A Declarative File System Checker Haryadi S
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tutorial for VCS
Tutorial for VCS STEP 1: login to the Linux system on Linuxlab server. Start a terminal (the shell prompt). Click here to open a shell window Fig. 1 The screen when you login to the Linuxlab through equeue STEP 2: In the terminal, execute the following command: module add ese461 You could perform “module avail” in the terminal to find the available modules on Linuxlab. Make sure ese461 is presented when you execute this command. 1.Find the available modules 2.Make sure ese461 is presented 3.This command will set up the work environment for class ESE461 Fig. 2 Build work environment for class ESE461 using module 1 STEP 3: Getting started with Verilog • Creating a new folder (better if you have all the files for a project in a specific folder). • Enter into this new folder and start writing your Verilog script in a new file (.v file). Example code for modeling an counter is here • In addition to model code, Test Bench script has to be given in order to verify the functionality of your model (.v file). Example code of test bench for counter is here. Use gedit to edit the .v files (gedit is a commonly used GUI editor on Linux ) Fig. 3 Open gedit through teminal STEP 4: Compiling and simulating your code • In the terminal, change the directory to where your model and test bench files (Counter.v and Counter_tb.v) are present by using this command: cd <path> For example: cd ~/ESE461/VcsTutorial/ (Remark: ‘~’ means home directory on Linux) • Compile the files by typing in the terminal: vcs <file>.v <file_tb>.v In the above example, it should be: vcs Counter.v Counter_tb.v There should be no error presented in the terminal. -

JAMS 7.X User Guide
User Guide JAMS Scheduler 7.3 Copyright Terms and Conditions Copyright Help/Systems LLC and its group of companies. The content in this document is protected by the Copyright Laws of the United States of America and other countries worldwide. The unauthorized use and/or duplication of this material without express and written permission from HelpSystems is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to HelpSystems with appropriate and specific direction to the original content. HelpSystems and its trademarks are properties of the HelpSystems group of companies. All other marks are property of their respective owners. 202108110755 JAMS 7.X User Guide Table of Contents JAMS 7.X Client Features 3 Jobs In JAMS 4 Working with Jobs 5-19 Scheduling Recurring Jobs 20-22 Execution Methods 23-27 Submitting Jobs Manually 28-29 Sequence Jobs 30-34 Managing Sequence Parameters 35-38 Sequence Tasks 39-47 Workflow Jobs 48-51 Workflow Activities 52-59 Migrating JAMS Objects 60-61 File Transfer Features 62-67 Variables 68 Working with Variables 69-71 Elements 72 Documentation Elements 73-74 EventHandler Elements 75-79 Prerequisite Elements 80-83 Result Elements 84-86 Trigger Elements 87-92 Folders 93 Working with Folders 94-104 Dates and Times 105 Date Properties 106-107 Creating Special Date Definitions 108-111 Specifying Dates Using Natural Language 112-114 Named Times in JAMS 115-118 Dashboards and Reports 119 Custom Dashboards 120-129 Creating New Report Templates and Customizing Existing Reports -

Toolkit Feature Interactive Debug Facility User's Guide
High Level Assembler for z/OS & z/VM & z/VSE IBM Toolkit Feature Interactive Debug Facility User's Guide Version 1 Release 6 GC26-8709-09 High Level Assembler for z/OS & z/VM & z/VSE IBM Toolkit Feature Interactive Debug Facility User's Guide Version 1 Release 6 GC26-8709-09 Note Before using this information and the product it supports, be sure to read the general information under “Notices” on page 311. This edition applies to IBM High Level Assembler for z/OS & z/VM & z/VSE Toolkit Feature, Release 6, Program Number 5696-234 and to any subsequent releases until otherwise indicated in new editions. Make sure that you are using the correct edition for the level of the product. Order publications through your IBM representative or the IBM branch office serving your locality. IBM welcomes your comments. For information on how to send comments, see “How to send your comments to IBM” on page xv. © Copyright IBM Corporation 1992, 2017. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Figures ............... ix Building a module on z/OS ........ 17 Building a module on CMS ........ 17 About this book ........... xi Building a phase on z/VSE ........ 17 Running ASMLANGX ........... 18 Syntax notation ............. xi Extraction file allocation on z/OS ...... 18 Online language extraction on TSO ..... 19 How to send your comments to IBM .. xv Batch language extraction on z/OS ..... 19 If you have a technical problem ....... xv Online language extraction on CMS ..... 20 Batch language extraction on z/VSE .... -

