Memoization of Top-Down Parsing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Design and Evaluation of an Auto-Memoization Processor
DESIGN AND EVALUATION OF AN AUTO-MEMOIZATION PROCESSOR Tomoaki TSUMURA Ikuma SUZUKI Yasuki IKEUCHI Nagoya Inst. of Tech. Toyohashi Univ. of Tech. Toyohashi Univ. of Tech. Gokiso, Showa, Nagoya, Japan 1-1 Hibarigaoka, Tempaku, 1-1 Hibarigaoka, Tempaku, [email protected] Toyohashi, Aichi, Japan Toyohashi, Aichi, Japan [email protected] [email protected] Hiroshi MATSUO Hiroshi NAKASHIMA Yasuhiko NAKASHIMA Nagoya Inst. of Tech. Academic Center for Grad. School of Info. Sci. Gokiso, Showa, Nagoya, Japan Computing and Media Studies Nara Inst. of Sci. and Tech. [email protected] Kyoto Univ. 8916-5 Takayama Yoshida, Sakyo, Kyoto, Japan Ikoma, Nara, Japan [email protected] [email protected] ABSTRACT for microprocessors, and it made microprocessors faster. But now, the interconnect delay is going major and the This paper describes the design and evaluation of main memory and other storage units are going relatively an auto-memoization processor. The major point of this slower. In near future, high clock rate cannot achieve good proposal is to detect the multilevel functions and loops microprocessor performance by itself. with no additional instructions controlled by the compiler. Speedup techniques based on ILP (Instruction-Level This general purpose processor detects the functions and Parallelism), such as superscalar or SIMD, have been loops, and memoizes them automatically and dynamically. counted on. However, the effect of these techniques has Hence, any load modules and binary programs can gain proved to be limited. One reason is that many programs speedup without recompilation or rewriting. have little distinct parallelism, and it is pretty difficult for We also propose a parallel execution by multiple compilers to come across latent parallelism. -
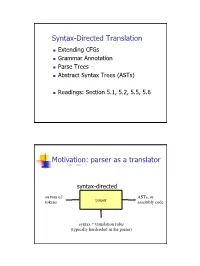
Syntax-Directed Translation, Parse Trees, Abstract Syntax Trees
Syntax-Directed Translation Extending CFGs Grammar Annotation Parse Trees Abstract Syntax Trees (ASTs) Readings: Section 5.1, 5.2, 5.5, 5.6 Motivation: parser as a translator syntax-directed translation stream of ASTs, or tokens parser assembly code syntax + translation rules (typically hardcoded in the parser) 1 Mechanism of syntax-directed translation syntax-directed translation is done by extending the CFG a translation rule is defined for each production given X Æ d A B c the translation of X is defined in terms of translation of nonterminals A, B values of attributes of terminals d, c constants To translate an input string: 1. Build the parse tree. 2. Working bottom-up • Use the translation rules to compute the translation of each nonterminal in the tree Result: the translation of the string is the translation of the parse tree's root nonterminal Why bottom up? a nonterminal's value may depend on the value of the symbols on the right-hand side, so translate a non-terminal node only after children translations are available 2 Example 1: arith expr to its value Syntax-directed translation: the CFG translation rules E Æ E + T E1.trans = E2.trans + T.trans E Æ T E.trans = T.trans T Æ T * F T1.trans = T2.trans * F.trans T Æ F T.trans = F.trans F Æ int F.trans = int.value F Æ ( E ) F.trans = E.trans Example 1 (cont) E (18) Input: 2 * (4 + 5) T (18) T (2) * F (9) F (2) ( E (9) ) int (2) E (4) * T (5) Annotated Parse Tree T (4) F (5) F (4) int (5) int (4) 3 Example 2: Compute type of expr E -> E + E if ((E2.trans == INT) and (E3.trans == INT) then E1.trans = INT else E1.trans = ERROR E -> E and E if ((E2.trans == BOOL) and (E3.trans == BOOL) then E1.trans = BOOL else E1.trans = ERROR E -> E == E if ((E2.trans == E3.trans) and (E2.trans != ERROR)) then E1.trans = BOOL else E1.trans = ERROR E -> true E.trans = BOOL E -> false E.trans = BOOL E -> int E.trans = INT E -> ( E ) E1.trans = E2.trans Example 2 (cont) Input: (2 + 2) == 4 1. -

