A Flow-Analysis Framework for Realistic Scheme Programs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Towards a Portable and Mobile Scheme Interpreter
Towards a Portable and Mobile Scheme Interpreter Adrien Pi´erard Marc Feeley Universit´eParis 6 Universit´ede Montr´eal [email protected] [email protected] Abstract guage. Because Mobit implements R4RS Scheme [6], we must also The transfer of program data between the nodes of a distributed address the serialization of continuations. Our main contribution is system is a fundamental operation. It usually requires some form the demonstration of how this can be done while preserving the in- of data serialization. For a functional language such as Scheme it is terpreter’s maintainability and with local changes to the original in- clearly desirable to also allow the unrestricted transfer of functions terpreter’s structure, mainly through the use of unhygienic macros. between nodes. With the goal of developing a portable implemen- We start by giving an overview of the pertinent features of the tation of the Termite system we have designed the Mobit Scheme Termite dialect of Scheme. In Section 3 we explain the structure interpreter which supports unrestricted serialization of Scheme ob- of the interpreter on which Mobit is based. Object serialization is jects, including procedures and continuations. Mobit is derived discussed in Section 4. Section 5 compares Mobit’s performance from an existing Scheme in Scheme fast interpreter. We demon- with other interpreters. We conclude with related and future work. strate how macros were valuable in transforming the interpreter while preserving its structure and maintainability. Our performance 2. Termite evaluation shows that the run time speed of Mobit is comparable to Termite is a Scheme adaptation of the Erlang concurrency model. -

Towards a Portable and Mobile Scheme Interpreter
Towards a Portable and Mobile Scheme Interpreter Adrien Pi´erard Marc Feeley Universit´eParis 6 Universit´ede Montr´eal [email protected] [email protected] Abstract guage. Because Mobit implements R4RS Scheme [6], we must also The transfer of program data between the nodes of a distributed address the serialization of continuations. Our main contribution is system is a fundamental operation. It usually requires some form the demonstration of how this can be done while preserving thein- of data serialization. For a functional language such as Scheme it is terpreter’s maintainability and with local changes to the original in- clearly desirable to also allow the unrestricted transfer offunctions terpreter’s structure, mainly through the use of unhygienicmacros. between nodes. With the goal of developing a portable implemen- We start by giving an overview of the pertinent features of the tation of the Termite system we have designed the Mobit Scheme Termite dialect of Scheme. In Section 3 we explain the structure interpreter which supports unrestricted serialization of Scheme ob- of the interpreter on which Mobit is based. Object serialization is jects, including procedures and continuations. Mobit is derived discussed in Section 4. Section 5 compares Mobit’s performance from an existing Scheme in Scheme fast interpreter. We demon- with other interpreters. We conclude with related and futurework. strate how macros were valuable in transforming the interpreter while preserving its structure and maintainability. Our performance 2. Termite evaluation shows that the run time speed of Mobit is comparable to Termite is a Scheme adaptation of the Erlang concurrency model. -

Fully-Parameterized, First-Class Modules with Hygienic Macros
Fully-parameterized, First-class Modules with Hygienic Macros Dissertation der Fakult¨at fur¨ Informations- und Kognitionswissenschaften der Eberhard-Karls-Universit¨at Tubingen¨ zur Erlangung des Grades eines Doktors der Naturwissenschaften (Dr. rer. nat.) vorgelegt von Dipl.-Inform. Josef Martin Gasbichler aus Biberach/Riß Tubingen¨ 2006 Tag der mundlichen¨ Qualifikation: 15. 02. 2006 Dekan: Prof. Dr. Michael Diehl 1. Berichterstatter: Prof. Dr. Herbert Klaeren 2. Berichterstatter: Prof. Dr. Peter Thiemann (Universit¨at Freiburg) Abstract It is possible to define a formal semantics for configuration, elaboration, linking, and evaluation of fully-parameterized first-class modules with hygienic macros, independent compilation, and code sharing. This dissertation defines such a semantics making use of explicit substitution to formalize hygienic expansion and linking. In the module system, interfaces define the static semantics of modules and include the definitions of exported macros. This enables full parameterization and independent compilation of modules even in the presence of macros. Thus modules are truly exchangeable components of the program. The basis for the module system is an operational semantics for hygienic macro expansion—computational macros as well as rewriting-based macros. The macro semantics provides deep insight into the nature of hygienic macro expansion through the use of explicit substitutions instead of conventional renaming techniques. The semantics also includes the formal description of Macro Scheme, the meta-language used for evaluating computational macros. Zusammenfassung Es ist m¨oglich, eine formale Semantik anzugeben, welche die Phasen Konfiguration, syntak- tische Analyse mit Makroexpansion, Linken und Auswertung fur¨ ein vollparametrisiertes Mo- dulsystem mit Modulen als Werten erster Klasse, unabh¨angiger Ubersetzung¨ und Code-Sharing beschreibt. -

