Chapter 11 Related Variables
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Conversation with Richard A. Olshen 3
Statistical Science 2015, Vol. 30, No. 1, 118–132 DOI: 10.1214/14-STS492 c Institute of Mathematical Statistics, 2015 A Conversation with Richard A. Olshen John A. Rice Abstract. Richard Olshen was born in Portland, Oregon, on May 17, 1942. Richard spent his early years in Chevy Chase, Maryland, but has lived most of his life in California. He received an A.B. in Statistics at the University of California, Berkeley, in 1963, and a Ph.D. in Statistics from Yale University in 1966, writing his dissertation under the direction of Jimmie Savage and Frank Anscombe. He served as Research Staff Statistician and Lecturer at Yale in 1966–1967. Richard accepted a faculty appointment at Stanford University in 1967, and has held tenured faculty positions at the University of Michigan (1972–1975), the University of California, San Diego (1975–1989), and Stanford University (since 1989). At Stanford, he is Professor of Health Research and Policy (Biostatistics), Chief of the Division of Biostatistics (since 1998) and Professor (by courtesy) of Electrical Engineering and of Statistics. At various times, he has had visiting faculty positions at Columbia, Harvard, MIT, Stanford and the Hebrew University. Richard’s research interests are in statistics and mathematics and their applications to medicine and biology. Much of his work has concerned binary tree-structured algorithms for classification, regression, survival analysis and clustering. Those for classification and survival analysis have been used with success in computer-aided diagnosis and prognosis, especially in cardiology, oncology and toxicology. He coauthored the 1984 book Classi- fication and Regression Trees (with Leo Brieman, Jerome Friedman and Charles Stone) which gives motivation, algorithms, various examples and mathematical theory for what have come to be known as CART algorithms. -

“I Didn't Want to Be a Statistician”
“I didn’t want to be a statistician” Making mathematical statisticians in the Second World War John Aldrich University of Southampton Seminar Durham January 2018 1 The individual before the event “I was interested in mathematics. I wanted to be either an analyst or possibly a mathematical physicist—I didn't want to be a statistician.” David Cox Interview 1994 A generation after the event “There was a large increase in the number of people who knew that statistics was an interesting subject. They had been given an excellent training free of charge.” George Barnard & Robin Plackett (1985) Statistics in the United Kingdom,1939-45 Cox, Barnard and Plackett were among the people who became mathematical statisticians 2 The people, born around 1920 and with a ‘name’ by the 60s : the 20/60s Robin Plackett was typical Born in 1920 Cambridge mathematics undergraduate 1940 Off the conveyor belt from Cambridge mathematics to statistics war-work at SR17 1942 Lecturer in Statistics at Liverpool in 1946 Professor of Statistics King’s College, Durham 1962 3 Some 20/60s (in 1968) 4 “It is interesting to note that a number of these men now hold statistical chairs in this country”* Egon Pearson on SR17 in 1973 In 1939 he was the UK’s only professor of statistics * Including Dennis Lindley Aberystwyth 1960 Peter Armitage School of Hygiene 1961 Robin Plackett Durham/Newcastle 1962 H. J. Godwin Royal Holloway 1968 Maurice Walker Sheffield 1972 5 SR 17 women in statistical chairs? None Few women in SR17: small skills pool—in 30s Cambridge graduated 5 times more men than women Post-war careers—not in statistics or universities Christine Stockman (1923-2015) Maths at Cambridge. -

