Release Engineering How Google Builds and Delivers Software
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Modisco: a Model Driven Reverse Engineering Framework Hugo Bruneliere, Jordi Cabot, Grégoire Dupé, Frédéric Madiot
MoDisco: a Model Driven Reverse Engineering Framework Hugo Bruneliere, Jordi Cabot, Grégoire Dupé, Frédéric Madiot To cite this version: Hugo Bruneliere, Jordi Cabot, Grégoire Dupé, Frédéric Madiot. MoDisco: a Model Driven Reverse Engineering Framework. Information and Software Technology, Elsevier, 2014, 56 (8), pp.1012-1032. 10.1016/j.infsof.2014.04.007. hal-00972632 HAL Id: hal-00972632 https://hal.inria.fr/hal-00972632 Submitted on 7 Apr 2014 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. MoDisco: a Model Driven Reverse Engineering Framework Hugo Bruneli`erea,1,∗, Jordi Cabota, Gr´egoire Dup´eb, Fr´ed´eric Madiotc aAtlanMod (Inria & LINA), Ecole des Mines de Nantes, 4 rue Alfred Kastler, 44307 Nantes, France bMia-Software, 4 rue du Chateau de l’Eraudi`ere, 44324 Nantes, France cObeo, 7 boulevard Amp`ere, Espace Performance La Fleuriaye, 44481 Carquefou, France Abstract Context: Most companies, independently of their size and activity type, are facing the problem of managing, maintaining and/or replacing (part of) their existing software systems. These legacy systems are often large applications playing a critical role in the company’s information system and with a non-negligible impact on its daily operations. -

Rugby - a Process Model for Continuous Software Engineering
INSTITUT FUR¨ INFORMATIK DER TECHNISCHEN UNIVERSITAT¨ MUNCHEN¨ Forschungs- und Lehreinheit I Angewandte Softwaretechnik Rugby - A Process Model for Continuous Software Engineering Stephan Tobias Krusche Vollstandiger¨ Abdruck der von der Fakultat¨ fur¨ Informatik der Technischen Universitat¨ Munchen¨ zur Erlangung des akademischen Grades eines Doktors der Naturwissenschaften (Dr. rer. nat.) genehmigten Dissertation. Vorsitzender: Univ.-Prof. Dr. Helmut Seidl Prufer¨ der Dissertation: 1. Univ.-Prof. Bernd Brugge,¨ Ph.D. 2. Prof. Dr. Jurgen¨ Borstler,¨ Blekinge Institute of Technology, Karlskrona, Schweden Die Dissertation wurde am 28.01.2016 bei der Technischen Universitat¨ Munchen¨ eingereicht und durch die Fakultat¨ fur¨ Informatik am 29.02.2016 angenommen. Abstract Software is developed in increasingly dynamic environments. Organizations need the capability to deal with uncertainty and to react to unexpected changes in require- ments and technologies. Agile methods already improve the flexibility towards changes and with the emergence of continuous delivery, regular feedback loops have become possible. The abilities to maintain high code quality through reviews, to regularly re- lease software, and to collect and prioritize user feedback, are necessary for con- tinuous software engineering. However, there exists no uniform process model that handles the increasing number of reviews, releases and feedback reports. In this dissertation, we describe Rugby, a process model for continuous software en- gineering that is based on a meta model, which treats development activities as parallel workflows and which allows tailoring, customization and extension. Rugby includes a change model and treats changes as events that activate workflows. It integrates re- view management, release management, and feedback management as workflows. As a consequence, Rugby handles the increasing number of reviews, releases and feedback and at the same time decreases their size and effort. -