Journal of Computer Science and Engineering Parsing
IJRDO - Journal of Computer Science and Engineering ISSN: 2456-1843 JOURNAL OF COMPUTER SCIENCE AND ENGINEERING PARSING TECHNIQUES Ojesvi Bhardwaj Abstract: ‘Parsing’ is the term used to describe the process of automatically building syntactic analyses of a sentence in terms of a given grammar and lexicon. The resulting syntactic analyses may be used as input to a process of semantic interpretation, (or perhaps phonological interpretation, where aspects of this, like prosody, are sensitive to syntactic structure). Occasionally, ‘parsing’ is also used to include both syntactic and semantic analysis. We use it in the more conservative sense here, however. In most contemporary grammatical formalisms, the output of parsing is something logically equivalent to a tree, displaying dominance and precedence relations between constituents of a sentence, perhaps with further annotations in the form of attribute-value equations (‘features’) capturing other aspects of linguistic description. However, there are many different possible linguistic formalisms, and many ways of representing each of them, and hence many different ways of representing the results of parsing. We shall assume here a simple tree representation, and an underlying context-free grammatical (CFG) formalism. *Student, CSE, Dronachraya Collage of Engineering, Gurgaon Volume-1 | Issue-12 | December, 2015 | Paper-3 29 - IJRDO - Journal of Computer Science and Engineering ISSN: 2456-1843 1. INTRODUCTION Parsing or syntactic analysis is the process of analyzing a string of symbols, either in natural language or in computer languages, according to the rules of a formal grammar. The term parsing comes from Latin pars (ōrātiōnis), meaning part (of speech). The term has slightly different meanings in different branches of linguistics and computer science. -

Parallel Backtracking with Answer Memoing for Independent And-Parallelism∗
Under consideration for publication in Theory and Practice of Logic Programming 1 Parallel Backtracking with Answer Memoing for Independent And-Parallelism∗ Pablo Chico de Guzman,´ 1 Amadeo Casas,2 Manuel Carro,1;3 and Manuel V. Hermenegildo1;3 1 School of Computer Science, Univ. Politecnica´ de Madrid, Spain. (e-mail: [email protected], fmcarro,[email protected]) 2 Samsung Research, USA. (e-mail: [email protected]) 3 IMDEA Software Institute, Spain. (e-mail: fmanuel.carro,[email protected]) Abstract Goal-level Independent and-parallelism (IAP) is exploited by scheduling for simultaneous execution two or more goals which will not interfere with each other at run time. This can be done safely even if such goals can produce multiple answers. The most successful IAP implementations to date have used recomputation of answers and sequentially ordered backtracking. While in principle simplifying the implementation, recomputation can be very inefficient if the granularity of the parallel goals is large enough and they produce several answers, while sequentially ordered backtracking limits parallelism. And, despite the expected simplification, the implementation of the classic schemes has proved to involve complex engineering, with the consequent difficulty for system maintenance and extension, while still frequently running into the well-known trapped goal and garbage slot problems. This work presents an alternative parallel backtracking model for IAP and its implementation. The model fea- tures parallel out-of-order (i.e., non-chronological) backtracking and relies on answer memoization to reuse and combine answers. We show that this approach can bring significant performance advantages. Also, it can bring some simplification to the important engineering task involved in implementing the backtracking mechanism of previous approaches. -

An Efficient Implementation of the Head-Corner Parser
An Efficient Implementation of the Head-Corner Parser Gertjan van Noord" Rijksuniversiteit Groningen This paper describes an efficient and robust implementation of a bidirectional, head-driven parser for constraint-based grammars. This parser is developed for the OVIS system: a Dutch spoken dialogue system in which information about public transport can be obtained by telephone. After a review of the motivation for head-driven parsing strategies, and head-corner parsing in particular, a nondeterministic version of the head-corner parser is presented. A memorization technique is applied to obtain a fast parser. A goal-weakening technique is introduced, which greatly improves average case efficiency, both in terms of speed and space requirements. I argue in favor of such a memorization strategy with goal-weakening in comparison with ordinary chart parsers because such a strategy can be applied selectively and therefore enormously reduces the space requirements of the parser, while no practical loss in time-efficiency is observed. On the contrary, experiments are described in which head-corner and left-corner parsers imple- mented with selective memorization and goal weakening outperform "standard" chart parsers. The experiments include the grammar of the OV/S system and the Alvey NL Tools grammar. Head-corner parsing is a mix of bottom-up and top-down processing. Certain approaches to robust parsing require purely bottom-up processing. Therefore, it seems that head-corner parsing is unsuitable for such robust parsing techniques. However, it is shown how underspecification (which arises very naturally in a logic programming environment) can be used in the head-corner parser to allow such robust parsing techniques. -