A Conversation with John Hartigan Daniel Barry
Statistical Science 2005, Vol. 20, No. 4, 418–430 DOI 10.1214/088342304000000242 © Institute of Mathematical Statistics, 2005 A Conversation with John Hartigan Daniel Barry Abstract. John Anthony Hartigan was born on July 2, 1937 in Sydney, Aus- tralia. He attended the University of Sydney, earning a B.Sc. degree in math- ematics in 1959 and an M.Sc. degree in mathematics the following year. In 1960 John moved to Princeton where he studied for his Ph.D. in statistics under the guidance of John Tukey and Frank Anscombe. He completed his Ph.D. in 1962, and worked as an Instructor at Princeton in 1962–1963, and as a visiting lecturer at the Cambridge Statistical Laboratory in 1963–1964. In 1964 he joined the faculty at Princeton. He moved to Yale as Associate Professor with tenure in 1969, became a Professor in 1972 and, in 1983, be- came Eugene Higgins Professor of Statistics at Yale—a position previously held by Jimmie Savage. He served as Chairman of the Statistics Department at Yale from 1973 to 1975 and again from 1988 to 1994. John was instrumen- tal in the establishment of the Social Sciences Statistical Laboratory at Yale and served as its Director from 1985 to 1989 and again from 1991 to 1993. He served as Chairman of the National Research Council Committee on the General Aptitude Test Battery from 1987 to 1990. John’s research interests cover the foundations of probability and statistics, classification, clustering, Bayes methods and statistical computing. He has published over 80 journal papers and two books: Clustering Algorithms in 1975 and Bayes Theory in 1983. -
What Everyone Should Know About Statistical Correlation » American
What Everyone Should Know about Statistical Correlation » Am... http://www.americanscientist.org/issues/id.16293,y.0,no.,content.... ETHICS What Everyone Should Know about Statistical Correlation A common analytical error hinders biomedical research and misleads the public. Vladica Velickovic In 2012, the New England Journal of Medicine published a paper claiming that chocolate consumption could enhance cognitive function. The basis for this conclusion was that the number of Nobel Prize laureates in each country was strongly correlated with the per capita consumption of chocolate in that country. When I read this paper I was surprised that it made it through peer review, because it was clear to me that the authors had committed two common mistakes I see in the biomedical literature when researchers perform a correlation analysis. Correlation describes the strength of the linear relationship between two observed phenomena (to keep matters simple, I focus on the most commonly used linear relationship, or Pearson’s correlation, here). For example, the increase in the value of one variable, such as chocolate consumption, may be followed by the increase in the value of the other one, such as Nobel laureates. Or the correlation can be negative: The increase in the value of one variable may be followed by the decrease in the value of the other. Because it is possible to correlate two variables whose values cannot be expressed in the same units—for example, per capita income and cholera incidence—their relationship is measured by calculating a unitless number, the correlation coefficient . The correlation coefficient ranges in value from –1 to +1. -

Cautionary Tales in Designed Experiments
The correct bibliographic citation for this manual is as follows: Salsburg, David S. 2020. Cautionary Tales in Designed Experiments. Cary, NC: SAS Institute Inc. Cautionary Tales in Designed Experiments Copyright © 2020, SAS Institute Inc., Cary, NC, USA ISBN 978-1-952363-24-5 (Paperback) ISBN 978-1-952363-23-8 (Web PDF) All Rights Reserved. Produced in the United States of America. For a hard copy book: No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, or otherwise, without the prior written permission of the publisher, SAS Institute Inc. For a web download or e-book: Your use of this publication shall be governed by the terms established by the vendor at the time you acquire this publication. The scanning, uploading, and distribution of this book via the Internet or any other means without the permission of the publisher is illegal and punishable by law. Please purchase only authorized electronic editions and do not participate in or encourage electronic piracy of copyrighted materials. Your support of others’ rights is appreciated. U.S. Government License Rights; Restricted Rights: The Software and its documentation is commercial computer software developed at private expense and is provided with RESTRICTED RIGHTS to the United States Government. Use, duplication, or disclosure of the Software by the United States Government is subject to the license terms of this Agreement pursuant to, as applicable, FAR 12.212, DFAR 227.7202-1(a), DFAR 227.7202-3(a), and DFAR 227.7202-4, and, to the extent required under U.S. -

Memories of Mervyn Stone Rex Galbraith, Department of Statistical Science, UCL Janmuary 25, 2021
Memories of Mervyn Stone Rex Galbraith, Department of Statistical Science, UCL Janmuary 25, 2021 With much sadness we record the death, on 19 September 2020, of our friend and colleague Mervyn Stone. He made major contribu- tions to our discipline and is an important part of the history of our Mervyn and Solveig Stone in 1982 Photo courtesy of Helen Bridgeman department. He joined UCL in 1968 and remained for the rest of his working life. After retiring in the 1990s he continued his activities as an emeritus professor. Below I have reproduced the obituary of Mervyn that I wrote 1 for the Royal Statistical Society, and I have added some further 1 J. R. Stat. Soc. Series A, 184, 1, 396–398. doi 10 1111 126 38 memories and a list of his publications. Among other things they : . /rssa . , Open Access. are a reminder of how active he was in his writing and thinking. Obituary published by the Royal Statistical Society Mervyn Stone died on 19 September 2020, aged 87. He was a brilliant mathematician, professor of probability and statistics, and thinker. He was elected to the Royal Statistical Society in 1955; served on the Series B Editorial Panel (1966–1969) and as Editor of Series B (1975–1977); on the Research Section Committee (1974–1977), the Conference Committee (1977–1978) and as a Member of Council (1976–1980). He was awarded the Guy Medal in Silver in 1980 for his contributions to statistical theory. His theoretical interests are listed in his CV as: criticism of formal Bayesian methods, design of experiments, large deviations, cross-validation, and coordinate-free multivariate analysis. -