A Tractable Scheme Implementation
LISP AND SYMBOLIC COMPUTATION:An International Journal, 7, 315-335 (1994) © 1994 Kluwer Academic Publishers, Boston. Manufactured in The Netherlands. A Tractable Scheme Implementation RICHARD A. KELSEY [email protected] NEC Research Institute JONATHAN A. REES [email protected] M1T and Cornell University Abstract. Scheme 48 is an implementation of the Scheme programming language constructed with tractability and reliability as its primary design goals. It has the structural properties of large, compiler-based Lisp implementations: it is written entirely in Scheme, is bootstrapped via its compiler, and provides numerous language extensions. It controls the complexity that ordinarily attends such large Lisp implementations through clear articulation of internal modularity and by the exclusion of features, optimizations, and generalizations that are of only marginal value. Keywords: byte-code interpreters, virtual machines, modularity, Scheme, partial evaluation, layered design 1. Introduction Scheme 48 is an implementation of the Scheme programming language constructed with tractability and reliability as its primary design goals. By tractability we mean the ease with which the system can be understood and changed. Although Lisp dialects, including Scheme, are relatively simple languages, implementation tractability is often threatened by the demands of providing high performance and extended functionality. The Scheme 48 project was initiated in order to experiment with techniques for main- taining implementation tractability in the face of countervailing pressures and to find out what tradeoffs were involved in doing so. (The project was originally an experiment to see if a Scheme implementation could be written in a single weekend; the 48 refers to forty-eight hours.) Small Lisp implementations are usually tractable merely by virtue of being small; it is usually possible for an experienced programmer to read and understand the entire source program in a few days. -

The Incomplete Scheme 48 Reference Manual for Release 1.8
The Incomplete Scheme 48 Reference Manual for release 1.8 Richard Kelsey Jonathan Rees Mike Sperber A line may take us hours, yet if it does not seem a moment’s thought All our stitching and unstitching has been as nought. Yeats Adam’s Curse ii Acknowledgements Thanks to Scheme 48’s users for their suggestions, bug reports, and forbearance. Thanks also to Deborah Tatar for providing the Yeats quotation. iii Contents Contents iv 1 Introduction 1 2 User’s guide 2 2.1 Command line arguments . 2 2.2 Command processor . 3 2.3 Editing . 3 2.4 Performance . 3 2.5 Disassembler . 4 2.6 Module system . 4 2.7 Library . 6 3 Command processor 7 3.1 Current focus value and ## ..................... 7 3.2 Command levels . 8 3.3 Logistical commands . 9 3.4 Module commands . 9 3.5 Debugging commands . 9 3.6 Settings . 11 3.7 Inspection mode . 13 3.8 Command programs . 14 3.9 Building images . 15 3.10 Resource query and control . 15 3.11 Threads . 16 3.12 Quite obscure . 17 4 Module system 18 4.1 Introduction . 18 4.2 The configuration language . 19 4.3 Interfaces . 21 4.4 Macros . 22 4.5 Higher-order modules . 23 4.6 Compiling and linking . 23 iv 4.7 Semantics of configuration mutation . 23 4.8 Command processor support . 24 4.9 Configuration packages . 27 4.10 Discussion . 28 5 Libraries 30 5.1 General utilities . 30 5.2 Pretty-printing . 32 5.3 Bitwise integer operations . 32 5.4 Byte vectors . -