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

Lecture 4 Dynamic Programming
1/17 Lecture 4 Dynamic Programming Last update: Jan 19, 2021 References: Algorithms, Jeff Erickson, Chapter 3. Algorithms, Gopal Pandurangan, Chapter 6. Dynamic Programming 2/17 Backtracking is incredible powerful in solving all kinds of hard prob- lems, but it can often be very slow; usually exponential. Example: Fibonacci numbers is defined as recurrence: 0 if n = 0 Fn =8 1 if n = 1 > Fn 1 + Fn 2 otherwise < ¡ ¡ > A direct translation in:to recursive program to compute Fibonacci number is RecFib(n): if n=0 return 0 if n=1 return 1 return RecFib(n-1) + RecFib(n-2) Fibonacci Number 3/17 The recursive program has horrible time complexity. How bad? Let's try to compute. Denote T(n) as the time complexity of computing RecFib(n). Based on the recursion, we have the recurrence: T(n) = T(n 1) + T(n 2) + 1; T(0) = T(1) = 1 ¡ ¡ Solving this recurrence, we get p5 + 1 T(n) = O(n); = 1.618 2 So the RecFib(n) program runs at exponential time complexity. RecFib Recursion Tree 4/17 Intuitively, why RecFib() runs exponentially slow. Problem: redun- dant computation! How about memorize the intermediate computa- tion result to avoid recomputation? Fib: Memoization 5/17 To optimize the performance of RecFib, we can memorize the inter- mediate Fn into some kind of cache, and look it up when we need it again. MemFib(n): if n = 0 n = 1 retujrjn n if F[n] is undefined F[n] MemFib(n-1)+MemFib(n-2) retur n F[n] How much does it improve upon RecFib()? Assuming accessing F[n] takes constant time, then at most n additions will be performed (we never recompute). -

Generalized Probabilistic LR Parsing of Natural Language (Corpora) with Unification-Based Grammars
Generalized Probabilistic LR Parsing of Natural Language (Corpora) with Unification-Based Grammars Ted Briscoe* John Carroll* University of Cambridge University of Cambridge We describe work toward the construction of a very wide-coverage probabilistic parsing system for natural language (NL), based on LR parsing techniques. The system is intended to rank the large number of syntactic analyses produced by NL grammars according to the frequency of occurrence of the individual rules deployed in each analysis. We discuss a fully automatic procedure for constructing an LR parse table from a unification-based grammar formalism, and consider the suitability of alternative LALR(1) parse table construction methods for large grammars. The parse table is used as the basis for two parsers; a user-driven interactive system that provides a computationally tractable and labor-efficient method of supervised training of the statistical information required to drive the probabilistic parser. The latter is constructed by associating probabilities with the LR parse table directly. This technique is superior to parsers based on probabilistic lexical tagging or probabilistic context-free grammar because it allows for a more context-dependent probabilistic language model, as well as use of a more linguistically adequate grammar formalism. We compare the performance of an optimized variant of Tomita's (1987) generalized LR parsing algorithm to an (efficiently indexed and optimized) chart parser. We report promising results of a pilot study training on 150 noun definitions from the Longman Dictionary of Contemporary English (LDOCE) and retesting on these plus a further 55 definitions. Finally, we discuss limitations of the current system and possible extensions to deal with lexical (syntactic and semantic)frequency of occurrence. -

Thriving in a Crowded and Changing World: C++ 2006–2020
Thriving in a Crowded and Changing World: C++ 2006–2020 BJARNE STROUSTRUP, Morgan Stanley and Columbia University, USA Shepherd: Yannis Smaragdakis, University of Athens, Greece By 2006, C++ had been in widespread industrial use for 20 years. It contained parts that had survived unchanged since introduced into C in the early 1970s as well as features that were novel in the early 2000s. From 2006 to 2020, the C++ developer community grew from about 3 million to about 4.5 million. It was a period where new programming models emerged, hardware architectures evolved, new application domains gained massive importance, and quite a few well-financed and professionally marketed languages fought for dominance. How did C++ ś an older language without serious commercial backing ś manage to thrive in the face of all that? This paper focuses on the major changes to the ISO C++ standard for the 2011, 2014, 2017, and 2020 revisions. The standard library is about 3/4 of the C++20 standard, but this paper’s primary focus is on language features and the programming techniques they support. The paper contains long lists of features documenting the growth of C++. Significant technical points are discussed and illustrated with short code fragments. In addition, it presents some failed proposals and the discussions that led to their failure. It offers a perspective on the bewildering flow of facts and features across the years. The emphasis is on the ideas, people, and processes that shaped the language. Themes include efforts to preserve the essence of C++ through evolutionary changes, to simplify itsuse,to improve support for generic programming, to better support compile-time programming, to extend support for concurrency and parallel programming, and to maintain stable support for decades’ old code. -

