Fortran Programming Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

KDE 2.0 Development, Which Is Directly Supported
23 8911 CH18 10/16/00 1:44 PM Page 401 The KDevelop IDE: The CHAPTER Integrated Development Environment for KDE by Ralf Nolden 18 IN THIS CHAPTER • General Issues 402 • Creating KDE 2.0 Applications 409 • Getting Started with the KDE 2.0 API 413 • The Classbrowser and Your Project 416 • The File Viewers—The Windows to Your Project Files 419 • The KDevelop Debugger 421 • KDevelop 2.0—A Preview 425 23 8911 CH18 10/16/00 1:44 PM Page 402 Developer Tools and Support 402 PART IV Although developing applications under UNIX systems can be a lot of fun, until now the pro- grammer was lacking a comfortable environment that takes away the usual standard activities that have to be done over and over in the process of programming. The KDevelop IDE closes this gap and makes it a joy to work within a complete, integrated development environment, combining the use of the GNU standard development tools such as the g++ compiler and the gdb debugger with the advantages of a GUI-based environment that automates all standard actions and allows the developer to concentrate on the work of writing software instead of managing command-line tools. It also offers direct and quick access to source files and docu- mentation. KDevelop primarily aims to provide the best means to rapidly set up and write KDE software; it also supports extended features such as GUI designing and translation in con- junction with other tools available especially for KDE development. The KDevelop IDE itself is published under the GNU Public License (GPL), like KDE, and is therefore publicly avail- able at no cost—including its source code—and it may be used both for free and for commer- cial development. -

Introduction to Programming in Fortran 77 for Students of Science and Engineering
Introduction to programming in Fortran 77 for students of Science and Engineering Roman GrÄoger University of Pennsylvania, Department of Materials Science and Engineering 3231 Walnut Street, O±ce #215, Philadelphia, PA 19104 Revision 1.2 (September 27, 2004) 1 Introduction Fortran (FORmula TRANslation) is a programming language designed speci¯cally for scientists and engineers. For the past 30 years Fortran has been used for such projects as the design of bridges and aeroplane structures, it is used for factory automation control, for storm drainage design, analysis of scienti¯c data and so on. Throughout the life of this language, groups of users have written libraries of useful standard Fortran programs. These programs can be borrowed and used by other people who wish to take advantage of the expertise and experience of the authors, in a similar way in which a book is borrowed from a library. Fortran belongs to a class of higher-level programming languages in which the programs are not written directly in the machine code but instead in an arti¯cal, human-readable language. This source code consists of algorithms built using a set of standard constructions, each consisting of a series of commands which de¯ne the elementary operations with your data. In other words, any algorithm is a cookbook which speci¯es input ingredients, operations with them and with other data and ¯nally returns one or more results, depending on the function of this algorithm. Any source code has to be compiled in order to obtain an executable code which can be run on your computer. -

A Beginner's Guide to Freebasic
A Beginner’s Guide to FreeBasic Richard D. Clark Ebben Feagan A Clark Productions / HMCsoft Book Copyright (c) Ebben Feagan and Richard Clark. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License". The source code was compiled under version .17b of the FreeBasic compiler and tested under Windows 2000 Professional and Ubuntu Linux 6.06. Later compiler versions may require changes to the source code to compile successfully and results may differ under different operating systems. All source code is released under version 2 of the Gnu Public License (http://www.gnu.org/copyleft/gpl.html). The source code is provided AS IS, WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. Microsoft Windows®, Visual Basic® and QuickBasic® are registered trademarks and are copyright © Microsoft Corporation. Ubuntu is a registered trademark of Canonical Limited. 2 To all the members of the FreeBasic community, especially the developers. 3 Acknowledgments Writing a book is difficult business, especially a book on programming. It is impossible to know how to do everything in a particular language, and everyone learns something from the programming community. I have learned a multitude of things from the FreeBasic community and I want to send my thanks to all of those who have taken the time to post answers and examples to questions. -

B-Prolog User's Manual
B-Prolog User's Manual (Version 8.1) Prolog, Agent, and Constraint Programming Neng-Fa Zhou Afany Software & CUNY & Kyutech Copyright c Afany Software, 1994-2014. Last updated February 23, 2014 Preface Welcome to B-Prolog, a versatile and efficient constraint logic programming (CLP) system. B-Prolog is being brought to you by Afany Software. The birth of CLP is a milestone in the history of programming languages. CLP combines two declarative programming paradigms: logic programming and constraint solving. The declarative nature has proven appealing in numerous ap- plications, including computer-aided design and verification, databases, software engineering, optimization, configuration, graphical user interfaces, and language processing. It greatly enhances the productivity of software development and soft- ware maintainability. In addition, because of the availability of efficient constraint- solving, memory management, and compilation techniques, CLP programs can be more efficient than their counterparts that are written in procedural languages. B-Prolog is a Prolog system with extensions for programming concurrency, constraints, and interactive graphics. The system is based on a significantly refined WAM [1], called TOAM Jr. [19] (a successor of TOAM [16]), which facilitates software emulation. In addition to a TOAM emulator with a garbage collector that is written in C, the system consists of a compiler and an interpreter that are written in Prolog, and a library of built-in predicates that are written in C and in Prolog. B-Prolog does not only accept standard-form Prolog programs, but also accepts matching clauses, in which the determinacy and input/output unifications are explicitly denoted. Matching clauses are compiled into more compact and faster code than standard-form clauses. -

