The Stanford Corenlp Natural Language Processing Toolkit Christopher D
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

The Programmer's Guide to Apache Thrift MEAP
MEAP Edition Manning Early Access Program The Programmer’s Guide to Apache Thrift Version 5 Copyright 2013 Manning Publications For more information on this and other Manning titles go to www.manning.com ©Manning Publications Co. We welcome reader comments about anything in the manuscript - other than typos and other simple mistakes. These will be cleaned up during production of the book by copyeditors and proofreaders. http://www.manning-sandbox.com/forum.jspa?forumID=873 Licensed to Daniel Gavrila <[email protected]> Welcome Hello and welcome to the third MEAP update for The Programmer’s Guide to Apache Thrift. This update adds Chapter 7, Designing and Serializing User Defined Types. This latest chapter is the first of the application layer chapters in Part 2. Chapters 3, 4 and 5 cover transports, error handling and protocols respectively. These chapters describe the foundational elements of Apache Thrift. Chapter 6 describes Apache Thrift IDL in depth, introducing the tools which enable us to describe data types and services in IDL. Chapters 7 through 9 bring these concepts into action, covering the three key applications areas of Apache Thrift in turn: User Defined Types (UDTs), Services and Servers. Chapter 7 introduces Apache Thrift IDL UDTs and provides insight into the critical role played by interface evolution in quality type design. Using IDL to effectively describe cross language types greatly simplifies the transmission of common data structures over messaging systems and other generic communications interfaces. Chapter 7 demonstrates the process of serializing types for use with external interfaces, disk I/O and in combination with Apache Thrift transport layer compression. -

HDP 3.1.4 Release Notes Date of Publish: 2019-08-26
Release Notes 3 HDP 3.1.4 Release Notes Date of Publish: 2019-08-26 https://docs.hortonworks.com Release Notes | Contents | ii Contents HDP 3.1.4 Release Notes..........................................................................................4 Component Versions.................................................................................................4 Descriptions of New Features..................................................................................5 Deprecation Notices.................................................................................................. 6 Terminology.......................................................................................................................................................... 6 Removed Components and Product Capabilities.................................................................................................6 Testing Unsupported Features................................................................................ 6 Descriptions of the Latest Technical Preview Features.......................................................................................7 Upgrading to HDP 3.1.4...........................................................................................7 Behavioral Changes.................................................................................................. 7 Apache Patch Information.....................................................................................11 Accumulo........................................................................................................................................................... -

Kyuubi Release 1.3.0 Kent
Kyuubi Release 1.3.0 Kent Yao Sep 30, 2021 USAGE GUIDE 1 Multi-tenancy 3 2 Ease of Use 5 3 Run Anywhere 7 4 High Performance 9 5 Authentication & Authorization 11 6 High Availability 13 6.1 Quick Start................................................ 13 6.2 Deploying Kyuubi............................................ 47 6.3 Kyuubi Security Overview........................................ 76 6.4 Client Documentation.......................................... 80 6.5 Integrations................................................ 82 6.6 Monitoring................................................ 87 6.7 SQL References............................................. 94 6.8 Tools................................................... 98 6.9 Overview................................................. 101 6.10 Develop Tools.............................................. 113 6.11 Community................................................ 120 6.12 Appendixes................................................ 128 i ii Kyuubi, Release 1.3.0 Kyuubi™ is a unified multi-tenant JDBC interface for large-scale data processing and analytics, built on top of Apache Spark™. In general, the complete ecosystem of Kyuubi falls into the hierarchies shown in the above figure, with each layer loosely coupled to the other. For example, you can use Kyuubi, Spark and Apache Iceberg to build and manage Data Lake with pure SQL for both data processing e.g. ETL, and analytics e.g. BI. All workloads can be done on one platform, using one copy of data, with one SQL interface. Kyuubi provides the following features: USAGE GUIDE 1 Kyuubi, Release 1.3.0 2 USAGE GUIDE CHAPTER ONE MULTI-TENANCY Kyuubi supports the end-to-end multi-tenancy, and this is why we want to create this project despite that the Spark Thrift JDBC/ODBC server already exists. 1. Supports multi-client concurrency and authentication 2. Supports one Spark application per account(SPA). 3. Supports QUEUE/NAMESPACE Access Control Lists (ACL) 4. -

