific Workplace· • Mathematical Word Processing • LATEX Typesetting Scientific Word· • Computer Algebra
Scientific WorkPlace· • Mathematical Word Processing • LATEX Typesetting Scientific Word· • Computer Algebra (-l +lr,:znt:,-1 + 2r) ,..,_' '"""""Ke~r~UrN- r o~ r PooiliorK 1.931'J1 Po6'lf ·1.:1l26!.1 Pod:iDnZ 3.881()2 UfW'IICI(JI)( -2.801~ ""'"""U!NecteoZ l!l!iS'11 v~ 0.7815399 Animated plots ln spherical coordln1tes > To make an anlm.ted plot In spherical coordinates 1. Type an expression In thr.. variables . 2 WMh the Insertion poilt In the expression, choose Plot 3D The next exampfe shows a sphere that grows ftom radius 1 to .. Plot 3D Animated + Spherical The Gold Standard for Mathematical Publishing Scientific WorkPlace and Scientific Word Version 5.5 make writing, sharing, and doing mathematics easier. You compose and edit your documents directly on the screen, without having to think in a programming language. A click of a button allows you to typeset your documents in LAT£X. You choose to print with or without LATEX typesetting, or publish on the web. Scientific WorkPlace and Scientific Word enable both professionals and support staff to produce stunning books and articles. Also, the integrated computer algebra system in Scientific WorkPlace enables you to solve and plot equations, animate 20 and 30 plots, rotate, move, and fly through 3D plots, create 3D implicit plots, and more. MuPAD' Pro MuPAD Pro is an integrated and open mathematical problem solving environment for symbolic and numeric computing. Visit our website for details. cK.ichan SOFTWARE , I NC. Visit our website for free trial versions of all our products. www.mackichan.com/notices • Email: info@mac kichan.com • Toll free: 877-724-9673 It@\ A I M S \W ELEGRONIC EDITORIAL BOARD http://www.math.psu.edu/era/ Managing Editors: This electronic-only journal publishes research announcements (up to about 10 Keith Burns journal pages) of significant advances in all branches of mathematics. -

Kathleen Mckeown
Kathleen McKeown Department of Computer Science Columbia University New York, NY. 10027 U.S.A. Phone: 212-939-7118 Fax: 212-666-0140 email: [email protected] website: http://www.cs.columbia.edu/ kathy Current position Henry and Gertrude Rothschild Professor of Computer Science, Columbia University, New York Research Interests Computational Linguistics/Natural-Language Processing: Text Summarization; Language Genera- tion; Social Media Analysis; Open-ended question answering; Sentiment Analysis Education 1982 Ph.D., Computer and Information Science, University of Pennsylvania 1979 M.S., Computer and Information Science, University of Pennsylvania 1976 A.B., Comparative Literature, Brown University Appointments held 2012-2018 Founding Director, Columbia Data Science Institute 2011-2012 Vice Dean for Research, School of Engineering and Applied Science 2005-present Henry and Gertrude Rothschild Professor of Computer Science, Columbia University 1997-present Professor, Columbia University 7/2003-12/2003 Acting Chair, Department of Computer Science, Columbia University 1997-2002 Chair, Department of Computer Science, Columbia University 1987-1997 Associate Professor, Columbia University 1982-1987 Assistant Professor, Columbia University Honors & awards 2018 Keynote Speaker, ROCLING-18 speaker, Hsinchu, Taiwan. 2016 Keynote Speaker, International Semantic Web Conference, Kobe, Japan 20162014 Grace Hopper Distinguished Lecture, University of Pennsylvania Philadelphia, Pa., Nov. 2016. Distin- guished Lecturer, University of Edinburgh, Launch of the Centre for Doctoral Training in Data Science, Edinburgh, Scotland 2014 Keynote Speaker, 10th IEEE International Conference on eScience, Guaruja, Sao Paolo, Brazil, October 2013 Keynote Speaker, The 2013 Conference of the North American Association for Computational Linguistics K. McKeown 2 2012 Best paper award, Kristen Parton, Nizar Habash, Kathleen McKeown, Gonzalo Iglesias, and Adria de Gis- pert. -
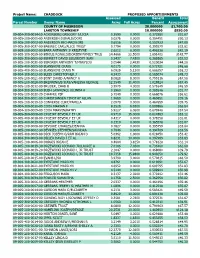
Project Name: CHADDOCK PROPOSED APPORTIONMENTS
Project Name: CHADDOCK PROPOSED APPORTIONMENTS Assessed Benefit Total Parcel Number Owner Name Acres Full Acres Percent Assessment COUNTY OF MUSKEGON 20.000000 $1,700.00 LAKETON TOWNSHIP 10.000000 $850.00 09-004-300-0014-10 ACKERBERG GREGORY J/LICIA 0.3590 0.0000 0.372580 $31.67 09-005-200-0005-00 ANDERSEN DONALD/DORI 0.0276 0.0000 0.354451 $30.13 09-005-200-0003-00 ANDERSON RICHARD/LORI 3.6556 0.0000 0.552923 $47.00 09-005-300-0037-00 BABINEC CARL/ALICE TRUST 0.7794 0.0000 0.395579 $33.62 09-005-200-0002-00 BARR ANTHONY J/ KRISTYNE 2.6212 6.0000 0.496336 $42.19 09-005-100-0029-00 BEKIUS RONALD/DOREEN FAMILY TRUS 24.4666 22.5000 1.691402 $143.77 09-005-300-0005-00 BENNETT DAVID LEE/BECKY JEAN 0.5437 7.4300 0.382685 $32.53 09-005-200-0030-00 BERGREN ANTHONY T/MARYLOU 3.0544 2.4930 0.520034 $44.20 09-005-400-0005-00 BLANSHINE CRAIG 4.0175 0.0000 0.572721 $48.68 09-005-400-0006-00 BLANSHINE CRAIG M 6.0929 5.1300 0.686257 $58.33 09-004-100-0023-00 BLISS CHRISTOPHER J 4.2433 0.0000 0.585074 $49.73 09-005-200-0021-00 BONT DAVID A/NANCY A 8.0828 8.0000 0.795116 $67.58 09-005-200-0028-00 BRENNING/B SIAS/VANESSA GEORGE 12.3549 11.4000 1.028824 $87.45 09-005-200-0012-00 BRUDER, CHAD B 3.9979 4.0000 0.571649 $48.59 09-004-300-0004-00 BUSH LAWRENCE 0/LINDA K 0.5960 0.0000 0.385546 $32.77 09-005-200-0030-20 CHAFFEE PSP 5.7240 0.0000 0.666076 $56.62 09-004-300-0001-00 CHRISTIANSEN TIMOTHY ALLAN 1.9689 0.0000 0.460651 $39.16 09-005-200-0019-10 CONVERSE CURT/PAMELA 2.0970 0.0000 0.467659 $39.75 09-004-100-0010-00 COOK MARIAN F 8.3528 8.9300 0.809886 $68.84 -

