Lab 6 - Networking Monitoring (Linux)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Introduction
Technical report, IDE1202, February 2012 Enhancing Network Security in Linux Environment Master Thesis in Computer Network Engineering By Ali Mohammed, Sachin Sama and Majeed Mohammed School of Information Science, Computer and Electrical Engineering Halmstad University i Enhancing Network Security in Linux Environment Master Thesis in Computer Network Engineering School of Information Science, Computer and Electrical Engineering Halmstad University Box 823, S-301 18 Halmstad, Sweden February 2012 ii Preface First of all, we would like to express our sincere gratitude to our Supervisor Philip Heimer and Professor Tony Larsson for their supervision and assistance in the entire thesis work. We are also thankful to IDE department, Halmstad University for providing this opportunity to complete this thesis. Ali Mohammed Sachin Sama Majeed Mohammed iii iv Abstract Designing a secured network is the most important task in any enterprise or organization development. Securing a network mainly involves applying policies and procedures to protect different network devices from unauthorized access. Servers such as web servers, file servers, mail servers, etc., are the important devices in a network. Therefore, securing these servers is the first and foremost step followed in every security implementation mechanism. To implement this, it is very important to analyse and study the security mechanisms provided by the operating system. This makes it easier for security implementation in a network. This thesis work demonstrates the tasks needed to enhance the network security in Linux environment. The various security modules existing in Linux makes it different from other operating systems. The security measures which are mainly needed to enhance the system security are documented as a baseline for practical implementation. -

Improving Networking
IMPERIAL COLLEGE LONDON FINALYEARPROJECT JUNE 14, 2010 Improving Networking by moving the network stack to userspace Author: Matthew WHITWORTH Supervisor: Dr. Naranker DULAY 2 Abstract In our modern, networked world the software, protocols and algorithms involved in communication are among some of the most critical parts of an operating system. The core communication software in most modern systems is the network stack, but its basic monolithic design and functioning has remained unchanged for decades. Here we present an adaptable user-space network stack, as an addition to my operating system Whitix. The ideas and concepts presented in this report, however, are applicable to any mainstream operating system. We show how re-imagining the whole architecture of networking in a modern operating system offers numerous benefits for stack-application interactivity, protocol extensibility, and improvements in network throughput and latency. 3 4 Acknowledgements I would like to thank Naranker Dulay for supervising me during the course of this project. His time spent offering constructive feedback about the progress of the project is very much appreciated. I would also like to thank my family and friends for their support, and also anybody who has contributed to Whitix in the past or offered encouragement with the project. 5 6 Contents 1 Introduction 11 1.1 Motivation.................................... 11 1.1.1 Adaptability and interactivity.................... 11 1.1.2 Multiprocessor systems and locking................ 12 1.1.3 Cache performance.......................... 14 1.2 Whitix....................................... 14 1.3 Outline...................................... 15 2 Hardware and the LDL 17 2.1 Architectural overview............................. 17 2.2 Network drivers................................. 18 2.2.1 Driver and device setup....................... -

ENT-UG1060 User Guide Software API Programming
ENT-UG1060 User Guide Software API Programming Microsemi Corporation (Nasdaq: MSCC) offers a comprehensive portfolio of semiconductor and system solutions for communications, defense & security, aerospace and industrial markets. Products include high-performance and radiation-hardened analog mixed-signal integrated circuits, FPGAs, SoCs and ASICs; power management products; timing and synchronization devices and precise time solutions, setting the world's standard for time; voice processing devices; RF solutions; discrete components; security technologies and scalable anti-tamper products; Ethernet solutions; Power-over-Ethernet ICs and midspans; as well as custom design capabilities and services. Microsemi is headquartered in Aliso Viejo, Calif, and has approximately 3,600 employees globally. Learn more at www.microsemi.com. Microsemi Corporate Headquarters Microsemi makes no warranty, representation, or guarantee regarding the information contained herein or One Enterprise, Aliso Viejo, the suitability of its products and services for any particular purpose, nor does Microsemi assume any CA 92656 USA liability whatsoever arising out of the application or use of any product or circuit. The products sold hereunder and any other products sold by Microsemi have been subject to limited testing and should not Within the USA: +1 (800) 713-4113 be used in conjunction with mission-critical equipment or applications. Any performance specifications are Outside the USA: +1 (949) 380-6100 believed to be reliable but are not verified, and Buyer must conduct and complete all performance and Sales: +1 (949) 380-6136 other testing of the products, alone and together with, or installed in, any end-products. Buyer shall not rely Fax: +1 (949) 215-4996 on any data and performance specifications or parameters provided by Microsemi. -