Enterprise Architecture
Enterprise Architecture Dr. Adnan Albar Faculty of Computing & Information Technology King AbdulAziz University - Jeddah 1 Enterprise Architecture Methods Lecture 5 Week 5 Slides King AbdulAziz University - FCIT 2 Overview . Description Languages for Business & IT Domains . IDEF . BPMN . Testbed . ARIS . Unified Modeling Language . Service-Oriented Architecture (SOA) Slide 3 Description Languages . In domains such as business process design and software development, we find established description languages for modeling these domains. For software modeling, UML is of course, the single dominant language. In organization and process modeling, on the other hand, a multitude of languages are in use: there is no standard for models in this domain. We will focus on languages that either find widespread use or have properties that are interesting from the perspective of our goals in developing an enterprise architecture language. Slide 4 IDEF – Integrated DEFinition Methods .IDEF is a family of languages .Used to perform enterprise modeling and analysis .Currently, there are 16 IDEF methods. Of these methods, IDEF0, IDEF3, and IDEF1X (‘the core’) are the most commonly used. Slide 5 IDEF – The Scope it Covers .Functional modeling, IDEF0: The idea behind IDEF0 is to model the elements controlling the execution of a function, the actors performing the function, the objects or data consumed and produced by the function, and the relationships between business functions (shared resources and dependencies). .Process modeling, IDEF3: IDEF3 captures the workflow of a business process via process flow diagrams. These show the task sequence for processes performed by the organization, the decision logic, describe different scenarios for performing the same business functions, and enable the analysis and improvement of the workflow. -

D1.1.1 Public State of the Art Document
D1.1.1 Public state of the art document Programme ITEA3 Challenge Smart Engineering Project number 17038 Project name Visual diagnosis for DevOps software development Project duration 1st October 2018 – 30st June 2022 Project website Project WP WP1 - Pre-studies and requirements Project Task Task 1.1 – Update of state-of-art and state-of-the practice analysis for visualization in software projects in DevOps context Deliverable type X Doc Textual deliverable SW Software deliverable Version V17 Delivered 18/11/2019 Access x Public Abstracts are public Confidential D1.1.1 Public state of the art document Document Contributors Partber Author Role EXPERIS Ester Sancho editor EXPERIS Miriam Moreno writer GRO Paris Avgeriou writer INVENCO Mika Koivuluoma writer OCE Lou Somers writer/reviewer OULU Markus Kelanti writer TAU Kari Systä writer/reviewer TAU Outi Sievi-Korte writer/reviewer TIOBE Paul Jansen writer TIOBE Marvin Wener writer UPC Lidia López writer UPC Xavier Franch writer VINCIT Veli-Pekka Eloranta writer Document History Date Version Editors Status 18/06/2019 ToC EXPERIS Table of Content 10/07/2019 V01 TAU Draft 30/09/2019 V02 OCE/GRO Draft 17/10/2019 V06 TIOBE Draft 22/10/2019 V08 OULU Draft 12/11/2019 V09 VINCIT 1ST Final Draft 20/11/2019 V10 OCE Reviewed version 26/11/2019 V12 UPC/EXPERIS/TAU 2nd Final Draft 10/12/2019 V16 EXPERIS Final Version 16/12/2019 V16.01 TAU Peer Review 18/12/2019 V17 EXPERIS Submission 2 D1.1.1 Public state of the art document Table of Contents Executive Summary ............................................................................................................................. 6 1. -
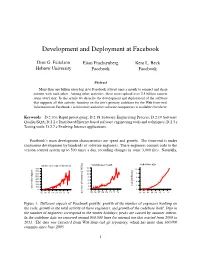
Development and Deployment at Facebook
Development and Deployment at Facebook Dror G. Feitelson Eitan Frachtenberg Kent L. Beck Hebrew University Facebook Facebook Abstract More than one billion users log in to Facebook at least once a month to connect and share content with each other. Among other activities, these users upload over 2.5 billion content items every day. In this article we describe the development and deployment of the software that supports all this activity, focusing on the site’s primary codebase for the Web front-end. Information on Facebook’s architecture and other software components is available elsewhere. Keywords D.2.10.i Rapid prototyping; D.2.18 Software Engineering Process; D.2.19 Software Quality/SQA; D.2.2.c Distributed/Internet based software engineering tools and techniques; D.2.5.r Testing tools; D.2.7.e Evolving Internet applications. Facebook’s main development characteristics are speed and growth. The front-end is under continuous development by hundreds of software engineers. These engineers commit code to the version control system up to 500 times a day, recording changes in some 3,000 files. Naturally, codebase size unique developers by week commits per month 14 800 10 700 12 600 10 8 500 8 6 400 6 300 4 4 200 LoC [millions] 2 100 2 active developers 0 0 0 ’05 ’06 ’07 ’08 ’09 ’10 ’11 ’12 ’05 ’06 ’07 ’08 ’09 ’10 ’11 ’12 number of commits [1000s] ’05 ’06 ’07 ’08 ’09 ’10 ’11 ’12 Figure 1: Different aspects of Facebook growth: growth of the number of engineers working on the code, growth in the total activity of these engineers, and growth of the codebase itself. -