Implementing Replication for Predictability Within Apache Thrift Jianwei Tu the Ohio State University [email protected]
Implementing Replication for Predictability within Apache Thrift Jianwei Tu The Ohio State University [email protected] ABSTRACT have a large number of packets. A study indicated that about Interactive applications, such as search, social networking and 0.02% of all flows contributed more than 59.3% of the total retail, hosted in cloud data center generate large quantities of traffic volume [1]. TCP is the dominating transport protocol small workloads that require extremely low median and tail used in data center. However, the performance for short flows latency in order to provide soft real-time performance to users. in TCP is very poor: although in theory they can be finished These small workloads are known as short TCP flows. in 10-20 microseconds with 1G or 10G interconnects, the However, these short TCP flows experience long latencies actual flow completion time (FCT) is as high as tens of due in part to large workloads consuming most available milliseconds [2]. This is due in part to long flows consuming buffer in the switches. Imperfect routing algorithm such as some or all of the available buffers in the switches [3]. ECMP makes the matter even worse. We propose a transport Imperfect routing algorithms such as ECMP makes the matter mechanism using replication for predictability to achieve low even worse. State of the art forwarding in enterprise and data flow completion time (FCT) for short TCP flows. We center environment uses ECMP to statically direct flows implement replication for predictability within Apache Thrift across available paths using flow hashing. It doesn’t account transport layer that replicates each short TCP flow and sends for either current network utilization or flow size, and may out identical packets for both flows, then utilizes the first flow direct many long flows to the same path causing flash that finishes the transfer. -
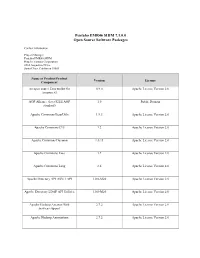
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho EMR46 SHIM Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component An open source Java toolkit for 0.9.0 Apache License Version 2.0 Amazon S3 AOP Alliance (Java/J2EE AOP 1.0 Public Domain standard) Apache Commons BeanUtils 1.9.3 Apache License Version 2.0 Apache Commons CLI 1.2 Apache License Version 2.0 Apache Commons Daemon 1.0.13 Apache License Version 2.0 Apache Commons Exec 1.2 Apache License Version 2.0 Apache Commons Lang 2.6 Apache License Version 2.0 Apache Directory API ASN.1 API 1.0.0-M20 Apache License Version 2.0 Apache Directory LDAP API Utilities 1.0.0-M20 Apache License Version 2.0 Apache Hadoop Amazon Web 2.7.2 Apache License Version 2.0 Services support Apache Hadoop Annotations 2.7.2 Apache License Version 2.0 Name of Product/Product Version License Component Apache Hadoop Auth 2.7.2 Apache License Version 2.0 Apache Hadoop Common - 2.7.2 Apache License Version 2.0 org.apache.hadoop:hadoop-common Apache Hadoop HDFS 2.7.2 Apache License Version 2.0 Apache HBase - Client 1.2.0 Apache License Version 2.0 Apache HBase - Common 1.2.0 Apache License Version 2.0 Apache HBase - Hadoop 1.2.0 Apache License Version 2.0 Compatibility Apache HBase - Protocol 1.2.0 Apache License Version 2.0 Apache HBase - Server 1.2.0 Apache License Version 2.0 Apache HBase - Thrift - 1.2.0 Apache License Version 2.0 org.apache.hbase:hbase-thrift Apache HttpComponents Core -