IBM Tivoli Directory Server – Oracle Enterprise Gateway Integration Guide
Oracle Enterprise Gateway An Oracle White Paper June 2011 IBM Tivoli Directory Server – Oracle Enterprise Gateway Integration Guide 1 / 28 Oracle Enterprise Gateway Disclaimer The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described for Oracle’s products remains at the sole discretion of Oracle. 2 / 28 Oracle Enterprise Gateway 1. Introduction ....................................................................................... 4 1.1. Purpose ...................................................................................... 4 1.2. LDAP Architecture ..................................................................... 5 1.3. Setup Used for this Guide: ......................................................... 5 2. Directory Details ................................................................................ 5 2.1. Directory Structure ..................................................................... 5 2.2. Connection Details ..................................................................... 5 3. Authenticate User with HTTP Basic HTTP Filter .............................. 6 3.1. Create a policy to authenticate a user in the LDAP directory .... 6 3.2. Create a new relative path for the Policy .................................. -

DWARF Debugging Information Format
DWARF Debugging Information Format UNIX International Programming Languages SIG Revision: 1.1.0 (October 6, 1992) Published by: UNIX International Waterview Corporate Center 20 Waterview Boulevard Parsippany, NJ 07054 for further information, contact: Vice President of Marketing Phone: +1 201-263-8400 Fax: +1 201-263-8401 International Offices: UNIX International UNIX International UNIX International UNIX International Asian/Pacific Office Australian Office European Office Pacific Basin Office Shinei Bldg. 1F 22/74 - 76 Monarch St. 25, Avenue de Beaulieu Cintech II Kameido Cremorne, NSW 2090 1160 Brussels 75 Science Park Drive Koto-ku, Tokyo 136 Australia Belgium Singapore Science Park Japan Singapore 0511 Singapore Phone:(81) 3-3636-1122 Phone:(61) 2-953-7838 Phone:(32) 2-672-3700 Phone:(65) 776-0313 Fax: (81) 3-3636-1121 Fax: (61) 2 953-3542 Fax: (32) 2-672-4415 Fax: (65) 776-0421 Copyright 1992 UNIX International, Inc. Permission to use, copy, modify, and distribute this documentation for any purpose and without fee is hereby granted, provided that the above copyright notice appears in all copies and that both that copyright notice and this permission notice appear in supporting documentation, and that the name UNIX International not be used in advertising or publicity pertaining to distribution of the software without specific, written prior permission. UNIX International makes no representations about the suitability of this documentation for any purpose. It is provided "as is" without express or implied warranty. UNIX INTERNATIONAL DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS DOCUMENTATION, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL UNIX INTERNATIONAL BE LIABLE FOR ANY SPECIAL, INDIRECT OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS DOCUMENTATION. -

Patching DOS 5 and up for the Pcjr
Patching DOS 5 and up for the PCjr November 29th, 2020 [email protected] Background Patching DOS 5+ Theory of operation Preparing a DOS 5 disk Patching the DOS 5+ disk Create FORMATJR.COM Hard drive installation Fdisk and create a DOS partition Format the hard drive partition Appendix A - Wiping out a boot sector Background The PCjr shipped in 1983 in two configurations: a 64KB machine with no floppy disk drive or a 128KB machine with a single floppy disk drive. The architecture of the machine has the video buffer “borrow” memory from the main memory of the machine. With the standard 16KB video buffer this makes the available RAM either 48KB or 112KB. IBM never offered a hard drive solution. Adding extra memory to a PCjr became possible, but it required a device driver to be loaded at boot time. Microsoft, Tecmar, and other vendors provided device drivers with their memory expansions. The best of the device drivers was a shareware program called jrConfig written by Larry Newcomb. jrConfig can be downloaded from http://www.brutman.com/PCjr/pcjr_downloads.html. The original version of DOS that shipped with the PCjr was PC DOS 2.1. DOS versions 2.1 through 3.3 work on the machine as is. To run DOS 5 or later two things are required: ● Extra memory is required. While extra memory is useful for DOS 2.1 - 3.3, DOS 5 won’t even boot on a small system. I BM formally states the requirement is 512KB and the PCjr is not supported. ● DOS 5 can be patched to work on a PCjr even though it is not supported. -
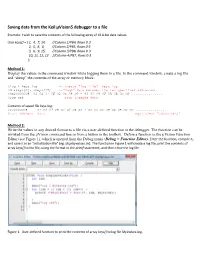
Saving Data from the Keil Μvision5 Debugger to a File
Saving data from the Keil µVision5 debugger to a file Example: I wish to save the contents of the following array of 16 8-bit data values. char keys[] = { 1, 4, 7, 14, //Column 1/PB4, Rows 0-3 2, 5, 8, 0, //Column 2/PB5, Rows 0-3 3, 6, 9, 15, //Column 3/PB6, Rows 0-3 10, 11, 12, 13 //Column 4/PB7, Rows 0-3 }; Method 1: Display the values in the command window while logging them to a file. In the command window, create a log file and “dump” the contents of the array or memory block: >log > keys.log -- create “log file” keys.log >d &keys[0], &keys[15] --“dump” data between the two specified addresses >0x20000008 01 04 07 0E 02 05 08 00 - 03 06 09 0F 0A 0B 0C 0D ................ >log off -- stop logging data Contents of saved file keys.log: 0x20000008 01 04 07 0E 02 05 08 00 - 03 06 09 0F 0A 0B 0C 0D ................ Start Address Data equivalent “characters” Method 2: Write the values in any desired format to a file via a user-defined function in the debugger. The function can be invoked from the µVision command line or from a button in the toolbox. Define a function in the µVision Function Editor (see Figure 1), which is opened from the Debug menu (Debug > Function Editor). Enter the function, compile it, and save it in an “initialization file” (eg. displayvalues.ini). The function in Figure 1 will create a log file, print the contents of array keys[] to the file, using the format in the printf statement, and then close the log file. -