Laboratory for Computer Science a Scheme Shell
MASSACHUSETTS INSTITUTE OF TECHNOLOGY Laboratory for Computer Science Personal Information Architecture Note 3 4/94 A Scheme Shell Olin Shivers [email protected] Although robust enough for general use, adventures into the esoteric periphery of the C shell may reveal unexpected quirks. — SunOS 4.1 csh(1) man page, 10/2/89 Prologue Shell programming terrifies me. There is something about writing a sim- ple shell script that is just much, much more unpleasant than writing a simple C program, or a simple COMMON LISP program, or a simple Mips assembler program. Is it trying to remember what the rules are for all the different quotes? Is it having to look up the multi-phased interaction between filename expansion, shell variables, quotation, backslashes and alias expansion? Maybe it’s having to subsequently look up which of the twenty or thirty flags I need for my grep, sed, and awk invocations. Maybe it just gets on my nerves that I have to run two complete programs simply to count the number of files in a directory (ls | wc -l), which seems like several orders of magnitude more cycles than was really needed. Whatever it is, it’s an object lesson in angst. Furthermore, during late- night conversations with office mates and graduate students, I have formed the impression that I am not alone. In late February1, I got embroiled in a multi-way email flamefest about just exactly what it was about Unix that drove me nuts. In the midst of the debate, I did a rash thing. I claimed that it would be easy and so much nicer to do shell programming from Scheme. -

Precursors for Synthesis of the First Compounds with Metal-Silicon Triple Bonds
Novel Molecular Si(II) Precursors for Synthesis of the First Compounds with Metal-Silicon Triple Bonds Dissertation Submitted in fulfillment of the degree doctor rerum naturalium (Dr. rer. nat) of The Faculty of Mathematics and Natural Sciences of The Rheinische Friedrich-Wilhelms-University of Bonn by Dipl.-Chem. Oleg Chernov born in Belgorod, Russia Bonn, April 2012 Angefertigt mit Genehmigung der Mathematisch-Naturwissenschaftlichen Fakultät der Rheinischen Friedrich-Wilhelms-Universität Bonn 1st Examiner: Prof. Dr. A. C. Filippou 2nd Examiner: Prof. Dr. J. Beck 3rd Examiner: Prof. Dr. A. Gansäuer 4th Examiner: Prof. Dr. M. Wagner Date of dissertation defense: 21. September 2012 Publication year: 2012 2 Acknowledgements First, I would like to thank Prof. Dr. Alexander C. Filippou for giving me the opportunity to work in his research group, for his guidance, helpful advices and the thorough evaluation of my thesis including various suggestions for amendments. I am obliged to many of my colleagues, without their help this dissertation would not have been possible: Dr. Gregor Schnakenburg for the X-ray diffraction measurements, quantum chemical calculations and of course for correcting the draft of the disertation. Gabriele Hofer, Katrin Puffler, Kerstin Kühnel-Lysek, Bernhard Beile and Dietmar Kühlmorgen for the synthesis of starting materials and everyday help. Dr. Jürgen Tirée for his great help in organization of the experimental work. All of my students, who contributed to my research: Volker Adam, Martin Speer, Jana Haag, Klaas Remmerssen. Dr. Nils Weidemann for his useful advices and some of precious starting materials. Dr. Sebastian Schwieger for solving some of my X-ray structures The NMR department: Karin Prochnicki, Claus Schmidt, Hannelore Spitz and Dr. -

23 Things I Know About Modules for Scheme
23 things I know about modules for Scheme Christian Queinnec Université Paris 6 — Pierre et Marie Curie LIP6, 4 place Jussieu, 75252 Paris Cedex — France [email protected] ABSTRACT ables), types, classes (and their cortege` of accessors, con- The benefits of modularization are well known. However, modules structors and predicates) ? are not standard in Scheme. This paper accompanies an invited talk The usual answer in Scheme is to share locations with (quite at the Scheme Workshop 2002 on the current state of modules for often) two additional properties: (i) these locations can only Scheme. Implementation is not addressed, only linguistic features be mutated from the body of their defining modules (this fa- are covered. vors block compilation), (ii) they should hold functions (and Cave lector, this paper only reflects my own and instantaneous this should be statically (and easily) discoverable). This biases! restricts linking with other (foreign) languages that may ex- port locations holding non-functional data (the errno loca- 1. MODULES tion for instance). This is not a big restriction since modern interfaces (Corba for example) tend to exclusively use func- The benefits of modularization within conventional languages tions (or methods). On the good side, this restriction allows are well known. Modules dissociate interfaces and implementa- for better compilation since non mutated exported functions tions; they allow separate compilation (or at least independent com- may be directly invoked or inlined. pilation a` la C). Modules tend to favor re-usability, common li- braries and cross language linkage. Let us remark that values, if staying in an entirely Scheme Modules discipline name spaces with explicit names exposure, world, would be sufficient since closures are values giving hiding or renaming. -

