A Sliding Window Technique for Interactive High-Performance Computing Scenarios
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PC Literacy II
Computer classes at The Library East Brunswick Public Library PC Literacy II Common Window Elements Most windows have common features, so once you become familiar with one program, you can use that knowledge in another program. Double-click the Internet Explorer icon on the desktop to start the program. Locate the following items on the computer screen. • Title bar: The top bar of a window displaying the title of the program and the document. • Menu bar: The bar containing names of menus, located below the title bar. You can use the menus on the menu bar to access many of the tools available in a program by clicking on a word in the menu bar. • Minimize button: The left button in the upper-right corner of a window used to minimize a program window. A minimized program remains open, but is visible only as a button on the taskbar. • Resize button: The middle button in the upper-right corner of a window used to resize a program window. If a program window is full-screen size it fills the entire screen and the Restore Down button is displayed. You can use the Restore Down button to reduce the size of a program window. If a program window is less than full-screen size, the Maximize button is displayed. You can use the Maximize button to enlarge a program window to full-screen size. • Close button: The right button in the upper-right corner of a window used to quit a program or close a document window – the X • Scroll bars: A vertical bar on the side of a window and a horizontal bar at the bottom of the window are used to move around in a document. -

Spot-Tracking Lens: a Zoomable User Interface for Animated Bubble Charts
Spot-Tracking Lens: A Zoomable User Interface for Animated Bubble Charts Yueqi Hu, Tom Polk, Jing Yang ∗ Ye Zhao y Shixia Liu z University of North Carolina at Charlotte Kent State University Tshinghua University Figure 1: A screenshot of the spot-tracking lens. The lens is following Belarus in the year 1995. Egypt, Syria, and Tunisia are automatically labeled since they move faster than Belarus. Ukraine and Russia are tracked. They are visible even when they go out of the spotlight. The color coding of countries is the same as in Gapminder[1], in which countries from the same geographic region share the same color. The world map on the top right corner provides a legend of the colors. ABSTRACT thus see more details. Zooming brings many benefits to visualiza- Zoomable user interfaces are widely used in static visualizations tion: it allows users to examine the context of an interesting object and have many benefits. However, they are not well supported in by zooming in the area where the object resides; labels overcrowded animated visualizations due to problems such as change blindness in the original view can be displayed without overlaps after zoom- and information overload. We propose the spot-tracking lens, a new ing in; it allows users to focus on a local area and thus reduce their zoomable user interface for animated bubble charts, to tackle these cognitive load. problems. It couples zooming with automatic panning and provides In spite of these benefits, zooming is not as well supported in an- a rich set of auxiliary techniques to enhance its effectiveness. -

Organizing Windows Desktop/Workspace
Organizing Windows Desktop/Workspace Instructions Below are the different places in Windows that you may want to customize. On your lab computer, go ahead and set up the environment in different ways to see how you’d like to customize your work computer. Start Menu and Taskbar ● Size: Click on the Start Icon (bottom left). As you move your mouse to the edges of the Start Menu window, your mouse icon will change to the resize icons . Click and drag the mouse to the desired Start Menu size. ● Open Start Menu, and “Pin” apps to the Start Menu/Taskbar by finding them in the list, right-clicking the app, and select “Pin to Start” or “More-> “Pin to Taskbar” OR click and drag the icon to the Tiles section. ● Drop “Tiles” on top of each other to create folders of apps. ● Right-click on Tiles (for example the Weather Tile), and you can resize the Tile (maybe for apps you use more often), and also Turn On live tiles to get updates automatically in the Tile (not for all Tiles) ● Right-click applications in the Taskbar to view “jump lists” for certain applications, which can show recently used documents, visited websites, or other application options. ● If you prefer using the keyboard for opening apps, you probably won’t need to customize the start menu. Simply hit the Windows Key and start typing the name of the application to open, then hit enter when it is highlighted. As the same searches happen, the most used apps will show up as the first selection. -

