DS HW2: Swimming Classes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How Fast Were the Fast Suits? a Visual Analysis of the Textile Vs
How Fast Were The Fast Suits? A Visual Analysis of the Textile vs. Non-Textile Swim Suit Era’s Prepared by Elliot Meena June 2014 theswimscout Agenda I. World Records VI. Backstroke II. All Strokes VII. Breaststroke III. Long-Axis VIII. Freestyle IV. Short-Axis IX. Individual Medley V. Butterfly X. Era 1 3 2 World Records Used In Analysis Section I 3 Female Long-Axis World Record’s Used In Analysis Female Long-Axis World Record's Used In Analysis Era* Event Name Time Date Event Name Time Date 1 50 Backstroke Li Yang 28.09 10/15/07 50 Freestyle Inge de Bruijn 24.13 09/22/00 2 50 Backstroke Sophie Edington 27.67 03/23/08 50 Freestyle Libby Trickett 23.97 03/29/08 3 50 Backstroke Jing Zhao 27.06 07/30/09 50 Freestyle Britta Stefen 23.73 08/02/09 4 50 Backstroke Fu Yuanhui 27.22 05/04/13 50 Freestyle Ranomi Kromowidjojo 24.05 04/08/12 1 100 Backstroke Natalie Coughlin 59.44 03/27/07 100 Freestyle Britta Stefen 53.30 08/02/06 2 100 Backstroke Kirsty Coventry 58.77 08/11/08 100 Freestyle Libby Trickett 52.88 03/27/08 3 100 Backstroke Gemma Spofforth 58.12 07/28/09 100 Freestyle Britta Stefen 52.07 07/31/09 4 100 Backstroke Emily Seebohm 58.23 07/29/12 100 Freestyle Cate Campbell 52.33 07/28/13 1 200 Backstroke Kristina Egerszegi 126.62 08/22/91 200 Freestyle Laure Manaudou 115.52 03/28/07 2 200 Backstroke Kirsty Coventry 125.24 08/16/08 200 Freestyle Federica Pellegrini 114.82 08/13/08 3 200 Backstroke Kirsty Coventry 124.81 08/01/09 200 Freestyle Federica Pellegrini 112.98 07/29/09 4 200 Backstroke Missy Franklin 124.06 08/03/12 200 Freestyle -

WOMEN 200Free
FINAL 200 free women World Record 1:52.98 Federica Pellegrini (ITA) 29 Jul 2009, Rome European Record 1:52.98 Federica Pellegrini (ITA) 29 Jul 2009, Rome World Best Time 2016 1:54.43 Kathleen Ledecky (USA) Olympic Champion 2012 1:53.61 Allison Schmitt (USA) World Champion 2015 1:55.16 Kathleen Ledecky (USA) European Champion 2014 1:56.01 Federica Pellegrini (ITA) Lane Name Personal Info OG WC EC DoB: 06 AUG 1992 LC-2. (4x200FR) '16 PoB: Madrid LC-5. (4x100MR) '12 Patricia CASTRO SC-8. (400FR) '10 Club: Real Canoe NC LC-6. (200FR) '10, '12 8 10. (4x200FR) '12 WJC-6. (200FR) '08 ESP Coach: José F. Gonzalez LC-8. (500FR) '10 WJC-8. (100FR) '08 QT 1:58.83 PB 1:58.11 Height: 178cm SC-4. (200FR) '12 Occupation: Student EJC-1. (200FR) '08 DoB: 22 OCT 1990 LC-16. (200FR) '15 LC-6. (100FR) '16 Nina RANGELOVA PoB: Plovdiv 19. (200FR) '12 LC-22. (200FR) '11 LC-8. (100FR) '14 7 BUL Club: SMU Mustangs, Dallas, USA 23. (400FR) '12 LC-29. (200FR) '11 LC-8. (200FR) '14 QT 1:58.68 Coach: Steve Collins, USA 24. (100FR) '12 SC-10. (400FR) '10 LC-13. (200FR) '12 PB 1:58.68 Height: 173cm SC-16. (200FR) '12 SC-7. (200FR) '11 DoB: 24 APR 1989 LC-2. (400FR) '13 LC-4. (200FR) '14 PoB/Res.: Palma de Mallorca LC-5. (200FR) '13 Melani COSTA LC-5. (800FR) '12 Club: UCAM Fuensanta 9. (200FR) '12 LC-6. (400FR) '15 6 LC-6. -

Code De Conduite Pour Le Water Polo