Plugin Tapestry
PlugIn Tapestry Autor @picodotdev https://picodotdev.github.io/blog-bitix/ 2019 1.4.2 5.4 A tod@s l@s programador@s que en su trabajo no pueden usar el framework, librería o lenguaje que quisieran. Y a las que se divierten programando y aprendiendo hasta altas horas de la madrugada. Non gogoa, han zangoa Hecho con un esfuerzo en tiempo considerable con una buena cantidad de software libre y más ilusión en una región llamada Euskadi. PlugIn Tapestry: Desarrollo de aplicaciones y páginas web con Apache Tapestry @picodotdev 2014 - 2019 2 Prefacio Empecé El blog de pico.dev y unos años más tarde Blog Bitix con el objetivo de poder aprender y compartir el conocimiento de muchas cosas que me interesaban desde la programación y el software libre hasta análisis de los productos tecnológicos que caen en mis manos. Las del ámbito de la programación creo que usándolas pueden resolver en muchos casos los problemas típicos de las aplicaciones web y que encuentro en el día a día en mi trabajo como desarrollador. Sin embargo, por distintas circunstancias ya sean propias del cliente, la empresa o las personas es habitual que solo me sirvan meramente como satisfacción de adquirir conocimientos. Hasta el día de hoy una de ellas es el tema del que trata este libro, Apache Tapestry. Para escribir en el blog solo dependo de mí y de ninguna otra circunstancia salvo mi tiempo personal, es com- pletamente mío con lo que puedo hacer lo que quiera con él y no tengo ninguna limitación para escribir y usar cualquier herramienta, aunque en un principio solo sea para hacer un ejemplo muy sencillo, en el momento que llegue la oportunidad quizá me sirva para aplicarlo a un proyecto real. -
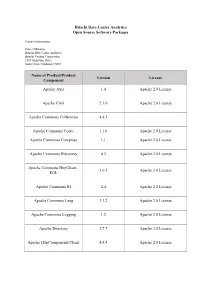
Hitachi Data Center Analytics Open Source Software Packages
Hitachi Data Center Analytics Open Source Software Packages Contact Information: Project Manager Hitachi Data Center Analytics Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component Apache Axis 1.4 Apache 2.0 License Apache Click 2.3.0 Apache 2.0 License Apache Commons Collections 4.4.1 Apache Commons Codec 1.10 Apache 2.0 License Apache Commons Compress 1.1 Apache 2.0 License Apache Commons Discovery 0.2 Apache 2.0 License Apache Commons HttpClient - 3.0.1 Apache 2.0 License EOL Apache Commons IO 2.4 Apache 2.0 License Apache Commons Lang 3.3.2 Apache 2.0 License Apache Commons Logging 1.2 Apache 2.0 License Apache Directory 2.7.7 Apache 2.0 License Apache HttpComponents Client 4.4.4 Apache 2.0 License Name of Product/Product Version License Component Apache HttpComponents 5.5.2 Apache 2.0 License Apache Log4j 1.2.17 Apache 2.0 License Apache Log4net 1.2.10 Apache 2.0 License Apache PDF Box 2.0.2 Apache 2.0 License Apache POI 3.15 Apache 2.0 License Apache Thrift 0.9.1 Apache 2.0 License Apache Web Services 1.0.2 Apache 2.0 License Apache Xerces Java Parser 2.9.0 Apache 2.0 License Apache XML Graphics 1.4 Apache 2.0 License Apache XML-RPC 3.1 Apache 2.0 License Apache XMLBeans 2.6.0 Apache 2.0 License Bouncy Castle Crypto API 1.45.0 MIT license CHILKAT CRYPT 9.5.0 Paid click-calendar 1.3.0 Apache 2.0 License Customized log4j File Appender Apache 2.0 License docx4j 2.7.0 Apache 2.0 License Name of Product/Product Version License Component dom4j 1.6.1 Apache 2.0 -

Customizable and Extensible Deployment for Mobile/Cloud Applications Irene Zhang Adriana Szekeres Dana Van Aken Isaac Ackerman Steven D
Customizable and Extensible Deployment for Mobile/Cloud Applications Irene Zhang Adriana Szekeres Dana Van Aken Isaac Ackerman Steven D. Gribble∗ Arvind Krishnamurthy Henry M. Levy University of Washington Abstract between application requirements and deployment de- cisions leads programmers to mix deployment decisions Modern applications face new challenges in manag- with complex application logic in the code, which makes ing today’s highly distributed and heterogeneous envi- mobile/cloud applications difficult to implement, debug, ronment. For example, they must stitch together code maintain, and evolve. Even worse, the rapid evolution of that crosses smartphones, tablets, personal devices, and devices, networks, systems, and applications means that cloud services, connected by variable wide-area net- the trade-offs that impact these deployment decisions are works, such as WiFi and 4G. This paper describes Sap- constantly in flux. For all of these reasons, programmers , a distributed programming platform that simplifies phire need a flexible system that allows them to easily create the programming of today’s mobile/cloud applications. and modify distributed application deployments without Sapphire’s key design feature is its distributed runtime needing to rewrite major parts of their application. system, which supports a flexible and extensible deploy- ment layer for solving complex distributed systems tasks, This paper presents Sapphire, a general-purpose such as fault-tolerance, code-offloading, and caching. distributed programming platform that greatly simplifies Rather than writing distributed systems code, program- the design and implementation of applications spanning mers choose deployment managers that extend Sapphire’s mobile devices and clouds. Sapphire removes much of kernel to meet their applications’ deployment require- the complexity of managing a wide-area, multi-platform ments. -

