JFLAP Activities for Formal Languages and Automata
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nooj Computational Devices Max Silberztein
NooJ Computational Devices Max Silberztein To cite this version: Max Silberztein. NooJ Computational Devices. Formalising Natural Languages With NooJ, Jun 2012, Paris, France. hal-02435921 HAL Id: hal-02435921 https://hal.archives-ouvertes.fr/hal-02435921 Submitted on 11 Jan 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. NOOJ COMPUTATIONAL DEVICES MAX SILBERZTEIN Introduction NooJ’s linguistic development environment provides tools for linguists to construct linguistic resources that formalize 7 types of linguistic phenomena: typography, orthography, inflectional and derivational morphology, local and structural syntax, and semantics. NooJ also provides a set of parsers that can process any linguistic resource for these 7 types, and apply it to any corpus of texts in order to extract examples, annotate matching sequences, perform statistical analyses, etc.1 NooJ’s approach to Linguistics is peculiar in the world of Computational Linguistics: instead of constructing a large single grammar to describe a particular natural language (e.g. “a grammar of English”), NooJ users typically construct, edit, test and maintain a large number of local (small) grammars; for instance, there is a grammar that describes how to conjugate the verb to be, another grammar that describes how to state a date in English, another grammar that describes the heads of Noun Phrases, etc. -

Implementation of Recursively Enumerable Languages Using Universal Turing Machine in JFLAP
International Journal of Information and Computation Technology. ISSN 0974-2239 Volume 4, Number 1 (2014), pp. 79-84 © International Research Publications House http://www. irphouse.com /ijict.htm Implementation of Recursively Enumerable Languages using Universal Turing Machine in JFLAP Ankur Singh1 and Jainendra Singh2 1Department of Computer Science, IEC College of Engineering, Greater Noida, INDIA. 2 Department of Computer Science, Maharaja Surajmal Institute, C-4, Janakpuri, New Delhi, INDIA. Abstract This paper presents the implementation of recursively enumerable language using Universal Turing machine for JFLAP platform. Automata play a major role in compiler design and parsing. The class of formal languages that work for the most complex problems belongs to the set of Recursively Enumerable Language (REL).RELs are accepted by the type of automata as Turing Machine. Turing Machines are the most powerful computational machines and are the theoretical basis for modern computers. Turing Machine works for all classes of languages including regular language, Context Free Languages as well as Recursive Enumerable Languages. Still it is a tedious task to create and maintain Turing Machines for all problems. The Universal Turing Machine (UTM) is a solution to this problem. A UTM simulates any other TM, thus providing a single model and solution for all the computational problems. Universal Turing Machine is used to implementation of RELs for JFLAP platform. JFLAP is most successful and widely used tool for visualizing and simulating all types of automata. Keywords: Automata; Compiler; Turing Machine; TM; JFLAP; PDA. 1. Introduction An automaton is a mathematical model for a finite state machine (FSM). A FSM is a machine that has a set of input symbols and transitions and jumps through a series of states according to a transition function. -

The Earley Algorithm Is to Avoid This, by Only Building Constituents That Are Compatible with the Input Read So Far
Earley Parsing Informatics 2A: Lecture 21 Shay Cohen 3 November 2017 1 / 31 1 The CYK chart as a graph What's wrong with CYK Adding Prediction to the Chart 2 The Earley Parsing Algorithm The Predictor Operator The Scanner Operator The Completer Operator Earley parsing: example Comparing Earley and CYK 2 / 31 We would have to split a given span into all possible subspans according to the length of the RHS. What is the complexity of such algorithm? Still O(n2) charts, but now it takes O(nk−1) time to process each cell, where k is the maximal length of an RHS. Therefore: O(nk+1). For CYK, k = 2. Can we do better than that? Note about CYK The CYK algorithm parses input strings in Chomsky normal form. Can you see how to change it to an algorithm with an arbitrary RHS length (of only nonterminals)? 3 / 31 Still O(n2) charts, but now it takes O(nk−1) time to process each cell, where k is the maximal length of an RHS. Therefore: O(nk+1). For CYK, k = 2. Can we do better than that? Note about CYK The CYK algorithm parses input strings in Chomsky normal form. Can you see how to change it to an algorithm with an arbitrary RHS length (of only nonterminals)? We would have to split a given span into all possible subspans according to the length of the RHS. What is the complexity of such algorithm? 3 / 31 Note about CYK The CYK algorithm parses input strings in Chomsky normal form. -