F I U 'S in Action
F I U ’s in action A compilation of 100 sanitised ca s es This edition is the product of on succes s es and learning moments contributions from Egmont Members: in the fight against money laundering Financial Intelligence Units 100 ca s es from the Egmont Group No rights may be derived from this publica t i o n . All names of natural persons and legal entities are fictitious and any similarities are purely coincidenta l . I N T R ODUCT I ON 2 I N T R ODUC T ION In 1999, the Egmont Training Working Group undertook an initiative to draw together a compilation of sanitised ca s es about the fight against money laundering undertaken by the Egmont Group member FIUs. The compilation was to reflect in part the Egmont Group’s fifth anniversary in 2000. We are pleased that almost every member FIU contributed at least one case. We would, therefore, like to thank all members for their co-operation. Without such e f f o r t s we w ou ld not hav e been ab l e to p rod uce th e compila ti on . For fi n a nc ia l a nd p rac ti c al r ea son s i t wa s not po s si b le to pu b li sh th is ed it io n as a b oo kl e t. Instead we choose a CD-ROM publication. The advantage of this format, however, is that you are free to copy the data for the benefit of your FIU. -

Chamaecyparis Nootkatensis
This file was created by scanning the printed publication Text errors identified by the software have been corrected; however, some errors may remain. Compilers P.E. HENNON is a research plant pathologist, Forestry Sciences Laboratory, Pacific Northwest Research Station and State and Private Forestry, USDA Forest Service, 2770 Sherwood Lane, Suite 2A, Juneau, AK 99801; A.S. HARRIS was a research silviculturist (now retired), 4400 Glacier Highway, Juneau, AK 99801. Annotated Bibliography of Chamaecyparis nootkatensis RE. Hennon A.S. Harris Compilers U S Department of Agriculture Forest Service Pacific Northwest Research Station Portland, Oregon General Technical Report PNW-GTR-413 September 1997 Abstract Hennon, P.E ; Harris, A.S., comps. 1997. Annotated bibliography of Chamaecypans nootkatensis Gen Tech Rep PNW-GTR-413 Portland, OR US Department of Agriculture, Forest Service, Pacific Northwest Research Station 112 p Some 680 citations from literature treating Chamaecypans nootkatensis are listed alphabetically by author in this bibliography Most citations are followed by a short summary A subject index is included Key words Yellow-cedar, Alaska-cedar, Alaska yellow-cedar, bibliography Foreword A considerable amount of material has been published on Chamaecypans nootkatensis (D Don) Spach in the 28 years since the 1969 printing of "Alaska-cedar, a bibliography with abstracts The current bibliography is a revision and expansion of the initial 1969 publication, now out of print The original 301 citations are included here with new ones -