HistoFINA SWIMMING MEDALLISTS AND STATISTICS AT OLYMPIC GAMES Last updated in November, 2016 (After the Rio 2016 Olympic Games) Fédération Internationale de Natation Ch. De Bellevue 24a/24b – 1005 Lausanne – Switzerland TEL: (41-21) 310 47 10 – FAX: (41-21) 312 66 10 – E-mail: [email protected] Website: www.fina.org Copyright FINA, Lausanne 2013 In memory of Jean-Louis Meuret CONTENTS OLYMPIC GAMES Swimming – 1896-2012 Introduction 3 Olympic Games dates, sites, number of victories by National Federations (NF) and on the podiums 4 1896 – 2016 – From Athens to Rio 6 Olympic Gold Medals & Olympic Champions by Country 21 MEN’S EVENTS – Podiums and statistics 22 WOMEN’S EVENTS – Podiums and statistics 82 FINA Members and Country Codes 136 2 Introduction In the following study you will find the statistics of the swimming events at the Olympic Games held since 1896 (under the umbrella of FINA since 1912) as well as the podiums and number of medals obtained by National Federation. You will also find the standings of the first three places in all events for men and women at the Olympic Games followed by several classifications which are listed either by the number of titles or medals by swimmer or National Federation. It should be noted that these standings only have an historical aim but no sport signification because the comparison between the achievements of swimmers of different generations is always unfair for several reasons: 1. The period of time. The Olympic Games were not organised in 1916, 1940 and 1944 2. The evolution of the programme. -

Swimming World Recognizes Best Swimmers of 2011
WORLD SWIMMERS OF THE YEAR N RECORD PROGRESSIONS N MAKING MOST OF THE OFF-SEASON DECEMBER 2011 —VOLUME 52 NO. 12 USA SWEEPS AND REPEATS pages 12-13 “The daily news of swimming” Check us out online at: www.SwimmingWorldMagazine.com $3.95 USA • $4.50 CAN INSIDE THE DECEMBER ISSUE of FEATURES 8 10 Best Performances of 2011 by John Lohn 12 World and Regional Swimmers of the Year 8 by Jason Marsteller and Jeff Commings World & American: Rebecca Soni and Ryan Lochte European: Federica Pellegrini and Alexander Dale Oen Pacific Rim: Ye Shiwen and Sun Yang African: Kirsty Coventry and Cameron van der Burgh 20 Diving, Water Polo, Synchronized Swimming Award Winners Diving: Chen Ruolin and Qiu Bo Water Polo: Krystina Alogbo and Stefano Tempesti Synchronized Swimming: Natalia Ischenko 22 Defining Moments by Judy Jacob 12 The Pan-Am Games appear to be Brazil’s Thiago Pereira’s own personal playground, as he matched his records for most gold medals and overall med- als that he had set four years ago. 28 Workout Card: Las Vegas Masters by Vic Hecker 30 Q&A with Coach Monty Hopkins by Michael J. Stott 32 How They Train: Josh Schneider by Michael J. Stott 33 Science of Performance: Off-season Training by G. John Mullen 22 The off-season is a good time to stay productive and help make yourself a better swimmer. 36 American Relay by Judy Jacob 37 TYR Age Group Swimmer of the Month 42 World & American Record Progressions by Jason Marsteller DEPARTMENTS 6 A Voice for the Sport 41 For the Record 24 Holiday Gift Guide 46 Parting Shot 32 39 Calendar ON THE COVER: Rebecca Soni, 24, is the first woman from the United States to claim back-to-back World Swimmer of the Year honors since Janet Evans (1989-90). -

FINA Champions Swim Series 2019 - Athletes List