LATE Ain't Earley: a Faster Parallel Earley Parser
LATE Ain’T Earley: A Faster Parallel Earley Parser Peter Ahrens John Feser Joseph Hui [email protected] [email protected] [email protected] July 18, 2018 Abstract We present the LATE algorithm, an asynchronous variant of the Earley algorithm for pars- ing context-free grammars. The Earley algorithm is naturally task-based, but is difficult to parallelize because of dependencies between the tasks. We present the LATE algorithm, which uses additional data structures to maintain information about the state of the parse so that work items may be processed in any order. This property allows the LATE algorithm to be sped up using task parallelism. We show that the LATE algorithm can achieve a 120x speedup over the Earley algorithm on a natural language task. 1 Introduction Improvements in the efficiency of parsers for context-free grammars (CFGs) have the potential to speed up applications in software development, computational linguistics, and human-computer interaction. The Earley parser has an asymptotic complexity that scales with the complexity of the CFG, a unique, desirable trait among parsers for arbitrary CFGs. However, while the more commonly used Cocke-Younger-Kasami (CYK) [2, 5, 12] parser has been successfully parallelized [1, 7], the Earley algorithm has seen relatively few attempts at parallelization. Our research objectives were to understand when there exists parallelism in the Earley algorithm, and to explore methods for exploiting this parallelism. We first tried to naively parallelize the Earley algorithm by processing the Earley items in each Earley set in parallel. We found that this approach does not produce any speedup, because the dependencies between Earley items force much of the work to be performed sequentially. -

More Concise Representation of Regular Languages by Automata and Regular Expressions
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Information and Computation 208 (2010)385–394 Contents lists available at ScienceDirect Information and Computation journal homepage: www.elsevier.com/locate/ic More concise representation of regular languages by automata ୋ and regular expressions Viliam Geffert a, Carlo Mereghetti b,∗, Beatrice Palano b a Department of Computer Science, P. J. Šafárik University, Jesenná 5, 04154 Košice, Slovakia b Dipartimento di Scienze dell’Informazione, Università degli Studi di Milano, via Comelico 39, 20135 Milano, Italy ARTICLE INFO ABSTRACT Article history: We consider two formalisms for representing regular languages: constant height pushdown Received 12 February 2009 automata and straight line programs for regular expressions. We constructively prove that Revised 27 July 2009 their sizes are polynomially related. Comparing them with the sizes of finite state automata Available online 18 January 2010 and regular expressions, we obtain optimal exponential and double exponential gaps, i.e., a more concise representation of regular languages. Keywords: © 2010 Elsevier Inc. All rights reserved. Pushdown automata Regular expressions Straight line programs Descriptional complexity 1. Introduction Several systems for representing regular languages have been presented and studied in the literature. For instance, for the original model of finite state automaton [11], a lot of modifications have been introduced: nondeterminism [11], alternation [4], probabilistic evolution [10], two-way input head motion [12], etc. Other important formalisms for defining regular languages are, e.g., regular grammars [7] and regular expressions [8]. All these models have been proved to share the same expressive power by exhibiting simulation results. -