Using Microsoft Visual Studio to Create a Graphical User Interface ECE 480: Design Team 11
Using Microsoft Visual Studio to Create a Graphical User Interface ECE 480: Design Team 11 Application Note Joshua Folks April 3, 2015 Abstract: Software Application programming involves the concept of human-computer interaction and in this area of the program, a graphical user interface is very important. Visual widgets such as checkboxes and buttons are used to manipulate information to simulate interactions with the program. A well-designed GUI gives a flexible structure where the interface is independent from, but directly connected to the application functionality. This quality is directly proportional to the user friendliness of the application. This note will briefly explain how to properly create a Graphical User Interface (GUI) while ensuring that the user friendliness and the functionality of the application are maintained at a high standard. 1 | P a g e Table of Contents Abstract…………..…………………………………………………………………………………………………………………………1 Introduction….……………………………………………………………………………………………………………………………3 Operation….………………………………………………….……………………………………………………………………………3 Operation….………………………………………………….……………………………………………………………………………3 Visual Studio Methods.…..…………………………….……………………………………………………………………………4 Interface Types………….…..…………………………….……………………………………………………………………………6 Understanding Variables..…………………………….……………………………………………………………………………7 Final Forms…………………....…………………………….……………………………………………………………………………7 Conclusion.…………………....…………………………….……………………………………………………………………………8 2 | P a g e Key Words: Interface, GUI, IDE Introduction: Establishing a connection between -

Widget Toolkit – Getting Started
APPLICATION NOTE Atmel AVR1614: Widget Toolkit – Getting Started Atmel Microcontrollers Prerequisites • Required knowledge • Basic knowledge of microcontrollers and the C programming language • Software prerequisites • Atmel® Studio 6 • Atmel Software Framework 3.3.0 or later • Hardware prerequisites • mXT143E Xplained evaluation board • Xplained series MCU evaluation board • Programmer/debugger: • Atmel AVR® JTAGICE 3 • Atmel AVR Dragon™ • Atmel AVR JTAGICE mkll • Atmel AVR ONE! • Estimated completion time • 2 hours Introduction The aim of this document is to introduce the Window system and Widget toolkit (WTK) which is distributed with the Atmel Software Framework. This application note is organized as a training which will go through: • The basics of setting up graphical widgets on a screen to make a graphical user interface (GUI) • How to get feedback when a user has interacted with a widget • How to draw custom graphical elements on the screen 8300B−AVR−07/2012 Table of Contents 1. Introduction to the Window system and widget toolkit ......................... 3 1.1 Overview ........................................................................................................... 3 1.2 The Window system .......................................................................................... 4 1.3 Event handling .................................................................................................. 5 1.3.2 The draw event ................................................................................... 6 1.4 The Widget -