Why Visualization? 2 the Critical Role of Visualization Methods for Data Analysis
1 Why Visualization? 2 The Critical Role of Visualization Methods for Data Analysis First effectively argued in the 1960s John Tukey, Frank Anscombe, Cuthbert Daniel, and others 3 The Critical Role of Visualization Methods for Data Analysis Part I Visual displays of data are essential for understanding the patterns in a dataset • determining which mathematical learning methods and models are appropriate • for the data Using mathematical methods and models, without understanding the patterns, risks missing important information in the data • incorrect conclusions • 4 The Critical Role of Visualization Methods for Data Analysis Part II But, one cannot get far with just visualization of the raw data Need the mathematical learning methods at the outset as well Fit mathematical structures to aid in visualizing the patterns in the data 5 The Critical Role of Visualization Methods for Data Analysis Mathematical methods and visualization methods are symbiotic. Both should be applied from the moment the data arrive. 6 About the Course: Technical It is really a course about how to analyze data Visualization methods Some attention to enhancing our ability to perceive important effects in using theses methods We will use R in class and for homework the highest honored and probably the most used language for data analysis • it’s free • We will use the trellis display very powerful visualization system for data analysis • implemented in R: lattice graphics package • There will be data everywhere, in class and in homework We will make a foray into big -

Study on Parameter Estimation Via Multistage Sampling with Applications
STUDY ON PARAMETER ESTIMATION VIA MULTI-STAGE SAMPLING WITH APPLICATIONS by Francis Bilson Darku APPROVED BY SUPERVISORY COMMITTEE: Bhargab Chattopadhyay, Co-Chair Frank Konietschke, Co-Chair Swati Biswas Pankaj K. Choudhary Copyright c 2018 Francis Bilson Darku All rights reserved This dissertation is dedicated to my family, fianc´eeand all who believed in me and have supported me one way or the other. STUDY ON PARAMETER ESTIMATION VIA MULTI-STAGE SAMPLING WITH APPLICATIONS by FRANCIS BILSON DARKU, BSc, MSc DISSERTATION Presented to the Faculty of The University of Texas at Dallas in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY IN STATISTICS THE UNIVERSITY OF TEXAS AT DALLAS August 2018 ACKNOWLEDGMENTS I take this opportunity to express my heartfelt gratitude to all who have influenced and guided me in producing this wonderful work. First and foremost, I would like to express my appreciation to Dr. Bhargab Chattopadhyay and Dr. Frank Konietschke for their immense guidance, support, advice and time throughout my journey as a PhD student. Their patience and tolerance made them very approachable at all times (literally). My thanks also goes to Dr. Swati Biswas and Dr. Pankaj Kumar Choudhary for serving on my advising committee, providing me with valuable feedback, and granting me the opportunities to serve as their teaching assistant. Furthermore, I am thankful to Dr. Ken Kelley of University of Notre Dame for his collaboration and advice on my future career. I would also like to acknowledge all the Statistics professors in the Department of Mathematical Sciences for the knowledge they imparted in me throughout my studies. -
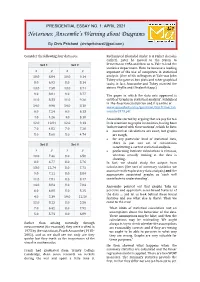
Notorious: Anscombe's Warning About Diagrams
PRESIDENTIAL ESSAY NO. 1: APRIL 2021 Notorious: Anscombe’s Warning about Diagrams By Chris Pritchard ([email protected]) Consider the following four data sets: Rothamsted (founded under R A Fisher decades earlier). Later he moved to the States, to Set 1 Set 2 Princeton in 1956 and then on to Yale to lead the statistics department. Here he became a leading x y x y exponent of the use of computers in statistical 10.0 8.04 10.0 9.14 analysis. (One of his colleagues at Yale was John Tukey who gave us box plots and other graphical 8.0 6.95 8.0 8.14 tools; in fact, Anscombe and Tukey married the 13.0 7.58 13.0 8.74 sisters Phyllis and Elizabeth Rapp.) 9.0 8.81 9.0 8.77 The paper in which the data sets appeared is 11.0 8.33 11.0 9.26 entitled ‘Graphs in statistical analysis’. Published in The American Statistician and it is online at 14.0 9.96 14.0 8.10 www.sjsu.edu/faculty/gerstman/StatPrimer/an 6.0 7.24 6.0 6.13 scombe1973.pdf 4.0 4.26 4.0 3.10 Anscombe started by arguing that we pay far too 12.0 10.84 12.0 9.13 little attention to graphs in statistics, having been ‘indoctrinated with these notions’, which he lists: 7.0 4.82 7.0 7.26 numerical calculations are exact, but graphs 5.0 5.68 5.0 4.74 are rough, for any particular kind of statistical data, Set 3 Set 4 there is just one set of calculations constituting a correct statistical analysis, x y x y performing intricate calculations is virtuous, 10.0 7.46 8.0 6.58 whereas actually looking at the data is cheating. -