Network Forensics: Following the Digital Trail in a Virtual Environment
Network Forensics: Following the Digital Trail in a Virtual Environment Master of Science Thesis in the Programme: Networks & Distributed Systems KONSTANTINOS SAMALEKAS Chalmers University of Technology University of Gothenburg Department of Computer Science and Engineering Göteborg, Sweden, October 2010 The Author grants to Chalmers University of Technology and University of Gothenburg the non-exclusive right to publish the Work electronically and in a non-commercial purpose make it accessible on the Internet. The Author warrants that he is the author to the Work, and warrants that the Work does not contain text, pictures or other material that violates copyright law. The Author shall, when transferring the rights of the Work to a third party (for example a publisher or a company), acknowledge the third party about this agreement. If the Author has signed a copyright agreement with a third party regarding the Work, the Author warrants hereby that he has obtained any necessary permission from this third party to let Chalmers University of Technology and University of Gothenburg store the Work electronically and make it accessible on the Internet. Network Forensics: Following the Digital Trail in a Virtual Environment KONSTANTINOS SAMALEKAS © KONSTANTINOS SAMALEKAS, October 2010. Examiner: ARNE LINDE Chalmers University of Technology University of Gothenburg Department of Computer Science and Engineering SE-412 96 Göteborg Sweden Telephone + 46 (0)31-772 1000 Department of Computer Science and Engineering Göteborg, Sweden, October 2010 ABSTRACT The objective of this project is to examine all important aspects of network forensics, and apply incident response methods and investigation tech- niques in practice. The subject is twofold and begins by introducing the reader to the major network forensic topics. -

SUSE Linux Enterprise Server 11 SP4 System Analysis and Tuning Guide System Analysis and Tuning Guide SUSE Linux Enterprise Server 11 SP4
SUSE Linux Enterprise Server 11 SP4 System Analysis and Tuning Guide System Analysis and Tuning Guide SUSE Linux Enterprise Server 11 SP4 Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see http://www.suse.com/company/legal/ . All other third party trademarks are the property of their respective owners. A trademark symbol (®, ™ etc.) denotes a SUSE or Novell trademark; an asterisk (*) denotes a third party trademark. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents About This Guide xi 1 Available Documentation xii 2 Feedback xiv 3 Documentation Conventions xv I BASICS 1 1 General Notes on System Tuning 2 1.1 Be Sure What Problem to Solve 2 1.2 Rule Out Common Problems 3 1.3 Finding the Bottleneck 3 1.4 Step-by-step Tuning 4 II SYSTEM MONITORING 5 2 System Monitoring Utilities 6 2.1 Multi-Purpose Tools 6 vmstat 7 -
![Internet Security [1] VU 184.216](https://docslib.b-cdn.net/cover/2487/internet-security-1-vu-184-216-972487.webp)
Internet Security [1] VU 184.216
Internet Security [1] VU 184.216 Engin Kirda [email protected] Christopher Kruegel [email protected] The Internet Host Host Internet Host Subnet Host Subnet Host Host Subnet PPP (phone) Internet Security 1 2 Direct IP delivery • If two hosts are in the same physical network the IP datagram is encapsulated and delivered directly Host 1 Host 2 Host 3 (192.168.0.2) (192.168.0.3) (192.168.0.5) Host 4 Host 5 Host 6 (192.168.0.81) (192.168.0.99) (192.168.0.7) Internet Security 1 3 Ethernet dest (48 bits) src (48 bits) type (16) data CRC (32) 0x0800 IP Datagram Internet Security 1 4 Ethernet • Widely used link layer protocol • Carrier Sense, Multiple Access, Collision Detection • Addresses: 48 bits (e.g. 00:38:af:23:34:0f), mostly – hardwired by the manufacturer • Type (2 bytes): specifies encapsulated protocol – IP, ARP, RARP • Data: – min. 46 bytes payload (padding may be needed), max 1500 bytes • CRC (4 bytes) Internet Security 1 5 Direct IP delivery Problem: • Ethernet uses 48 bit addresses • IP uses 32 bit addresses • we want to send an IP datagram • but we only can use the Link Layer to do this Internet Security 1 6 ARP ARP (Address Resolution Protocol) • Service at the link-level, RFC 826 • maps network-addresses to link-level addresses • Host A wants to know the hardware address associated with IP address of host B • A broadcasts ARP message on physical link – including its own mapping • B answers A with ARP answer message • Mappings are cached: arp -a shows mapping Internet Security 1 7 RARP RARP (Reverse Address Resolution -