Published on fina.org - Official FINA website (//www.fina.org) FINA Champions Swim Series 2019 - Athletes List Updated on: 19.04.2019 Guangzhou (CHN) - Men 50m Freestyle - USA Anthony Ervin - GBR Ben Proud - ITA Andrea Vergani - RUS Vladimir Morozov 100m Freestyle - RUS Vladimir Morozov - BEL Pieter Timmers - RUS Kliment Kolesnikov - RSA Chad Le Clos 200m Freestyle - CHN Sun Yang - RSA Chad Le Clos - LTU Danas Rapsys - CHN Wang Shun 400m Freestyle - ITA Gabriele Detti - CHN Sun Yang - AUS Jack McLoughlin - UKR Mykhailo Romanchuk 50m Backstroke - RUS Kliment Kolesnikov - ROU Robert Glinta - RUS Vladimir Morozov - USA Michael Andrew 100m Backstroke - CHN Xu Jiayu - RUS Kliment Kolesnikov - JPN Ryosuke Irie - ROU Robert Glinta 200m Backstroke - CHN Xu Jiayu - JPN Ryosuke Irie - LTU Danas Rapsys - CHN Li Guangyuan 50m Breaststroke - BRA Joao Gomes Jr - ITA Fabio Scozzoli - BRA Felipe Lima - USA Michael Andrew 100m Breaststroke - RUS Anton Chupkov - NED Arno Kamminga - ITA Fabio Scozzoli - USA Michael Andrew 200m Breaststroke - KAZ Dmitry Balandin - RUS Anton Chupkov - JPN Ippei Watanabe - CHN Qiu Haiyang 50m Butterfly - GBR Ben Proud - BRA Nicholas Santos - UKR Andriy Govorov - USA Michael Andrew 100m Butterfly - RSA Chad Le Clos - RUS Andrei Minakov - USA Michael Andrew - CHN Li Zhuhao 200m Butterfly - JPN Masato Sakai - RSA Chad Le Clos - CHN Li Zhuhao - CHN Wang Zhou 200m Ind. Medley - CHN Wang Shun - CHN Qin Haiyang - USA Michael Andrew - CHN Wang Yizhe Guangzhou (CHN) - Women 50m Freestyle - DEN Pernille Blume - SWE Sarah Sjostrom - NED -
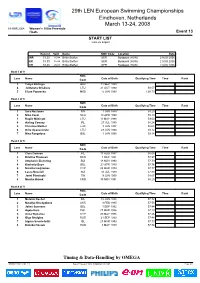
Women's 100M Freestyle Heats Event 13 START LIST Liste De Départ
29th LEN European Swimming Championships Eindhoven, Netherlands March 1324, 2008 19 MAR 2008 Women's 100m Freestyle Heats Event 13 START LIST Liste de départ Record Split Name NOC Code Location Date WR 53.30 25.84 Britta Steffen GER Budapest (HUN) 2 AUG 2006 ER 53.30 25.84 Britta Steffen GER Budapest (HUN) 2 AUG 2006 CR 53.30 25.84 Britta Steffen GER Budapest (HUN) 2 AUG 2006 Heat 1 of 9 NOC Lane Name Date of Birth Qualifying Time Time Rank Code 3 Yuliya Khitraya BLR 11 SEP 1989 4 Jelizaveta Griskova LTU 21 OCT 1990 59.57 5 Elena Popovska MKD 6 JAN 1990 1:00.73 Heat 2 of 9 NOC Lane Name Date of Birth Qualifying Time Time Rank Code 1 Sara Neulanen FIN 1 JAN 1989 59.23 2 Nina Cesar SLO 18 APR 1990 59.13 3 Rugile Mileisyte LTU 11 MAY 1988 59.00 4 Aisling Cooney IRL 27 JUL 1990 58.24 5 Christine Mailliet LUX 9 JAN 1987 58.64 6 Grite Apanaviciute LTU 29 JUN 1990 59.12 7 Nina Rangelova BUL 1 JAN 1990 59.14 Heat 3 of 9 NOC Lane Name Date of Birth Qualifying Time Time Rank Code 1 Clare Dawson IRL 17 AUG 1987 58.08 2 Kristina Thomsen DEN 1 DEC 1991 57.97 3 Stephanie Eisenring SUI 18 NOV 1990 57.79 4 Kimberly Buys BEL 23 APR 1989 57.76 5 Natatlia Hadjiloizou CYP 23 MAR 1979 57.77 6 Laura Noccioli SUI 31 JUL 1989 57.80 7 Jenni Pienimaki FIN 9 JUN 1990 58.07 8 Monika Babok CRO 30 NOV 1991 58.20 Heat 4 of 9 NOC Lane Name Date of Birth Qualifying Time Time Rank Code 1 Melanie Nocher IRL 18 JUN 1988 57.72 2 Nataliya Khudyakova UKR 8 FEB 1985 57.55 3 Jolien Sysmans BEL 1 SEP 1992 57.44 4 Agata Korc POL 27 MAR 1986 57.13 5 Anna Stylianou CYP 20 MAY 1986 -

Wsca Contents