Software Process Validation: Quantitatively Measuring the Correspondence of a Process to a Model
Software Process Validation: Quantitatively Measuring the Correspondence of a Process to a Model JONATHAN E. COOK New Mexico State University and ALEXANDER L. WOLF University of Colorado To a great extent, the usefulness of a formal model of a software process lies in its ability to accurately predict the behavior of the executing process. Similarly, the usefulness of an executing process lies largely in its ability to fulfill the requirements embodied in a formal model of the process. When process models and process executions diverge, something significant is happening. We have developed techniques for uncovering and measuring the discrepancies between models and executions, which we call process validation. Process validation takes a process execution and a process model, and measures the level of correspon- dence between the two. Our metrics are tailorable and give process engineers control over determining the severity of different types of discrepancies. The techniques provide detailed information once a high-level measurement indicates the presence of a problem. We have applied our process validation methods in an industrial case study, of which a portion is described in this article. Categories and Subject Descriptors: D.2.6 [Software Engineering]: Programming Environ- ments; K.6.3 [Management of Computing and Information Systems]: Software Manage- ment—software development; software maintenance General Terms: Management Additional Key Words and Phrases: Balboa, process validation, software process, tools This work was supported in part by the National Science Foundation under grants CCR-93- 02739 and CCR-9804067, and the Air Force Materiel Command, Rome Laboratory, and the Defense Advanced Research Projects Agency under Contract Number F30602-94-C-0253. -

Oracle® Developer Studio 12.5
® Oracle Developer Studio 12.5: C User's Guide Part No: E60745 June 2017 Oracle Developer Studio 12.5: C User's Guide Part No: E60745 Copyright © 2016, 2017, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -
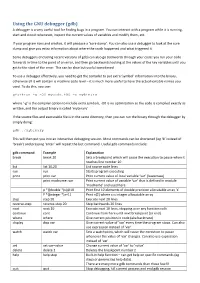
Using the GNU Debugger (Gdb) a Debugger Is a Very Useful Tool for Finding Bugs in a Program
Using the GNU debugger (gdb) A debugger is a very useful tool for finding bugs in a program. You can interact with a program while it is running, start and stop it whenever, inspect the current values of variables and modify them, etc. If your program runs and crashes, it will produce a ‘core dump’. You can also use a debugger to look at the core dump and give you extra information about where the crash happened and what triggered it. Some debuggers (including recent versions of gdb) can also go backwards through your code: you run your code forwards in time to the point of an error, and then go backwards looking at the values of the key variables until you get to the start of the error. This can be slow but useful sometimes! To use a debugger effectively, you need to get the compiler to put extra ‘symbol’ information into the binary, otherwise all it will contain is machine code level – it is much more useful to have the actual variable names you used. To do this, you use: gfortran –g –O0 mycode.f90 –o mybinary where ‘-g’ is the compiler option to include extra symbols, -O0 is no optimization so the code is compiled exactly as written, and the output binary is called ’mybinary’. If the source files and executable file is in the same directory, then you can run the binary through the debugger by simply doing: gdb ./mybinary This will then put you into an interactive debugging session. Most commands can be shortened (eg ‘b’ instead of ‘break’) and pressing ‘enter’ will repeat the last command. -

BUGS Code for Item Response Theory
JSS Journal of Statistical Software August 2010, Volume 36, Code Snippet 1. http://www.jstatsoft.org/ BUGS Code for Item Response Theory S. McKay Curtis University of Washington Abstract I present BUGS code to fit common models from item response theory (IRT), such as the two parameter logistic model, three parameter logisitic model, graded response model, generalized partial credit model, testlet model, and generalized testlet models. I demonstrate how the code in this article can easily be extended to fit more complicated IRT models, when the data at hand require a more sophisticated approach. Specifically, I describe modifications to the BUGS code that accommodate longitudinal item response data. Keywords: education, psychometrics, latent variable model, measurement model, Bayesian inference, Markov chain Monte Carlo, longitudinal data. 1. Introduction In this paper, I present BUGS (Gilks, Thomas, and Spiegelhalter 1994) code to fit several models from item response theory (IRT). Several different software packages are available for fitting IRT models. These programs include packages from Scientific Software International (du Toit 2003), such as PARSCALE (Muraki and Bock 2005), BILOG-MG (Zimowski, Mu- raki, Mislevy, and Bock 2005), MULTILOG (Thissen, Chen, and Bock 2003), and TESTFACT (Wood, Wilson, Gibbons, Schilling, Muraki, and Bock 2003). The Comprehensive R Archive Network (CRAN) task view \Psychometric Models and Methods" (Mair and Hatzinger 2010) contains a description of many different R packages that can be used to fit IRT models in the R computing environment (R Development Core Team 2010). Among these R packages are ltm (Rizopoulos 2006) and gpcm (Johnson 2007), which contain several functions to fit IRT models using marginal maximum likelihood methods, and eRm (Mair and Hatzinger 2007), which contains functions to fit several variations of the Rasch model (Fischer and Molenaar 1995). -