Practical Data Analysis with JMP®, Second Edition
Practical Data Analysis with JMP ® Second Edition Robert H. Carver From Practical Data Analysis with JMP®, Second Edition. Full book available for purchase here. Contents About This Book ..................................................................................... xiii About The Author .................................................................................. xxiii Chapter 1 Getting Started: Data Analysis with JMP ................................... 1 Overview .......................................................................................................................................... 1 Goals of Data Analysis: Description and Inference .................................................................... 2 Types of Data .................................................................................................................................. 3 Starting JMP ................................................................................................................................... 4 A Simple Data Table ....................................................................................................................... 5 Graph Builder: An Interactive Tool to Explore Data ................................................................... 9 Using an Analysis Platform ......................................................................................................... 12 Row States ................................................................................................................................... -

Unbiased Estimates of the Wage Equation When Individuals Choose Among Income-Earning Activities
A Service of Leibniz-Informationszentrum econstor Wirtschaft Leibniz Information Centre Make Your Publications Visible. zbw for Economics Vyverberg, Wim P. M. Working Paper Unbiased Estimates of the Wage Equation When Individuals Choose Among Income-Earning Activities Center Discussion Paper, No. 429 Provided in Cooperation with: Economic Growth Center (EGC), Yale University Suggested Citation: Vyverberg, Wim P. M. (1982) : Unbiased Estimates of the Wage Equation When Individuals Choose Among Income-Earning Activities, Center Discussion Paper, No. 429, Yale University, Economic Growth Center, New Haven, CT This Version is available at: http://hdl.handle.net/10419/160353 Standard-Nutzungsbedingungen: Terms of use: Die Dokumente auf EconStor dürfen zu eigenen wissenschaftlichen Documents in EconStor may be saved and copied for your Zwecken und zum Privatgebrauch gespeichert und kopiert werden. personal and scholarly purposes. Sie dürfen die Dokumente nicht für öffentliche oder kommerzielle You are not to copy documents for public or commercial Zwecke vervielfältigen, öffentlich ausstellen, öffentlich zugänglich purposes, to exhibit the documents publicly, to make them machen, vertreiben oder anderweitig nutzen. publicly available on the internet, or to distribute or otherwise use the documents in public. Sofern die Verfasser die Dokumente unter Open-Content-Lizenzen (insbesondere CC-Lizenzen) zur Verfügung gestellt haben sollten, If the documents have been made available under an Open gelten abweichend von diesen Nutzungsbedingungen die in der dort Content Licence (especially Creative Commons Licences), you genannten Lizenz gewährten Nutzungsrechte. may exercise further usage rights as specified in the indicated licence. www.econstor.eu ECONOMIC GROWTH CENTER YALE UNIVERSITY Box 1987, Yale Station New Haven, Connecticut CENTER DISCUSSION PAPER NO. -

John W. Tukey: His Life and Professional Contributions1
The Annals of Statistics 2002, Vol. 30, No. 6, 1535–1575 JOHN W. TUKEY: HIS LIFE AND PROFESSIONAL CONTRIBUTIONS1 BY DAV ID R. BRILLINGER University of California, Berkeley As both practicing data analyst and scientific methodologist, John W. Tukey made an immense diversity of contributions to science, government and industry. This article reviews some of the highly varied aspects of his life. Following articles address specific contributions to important areas of statistics. I believe that the whole country—scientifically, industrially, financially—is better off because of him and bears evidence of his influence. John A. Wheeler, Princeton Professor of Physics Emeritus [65] 1. Introduction. John Wilder Tukey (JWT)—chemist, topologist, educator, consultant, information scientist, researcher, statistician, data analyst, executive— died of a heart attack on July 26, 2000 in New Brunswick, New Jersey. The death followed a short illness. Tukey was born in New Bedford, Massachusets on June 16, 1915. He was educated at home until commencing college. He obtained B.Sc. and M.Sc. degrees in chemistry from Brown University and then he went to graduate school at Princeton. At Princeton he obtained M.A. and Ph.D. degrees in mathematics. In 1985 at age 70 he retired from Bell Telephone Laboratories and from teaching at Princeton University with a “Sunset salvo” [97]. While JWT’s graduate work was mainly in pure mathematics, the advent of World War II led him to focus on practical problems facing his nation and thereafter to revolutionize methods for the analysis of data. This encompasses most everything nowadays. At the end of the War he began a joint industrial- academic career at Bell Telephone Laboratories, Murray Hill and at Princeton University.