3D Dynamic Scene Graphs: Actionable Spatial Perception with Places, Objects, and Humans
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Opengl Shaders and Programming Models That Provide Object Persistence
OpenGL shaders and programming models that provide object persistence COSC342 Lecture 22 19 May 2016 OpenGL shaders É We discussed forms of local illumination in the ray tracing lectures. É We also saw that there were reasons you might want to modify these: e.g. procedural textures for bump maps. É Ideally the illumination calculations would be entirely programmable. É OpenGL shaders facilitate high performance programmability. É They have been available as extensions since OpenGL 1.5 (2003), but core within OpenGL 2.0 (2004). É We will focus on vertex and fragment shaders, but there are other types: e.g. geometry shaders, and more recent shaders for tessellation and general computing. COSC342 OpenGL shaders and programming models that provide object persistence 2 GL Shading Language|GLSL É C-like syntax. (No surprises given the OpenGL lineage . ) É However, compared to `real' use of C, GLSL programmers are further away from the actual hardware. É Usually the GLSL code will be passed as a string into the OpenGL library you are using. É Only supports limited number of data types: e.g. float, double,... É Adds some special types of its own: e.g. vector types vec2, vec4. É Unlike most software, GLSL is typically compiled every time you load your functions|there isn't (yet...) a standardised GL machine code. COSC342 OpenGL shaders and programming models that provide object persistence 3 GLSL on the hardware É The GLSL syntax just provides a standard way to specify functions. É Different vendors may use vastly different hardware implementations. É (Or indeed the CPU may be doing the GLSL work, e.g. -

Lecture 08: Hierarchical Modeling with Scene Graphs
Lecture 08: Hierarchical Modeling with Scene Graphs CSE 40166 Computer Graphics Peter Bui University of Notre Dame, IN, USA November 2, 2010 Symbols and Instances Objects as Symbols Model world as a collection of object symbols. Instance Transformation Place instances of each symbol in model using M = TRS. 1 glTranslatef (dx, dy, dz); 2 g l R o t a t e f (angle, rx, ry, rz); 3 g l S c a l e f (sx, sy, sz); 4 gluCylinder (quadric, base, top, height, slices, stacks); Problem: No Relationship Among Objects Symbols and instances modeling technique contains no information about relationships among objects. I Cannot separate movement of Wall-E from individual parts. I Hard to take advantage of the re-usable objects. Solution: Use Graph to Model Objects Represent the visual and abstract relationships among the parts of the models with a graph. I Graph consists of a set of nodes and a set of edges. I In directed graph, edges have a particular direction. Example: Robot Arm 1 display () 2 { 3 g l R o t a t e f (theta, 0.0, 1.0, 0.0); 4 base (); 5 glTranslatef (0.0, h1, 0.0); 6 g l R o t a t e f (phi, 0.0, 0.0, 1.0); 7 lower_arm(); 8 glTranslatef (0.0, h2, 0.0); 9 g l R o t a t e f (psi, 0.0, 0.0, 1.0); 10 upper_arm(); 11 } Example: Robot Arm (Graph) 1 ConstructRobotArm(Root) 2 { 3 Create Base; 4 Create LowerArm; 5 Create UpperArm; 6 7 Connect Base to Root; 8 Connect LowerArm to Base; 9 Connect UpperArm to LowerArm; 10 } 11 12 RenderNode(Node) 13 { 14 Store Environment; 15 16 Node.Render(); 17 18 For Each child in Node.children: 19 RenderNode(child); 20 21 Restore Environment; 22 } Scene Graph: Node Node in a scene graph requires the following components: I Render: A pointer to a function that draws the object represented by the node. -