Midterm Study Sheet for CS3719 Regular Languages and Finite
Midterm study sheet for CS3719 Regular languages and finite automata: • An alphabet is a finite set of symbols. Set of all finite strings over an alphabet Σ is denoted Σ∗.A language is a subset of Σ∗. Empty string is called (epsilon). • Regular expressions are built recursively starting from ∅, and symbols from Σ and closing under ∗ Union (R1 ∪ R2), Concatenation (R1 ◦ R2) and Kleene Star (R denoting 0 or more repetitions of R) operations. These three operations are called regular operations. • A Deterministic Finite Automaton (DFA) D is a 5-tuple (Q, Σ, δ, q0,F ), where Q is a finite set of states, Σ is the alphabet, δ : Q × Σ → Q is the transition function, q0 is the start state, and F is the set of accept states. A DFA accepts a string if there exists a sequence of states starting with r0 = q0 and ending with rn ∈ F such that ∀i, 0 ≤ i < n, δ(ri, wi) = ri+1. The language of a DFA, denoted L(D) is the set of all and only strings that D accepts. • Deterministic finite automata are used in string matching algorithms such as Knuth-Morris-Pratt algorithm. • A language is called regular if it is recognized by some DFA. • ‘Theorem: The class of regular languages is closed under union, concatenation and Kleene star operations. • A non-deterministic finite automaton (NFA) is a 5-tuple (Q, Σ, δ, q0,F ), where Q, Σ, q0 and F are as in the case of DFA, but the transition function δ is δ : Q × (Σ ∪ {}) → P(Q). -

JFLAP – an Interactive Formal Languages and Automata Package
JFLAP – An Interactive Formal Languages and Automata Package Susan H. Rodger Thomas W. Finley Duke University Cornell University October 18, 2005 ii To Thomas, Erich, and Markus — S. H. Rodger KYHDKIKINKOIIAGKTIYKD BLGKLGFAROADGINIRJREL MRJHKDIARARATALYMFTKY DRNERKTMATSKHWGOBBKRY RDUNDFFKCKALAAKBUTCIO MIOIAJSAIDMJEWRYRKOKF WFYUSCIYETEGAUDNMULWG NFUCRYJJTYNYHTEOJHMAM NUEWNCCTHKTYMGFDEEFUN AULWSBTYMUAIYKHONJNHJ TRRLLYEMNHBGTRTDGBCMS RYHKTGAIERFYABNCRFCLJ NLFFNKAULONGYTMBYLWLU SRAUEEYWELKCSIBMOUKDW MEHOHUGNIGNEMNLKKHMEH CNUSCNEYNIIOMANWGAWNI MTAUMKAREUSHMTSAWRSNW EWJRWFEEEBAOKGOAEEWAN FHJDWKLAUMEIAOMGIEGBH IEUSNWHISDADCOGTDRWTB WFCSCDOINCNOELTEIUBGL — T. W. Finley Contents Preface ix JFLAP Startup xiv 1 Finite Automata 1 1.1 A Simple Finite Automaton . 1 1.1.1 Create States . 2 1.1.2 Define the Initial State and the Final State . 2 1.1.3 Creating Transitions . 2 1.1.4 Deleting States and Transitions . 3 1.1.5 Attribute Editor Tool . 3 1.2 Simulation of Input . 5 1.2.1 Stepping Simulation . 5 1.2.2 Fast Simulation . 7 1.2.3 Multiple Simulation . 8 1.3 Nondeterminism . 9 1.3.1 Creating Nondeterministic Finite Automata . 9 1.3.2 Simulation . 10 1.4 Simple Analysis Operators . 12 1.4.1 Compare Equivalence . 13 1.4.2 Highlight Nondeterminism . 13 1.4.3 Highlight λ-Transitions . 13 1.5 Alternative Multiple Character Transitions∗ ....................... 13 1.6 Definition of FA in JFLAP . 14 1.7 Summary . 15 1.8 Exercises . 15 2 NFA to DFA to Minimal DFA 19 2.1 NFA to DFA . 19 iii iv CONTENTS 2.1.1 Idea for the Conversion . 19 2.1.2 Conversion Example . 20 2.1.3 Algorithm to Convert NFA M to DFA M 0 .................... 22 2.2 DFA to Minimal DFA . 23 2.2.1 Idea for the Conversion . 23 2.2.2 Conversion Example . -

