T05-1.Pdf (101,6Kb)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

GIT—A Stupid Content Tracker
GIT—A Stupid Content Tracker Junio C. Hamano Twin Sun, Inc. [email protected] Abstract The paper gives an overview of how git evolved and discusses the strengths and weaknesses of its design. Git was hurriedly hacked together by Linus Torvalds, after the Linux kernel project lost its license to use BitKeeper as its source code management system (SCM). It has since 1 Low level design quickly grown to become capable of managing the Linux kernel project source code. Other projects have started to replace their existing Git is a “stupid content tracker.” It is designed SCMs with it. to record and compare the whole tree states ef- ficiently. Unlike traditional source code control Among interesting things that it does are: systems, its data structures are not geared to- ward recording changes between revisions, but for making it efficient to retrieve the state of in- 1. giving a quick whole-tree diff, dividual revisions. 2. quick, simple, stupid-but-safe merge, The unit in git storage is an object. It records: 3. facilitating e-mail based patch exchange workflow, and • blob – the contents of a file (either the 4. helping to pin-point the change that caused contents of a regular file, or the path a particular bug by a bisection search in pointed at by a symbolic link). the development history. • tree – the contents of a directory, by recording the mapping from names to ob- The core git functionality is implemented as a jects (either a blob object or a tree object set of programs to allow higher-layer systems that represents a subdirectory). -

Bazaar, Das DVCS
Bazaar, das DVCS Marek Kubica 20. November 2008 Marek Kubica Bazaar, das DVCS Vorweg ein paar Infos Mit was ich so spiele Bazaar in der Arbeit Mercurial für Python-Projekte Git für den Rest Welche Spielzeuge lass ich links liegen CVS wozu noch wo es SVN gibt? SVN wozu noch wenn es DVCS gibt? darcs lohnt sich nicht mehr monotone, codeville, arch obsolete das selbsgehackte, tolle DVCS deines Nachbarn ;) Marek Kubica Bazaar, das DVCS Geschichte In the beginning, there was GNU Arch Marek Kubica Bazaar, das DVCS GNU Arch Die Anfänge von DVCS CVS stinkt, wir brauchen was besseres SVN ist Evolution, keine Revolution GNU Arch war das erste DVCS mit dem ich in Kontakt kam (larch) fürchterlich kompliziert wurde dann von tla ersetzt immer noch fürchterlich Canonical hat tla 1.2 geforkt und Bazaar, baz genannt Paralell dazu: revc = Arch 2.0 Marek Kubica Bazaar, das DVCS Baz als Rettung? Von heiÿen Kartoeln baz war in C Was passiert: Canonical ruft Bazaar-NG ins Leben, bzr, lässt baz fallen Bazaar-NG wird in Bazaar umgetauft baz ist tot, tla ist tot, larch ist tot, revc ist bedeutungslos Hurra, GNU Arch ist endlich tot, es lebe bzr! Marek Kubica Bazaar, das DVCS bzr, der Retter Was bietet Bazaar? in Python geschrieben, mit einigen Speedups in Pyrex (C) reguläre Releases (quasi jeden Monat) Einfache Bedienung Meist ausreichende Performance Umfangreiche Dokumentation: Programmmeldungen, Manpages, Wiki, IRC-Channel (wenn man Geduld hat) Flexible Einsatzmöglichkeiten (verschiedene Workows) 1 Git mit Bazaar simulieren 2 SVN in Bazaar nachbauen (für Nostalgiker) freier Hoster wo man Code hochladen kann (Launchpad) Marek Kubica Bazaar, das DVCS Zeitleiste 2005 war eine aufregende Zeit 26. -

Analysis and Comparison of Distributed Version Control Systems
Fachhochschul-Bachelorstudiengang SOFTWARE ENGINEERING A-4232 Hagenberg, Austria Analysis and Comparison of Distributed Version Control Systems Bachelorarbeit Teil 1 zur Erlangung des akademischen Grades Bachelor of Science in Engineering Eingereicht von Daniel Knittl-Frank Begutachter: DI Dr. Stefan Wagner Hagenberg, Juni 2010 Contents Abstract iii Kurzfassung iv 1 Introduction1 1.1 Motivation............................1 1.2 Goals...............................2 1.3 Content..............................2 2 Version Control in General3 2.1 Workflows.............................4 2.2 Foundations............................5 2.2.1 Glossary..........................5 2.2.2 Repository........................6 2.2.3 Working Directory....................7 2.2.4 Diff and Patch......................7 2.2.5 Merge...........................9 2.2.6 Mainline, Branches and Tags.............. 12 3 Centralized Version Control 14 3.1 Tools................................ 14 3.1.1 CVS............................ 14 3.1.2 Subversion........................ 15 4 Distributed Version Control 17 4.1 Differences............................. 17 4.2 Concepts............................. 19 4.2.1 Revision identifiers.................... 20 4.2.2 Integrity.......................... 20 4.2.3 History representation.................. 21 4.3 Tools................................ 21 4.3.1 Bazaar........................... 22 4.3.2 Git............................. 27 4.3.3 Mercurial......................... 32 i Contents ii 5 Comparison 38 5.1 Testing Scenario......................... 38 5.2 Results............................... 38 6 Conclusion 46 Abstract Version and configuration control systems have played an essential role in software development for the last decades. Starting with the new millennium a new trend surfaced, distributed version control: dedicated central servers for few authorized users lose importance in favor of a more dynamic workflow, in which every developer works with a copy of a project's complete history and changes are synchronized ad-hoc between developers. -