Third Party Notices Tibco Jaspersoft: Jasperreports Server, Jasperreports, Jaspersoft Studio Updated: 2014‐05‐27 Product Version: 5.6.0
Third Party Notices Tibco Jaspersoft: JasperReports Server, JasperReports, Jaspersoft Studio Updated: 2014‐05‐27 Product Version: 5.6.0 Component Version Home Page License A Java library for reading/writing Excel 2.6.10 http://sourceforge.net/projects/jexcelapi/ LGPL 2.1 ANT Contrib 1.0b3 http://ant-contrib.sourceforge.net/ Apache License Version 2.0 ant‐deb‐task Unspecified http://github.com/travis/ant-deb-task/ Apache License Version 2.0 ANTLR, ANother Tool for Language Recognition 3.0 http://www.antlr.org/ BSD 2.0 ANTLR, ANother Tool for Language Recognition 2.7.5 http://www.antlr.org/ ANTLR License ANTLR, ANother Tool for Language Recognition Unspecified http://www.antlr.org/ BSD 2.0 ANTLR, ANother Tool for Language Recognition 2.7.6 http://www.antlr.org/ ANTLR License AOP Alliance (Java/J2EE AOP standard) 1.0 http://sourceforge.net/projects/aopalliance/ Public Domain Apache Batik Unspecified http://xml.apache.org/batik/index.html Apache License Version 2.0 avro‐1.4.0‐cassandra‐1.jar http://avro.apache.org/ Apache License Version 2.0 cassandra‐all‐1.2.9.jar 1.2.9 http://cassandra.apache.org/ Apache License Version 2.0 cassandra‐driver‐core‐1.0.4‐dse.jar 1.0.4 http://cassandra.apache.org/ Apache License Version 2.0 cassandra‐thirft‐1.2.9 1.2.9 http://cassandra.apache.org/ Apache License Version 2.0 Apache Cassandra 1.0.6 http://cassandra.apache.org/ Apache License Version 2.0 https://repository.apache.org/content/repositories/releases/org/apa Apache Cassandra 1.0.5 che/cassandra/cassandra-thrift/ Apache License Version 2.0 Apache Commons -

System Demonstrations
ACL 2014 52nd Annual Meeting of the Association for Computational Linguistics Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations June 23-24, 2014 Baltimore, Maryland, USA c 2014 The Association for Computational Linguistics Order copies of this and other ACL proceedings from: Association for Computational Linguistics (ACL) 209 N. Eighth Street Stroudsburg, PA 18360 USA Tel: +1-570-476-8006 Fax: +1-570-476-0860 [email protected] ISBN 978-1-941643-00-6 ii Preface Welcome to the proceedings of the system demonstration session. This volume contains the papers of the system demonstrations presented at the 52nd Annual Meeting of the Association for Computational Linguistics, on June 23-24, 2014 in Baltimore, Maryland, USA. The system demonstrations program offers the presentation of early research prototypes as well as interesting mature systems. The system demonstration chairs and the members of the program committee received 39 submissions, of which 21 were selected for inclusion in the program (acceptance rate of 53.8%) after review by three members of the program committee. We would like to thank the members of the program committee for their timely help in reviewing the submissions. iii Co-Chairs: Kalina Bontcheva, University of Sheffield Zhu Jingbo, Northeastern University Program Committee: Beatrice Alex, University of Edinburgh Omar Alonso, Microsoft Thierry Declerck, DFKI Leon Derczynski, University of Sheffield Mark Dras, Macquarie University Josef van Genabith, Dublin City University -

Introduction to RPC, Apache Thrift Workshop Tomasz Powchowicz It Is All About Effective Communication
Introduction to RPC, Apache Thrift Workshop Tomasz Powchowicz It is all about effective communication • Apache Thrift Workshop page 2 • Synchronous, asynchronous execution Executor Executor A Executor B Executor A Executor B Task Task Task 1 1 1 Task Task Task 3 Task 2 2 2 result result Task Task Task 4 3 3 Task Task 4 4 • Apache Thrift Workshop page 3 • Thread vs Process Thread Process Address space Shares address space Have own address space Communication Mutex, Condition variable, Inter-process communication (IPC): File, Signal, Socket, Critical section, Spin lock, Unix Domain Socket, Message queue, Pipe, Named Atomics pipe, Semaphore, Shared memory, Message passing (e.g. RPC, RMI), Memory mapped file Error resiliency Data on stack and on heap Address space is protected. could be damaged. Spawning Cheap Expensive Security Secure data could be Memory is secured, other resources could be separated accessed from other thread. by introducing an extra layer such as LXC or KVM. Scaling Limited to the number of cores Could be scaled to many CPUs. in CPU. Context Fast - shared virtual memory Slow - A translation lookaside buffer (TLB) flush is switching maps. necessary. • Apache Thrift Workshop page 4 • RPC definition “In distributed computing, a remote procedure call (RPC) is when a computer program causes a procedure (subroutine) to execute in a different address space (commonly on another computer on a shared network), which is coded as if it were a normal (local) procedure call, without the programmer explicitly coding the details for the