Chapter 6 Formal Language Theory
Chapter 6 Formal Language Theory In this chapter, we introduce formal language theory, the computational theories of languages and grammars. The models are actually inspired by formal logic, enriched with insights from the theory of computation. We begin with the definition of a language and then proceed to a rough characterization of the basic Chomsky hierarchy. We then turn to a more de- tailed consideration of the types of languages in the hierarchy and automata theory. 6.1 Languages What is a language? Formally, a language L is defined as as set (possibly infinite) of strings over some finite alphabet. Definition 7 (Language) A language L is a possibly infinite set of strings over a finite alphabet Σ. We define Σ∗ as the set of all possible strings over some alphabet Σ. Thus L ⊆ Σ∗. The set of all possible languages over some alphabet Σ is the set of ∗ all possible subsets of Σ∗, i.e. 2Σ or ℘(Σ∗). This may seem rather simple, but is actually perfectly adequate for our purposes. 6.2 Grammars A grammar is a way to characterize a language L, a way to list out which strings of Σ∗ are in L and which are not. If L is finite, we could simply list 94 CHAPTER 6. FORMAL LANGUAGE THEORY 95 the strings, but languages by definition need not be finite. In fact, all of the languages we are interested in are infinite. This is, as we showed in chapter 2, also true of human language. Relating the material of this chapter to that of the preceding two, we can view a grammar as a logical system by which we can prove things. -
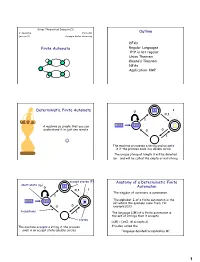
Deterministic Finite Automata 0 0,1 1
Great Theoretical Ideas in CS V. Adamchik CS 15-251 Outline Lecture 21 Carnegie Mellon University DFAs Finite Automata Regular Languages 0n1n is not regular Union Theorem Kleene’s Theorem NFAs Application: KMP 11 1 Deterministic Finite Automata 0 0,1 1 A machine so simple that you can 0111 111 1 ϵ understand it in just one minute 0 0 1 The machine processes a string and accepts it if the process ends in a double circle The unique string of length 0 will be denoted by ε and will be called the empty or null string accept states (F) Anatomy of a Deterministic Finite start state (q0) 11 0 Automaton 0,1 1 The singular of automata is automaton. 1 The alphabet Σ of a finite automaton is the 0111 111 1 ϵ set where the symbols come from, for 0 0 example {0,1} transitions 1 The language L(M) of a finite automaton is the set of strings that it accepts states L(M) = {x∈Σ: M accepts x} The machine accepts a string if the process It’s also called the ends in an accept state (double circle) “language decided/accepted by M”. 1 The Language L(M) of Machine M The Language L(M) of Machine M 0 0 0 0,1 1 q 0 q1 q0 1 1 What language does this DFA decide/accept? L(M) = All strings of 0s and 1s The language of a finite automaton is the set of strings that it accepts L(M) = { w | w has an even number of 1s} M = (Q, Σ, , q0, F) Q = {q0, q1, q2, q3} Formal definition of DFAs where Σ = {0,1} A finite automaton is a 5-tuple M = (Q, Σ, , q0, F) q0 Q is start state Q is the finite set of states F = {q1, q2} Q accept states : Q Σ → Q transition function Σ is the alphabet : Q Σ → Q is the transition function q 1 0 1 0 1 0,1 q0 Q is the start state q0 q0 q1 1 q q1 q2 q2 F Q is the set of accept states 0 M q2 0 0 q2 q3 q2 q q q 1 3 0 2 L(M) = the language of machine M q3 = set of all strings machine M accepts EXAMPLE Determine the language An automaton that accepts all recognized by and only those strings that contain 001 1 0,1 0,1 0 1 0 0 0 1 {0} {00} {001} 1 L(M)={1,11,111, …} 2 Membership problem Determine the language decided by Determine whether some word belongs to the language. -