Beyond the Desktop: a New Look at the Pad Metaphor for Information Organization
Beyond the Desktop: A new look at the Pad metaphor for Information Organization By Isaac Fehr Abstract Digital User interface design is currently dominated by the windows metaphor. However, alternatives for this metaphor, as the core of large user interfaces have been proposed in the history of Human-computer interaction and thoroughly explored. One of these is the Pad metaphor, which has spawned many examples such as Pad++. While the the Pad metaphor, implemented as zoomable user interfaces, has shown some serious drawbacks as the basis for an operating system, and limited success outside of image-based environments, literature has pointed to an opportunity for innovation in other domains. In this study, we apply the the design and interactions of a ZUI to Wikipedia, a platform consisting mostly of lengthy, linear, hypertext-based documents. We utilize a human centered design approach, and create an alternative, ZUI-based interface for Wikipedia, and observe the use by real users using mixed methods. These methods include qualitative user research, as well as a novel paradigm used to measure a user’s comprehension of the structure of a document. We validate some assumptions about the strengths of ZUIs in a new domain, and look forward to future research questions and methods. Introduction and Background Windows-based user interfaces have dominated the market of multipurpose, screen-based computers since the introduction of the first windowed system in the Stanford oN-Line System (NLS)[3]. From Desktop computers to smartphones, most popular operating systems are based upon at least the window and icon aspects of the WIMP (Window, Icon, Menu, Pointer) paradigm. -
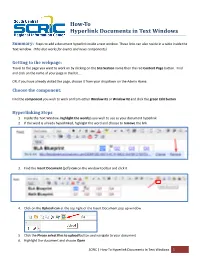
How to Hyperlink Documents in Text Windows
How-To Hyperlink Documents in Text Windows Summary: Steps to add a document hyperlink inside a text window. These links can also reside in a table inside the Text window. (This also works for events and news components). Getting to the webpage: Travel to the page you want to work on by clicking on the Site Section name then the red Content Page button. Find and click on the name of your page in the list….. OR, if you have already visited the page, choose it from your dropdown on the Admin Home. Choose the component: Find the component you wish to work on from either Window #1 or Window #2 and click the green Edit button Hyperlinking Steps 1. Inside the Text Window, highlight the word(s) you wish to use as your document hyperlink 2. If the word is already hyperlinked, highlight the word and choose to remove the link 3. Find the Insert Document (pdf) icon on the window toolbar and click it 4. Click on the Upload icon at the top right of the Insert Document pop up window 5. Click the Please select files to upload button and navigate to your document 6. Highlight the document and choose Open SCRIC | How-To Hyperlink Documents In Text Windows 1 7. You will now see your document at the top of the Insert Document pop up window. 8. You can choose here to have the document open in a new window if you like by clicking on the dropdown called Target (it will open in a new window when viewers click on the document hyperlink) 9. -
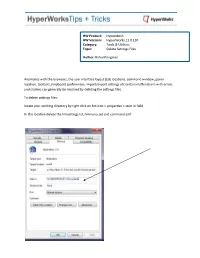
Tab Locations, Command Window, Panel Location, Toolbars
HW Product: HyperMesh HW Version: HyperWorks 11.0.130 Category: Tools & Utilities Topic: Delete Settings Files Author: Rahul Ponginan Anomalies with the browsers, the user interface layout (tab locations, command window, panel location, toolbars,) keyboard preferences, import/export settings etc certain malfunctions with errors and crashes can generally be resolved by deleting the settings files. To delete settings files- locate your working directory by right click on hm icon > properties > start in field In this location delete the hmsettings.tcl, hmmenu.set and command.cmf The following problems in HyperMesh have been successfully fixed by deleting the settings files. Entities missing Radio buttons missing in panel area Buttons missing in panel area Toolbar icons missing Utility menu is blank, browser has icons missing Status bar is missing Errors Can’t set hm framework minibar Segmentation error when user starts hm Fatal menu system error hmmenu.set has one or more fatal errors Menu system corrupted: menu itemgroup : get pointer Only a single create/edit window supported at a time, do you want to close current window before proceeding “Node command is out of sequence" while importing .fem file "Nodes already exist in the model" while converting Trias to tetras selection Unable to select lines and points from the graphics area, Unable to select elements, Entities do not change colour on being selected While selecting a node adjacent node gets selected. Unable to choose coincident nodes in the model. When user tries to choose one of the nodes at a particular location it does not show the option of picking one of the two or more nodes. -
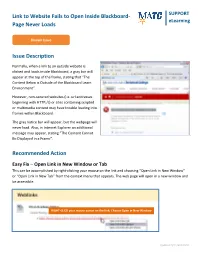
Link to Website Fails to Open Inside Blackboard- Page Never Loads Issue Description Recommended Action
Link to Website Fails to Open Inside Blackboard- SUPPORT eLearning Page Never Loads Known Issue Issue Description Normally, when a link to an outside website is clicked and loads inside Blackboard, a gray bar will appear at the top of the frame, stating that “The Content Below is Outside of the Blackboard Learn Environment”. However, non-secured websites (i.e. url addresses beginning with HTTP://) or sites containing scripted or multimedia content may have trouble loading into frames within Blackboard. The gray notice bar will appear, but the webpage will never load. Also, in Internet Explorer an additional message may appear, stating “The Content Cannot Be Displayed in a Frame”. Recommended Action Easy Fix – Open Link in New Window or Tab This can be accomplished by right-clicking your mouse on the link and choosing “Open Link in New Window” or “Open Link in New Tab” from the context menu that appears. The web page will open in a new window and be accessible. RIGHT-CLICK your mouse cursor on the link; Choose Open in New Window Updated 9/11/2013 MH Best Practice Fix – Create or Edit the Link to Open in New Window Automatically Links created through Blackboard’s Web link tool are easier to create and modify than links added to the text of a Blackboard Item. When creating or editing a link to your course, be sure to set the link to open in a new window. This will help ensure that the website is easily accessible in any browser going forwards. These instructions assume that you have EDIT MODE turned on in your course. -
Introduction to Computers
Introduction to Computers 2 BASIC MOUSE FUNCTIONS To use Windows, you will need to operate the mouse properly. POINT: Move the mouse until the pointer rests on what you want to open or use on the screen. The form of the mouse will change depending on what you are asking it to look at in Windows, so you need to be aware of what it looks like before you click. SINGLE-CLICK: The left mouse button is used to indicate choices from menus and indicate choices of options within a “dialog box” while you are working in an application program. Roll the mouse pointer on top of the choice and press the left mouse button once. RIGHT-CLICK: With a single quick press on the right mouse button, it will bring up a shortcut menu, which will contain specific options depending on where the right-click occurred. CLICK AND DRAG: This is used for a number of functions including choosing text to format, moving items around the screen, and choosing options from menu bars. Roll the mouse pointer over the item, click and hold down the left mouse button, and drag the mouse while still holding the button until you get to the desired position on the screen. Then release the mouse button. DOUBLE-CLICK: This is used to choose an application program. Roll the mouse pointer on top of the icon (picture on the desktop or within a window) of the application program you want to choose and press the left mouse button twice very rapidly. This should bring you to the window with the icons for that software package. -