The World Swimming Coaches Association NewsletterVol 08 Issue 4 CONTENTS ASCTA Annual Good Coaches? 2 Good Teachers? Coaches Awards Good Clubs? Coach of the Year Thoughts by Peter Ruddock Stephan Widmer Swimming Records 3 from Beijing Open Water Coach of the Year Olympics Ken Wood Report on the Age Group Coach of the Year 6 ASCA World Clinic Denis Cotterell By Terry Denison Telstra Swimmer with a Disability Coach of the Year Peter Bishop ASCA Coach of the Year Bob Bowman World Swimming Coaches Association 5101 NW 21st Ave., Suite 200 Ft. Lauderdale, FL 33309 USA Phone: 1-954-563-4930 or 1-800-356-2722 Fax: 1-954-563-9813 www.swimmingcoach.org/wsca W SC A World Swimming Coaches Association Good Coaches? Good Teachers? Good Clubs? Thoughts by Peter Ruddock – Australian Swimming Coaches and Teachers Association – Gold Licence Good discipline is one of the characteristics of a good We’ve all been influenced by the notion that quality can teacher. Discipline is not a matter of keeping things under be measured by results, thus we have rankings of clubs and control, it is a matter of helping swimmers learn to make swimmers in order of their results. We have seen state re- good choices and be responsible for those choices, and cords in events down to 8 year old and National rankings helping with their development. Without good discipline to 13 year old and we see many other lists of “top clubs the best planned lessons may fail to have the desired im- and top swimmers.” pact and to promote effective learning. -

Aus Girls Alltime Top 10 Lc to 31 Dec 2008
Australian Girls Alltime Top 10 Long Course to 31st December 2008 email any errors or omissions to [email protected] FINA Female 11 & Under 50 Free 1 28.19 L 665F Jemma Schlicht 11 VIC 1/12/2008 Pacific School Games 2008 S 2 28.36 L 653 PKaitlyn Schnyder 11 VIC 13/04/2005 2005 Brisbane - Australian A 3 28.37 L 653F Kacey Pilgrim 11 NSW 5/02/2005 Brisbane 4 28.39 L 651 FJasmine Paterson 11 WA 8/03/1997 Perth 5 28.44 L 648F Mara Cullen-Barlow 11 QLD 3/03/1990 North Qld 6 28.65 L 634FKate Brennan 11 NSW 20/09/2002 Darwin 7 28.73 L 629F Nicole Chen 11 NSW 1/12/2008 Pacific School Games 2008 S 8 28.77 L 626F Annie Belonogoff 11 QLD 27/03/2004 2004 Sydney - Aus Open 9 28.83 L 622F Bronte Barratt 11 QLD 3/02/2001 Brisbane 10 28.86 L 620P Mikkayla Maselli-Sheridan 11 BS 3/01/2007 2007 Victorian Championship Female 11 & Under 100 Free 1 1:01.12 L 690 FMikkayla Maselli-Sheridan 11 BS 3/01/2007 2007 Victorian Championship 2*F 1:01.24 L 686 Vanessa Puhlmann 11 REDLL 15/12/2007 2007 Zoggs QLD Champions 2*F 1:01.24 L 686 Bonnie MacDonald 11 MIAMI 15/12/2007 2007 Zoggs QLD Champions 4 1:01.60 L 674P Brittany McEvoy 11 MIAMI 9/04/2008 2008 Australian Age Champio 5 1:01.80 L 668FDana Wikaire 11 QLD 12/01/2003 Brisbane 6 1:01.83 L 667F Jenni Burke 11 QLD 7/01/1984 Brisbane 7 1:01.84 L 666 FJasmine Paterson 11 WA 8/03/1997 Perth 8 1:01.98 L 662F Brooke Kelly 11 QLD 12/01/2003 Brisbane 9 1:02.07 L 659FAmy Bannatyne 11 NSW 9/05/2003 Sydney 10 1:02.15 L 656F Leigh Habler 11 NSW 31/03/1988 Brisbane - Aus Age Female 11 & Under 200 Free 1 2:09.36 L 746F -

2016 MEL ZAJAC JR INTERNATIONAL SWIM MEET May 27-29 Page 1/6