The Carroll News
John Carroll University Carroll Collected The aC rroll News Student 9-12-1975 The aC rroll News- Vol. 58, No. 1 John Carroll University Follow this and additional works at: http://collected.jcu.edu/carrollnews Recommended Citation John Carroll University, "The aC rroll News- Vol. 58, No. 1" (1975). The Carroll News. 528. http://collected.jcu.edu/carrollnews/528 This Newspaper is brought to you for free and open access by the Student at Carroll Collected. It has been accepted for inclusion in The aC rroll News by an authorized administrator of Carroll Collected. For more information, please contact [email protected]. Students may now take advantage of an open swim swimming, beginning diving and aquatics. For the story period in the Johnson Swimming Pool, which opened last on the pool, the coach, and the open recreation swim week.. Accredited courses offered include introductory ~chedule, see Page 7. 3.2% Beer Permitted In Dorms By JANE KVACEK Birkenhauer approved the recom- . lounge or other public area of a Murph} head restdenr Chnstr mendation and put this new residence hall without specific lgnaut says. "studenu; should use Prohibition at John Carroll has pohcy on a one year trial basis. written authorizauon. No kegs the new poltcy to prove to the ad been repealed and 3.2• beer may Accord1ng to the Alcohol are permitted in the pnvatc mini)tration that they are mature be consumed within the confines Polley, "the Umvers1ty as a rooms of the' residence hall. enough to handle thmgs of which of a pnvate room or in the dor general pohcy does not encourage "Students must be held respon they are really capable."' mitory lounges with written students to consume beverages, sible for the1r pc!rsonal behavior. -

2020-2021 Acquisitions
2020-2021 Acquisitions 2020.1 Eleanor Antin (b. 1935, New York; lives in San Diego, California) Caught in the Act, 1973 Single-channel digital video, transferred from video tape (black-and-white, sound) Running time: 36min The Museum of Contemporary Art, Los Angeles Purchase with funds provided by the Acquisition and Collection Committee 2020.2 Ulysses Jenkins (b. 1946; Lives in Irvine, California) Dream City, 1983 Single-channel digital video transferred from video tape (color, sound) Running time: 5min, 23sec The Museum of Contemporary Art, Los Angeles Purchase with funds provided by the Acquisition and Collection Committee 2020.3 Ulysses Jenkins (b. 1946; Lives in Irvine, California) Remnants of the Watts Festival, 1972-73 Single-channel digital video transferred from video tape (black-and-white, sound) Running time: 60min The Museum of Contemporary Art, Los Angeles Purchase with funds provided by the Acquisition and Collection Committee 2020.4 Ulysses Jenkins (b. 1946; Lives in Irvine, California) Two-Zone Transfer, 1979 Single-channel digital video transferred from video tape (color, sound) Running time: 25min, 53sec The Museum of Contemporary Art, Los Angeles Purchase with funds provided by the Acquisition and Collection Committee 2020.5 Gordon Matta-Clark (b. 1943, New York; d. 1978, New York) Office Baroque, 1977-2005 Single- channel digital video transferred from 16 mm (black-and-white, color, sound) Running time: 44min The Museum of Contemporary Art, Los Angeles Purchase with funds provided by the Acquisition and Collection Committee 04/15/2021 Page 1 of 18 2020-2021 Acquisitions 2020.6 Carolee Schneemann (b. 1939, Fox Chase, Pennsylvania; d. -

A Guide to Names and Naming Practices
March 2006 AA GGUUIIDDEE TTOO NN AAMMEESS AANNDD NNAAMMIINNGG PPRRAACCTTIICCEESS This guide has been produced by the United Kingdom to aid with difficulties that are commonly encountered with names from around the globe. Interpol believes that member countries may find this guide useful when dealing with names from unfamiliar countries or regions. Interpol is keen to provide feedback to the authors and at the same time develop this guidance further for Interpol member countries to work towards standardisation for translation, data transmission and data entry. The General Secretariat encourages all member countries to take advantage of this document and provide feedback and, if necessary, updates or corrections in order to have the most up to date and accurate document possible. A GUIDE TO NAMES AND NAMING PRACTICES 1. Names are a valuable source of information. They can indicate gender, marital status, birthplace, nationality, ethnicity, religion, and position within a family or even within a society. However, naming practices vary enormously across the globe. The aim of this guide is to identify the knowledge that can be gained from names about their holders and to help overcome difficulties that are commonly encountered with names of foreign origin. 2. The sections of the guide are governed by nationality and/or ethnicity, depending on the influencing factor upon the naming practice, such as religion, language or geography. Inevitably, this guide is not exhaustive and any feedback or suggestions for additional sections will be welcomed. How to use this guide 4. Each section offers structured guidance on the following: a. typical components of a name: e.g.