DESIGN of an AUTONOMOUS ANTI-DDOS NETWORK (A2D2) By
DESIGN OF AN AUTONOMOUS ANTI-DDOS NETWORK (A2D2) by ANGELA CEARNS, B.A. University of Western Ontario, London, Ontario, Canada, 1995 A Thesis Submitted to the Faculty of Graduate School of the University of Colorado at Colorado Springs in Partial Fulfillment of the Requirements for the Degree of Master of Engineering Department of Computer Science 2002 ii Ó Copyright By Angela Cearns 2002 All Rights Reserved iii This thesis for the Master of Engineering degree by Angela Cearns has been approved for the Department of Computer Science by _______________________________________________________ Advisor: Dr. C. Edward Chow _______________________________________________________ Dr. Jugal K. Kalita _______________________________________________________ Dr. Charles M. Shub Date iv Design of an Autonomous Anti-DDoS Network (A2D2) by Angela Cearns (Master of Engineering, Software Engineering) Thesis directed by Associate Professor C. Edward Chow Department of Computer Science Abstract Recent threats of Distributed Denial of Service attacks (DDoS) are mainly directed at home and small to medium sized networks that lack the incentive, expertise, and financial means to defend themselves. Using the Evolutionary Software Life-Cycle model, this thesis designs an Autonomous Anti-DDoS Network (A2D2) that integrates and improves on existing DDoS mitigation technologies. A2D2 provides an affordable and manageable solution to small and medium networks, and enables small office and home office (SOHO) networks to take control of their own defense within their own network boundary. Test-bed results show that A2D2 is highly effective in ensuring Quality of Service (QoS) during bandwidth consumption DDoS attacks. The A2D2 test-bed has demonstrated significant intrusion tolerance against attacks of various types, including UDP, ICMP and TCP based DDoS attacks. -

Traceroute Applica�On Layer
Advanced Linux System Administraon Topic 11. Network administraon (Introducon). Pablo Abad Fidalgo José Ángel Herrero Velasco Departamento de Ingeniería Informáca y Electrónica Este tema se publica bajo Licencia: Creave Commons BY-NC-SA 4.0 Index • Introduc,on (TCP/IP). • Network Interface. • Link Layer. • Network Layer. • Monitoring/Test. Introduc,on (TCP/IP) • Protocol “Suite”, a set of protocols designed to implement interconnec7on networks: – Origin: research project of the USA defense department (ARPANET). • Mul7ple components, arranged hierarchically (stack). arp ssh, hp Gaming traceroute Applicaon Layer TCP UDP Transport Layer IP ICMP Network Layer ARP, drivers Link Layer Copper, fiber, wireless Physical Layer Introduc,on (TCP/IP) • Protocol “Suite”, a set of protocols designed to implement interconnec7on networks: – Origin: research project of the USA defense department (ARPANET). • Mul7ple components, arranged hierarchically (stack): – UDP, User Datagram Protocol, unverified, one-way data delivery. – TCP, Transmission Control Protocol, reliable, full duplex, flow controlled, error corrected conversaons. – IP, the Internet Protocol, routes data packets from one machine to another. – ICMP, the Internet Control Message Protocol, provides low level support for IP: error messages, rou7ng assistance, debugging. – ARP, Address Resolu7on Protocol, translates IP addresses into HW address (MAC). Introduc,on (TCP/IP) • Encapsulaon: – Data travels on the network in the form of packets, bursts of data with a maximum length imposed by the link layer. – Each packet consists of a header and a payload: • Header: includes Source-Des7naon and protocol informaon. • Payload: the informaon (Data). – As a packet travels down the TCP/IP protocol stack, each protocol adds its own header informaon. Ethernet Header IP Header UDP Header Applicaon Data CRC Eth. -