Release Engineering Processes, Models, and Metrics
Release Engineering Processes, Models, and Metrics Hyrum K. Wright Empirical Software Engineering Laboratory Department of Electrical and Computer Engineering The University of Texas at Austin Austin, Texas 78712 [email protected] ABSTRACT The primary goal of this research is to develop techniques, No matter the development process or methodology, a soft- methods, metrics and processes whereby the release engi- ware product must ultimately be released to a user in a neering process can be quantitatively measured, reasoned readily consumable form. Different software products, from about, and improved. Such techniques will benefit the soft- desktop applications to web services, may require different ware industry by reducing release process overhead, and im- release processes, but each process must produce an arti- proving the quality of the release artifact. This paper gives fact which meets an expected level of quality, and is rela- a brief background of release engineering as a practice, the tively bug-free. We describe current research to model and existing research in this area, and how we intend to proceed quantify existing release processes, and an effort to prescribe toward our goals. improvements to those processes. 2. BACKGROUND Categories and Subject Descriptors Release engineering is the part of the software engineer- ing process during which the release artifact, usually an ex- D.2.9 [Software Engineering]: Management|software pro- ecutable, installer, library or source code package, is pro- cess models; D.2.7 [Software Engineering]: Distribution, duced. In traditional software development methodologies, Maintenance, Enhancement|release creation and distribu- such as the spiral or waterfall models, release engineering tion comes as part of the deployment and maintenance phases [1, 8]. -

Who Needs Release and Devops Engineers, and Why?
Who Needs Release and DevOps Engineers, and Why? Noureddine Kerzazi Bram Adams ENSIAS, Mohammed V University in Rabat MCIS, Polytechnique Montreal [email protected] [email protected] ABSTRACT role overseeing and planning the transfer of deliverables to- The recent surge in interest in continuous delivery has opened wards the production environment? Penners et al. [7] found up the job market for release and DevOps engineers. How- that the experts consulted by them did not share a unique ever, despite an increasing number of conferences and publi- interpretation of the DevOps and release engineering roles, cations on continuous delivery, smaller companies and start- while Bass et al. [4] even define DevOps in terms of release ups still have a hard time determining the core tasks their engineering, i.e., \DevOps is a set of practices intended to future release and DevOps engineers should be responsible reduce the time between committing a change to a system for (and what the differences between those two roles are), and the change being placed into normal production, while while universities are not sure what essential techniques and ensuring high quality." skills they should teach to their students. This paper per- The Capability Maturity Model Integration (CMMI) de- forms an empirical analysis of online job postings to deter- scribes Release Management as emphasizing the Product In- mine and compare the main tasks of release and DevOps tegration (PI) process area [12]. The purpose of PI is to as- engineers, globally and across countries. Our qualitative semble the product from product components, to ensure that analysis shows that automation is the most important ac- the integrated product works properly, then to deliver it. -