Cleaning up the Tower: Numbers in Scheme
Cleaning up the Tower: Numbers in Scheme Sebastian Egner Richard A. Kelsey Michael Sperber Philips Research Laboratories Ember Corporation [email protected] [email protected] [email protected] Abstract Scheme 48 1.1 (default mode) 7/10 Petite Chez Scheme 6.0a, 3152519739159347/ The R5RS specification of numerical operations leads to unportable Gambit-C 3.0, 4503599627370496 and intransparent behavior of programs. Specifically, the notion Scheme 48 1.1 (after ,open of “exact/inexact numbers” and the misleading distinction between floatnums) “real” and “rational” numbers are two primary sources of confu- SCM 5d9 1 sion. Consequently, the way R5RS organizes numbers is signifi- Chicken 0/1082: “can not be represented cantly less useful than it could be. Based on this diagnosis, we pro- as an exact number” pose to abandon the concept of exact/inexact numbers from Scheme Table 1. Value of (inexact->exact 0.7) in various R5RS altogether. In this paper, we examine designs in which exact and in- Scheme implementations exact rounding operations are explicitly separated, while there is no distinction between exact and inexact numbers. Through examining alternatives and practical ramifications, we arrive at an alternative proposal for the design of the numerical operations in Scheme. compromise between the two—which introduces the need for trans- parency. Reproducibility is clearly desirable, but also often in con- flict with efficiency—the most efficient method for performing a 1 Introduction computation on one machine may be inefficient on another. At least, a programmer should be able to predict whether a program The set of numerical operations of a wide-spectrum programming computes a reproducible result. -