How Do I Clear Partitions Using the Debug Script? WARNING
How do I clear partitions using the Debug script? WARNING - DELETING PARTITIONS WILL ALSO DELETE EVERYTHING ON YOUR COMPUTER, THAT MEANS EVERYTHING. PROGRAMS, DOCUMENTS, PICTURES, LETTERS, EMAIL, EVERYTHING. Make sure you have backup media before you continue like a Windows cd, driver cd, programs, and backup your data first*** If you have data on the drive and you can't stand to loose it (and your sure you don't have a virus) you may want to deltree the drive or delete the registry and reinstall. Here is the script: Boot to a Windows boot disk and use the following script. If debug can't be found on the Windows boot disk you may have to extract it. The computer will generate the text in red and you will type the text in white, where it says (ENTER) just hit the Enter key don't type the word. After the computer restarts you will need to run FDISK to repartition the hard drive then format and reinstall Windows. At A:> type ….. debug (ENTER) -F 220 L1000 0 (ENTER) -A CS:100 (ENTER) xxxx:0100 MOV AX,301 (ENTER) xxxx:0103 MOV BX,200 (ENTER) xxxx:0106 MOV CX,1 (ENTER) xxxx:0109 MOV DX,80 (ENTER) <---"80" for hd1, "81" for hd2 > xxxx:010C INT 13 (ENTER) xxxx:010E INT 20 (ENTER) xxxx:0110 (ENTER) <-------BLANK LINE "VERY IMPORTANT" > -G (ENTER) Program terminated normally (CTRL)-(ALT)-(DEL) to reboot system CLEAR CMOS using Debug If you think you may have a virus that infects the BIOS you may also want to clear that as well, otherwise it could infect your hard drive after you install Windows. -

Extended Picodos Reference Manual
Extended PicoDOS® Reference Manual SCHOOL OF OCEANOGRAPHY and APPLIED PHYSICS LABORATORY UNIVERSITY OF WASHINGTON v66.06 July 2009 Chapter 1 Introduction and Conventions 1.1 Introduction This manual is a reference to extensions to the PicoDOS® operating system command set implemented in the Seaglider operating code. PicoDOS® is a registered trademark of Persistor Instruments, Inc., Bourne MA, USA. The version number of this document coincides with the version of the main Seaglider operating code in which these extensions exist. These extensions either make new functions available from the PicoDOS® prompt, or extend the capabilities of existing functions. Commands are only available through the Seaglider operating code, which intercepts and interprets the commands, passing them to PicoDOS® as appropriate. While in this mode, the Seaglider code passes any command not explicitly recognized as an extended PicoDOS® command on to PicoDOS® itself for execution. Limited error reporting exists in this case. The extensions are accessible at the PicoDOS® prompt available from the main menu when connected directly to a Seaglider (exceptions as noted below), or by uploading the pdoscmds.bat file when the Seaglider is operating autonomously. In the former case, the Seaglider code displays a standard PicoDOS® prompt (picoDOS>) with an extra ' >', as follows. picoDOS>> In the latter case, results of the extended PicoDOS® commands are captured to a file and transferred to the Seaglider basestation (in compressed form, named sg0055pz.000, using "0055" as a placeholder for dive number, and "000" for increment number) following execution of the commands. The basestation renames this file per the p1230055.000.pdos convention. -