Using Graph-Based Data Structures to Organize and Manage Scene
d07wals.x.g2db Page 1 of 7 Thursday, April 4, 2002 8:47:50 AM HEAD: Understanding Scene Graphs DEK Using graph-based Bio data structures to Aaron is chairman of Mantis Development, and teaches computer graphics and In- organize and manage ternet/Web application development at Boston College. He can be contacted at scene contents [email protected]. Byline NOTE TO AUTHORS: PLEASE CHECK ALL URLs AND SPELLINGS OF NAMES CAREFULLY. Aaron E. Walsh THANK YOU. Pullquotes Before scene-graph programming Scene-graph models, we usually nodes represent represented scene objects in a scene data and behavior procedurally d07wals.x.g2db Page 2 of 7 Thursday, April 4, 2002 8:47:50 AM 2.1 cene graphs are data structures used 2.68 At the scene level, you concern your- – to organize and manage the contents – self with what’s in the scene and any as- – of hierarchically oriented scene data. – sociated behavior or interaction among – Traditionally considered a high-level – objects therein. Underlying implementa- 2.5 S – data management facility for 3D content, tion and rendering details are abstracted – scene graphs are becoming popular as – out of the scene-graph programming mod- – general-purpose mechanisms for manag- – el. In this case, you can assume that your – ing a variety of media types. MPEG-4, for 2.75 VRML browser plug-in handles low-level – instance, uses the Virtual Reality Model- – concerns. 2.10 ing Language (VRML) scene-graph pro- – – gramming model for multimedia scene – Nodes and Arcs – composition, regardless of whether 3D – As Figure 2 depicts, scene graphs consist – data is part of such content. -
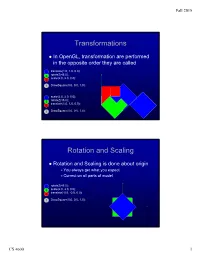
Transformations Rotation and Scaling
Fall 2015 Transformations In OpenGL, transformation are performed in the opposite order they are called 4 translate(1.0, 1.0, 0.0); 3 rotateZ(45.0); 2 scale(2.0, 2.0, 0.0); 1 DrawSquare(0.0, 0.0, 1.0); 4 scale(2.0, 2.0, 0.0); 3 rotateZ(45.0); translate(1.0, 1.0, 0.0); 2 1 DrawSquare(0.0, 0.0, 1.0); Rotation and Scaling Rotation and Scaling is done about origin You always get what you expect Correct on all parts of model 4 rotateZ(45.0); 3 scale(2.0, 2.0, 0.0); 2 translate(-0.5, -0.5, 0.0); 1 DrawSquare(0.0, 0.0, 1.0); CS 4600 1 Fall 2015 Load and Mult Matrices in MV.js Mat4(m) Mat4(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16) Sets the sixteen values of the current matrix to those specified by m. CTM = mult(CTM, xformMatrix); Multiplies the matrix,CTM, by xformMatrix and stores the result as the current matrix, CTM. OpenGL uses column instead of row vectors However, MV.js treats things in row-major order Flatten does the transpose Matrices are defined like this (use float m[16]); CS 4600 2 Fall 2015 Object Coordinate System Used to place objects in scene Draw at origin of WCS Scale and Rotate Translate to final position Use the MODELVIEW matrix as the CTM scale(x, y, z) rotate[XYZ](angle) translate(x, y, z) lookAt(eyeX, eyeY, eyeZ, atX, atY, atZ, upX, upY, upZ) lookAt LookAt(eye, at, up) Angel and Shreiner: Interactive Computer Graphics 7E © Addison-Wesley 2015 CS 4600 3 Fall 2015 The lookAt Function The GLU library contained the function gluLookAt to form the required modelview matrix through a simple interface Note -

Computation of Potentially Visible Set for Occluded Three-Dimensional Environments
Computation of Potentially Visible Set for Occluded Three-Dimensional Environments Derek Carr Advisor: Prof. William Ames Boston College Computer Science Department May 2004 Page 1 Abstract This thesis deals with the problem of visibility culling in interactive three- dimensional environments. Included in this thesis is a discussion surrounding the issues involved in both constructing and rendering three-dimensional environments. A renderer must sort the objects in a three-dimensional scene in order to draw the scene correctly. The Binary Space Partitioning (BSP) algorithm can sort objects in three- dimensional space using a tree based data structure. This thesis introduces the BSP algorithm in its original context before discussing its other uses in three-dimensional rendering algorithms. Constructive Solid Geometry (CSG) is an efficient interactive modeling technique that enables an artist to create complex three-dimensional environments by performing Boolean set operations on convex volumes. After providing a general overview of CSG, this thesis describes an efficient algorithm for computing CSG exp ression trees via the use of a BSP tree. When rendering a three-dimensional environment, only a subset of objects in the environment is visible to the user. We refer to this subset of objects as the Potentially Visible Set (PVS). This thesis presents an algorithm that divides an environment into a network of convex cellular volumes connected by invisible portal regions. A renderer can then utilize this network of cells and portals to compute a PVS via a depth first traversal of the scene graph in real-time. Finally, this thesis discusses how a simulation engine might exploit this data structure to provide dynamic collision detection against the scene graph. -