Methodology Project Release Processes Overview References
Release Engineering Processes in Open Source Projects Hyrum K. Wright and Dewayne E. Perry Emperical Software Engineering Laboratory Department of Electrical and Computer Engineering The University of Texas at Austin {hwright,perry}@ece.utexas.edu Overview Project Release Processes Methodology elease engineering is the part of the software engineering GCC release process e have begun a qualitative study the evolution of the re- Linux pre-2.6 release process process during which the release artifact, usually an exe- ... lease process for three specific open source projects: the R 4.2.0 4.2.1 4.2.2 4.2.3 4.2.4 4.3.0 W ... ... cutable, installer, or source code package, is produced. In tradi- 2.5.0 2.5.1 Linux Kernel; the Subversion version control system; and the 2.3.0 2.3.1 2.3.2 2.3.3 2.3.4 2.3.5 2.3.6 2.3.7 2.3.75 tional software development methodologies, such as the spiral Gnu Compiler Collection (GCC). Each project organization has or waterfall models, release engineering comes as part of the re- ... ... significantly changed the release management process during 4.2 branchedStage 1 Stage 2 Stage 3 4.3 branchedStage 1 lease and maintenance phases. In recent years, commercial and ... ... their history, allowing us to study how process changes affected 2.2.0 2.2.1 2.2.2 2.2.3 2.2.4 2.2.5 2.2.28 2.4.0 open source software projects have begun to employ dedicated 2.4.1 the release artifact. -

Systed. Volue 4: Design Of
NASA CR-132hO4 FEASIBILITY STUDY OF AN INTEGRATED PROGRAM FOR AEROSPACE-VEHICLE DESIGN (IPAD) SYSTEM by C. A. Garrocq, M. J. Hurley et al VOLUME IV DESIGN OF THE IPAD SYSTEM PART I - IPAD SYSTEM DESIGN REQUIREMENTS (PHASE I, TASK 2) 20 August 1973 Publicly Released February 10, 1978 -l Prepared Under Contract No.NAS-1-11431 by - NERAL DYNAMICS/CONVAIR AEROSPACE DIVISION C% San Diego, California NATIONAL AERONAUTICS AND SPACE ADMINISTRIO1 (NASA-CR-L132qoq) FEASIBILITY STUDY OF AN N78-16007 INTEGRATED PROGRAM FOR AEROSPACE-VEHICLE DESIGN (IPtfl),SYSTED. VOLUE 4: DESIGN OF . 1/r OT THE IPAD SYSTEM. PART 1: IPAD SYSTEM Unclas SDESIGN_ (General Dynamics/Convair) 250 p HC'03/02 02561 FEASIBILITY STUDY OF AN INTEGRATED PROGRAM FOR AEROSPACE-VEHICLE DESIGN (IPAD) SYSTEM VOLUME I - SUMMARY VOLUME II - CHARACTERIZATION OF THE IPAD SYSTEM (PHASE I, TASK 1) VOLUME III - ENGINEERING CREATIVE/EVALUATION PROCESSES (PHASE I, TASK 1) VOLUME IV - DESIGN OF THE IPAD SYSTEM PART I - IPAD SYSTEM DESIGN REQUIREMENTS (PHASE I, TASK 2) VOLUME V - DESIGN OF THE IPAD SYSTEM PART II - SYSTEM DESIGN PART III - GENERAL PURPOSE UTILITIES (PHASE I, TASK 2) VOLUME VI - IMPLEMENTATION SCHEDULE DEVELOPMENT COSTS OPERATIONAL COSTS BENEFIT ASSESSMENT IMPACT ON COMPANY ORGANIZATION SPIN-OFF ASSESSMENT (PHASE II, TASKS 3 to 8) FOREWORD This investigation was conducted for the NASA Langley Research Center by the Convair Aerospace Division of General Dynamics Corpo ration under Contract NAS 1-11431. The NASA Technical Monitor was Dr. R. E. Fulton, Head, IPAD Technology Section, Design Technology Branch, Structures and Dynamics Division, assisted by Dr. J. -