THE 53rd ANNUAL 2016 MEL ZAJAC JR INTERNATIONAL SWIM MEET May 27-29 Page 1/6 Sanction • Sanctioned by Swim BC: #19143 Location • UBC Aquatic Centre: 6121 University Blvd., Vancouver, BC V6T 1Z1, Canada • Competition Pool: 50 m - 8 lanes – Omega Electronic Timing Organizing Committee • Meet Director ................................... Tyler Lewall ......................... 604-736-0411 ......... [email protected] • Competition Coordinator…………….Brian Johns.……………….604-822-8903……… [email protected] • Technical & Entries ......................... Rob Traynor ........................ 604-822-8903 ......... [email protected] • Officials Director………………………Graem Luis………………….604-736-0411………[email protected] Entries • Domestic team entries should be submitted to https://www.swimming.ca/MeetList.aspx • Foreign team entries use the same website and select “Province selection --- Out of Country ---“ • The Team Manager Event File will be available at https://www.swimming.ca/MeetList.aspx Entry Fees • Individual Events: CA $105.00 including Provincial Team Splash fee, Relays Events: CA$20.00 per event • Fees must be paid in Canadian funds: cheque, money order or cash. Credit card payments and e-mail money transfers are available, please contact the Meet Director for further information. • Entry fees are due FRIDAY, May 27, 2016 at 08:00 AM PDT and MUST BE PAID PRIOR TO THE COMPETITION. Entry fees should be paid in person or credit card and not sent via postal service • Cheques and Money Orders are payable to “VPSC”. • Time trials may be run time -

2020 U.S. Olympic Team Trials - Swimming 1 Media Guidelines & Information Usaswimming.Org/Trials L @Usaswimming L @Usaswimmingnews L #Swimtrials21
2020 U.S. Olympic Team Trials - Swimming 1 Media Guidelines & Information usaswimming.org/trials l @USASwimming l @USASwimmingNews l #SwimTrials21 Facility Address Media Seating CHI Health Center Omaha USA Swimming will provide seating charts for tabled media in the competition 455 N. 10th Street venue. Overflow (non-tabled) media seating is available in section 102 and 103. Omaha, NE 68102 Seating in the media work room will not be assigned. COVID-19 Guidelines Internet Getty Images All credentialed, on-site media must adhere to the COVID-19 health and safety Wireless internet access will be available throughout the various media work areas. protocols listed at www.usaswimming.org/trials. Media members must receive a Ethernet connections will be available in the Media Seating Area (tables only), 2020 U.S. Olympic Team Trials - Swimming Media Guide COVID-19 PCR test 3-6 days before picking up their credentials in Omaha. select photographer locations and the Media Work Room. usaswimming.org/trials l @USASwimming l @USASwimmingNews l #SwimTrials21 Credentials Photographer Guidelines Competition Details Media credential pick-up will be located at the media entrance of the CHI Health Steven Currie will again serve as the photo chief for the U.S. Olympic Team Trials - Center Omaha. The entrance is located at the back of the building (east side of the Swimming. He will assist and coordinate locations for all photographers in Omaha. Wave I Dates: June 4-7, 2021 building), adjacent to Parking Lot A. This will be the media entrance throughout the Complete guidelines will be distributed to all credentialed photographers prior to Wave II Dates: June 13-20, 2021 me11-1et. -
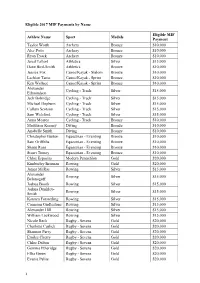
Eligible 2017 MIF Payments by Name Athlete Name