Open Scene Graph ODE - Open Dynamics Engine
Universidade do Vale do Rio dos Sinos Virtual Reality Tools OSG - Open Scene Graph ODE - Open Dynamics Engine M.Sc . Milton Roberto Heinen - Unisinos / UFRGS E-mail: [email protected] Dr. Fernando S. Osório - Unisinos E-mail: [email protected] Artificial Intelligence Group - GIA Virtual Reality Tools OSG (Open Scene Graph) + ODE (Open Dynamics Engine) Open Scene Graph Programa de Pós-Graduação em Computação Aplicada PIPCA Grupo de Inteligência Artificial - GIA 1 Virtual Reality Tools OSG (Open Scene Graph) + ODE (Open Dynamics Engine) Open Scene Graph - OSG http://www.openscenegraph.org/ • OSG: Open and Free Software Object Oriented (C++) Software Library (API) • The OSG Library is an abstraction layer over the OpenGL, allowing to easily create complex visual scenes • With OSG you do not need to use other APIs like MFC, GTK or Glut (windows and device libs) • With OSG you can read/show several 3D file formats as for example VRML, OBJ, DirectX (.X), OSG using textures, lights, particles and other visual effects • OSG works in Windows and Linux Environments creating portable graphical applications Programa de Pós-Graduação em Computação Aplicada PIPCA Grupo de Inteligência Artificial - GIA Virtual Reality Tools OSG (Open Scene Graph) + ODE (Open Dynamics Engine) OSG – Primitive Objects Programa de Pós-Graduação em Computação Aplicada PIPCA Grupo de Inteligência Artificial - GIA 2 Virtual Reality Tools OSG (Open Scene Graph) + ODE (Open Dynamics Engine) OSG – Textures Programa de Pós-Graduação em Computação Aplicada PIPCA Grupo de Inteligência -

Hierarchical Modeling and Scene Graphs
Hierarchical Modeling and Scene Graphs Adapted from material prepared by Ed Angel University of Texas at Austin CS354 - Computer Graphics Spring 2009 Don Fussell Objectives Examine the limitations of linear modeling Symbols and instances Introduce hierarchical models Articulated models Robots Introduce Tree and DAG models Examine various traversal strategies Generalize the notion of objects to include lights, cameras, attributes Introduce scene graphs University of Texas at Austin CS354 - Computer Graphics Don Fussell Instance Transformation Start with a prototype object (a symbol) Each appearance of the object in the model is an instance Must scale, orient, position Defines instance transformation University of Texas at Austin CS354 - Computer Graphics Don Fussell Relationships in Car Model Symbol-instance table does not show relationships between parts of model Consider model of car Chassis + 4 identical wheels Two symbols Rate of forward motion determined by rotational speed of wheels University of Texas at Austin CS354 - Computer Graphics Don Fussell Structure Through Function Calls car(speed){ chassis() wheel(right_front); wheel(left_front); wheel(right_rear); wheel(left_rear); } • Fails to show relationships well • Look at problem using a graph University of Texas at Austin CS354 - Computer Graphics Don Fussell Graphs Set of nodes and edges (links) Edge connects a pair of nodes Directed or undirected Cycle: directed path that is a loop loop University of Texas at Austin CS354 - Computer Graphics Don Fussell Tree Graph in which each -

Chapter 5 - the Scene Graph
Chapter 5 - The Scene Graph • Why a scene graph? • What is stored in the scene graph? – objects – appearance – camera – lights • Rendering with a scene graph • Practical example LMU München – Medieninformatik – Andreas Butz – Computergrafik 1 – SS2015 – Kapitel 5 1 The 3D Rendering Pipeline (our version for this class) 3D models in 3D models in world 2D Polygons in Pixels in image model coordinates coordinates camera coordinates coordinates Scene graph Camera Rasterization Animation, Lights Interaction LMU München – Medieninformatik – Andreas Butz – Computergrafik 1 – SS2015 – Kapitel 5 2 Why a Scene Graph? • Naive approach: – for each object in the scene, set its transformation by a single matrix (i.e., a tree 1 level deep and N nodes wide) • advantage: very fast for rendering • disadvantage: if several objects move, all of their transforms change • Observation: Things in the world are made from parts • Approach: define an object hierarchy along the part-of relation – transform all parts only relative to the whole group – transform group as a whole with another transform – parts can be groups again http://www.bosy-online.de/Veritherm/Explosionszeichnung.jpg LMU München – Medieninformatik – Andreas Butz – Computergrafik 1 – SS2015 – Kapitel 5 3 Chapter 5 - The Scene Graph • Why a scene graph? • What is stored in the scene graph? – objects – appearance – camera – lights • Rendering with a scene graph • Practical example LMU München – Medieninformatik – Andreas Butz – Computergrafik 1 – SS2015 – Kapitel 5 4 Geometry in the Scene Graph • -

Graphical Objects and Scene Graphs
Graphical Objects and Scene Graphs Ed Angel Professor of Computer Science, Electrical and Computer Engineering, and Media Arts University of New Mexico Objectives • Introduce graphical objects • Generalize the notion of objects to include lights, cameras, attributes • Introduce scene graphs Angel: Interactive Computer Graphics 3E © Addison-Wesley 2002 2 Limitations of Immediate Mode Graphics • When we define a geometric object in an application, upon execution of the code the object is passed through the pipeline • It then disappears from the graphical system • To redraw the object, either changed or the same, we must reexecute the code • Display lists provide only a partial solution to this problem Angel: Interactive Computer Graphics 3E © Addison-Wesley 2002 3 OpenGL and Objects • OpenGL lacks an object orientation • Consider, for example, a green sphere - We can model the sphere with polygons or use OpenGL quadrics - Its color is determined by the OpenGL state and is not a property of the object • Defies our notion of a physical object • We can try to build better objects in code using object-oriented languages/techniques Angel: Interactive Computer Graphics 3E © Addison-Wesley 2002 4 Imperative Programming Model • Example: rotate a cube cube data Application glRotate results • The rotation function must know how the cube is represented - Vertex list - Edge list Angel: Interactive Computer Graphics 3E © Addison-Wesley 2002 5 Object-Oriented Programming Model • In this model, the representation is stored with the object Application Cube -