Managing the Mosaic Interface (IB Mosaic Cheat Sheet) Interactive Brokers
Managing the Mosaic Interface (IB Mosaic Cheat Sheet) Interactive Brokers A 2 3 1 D 6 C 5 B 4 D 6 6 E 7 8 A. Dashboard D. Monitor/Activity 1. Font - Click to open the Font Size Adjustment box. In- 6. Add Tabs – Click the “+” sign to add a new tab to a crease or decrease font size across the Mosaic. window when that function is available. The “+” sign changes to and up/down arrow when more tabs than 2. Edit – Add, remove and rearrange windows and tools in shown are available. a workspace by clicking the “Lock” icon. When you see a green outline around the entire frame, the workspace Hold your mouse over a visible tab to see the remaining is editable. Click the “Lock” icon again to secure your hidden tabs. changes. The up/down arrow has the same “add a new tab” func- 3. Pin on Top – Use the pushpin icon to keep the interface tion as the “+” sign. on top of all desktop applications. E. Workspaces B. Charts 7. Switching Workspaces - Easily switch between the 4. Link by Color – Click the chain link icon to use the drop- Mosaic and Classic TWS layouts by clicking the appropri- down list. Every window linked by the same colored ate workspace tab along the bottom frame. Create your chain link will reflect the selected underlying. own custom workspace by clicking the “+” tab. 8. Custom Workspaces – Add new workspaces by clicking C. Quote Details the “+” icon along the bottom of the workspace frame. 5. Underlying in Blade – Many windows allow you to select or enter the underlying directly in the titlebar, or blade, of that window. -

Window Behavior
Window Behavior Mike McBride Jost Schenck Window Behavior 2 Window Behavior Contents 1 Window Behavior4 1.1 Focus . .4 1.1.1 Windows activation policy . .4 1.1.2 Focus stealing prevention . .5 1.1.3 Raising window . .5 1.2 Titlebar Actions . .6 1.2.1 Double-click . .6 1.2.2 Titlebar and Frame Actions ............................6 1.2.3 Maximize Button Actions .............................7 1.3 Window Actions . .7 1.3.1 Inactive Inner Window ..............................7 1.3.2 Inner Window, Titlebar and Frame .......................8 1.4 Movement . .8 1.4.1 Window geometry .................................8 1.4.2 Snap Zones .....................................8 1.5 Advanced . .9 3 Window Behavior 1 Window Behavior In the upper part of this control module you can see several tabs: Focus, Titlebar Actions, Win- dow Actions, Movement and Advanced. In the Focus panel you can configure how windows gain or lose focus, i.e. become active or inactive. Using Titlebar Actions and Window Actions you can configure how titlebars and windows react to mouse clicks. Movement allows you to configure how windows move and place themselves when started. The Advanced options cover some specialized options like ‘window shading’. NOTE Please note that the configuration in this module will not take effect if you do not use Plasma’s native window manager, KWin. If you do use a different window manager, please refer to its documentation for how to customize window behavior. 1.1 Focus The ‘focus’ of the desktop refers to the window which the user is currently working on. The window with focus is often referred to as the ‘active window’.