Release Engineering Practices and Pitfalls
Release Engineering Practices and Pitfalls Hyrum K. Wright and Dewayne E. Perry Dept. of Electrical and Computer Engineering The University of Texas at Austin Austin, Texas hyrum [email protected], [email protected] Abstract—The release and deployment phase of the software II. BACKGROUND development process is often overlooked as part of broader software engineering research. In this paper, we discuss early Release engineering has not historically received very results from a set of multiple semi-structured interviews much attention in the software engineering research commu- with practicing release engineers. Subjects for the interviews nity. There have been piecemeal efforts to describe various are drawn from a number of different commercial software development organizations, and our interviews focus on why aspects of release, but nothing holistic. Even the definition of release process faults and failures occur, how organizations “release engineering” is not very well articulated. This sec- recover from them, and how they can be predicted, avoided tion outlines our working definition for release engineering or prevented in the future. Along the way, the interviews and processes, as well as selected prior work in the area. provide insight into the state of release engineering today, This work is not the first effort to examine project release and interesting relationships between software architecture and release processes. processes, but does have a much wider scope than previous studies. Both Erenkrantz and Wright examined the release Keywords-release engineering; software process processes of specific software projects [1], [2]. Other work attempted to mine the version control system and bug tracker for a single project to develop a release history for that I. -

Releasing Fast and Slow
Releasing Fast and Slow Characterizing Rapid Releases in a Large Software-Driven Organization Technische Universiteit Delft Elvan Kula Releasing Fast and Slow Characterizing Rapid Releases in a Large Software-Driven Organization by Elvan Kula to obtain the degree of Master of Science at the Delft University of Technology, to be defended publicly on Wednesday May 15, 2019 at 16:30 PM. Student number: 4194217 Project duration: February 12, 2018 – September 1, 2018 March 1, 2019 – May 5, 2019 Thesis committee: Assistant Prof. Dr. Georgios Gousios, TU Delft, supervisor Full Prof. Dr. Arie van Deursen, TU Delft Assistant Prof. Dr. Asterios Katsifodimos, TU Delft An electronic version of this thesis is available at http://repository.tudelft.nl/. Abstract The appeal of delivering new features faster has led many software projects to change their development processes towards rapid release models. Even though rapid releases are in- creasingly being adopted in open-source and commercial software, it is not well understood what the effects are of this practice. This thesis presents an exploratory case study of rapid releases at ING, a large banking com- pany that develops software solutions in-house, to characterize rapid releases. Since 2011, ING has shifted to a rapid release model. This switch has resulted in a mixed environment of 611 teams releasing relatively fast and slow. We followed a mixed-methods approach in which we conducted a survey with 461 participants and corroborated their perceptions with two years of code quality data and one -

A Roundtable with Three Release Engineers
FOCUS: GUEST EDITORS’ INTRODUCTION The Practice and Future of Release Engineering A Roundtable with Three Release Engineers Bram Adams, Polytechnique Montréal // Stephany Bellomo, Software Engineering Institute // Christian Bird, Microsoft Research // Tamara Marshall-Keim, Software Engineering Institute // Foutse Khomh, Polytechnique Montréal // Kim Moir, Mozilla RELEASE ENGINEERING focuses manager; and Kim Moir, a release us to gauge the overall release health on building a pipeline that transforms engineer. We asked each of them of a service; the third measure can source code into an integrated, com- the same questions covering topics uncover issues in the testing pipe- piled, packaged, tested, and signed such as release- engineering metrics, line or growing code complexity. We product that’s ready for release. The continuous delivery’s bene ts and track these metrics and make com- pipeline’s input is the source code de- limitations, the required job skills, parisons from quarter to quarter. velopers write to create a product or the required changes in education, Related to testing, another metric modify an existing one. Enterprises and recommendations for future is the greenness of the testing pipe- running large-scale websites and de- research. line. Many tests, from code to perfor- livering mobile applications with mil- mance tests, are run daily in a con- lions of users must rely on a robust Every product release must meet an tinuous fashion. Stability of tests is a release pipeline to ensure they can expected level of quality, and release signal of product maturity and good deliver and update their products to processes undergo continual ne- engineering practices. Despite some new and existing customers, at the tuning.