X3D Ontology for Semantic Web
X3D Ontology for Semantic Web X3D Semantic Web Working Group Don Brutzman and Jakub Flotyński [email protected] [email protected] 29 July 2020 Semantic Web • W3C is helping to build a technology stack to support a “Web of data” supported by Semantic Web standards. • Wikipedia: “The Semantic Web is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable. To enable the encoding of semantics with the data, technologies such as Resource Description Framework (RDF) and Web Ontology Language (OWL) are used. These technologies are used to formally represent metadata. For example, ontology can describe concepts, relationships between entities, and categories of things. These embedded semantics offer significant advantages such as reasoning over data and operating with heterogeneous data sources.” X3D Semantic Web Working Group 1 • The X3D Semantic Web Working Group mission is to publish models to the Web using X3D in order to best gain Web interoperability and enable intelligent 3D applications, feature-based 3D model querying, and reasoning over 3D scenes. Motivations • Establish best practices for metadata and semantic information/relationships using X3D as a Web-based presentation layer. • Enable authors to utilize the power of X3Dv4 and HTML5/DOM together in any Web page utilizing a family of specifications and practices provided by the Semantic Web, such as HTML5 Microdata (microformats) and Linked Open Data, MPEG-7 and related references. • Align the X3Dv4 specification with these standards as best possible to further enable the Digital Publishing industry and communities. -
Binary Space Partioning Trees and Polygon Removal in Real Time 3D Rendering Samuel Ranta-Eskola
Uppsala Master's Theses in Computing Science Examensarbete 179 2001-01-19 ISSN 1100-1836 Binary Space Partioning Trees and Polygon Removal in Real Time 3D Rendering Samuel Ranta-Eskola Information Technology Computing Science Department Uppsala University Box 311 S-751 05 Uppsala Sweden Supervisor: Erik Olofsson Examiner: Passed: BSP-TREES AND POLYGON REMOVAL IN REAL TIME 3D RENDERING By Samuel Ranta-Eskola Uppsala University Abstract When the original design of the algorithm for Binary Space Partitioning (BSP)-trees was formulated the idea was to use it to sort the polygons in the world. The reason for this was there did not exist hardware accelerated Z- buffers, and software Z-buffering was too slow. Today that area of usage is obsolete, since hardware accelerated Z-buffers exist. Instead the usage is to optimise a wide variety of areas, such as radiosity calculations, drawing of the world, collision detection and networking. We set out to examine the areas where one can draw advantages of the structure supplied and study the generating process. As conclusion a BSP-tree is a very useful structure in most game engines. Although there are some drawbacks with it, such as that it is static and it is very expensive to modify during run-time. Hopefully some ideas can be taken from the BSP-tree algorithm to develop a more dynamic structure that has the same advantages as the BSP-tree. TABLE OF CONTENTS Number Page 1. Introduction ......................................................................................................1 · Background..............................................................................................1 -
Massive Model Visualization: an Investigation Into Spatial Partitioning Jeremy S
Iowa State University Capstones, Theses and Graduate Theses and Dissertations Dissertations 2009 Massive model visualization: An investigation into spatial partitioning Jeremy S. Bennett Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/etd Part of the Mechanical Engineering Commons Recommended Citation Bennett, Jeremy S., "Massive model visualization: An investigation into spatial partitioning" (2009). Graduate Theses and Dissertations. 10546. https://lib.dr.iastate.edu/etd/10546 This Thesis is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Graduate Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. Massive model visualization: An investigation into spatial hierarchies by Jeremy Scott Bennett A thesis submitted to the graduate faculty in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE Major: Human Computer Interaction Program of Study Committee: James Oliver (Major Professor) Yan-Bin Jia Eliot Winer Iowa State University Ames, Iowa 2009 Copyright © Jeremy Scott Bennett 2009. All rights reserved. ii TABLE OF CONTENTS LIST OF FIGURES IV LIST OF TABLES V ABSTRACT VI 1 INTRODUCTION 1 1.1 Product Lifecycle Management 1 1.2 Visualization Software 2 1.3 Motivation 3 1.4 Thesis Organization 4 2 BACKGROUND 5 2.1 Graphics Techniques 5 2.1.1