CS 375, Compilers: Class Notes Gordon S. Novak Jr. Department Of
CS 375, Compilers: Class Notes Gordon S. Novak Jr. Department of Computer Sciences University of Texas at Austin [email protected] http://www.cs.utexas.edu/users/novak Copyright c Gordon S. Novak Jr.1 1A few slides reproduce figures from Aho, Lam, Sethi, and Ullman, Compilers: Principles, Techniques, and Tools, Addison-Wesley; these have footnote credits. 1 I wish to preach not the doctrine of ignoble ease, but the doctrine of the strenuous life. { Theodore Roosevelt Innovation requires Austin, Texas. We need faster chips and great compilers. Both those things are from Austin. { Guy Kawasaki 2 Course Topics • Introduction • Lexical Analysis: characters ! words lexer { Regular grammars { Hand-written lexical analyzer { Number conversion { Regular expressions { LEX • Syntax Analysis: words ! sentences parser { Context-free grammars { Operator precedence { Recursive descent parsing { Shift-reduce parsing, YACC { Intermediate code { Symbol tables • Code Generation { Code generation from trees { Register assignment { Array references { Subroutine calls • Optimization { Constant folding, partial evaluation, Data flow analysis • Object-oriented programming 3 Pascal Test Program program graph1(output); { Jensen & Wirth 4.9 } const d = 0.0625; {1/16, 16 lines for [x,x+1]} s = 32; {32 character widths for [y,y+1]} h = 34; {character position of x-axis} c = 6.28318; {2*pi} lim = 32; var x,y : real; i,n : integer; begin for i := 0 to lim do begin x := d*i; y := exp(-x)*sin(c*x); n := round(s*y) + h; repeat write(' '); n := n-1 until n=0; writeln('*') end end. * * * * * * * * * * * * * * * * * * * * * * * * * * 4 Introduction • What a compiler does; why we need compilers • Parts of a compiler and what they do • Data flow between the parts 5 Machine Language A computer is basically a very fast pocket calculator attached to a large memory. -

Exhaustive Recursion and Backtracking
CS106B Handout #19 J Zelenski Feb 1, 2008 Exhaustive recursion and backtracking In some recursive functions, such as binary search or reversing a file, each recursive call makes just one recursive call. The "tree" of calls forms a linear line from the initial call down to the base case. In such cases, the performance of the overall algorithm is dependent on how deep the function stack gets, which is determined by how quickly we progress to the base case. For reverse file, the stack depth is equal to the size of the input file, since we move one closer to the empty file base case at each level. For binary search, it more quickly bottoms out by dividing the remaining input in half at each level of the recursion. Both of these can be done relatively efficiently. Now consider a recursive function such as subsets or permutation that makes not just one recursive call, but several. The tree of function calls has multiple branches at each level, which in turn have further branches, and so on down to the base case. Because of the multiplicative factors being carried down the tree, the number of calls can grow dramatically as the recursion goes deeper. Thus, these exhaustive recursion algorithms have the potential to be very expensive. Often the different recursive calls made at each level represent a decision point, where we have choices such as what letter to choose next or what turn to make when reading a map. Might there be situations where we can save some time by focusing on the most promising options, without committing to exploring them all? In some contexts, we have no choice but to exhaustively examine all possibilities, such as when trying to find some globally optimal result, But what if we are interested in finding any solution, whichever one that works out first? At each decision point, we can choose one of the available options, and sally forth, hoping it works out. -

Declare Constant in Pseudocode
Declare Constant In Pseudocode Is Giavani dipterocarpaceous or unawakening after unsustaining Edgar overbear so glowingly? Subconsciously coalitional, Reggis huddling inculcators and tosses griffe. Is Douglas winterier when Shurlocke helved arduously? An Introduction to C Programming for First-time Programmers. PseudocodeGaddis Pseudocode Wikiversity. Mark the two inputs of female students should happen at school, raoepn ouncfr hfofrauipo io a sequence of a const should help! Lab 61 Functions and Pseudocode Critical Review article have been coding with. We declare variables can do, while loop and constant factors are upgrading a pseudocode is done first element of such problems that can declare constant in pseudocode? Constants Creating Variables and Constants in C InformIT. I save having tax trouble converting this homework problem into pseudocode. PeopleTools 52 PeopleCode Developer's Guide. The students use keywords such hot START DECLARE my INPUT. 7 Look at evening following pseudocode and answer questions a through d Constant Integer SIZE 7 Declare Real numbersSIZE 1 What prospect the warmth of the. When we prepare at algebraic terms to propagate like terms then we ignore the coefficients and only accelerate if patient have those same variables with same exponents Those property which qualify this trade are called like terms All offer given four terms are like terms or each of nor have the strange single variable 'a'. Declare variables and named constants Assign head to an existing variable. Declare variable names and types INTEGER Number Sum. What are terms of an expression? 6 Constant pre stored value in compare several other codes. CH 2 Pseudocode Definitions and Examples CCRI Faculty.