Linux System Management for the Mainframe Systems Programmer
Linux System Management for the Mainframe Systems Programmer Mark Post Novell, Inc. Thursday, August 14, 2008 9224/9225 Agenda · Cultural Differences & Similarities · Terminology · How Does Linux/390 Compare to Unix System Services? · How Does Linux/390 Compare to Other Linux platforms? · What is a Distribution, and why doesn't IBM have one? · What Hardware Does Linux/390 Support? · What Networking Connections Does Linux/390 Support? · Where’s SYS1.PARMLIB Kept? · Do I Really Have to Know All This Stuff? 2 Agenda (2) · Linux/390 DASD Management · Backup and Restore · Software and Maintenance Management · Data Sharing with Linux/390 and Other OS · Job Scheduling · Security and User Management · Diagnostic Information Available (or not) · Editors · Basic vi Concepts 3 Agenda (3) · Scripting Languages · System Logs · Basic Commands · Advanced Commands · Kernel Modules, Loading and Unloading · System Startup and Shutdown · Performance Management · Creating Additional Images · Questions? 4 Agenda (4) · Additional Information Resources · Web sites, Redbooks/pieces/tips, Usenet (news), O’Reilly Books · Command Comparisons 5 Cultural Differences & Similarities · Open Source Community · Think of how many people you know from IBMMAIN or IBMVM · Open Source software · Software quality · Where and how you get support · Expectations of self-reliance · 3270 terminals vs. VTxxx. · Is rebooting unnecessarily a sin? · Install Linux on a PC and use it. 6 Terminology · IPL · boot · nucleus · kernel · PLPA / LINKLIST · kernel modules · TSO / CMS · shell · -

A Scalable Architecture for Network Traffic Monitoring and Analysis Using Free Open Source Software
Int. J. Communications, Network and System Sciences, 2009, 6, 528-539 doi:10.4236/ijcns.2009.26058 Published Online September 2009 (http://www.SciRP.org/journal/ijcns/). A Scalable Architecture for Network Traffic Monitoring and Analysis Using Free Open Source Software Olatunde ABIONA1, Temitope ALADESANMI2, Clement ONIME3, Adeniran OLUWARANTI4, Ayodeji OLUWATOPE5, Olakanmi ADEWARA6, Tricha ANJALI7, Lawrence KEHINDE8 1Department of Computer Information Systems, Indiana University Northwest, Garry, USA 2,6 Information Technology and Communications Unit, Obafemi Awolowo University, Nigeria 3Information and Communication Technology Section, Abdus Salam International Centre for Theoretical Physics, Trieste, Italy 4,5 Department of Computer Science and Engineering, Obafemi Awolowo University, Ile-Ife, Nigeria 7Electrical and Computer Engineering Department, Illinois Institute of Technology, Chicago, USA 8Department of Engineering Technologies, Texas Southern University, Houston, Texas, USA Email: [email protected], {2taladesanmi,4aranti,5aoluwato,6kanmiade}@oauife.edu.ng, [email protected], [email protected], [email protected] Received February 5, 2009; revised April 8, 2009; accepted June 10, 2009 ABSTRACT The lack of current network dynamics studies that evaluate the effects of new application and protocol de- ployment or long-term studies that observe the effect of incremental changes on the Internet, and the change in the overall stability of the Internet under various conditions and threats has made network monitoring challenging. A good understanding of the nature and type of network traffic is the key to solving congestion problems. In this paper we describe the architecture and implementation of a scalable network traffic moni- toring and analysis system. The gigabit interface on the monitoring system was configured to capture net- work traffic and the Multi Router Traffic Grapher (MRTG) and Webalizer produces graphical and detailed traffic analysis. -