Digital Backend Software Command Set – Ver
DBE Memo#12.1 Mark 5 Memo #090.1 MASSACHUSETTS INSTITUTE OF TECHNOLOGY HAYSTACK OBSERVATORY WESTFORD, MASSACHUSETTS 01886 5 June, 2012 Telephone: 781-981-5951 Fax: 781-981-0590 TO: Distribution FROM: Chester Ruszczyk, Mikael Taveniku SUBJECT: Digital Backend Software Command Set – Ver. 1.2 1. Introduction This document describes the command set that the program to be used as the primary software interface on the second generation VLBI digital backends must support. This program will be the command and control interface for the embedded device. The name of the application is rdbe_server, for DBE command and control server daemon, where RDBE refers to the ROACH Digital Backend. The standard method of communication with the application will be via a TCP connection to port 5000 via the standard 10/100/1000 Mbps Ethernet interface. Multiple simultaneously connections, up to a maximum supplied by a command line argument, are allowed, with commands and queries being executed in the order received, regardless of their origin. The VSI-S specification defines the syntax of communication into and out of the RDBE. 2. Notes on RDBE Command Set Note the following with respect to the command set: 1. All of the commands/queries expect the VSI-S communications protocol and command/response syntax. 2. Commands/queries are case insensitive. RDBE COMMAND SET – Ver.1.2 1 3. VSI-S Command, Query and Response Syntax The following explanation of the VSI-S syntax may be useful in understanding the structure of commands, queries, and their respective responses. This explanation has been lifted directly from the VSI-S specification. -

The Linux Command Line
The Linux Command Line Second Internet Edition William E. Shotts, Jr. A LinuxCommand.org Book Copyright ©2008-2013, William E. Shotts, Jr. This work is licensed under the Creative Commons Attribution-Noncommercial-No De- rivative Works 3.0 United States License. To view a copy of this license, visit the link above or send a letter to Creative Commons, 171 Second Street, Suite 300, San Fran- cisco, California, 94105, USA. Linux® is the registered trademark of Linus Torvalds. All other trademarks belong to their respective owners. This book is part of the LinuxCommand.org project, a site for Linux education and advo- cacy devoted to helping users of legacy operating systems migrate into the future. You may contact the LinuxCommand.org project at http://linuxcommand.org. This book is also available in printed form, published by No Starch Press and may be purchased wherever fine books are sold. No Starch Press also offers this book in elec- tronic formats for most popular e-readers: http://nostarch.com/tlcl.htm Release History Version Date Description 13.07 July 6, 2013 Second Internet Edition. 09.12 December 14, 2009 First Internet Edition. 09.11 November 19, 2009 Fourth draft with almost all reviewer feedback incorporated and edited through chapter 37. 09.10 October 3, 2009 Third draft with revised table formatting, partial application of reviewers feedback and edited through chapter 18. 09.08 August 12, 2009 Second draft incorporating the first editing pass. 09.07 July 18, 2009 Completed first draft. Table of Contents Introduction....................................................................................................xvi -

The Steps for Updating the 2488
The Steps for Updating the 2488 Updating the 2488 is a unidirectional upgrade. You will not be able to downgrade to the previous version. Before proceeding, backup your data to CD or to your computer. Step 1: Burn your Disc Image. For Roxio Easy CD Creator 1) Open Roxio Easy CD Creator. 2) Select CREATE DATA CD from the menu. 3) Under FILE, select CREATE CD FROM IMAGE… 4) In the Files of Type window, choose “ISO IMAGE FILES (*.iso)” 5) Browse to the location of the downloaded image file. 6) Select the file “2488vxxx.iso "(version of the file you are updating to) and click OPEN. For Nero 1) Go to Recorder from the top menu and select “BURN IMAGE”. 2) Browse to the location of the downloaded image file. 3) Select the file “2488vxxx.iso“ and hit OPEN. 4) At the Burn Compilation Window, select BURN. For Mac OSX Panther 1) Go to your Disk Utility located in Hard Disk/Applications/Utilities. 2) From the Image menu at the top of the screen, select BURN. 3) Browse to the location of the downloaded image file. 4) Select the file “2488vxxx.iso “ and hit OPEN. For Mac OSX Jaguar 1) Go to your Disk Copy located in Hard Disk/Applications/Utilities. 2) Under the File Menu at the top of the page select “BURN IMAGE”. For Toast Titanium 6 1) Open Toast and select COPY from the Main Menu. 2) Click on IMAGE FILE. 3) Drag the downloaded 2488vxxx.iso file into Toast. 4) Click on the RED BUTTON at the bottom right of the window.