Eligible 2017 MIF Payments by Name Eligible MIF Athlete Name Sport Medals Payment Taylor Worth Archery Bronze $10,000 Alec Potts Archery Bronze $10,000 Ryan Tyack Archery Bronze $10,000 Jared Tallent Athletics Silver $15,000 Dane Bird-Smith Athletics Bronze $10,000 Jessica Fox Canoe/Kayak - Slalom Bronze $10,000 Lachlan Tame Canoe/Kayak - Sprint Bronze $10,000 Ken Wallace Canoe/Kayak - Sprint Bronze $10,000 Alexander Cycling - Track Silver $15,000 Edmondson Jack Bobridge Cycling - Track Silver $15,000 Michael Hepburn Cycling - Track Silver $15,000 Callum Scotson Cycling - Track Silver $15,000 Sam Welsford Cycling - Track Silver $15,000 Anna Meares Cycling - Track Bronze $10,000 Maddison Keeney Diving Bronze $10,000 Anabelle Smith Diving Bronze $10,000 Christopher Burton Equestrian - Eventing Bronze $10,000 Sam Griffiths Equestrian - Eventing Bronze $10,000 Shane Rose Equestrian - Eventing Bronze $10,000 Stuart Tinney Equestrian - Eventing Bronze $10,000 Chloe Esposito Modern Pentathlon Gold $20,000 Kimberley Brennan Rowing Gold $20,000 James McRae Rowing Silver $15,000 Alexander Rowing Silver $15,000 Belonogoff Joshua Booth Rowing Silver $15,000 Joshua Dunkley- Rowing Silver $15,000 Smith Karsten Forsterling Rowing Silver $15,000 Cameron Girdlestone Rowing Silver $15,000 Alexander Hill Rowing Silver $15,000 William Lockwood Rowing Silver $15,000 Nicole Beck Rugby - Sevens Gold $20,000 Charlotte Caslick Rugby - Sevens Gold $20,000 Shannon Parry Rugby - Sevens Gold $20,000 Emilee Cherry Rugby - Sevens Gold $20,000 Chloe Dalton Rugby - Sevens -

ANNUAL REPORT 2008–09 Official Sponsors
s w i m m i n g a u s t r a l i a ANNUAL REPORT 2008–09 OFFICIAL SPONSORS Official broadcaster Supporting organisations Official supplier Official training base SWIMMING AUSTRALIA ANNUAL REPORT 2008–09 | CONTENTS CONTENTS Foreword from the Minister for Sport .......................................................................................................................................................................................................3 Message from Telstra ...................................................................................................................................................................................................................................................4 President’s report .............................................................................................................................................................................................................................................................5 Chief Executive Officer’s report ........................................................................................................................................................................................................................7 Commercial and Communications................................................................................................................................................................................................................................................8 High Performance Operations ..........................................................................................................................................................................................................................................................14