Lecture 10: CYK and Earley Parsers Alvin Cheung Building Parse Trees Maaz Ahmad CYK and Earley Algorithms Talia Ringer More Disambiguation
Hack Your Language! CSE401 Winter 2016 Introduction to Compiler Construction Ras Bodik Lecture 10: CYK and Earley Parsers Alvin Cheung Building Parse Trees Maaz Ahmad CYK and Earley algorithms Talia Ringer More Disambiguation Ben Tebbs 1 Announcements • HW3 due Sunday • Project proposals due tonight – No late days • Review session this Sunday 6-7pm EEB 115 2 Outline • Last time we saw how to construct AST from parse tree • We will now discuss algorithms for generating parse trees from input strings 3 Today CYK parser builds the parse tree bottom up More Disambiguation Forcing the parser to select the desired parse tree Earley parser solves CYK’s inefficiency 4 CYK parser Parser Motivation • Given a grammar G and an input string s, we need an algorithm to: – Decide whether s is in L(G) – If so, generate a parse tree for s • We will see two algorithms for doing this today – Many others are available – Each with different tradeoffs in time and space 6 CYK Algorithm • Parsing algorithm for context-free grammars • Invented by John Cocke, Daniel Younger, and Tadao Kasami • Basic idea given string s with n tokens: 1. Find production rules that cover 1 token in s 2. Use 1. to find rules that cover 2 tokens in s 3. Use 2. to find rules that cover 3 tokens in s 4. … N. Use N-1. to find rules that cover n tokens in s. If succeeds then s is in L(G), else it is not 7 A graphical way to visualize CYK Initial graph: the input (terminals) Repeat: add non-terminal edges until no more can be added. -

Animating the Conversion of Nondeterministic Finite State
ANIMATING THE CONVERSION OF NONDETERMINISTIC FINITE STATE AUTOMATA TO DETERMINISTIC FINITE STATE AUTOMATA by William Patrick Merryman A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science MONTANA STATE UNIVERSITY Bozeman, Montana January 2007 ©COPYRIGHT by William Patrick Merryman 2007 All Rights Reserved ii APPROVAL of a thesis submitted by William Patrick Merryman This thesis has been read by each member of the thesis committee and has been found to be satisfactory regarding content, English usage, format, citations, bibliographic content, and consistency, and is ready for submission to the Division of Graduate Education. Dr. Rockford Ross Approved for the Department of Computer Science Dr. Michael Oudshoorn Approved for the Division of Graduate Education Dr. Carl A. Fox iii STATEMENT OF PERMISSION TO USE In presenting this thesis in partial fulfillment of the requirements for a Master’s degree at Montana State University, I agree that the Library shall make it available to borrowers under rules of the Library. If I have indicated my intention to copyright this thesis by including a copyright notice page, copying is allowable only for scholarly purposes, consistent with “fair use” as prescribed in the U.S. Copyright Law. Requests for permission for extended quotation from or reproduction of this thesis in whole or in parts may be granted only by the copyright holder. William Patrick Merryman January, 2007 iv TABLE OF CONTENTS 1. INTRODUCTION ........................................................................................ -
6.045 Final Exam Name
6.045J/18.400J: Automata, Computability and Complexity Prof. Nancy Lynch 6.045 Final Exam May 20, 2005 Name: • Please write your name on each page. • This exam is open book, open notes. • There are two sheets of scratch paper at the end of this exam. • Questions vary substantially in difficulty. Use your time accordingly. • If you cannot produce a full proof, clearly state partial results for partial credit. • Good luck! Part Problem Points Grade Part I 1–10 50 1 20 2 15 3 25 Part II 4 15 5 15 6 10 Total 150 final-1 Name: Part I Multiple Choice Questions. (50 points, 5 points for each question) For each question, any number of the listed answersClearly may place be correct. an “X” in the box next to each of the answers that you are selecting. Problem 1: Which of the following are true statements about regular and nonregular languages? (All lan guages are over the alphabet{0, 1}) IfL1 ⊆ L2 andL2 is regular, thenL1 must be regular. IfL1 andL2 are nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is nonregular, then the complementL 1 must of also be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is regular, thenL1 ∪ L2 must be nonregular. Problem 2: Which of the following are guaranteed to be regular languages ? ∗ L2 = {ww : w ∈{0, 1}}. L2 = {ww : w ∈ L1}, whereL1 is a regular language. L2 = {w : ww ∈ L1}, whereL1 is a regular language. L2 = {w : for somex,| w| = |x| andwx ∈ L1}, whereL1 is a regular language.