Coresim: a Simulator for Evaluating LISP Mapping Systems
TECHNICAL UNIVERSITY OF CLUJ-NAPOCA DIPLOM THESIS PROJECT CoreSim: A Simulator for Evaluating LISP Mapping Systems Supervisors: Author: Phd. Virgil DOBROTA˘ Florin-Tudorel CORAS¸ Phd. Albert CABELLOS Lorand´ JAKAB Contents Contents 1 List of Figures 3 1 State-of-the-art 4 1.1 Problem Statement . .4 1.1.1 The scalability of the Routing System . .4 1.1.2 The Overloading of the IP Address Semantics . .5 1.2 Current State and Solution Space . .5 1.2.1 Initial Research . .5 1.2.2 New Proposals . .7 1.3 Current Implementations . .9 2 Theoretical Fundamentals 10 2.1 Locator/Identifier Separation principle . 10 2.1.1 Endpoints and Endpoint Names . 10 2.1.2 Initial Proposals . 11 2.2 Locator/Identifier Separation Protocol (LISP) . 13 2.2.1 LISP Map Server . 16 2.3 LISP Proposed Mapping Systems . 18 2.3.1 LISP+ALT . 18 2.3.2 LISP-DHT . 21 3 Design 23 3.1 Simulator architecture . 23 3.1.1 Simulator Components . 23 3.1.2 Simulator nature . 25 3.2 From Design to Implementation . 25 3.2.1 The Problem . 25 3.2.2 Program Requirements . 26 3.2.3 Additional Requirements . 26 3.2.4 Deciding upon a programming language . 26 3.2.5 Back to the drawing board . 27 3.3 Topology Module . 27 3.3.1 iPlane . 28 3.3.2 iPlane is not enough . 30 3.3.3 Design constraints . 31 3.3.4 Internal components . 32 3.4 Chord Module . 34 3.4.1 Topology Design Issues . 34 3.4.2 Internal Components . -
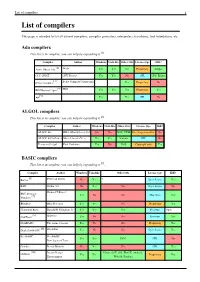
List of Compilers 1 List of Compilers
List of compilers 1 List of compilers This page is intended to list all current compilers, compiler generators, interpreters, translators, tool foundations, etc. Ada compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [2] Aonix Object Ada Atego Yes Yes Yes Proprietary Eclipse GCC GNAT GNU Project Yes Yes No GPL GPS, Eclipse [3] Irvine Compiler Irvine Compiler Corporation Yes Proprietary No [4] IBM Rational Apex IBM Yes Yes Yes Proprietary Yes [5] A# Yes Yes GPL No ALGOL compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? ALGOL 60 RHA (Minisystems) Ltd No No DOS, CP/M Free for personal use No ALGOL 68G (Genie) Marcel van der Veer Yes Yes Various GPL No Persistent S-algol Paul Cockshott Yes No DOS Copyright only Yes BASIC compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [6] BaCon Peter van Eerten No Yes ? Open Source Yes BAIL Studio 403 No Yes No Open Source No BBC Basic for Richard T Russel [7] Yes No No Shareware Yes Windows BlitzMax Blitz Research Yes Yes No Proprietary Yes Chipmunk Basic Ronald H. Nicholson, Jr. Yes Yes Yes Freeware Open [8] CoolBasic Spywave Yes No No Freeware Yes DarkBASIC The Game Creators Yes No No Proprietary Yes [9] DoyleSoft BASIC DoyleSoft Yes No No Open Source Yes FreeBASIC FreeBASIC Yes Yes DOS GPL No Development Team Gambas Benoît Minisini No Yes No GPL Yes [10] Dream Design Linux, OSX, iOS, WinCE, Android, GLBasic Yes Yes Proprietary Yes Entertainment WebOS, Pandora List of compilers 2 [11] Just BASIC Shoptalk Systems Yes No No Freeware Yes [12] KBasic KBasic Software Yes Yes No Open source Yes Liberty BASIC Shoptalk Systems Yes No No Proprietary Yes [13] [14] Creative Maximite MMBasic Geoff Graham Yes No Maximite,PIC32 Commons EDIT [15] NBasic SylvaWare Yes No No Freeware No PowerBASIC PowerBASIC, Inc. -
Concurrent ML
Concurrent ML: The One That Got Away Michael Sperber @sperbsen • software project development • in many fields • Scala, Clojure, Erlang, Haskell, F#, OCaml • training, coaching • co-organize BOB conference www.active-group.de funktionale-programmierung.de Myself • taught Concurrent Programming at U Tübingen in 2002 • implemented Concurrent ML for Scheme 48 • designed Concurrent ML for Star F# Tutorial, CUFP 2011 John Reppy. Concurrent ML. Cambridge. Actor Model F# /// split elements coming into inbox among the two sinks let split (inbox: Agent<SinkMessage<'T>>) (sink1: Agent<SinkMessage<'T>>) (sink2: Agent<SinkMessage<'T>>) : Async<unit> = let rec loop (sink1: Agent<SinkMessage<'T>>) (sink2: Agent<SinkMessage<'T>>) = async { let! msg = inbox.Receive () match msg with | EndOfInput -> do sink1.Post EndOfInput do sink2.Post EndOfInput return () | Value x -> do sink1.Post msg return! loop sink2 sink1 | GetNext _ -> failwith "premature GetNext" } loop sink1 sink2 Abstractions Matter! (Duh!) Composition Matters! Concurrent ML • SML/NJ • Manticore • Multi-MLton • Scheme 48 • Racket • Guile • Star • *Haskell Things that are not CML • Erlang • Go • Clojure core.async • Akka streams Fibonacci Network (define (make-fibonacci-network) (let ((outch (make-channel)) (c1 (make-channel)) (c2 (make-channel)) (c3 (make-channel)) (c4 (make-channel)) (c5 (make-channel))) (delay1 0 c4 c5) (copy c2 c3 c4) (add c3 c5 c1) (copy c1 c2 outch) (send c1 1) outch)) Process Networks: Add (define (add inch1 inch2 outch) (forever #f (lambda (_) (send outch (+ (receive