Tuning Linux OS on IBM System P the POWER of Innovation June 2007
Front cover Tuning Linux OS on System p The POWER of Innovation Linux kernel tuning DB2, WebSphere, and Oracle tuning SystemTap examples Stephen Hochstetler Kraml Liu Andre Metelo Prasanna S Panchamukhi John Zucker ibm.com/redbooks International Technical Support Organization Tuning Linux OS on IBM System p The POWER of Innovation June 2007 SG24-7338-00 Note: Before using this information and the product it supports, read the information in “Notices” on page ix. First Edition (June 2007) This edition applies to Red Hat Enterprise Linux AS 4 and SUSE Linux Enterprise Server 10. © Copyright International Business Machines Corporation 2007. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . ix Trademarks . x Preface . xi The team that wrote this book . xi Become a published author . xiv Comments welcome. xv Chapter 1. Introduction to the book. 1 1.1 Operating an efficient server: four phase . 2 1.2 Performance tuning guidelines . 3 1.3 Using information from the System p Performance Lab . 3 1.4 Linux Technology Center . 5 1.5 Understanding the organization of this book . 5 Chapter 2. IBM System p hardware . 7 2.1 System p advantages . 8 2.1.1 Performance . 8 2.1.2 Scalability . 9 2.1.3 Reliability, availability, and serviceability. 11 2.1.4 Manageability . 13 2.1.5 Virtualization . 14 2.2 System p product line introduction . 15 2.2.1 POWER servers . 16 2.2.2 PowerPC servers and blades . 23 2.2.3 IntelliStation. -
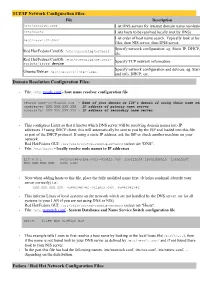
TCP/IP Network Configuration Files: Domain Resolution Configuration
TCP/IP Network Configuration Files: File Description /etc/resolve.conf List DNS servers for internet domain name resolution /etc/hosts Lists hosts to be resolved locally (not by DNS) List order of host name search. Typically look at local /etc/nsswitch.conf files, then NIS server, then DNS server. Specify network configuration. eg. Static IP, DHCP, NIS, Red Hat/Fedora/CentOS: /etc/sysconfig/network etc. Red Hat/Fedora/CentOS: /etc/sysconfig/network- Specify TCP network information. scripts/ifcfg-device Specify network configuration and devices. eg. Static IP Ubuntu/Debian: /etc/network/interfaces and info, DHCP, etc. Domain Resolution Configuration Files: • File: /etc/resolv.conf - host name resolver configuration file search name-of-domain.com - Name of your domain or ISP's domain if using their name server nameserver XXX.XXX.XXX.XXX - IP address of primary name server nameserver XXX.XXX.XXX.XXX - IP address of secondary name server • This configures Linux so that it knows which DNS server will be resolving domain names into IP addresses. If using DHCP client, this will automatically be sent to you by the ISP and loaded into this file as part of the DHCP protocol. If using a static IP address, ask the ISP or check another machine on your network. Red Hat/Fedora GUI: /usr/sbin/system-config-network (select tab "DNS". • File: /etc/hosts - locally resolve node names to IP addresses 127.0.0.1 your-node-name.your-domain.com localhost.localdomain localhost XXX.XXX.XXX.XXX node-name • Note when adding hosts to this file, place the fully qualified name first.