Cobol Vs Standards and Conventions
Number: 11.10 COBOL VS STANDARDS AND CONVENTIONS July 2005 Number: 11.10 Effective: 07/01/05 TABLE OF CONTENTS 1 INTRODUCTION .................................................................................................................................................. 1 1.1 PURPOSE .................................................................................................................................................. 1 1.2 SCOPE ...................................................................................................................................................... 1 1.3 APPLICABILITY ........................................................................................................................................... 2 1.4 MAINFRAME COMPUTER PROCESSING ....................................................................................................... 2 1.5 MAINFRAME PRODUCTION JOB MANAGEMENT ............................................................................................ 2 1.6 COMMENTS AND SUGGESTIONS ................................................................................................................. 3 2 COBOL DESIGN STANDARDS .......................................................................................................................... 3 2.1 IDENTIFICATION DIVISION .................................................................................................................. 4 2.1.1 PROGRAM-ID .......................................................................................................................... -

AN125: Integrating Raisonance 8051 Tools Into The
AN125 INTEGRATING RAISONANCE 8051 TOOLS INTO THE SILICON LABS IDE 1. Introduction 4. Configure the Tool Chain This application note describes how to integrate the Integration Dialog Raisonance 8051 Tools into the Silicon Laboratories Under the 'Project' menu, select 'Tool Chain Integration’ IDE (Integrated Development Environment). Integration to bring up the dialog box shown below. Raisonance provides an efficient development environment with (Ride 7) is the default. To use Raisonance (Ride 6), you compose, edit, build, download and debug operations can select it from the 'Preset Name' drop down box integrated in the same program. under 'Tools Definition Presets'. Next, define the Raisonance assembler, compiler, and linker as shown in 2. Key Points the following sections. The Intel OMF-51 absolute object file generated by the Raisonance 8051 tools enables source-level debug from the Silicon Labs IDE. Once Raisonance Tools are integrated into the IDE they are called by simply pressing the ‘Assemble/ Compile Current File’ button or the ‘Build/Make Project’ button. See the “..\Silabs\MCU\Examples” directory for examples that can be used with the Raisonance tools. Information in this application note applies to Version 4.00 and later of the Silicon Labs IDE and Ride7 and later of the Raisonance 8051 tools. 4.1. Assembler Definition 1. Under the ‘Assembler’ tab, if the assembler 3. Create a Project in the Silicon executable is not already defined, click the browse Labs IDE button next to the ‘Executable:’ text box, and locate the assembler executable. The default location for A project is necessary in order to link assembly files the Raisonance assembler is: created by the compiler and build an absolute ‘OMF-51’ C:\Program Files\Raisonance\Ride7\bin\ma51.exe output file. -

Fortran Reference Guide
FORTRAN REFERENCE GUIDE Version 2018 TABLE OF CONTENTS Preface............................................................................................................ xv Audience Description......................................................................................... xv Compatibility and Conformance to Standards............................................................ xv Organization................................................................................................... xvi Hardware and Software Constraints...................................................................... xvii Conventions................................................................................................... xvii Related Publications........................................................................................ xviii Chapter 1. Language Overview............................................................................... 1 1.1. Elements of a Fortran Program Unit.................................................................. 1 1.1.1. Fortran Statements................................................................................. 1 1.1.2. Free and Fixed Source............................................................................. 2 1.1.3. Statement Ordering................................................................................. 2 1.2. The Fortran Character Set.............................................................................. 3 1.3. Free Form Formatting.................................................................................. -

SPSS to Orthosim File Conversion Utility Helpfile V.1.4
SPSS to Orthosim File Conversion Utility Helpfile v.1.4 Paul Barrett Advanced Projects R&D Ltd. Auckland New Zealand email: [email protected] Web: www.pbarrett.net 30th December, 2019 Contents 3 Table of Contents Part I Introduction 5 1 Installation Details ................................................................................................................................... 7 2 Extracting Matrices from SPSS - Cut and Paste ................................................................................................................................... 8 3 Extracting Matrices from SPSS: Orthogonal Factors - E.x..c..e..l. .E..x..p..o..r.t................................................................................................................. 17 4 Extracting Matrices from SPSS: Oblique Factors - Exce.l. .E..x..p..o..r..t...................................................................................................................... 24 5 Creating Orthogonal Factor Orthosim Files ................................................................................................................................... 32 6 Creating Oblique Factor Orthosim Files ................................................................................................................................... 41 3 Paul Barrett Part I 6 SPSS to Orthosim File Conversion Utility Helpfile v.1.4 1 Introduction SPSS-to-Orthosim converts SPSS 11/12/13/14 factor loading and factor correlation matrices into the fixed-format .vf (simple ASCII text) files