J2EETM Deployment: the Jonas Case Study
J2EETM Deployment: The JOnAS Case Study François Exertier Bull, 1, rue de Provence BP 208 38432 Echirolles Cedex [email protected] RÉSUMÉ. La spécification J2EE (Java 2 platform Enterprise Edition) définit une architecture de serveur d'application Java. Jusqu'à J2EE 1.3, seuls les aspects de déploiement concernant le développeur d'applications étaient adressés. Avec J2EE 1.4, les interfaces et les étapes de déploiement ont été plus précisément spécifiées dans la spécification "J2EE Deployment". JOnAS (Java Open Application Server) est une plate-forme J2EE développée au sein du consortium ObjectWeb. Les aspects déploiement sont en cours de développement. Cet article décrit les concepts liés au déploiement dans J2EE, ainsi que les problématiques levées lors de leur mise en œuvre pour JOnAS. Il n'a pas pour but de présenter un travail abouti, mais illustre le déploiement par un cas concret et ébauche une liste de besoins non encore satisfaits dans le domaine. ABSTRACT. The J2EE (Java 2 platform Enterprise Edition) specification defines an architecture for Java Application Servers. Until J2EE 1.3, the deployment aspect was addressed from the developer point of view only. Since J2EE 1.4, deployment APIs and steps have been more precisely specified within the "J2EE Deployment Specification". JOnAS (Java Open Application Server) is a J2EE platform implementation by ObjectWeb. The deployment aspects are under development. This article describes the J2EE Deployment concepts, and the issues raised when implementing deployment features within JOnAS. It does not provide a complete solution, but illustrates deployment through a concrete example and initiates a list of non fulfilled requirements. -

Linux-Cookbook.Pdf
LINUX COOKBOOK ™ Other Linux resources from O’Reilly Related titles Linux Device Drivers Exploring the JDS Linux Linux in a Nutshell Desktop Running Linux Learning Red Hat Enterprise Building Embedded Linux Linux and Fedora Systems Linux Pocket Guide Linux Security Cookbook Understanding the Linux Kernel Linux Books linux.oreilly.com is a complete catalog of O’Reilly’s books on Resource Center Linux and Unix and related technologies, including sample chapters and code examples. ONLamp.com is the premier site for the open source web plat- form: Linux, Apache, MySQL, and either Perl, Python, or PHP. Conferences O’Reilly brings diverse innovators together to nurture the ideas that spark revolutionary industries. We specialize in document- ing the latest tools and systems, translating the innovator’s knowledge into useful skills for those in the trenches. Visit conferences.oreilly.com for our upcoming events. Safari Bookshelf (safari.oreilly.com) is the premier online refer- ence library for programmers and IT professionals. Conduct searches across more than 1,000 books. Subscribers can zero in on answers to time-critical questions in a matter of seconds. Read the books on your Bookshelf from cover to cover or sim- ply flip to the page you need. Try it today with a free trial. LINUX COOKBOOK ™ Carla Schroder Beijing • Cambridge • Farnham • Köln • Paris • Sebastopol • Taipei • Tokyo Linux Cookbook™ by Carla Schroder Copyright © 2005 O’Reilly Media, Inc. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. -

SCM: a Look at Scons and GNU Arch
SCM: A look at SCons and GNU Arch ¡ ¢ £ ¤ ¥ Ben Leslie ¦ § ¡ ¨ © ¢ § ¨ ¡ © ¨ © 1 WHAT IS SCM? CM is the discpline of controlling the evolution of complex systems; SCM is its specialization for computer programs and associated documents WHAT IS SCM? 2 WHAT IS SCM? CM is the discpline of controlling the evolution of complex systems; SCM is its specialization for computer programs and associated documents No really, what is it ? WHAT IS SCM? 2-A WHAT IS SCM? CM is the discpline of controlling the evolution of complex systems; SCM is its specialization for computer programs and associated documents No really, what is it ? • Versioning WHAT IS SCM? 2-B WHAT IS SCM? CM is the discpline of controlling the evolution of complex systems; SCM is its specialization for computer programs and associated documents No really, what is it ? • Versioning • Building WHAT IS SCM? 2-C BUILD SYSTEM – PURPOSE Automate construction process • Build rules – how to change .c into .o • Capture all build rules Rebuild exactly what is needed BUILD SYSTEM – PURPOSE 3 BUILD SYSTEM – PURPOSE Automate construction process • Build rules – how to change .c into .o • Capture all build rules Rebuild exactly what is needed • Build everything required – correctness. BUILD SYSTEM – PURPOSE 3-A BUILD SYSTEM – PURPOSE Automate construction process • Build rules – how to change .c into .o • Capture all build rules Rebuild exactly what is needed • Build everything required – correctness. • Don’t build anymore then needed – performance. BUILD SYSTEM – PURPOSE 3-B BUILD SYSTEM – PURPOSE Automate construction process • Build rules – how to change .c into .o • Capture all build rules Rebuild exactly what is needed • Build everything required – correctness. -

Jonas 5 Commands Reference Guide
JOnAS 5 Commands Reference Guide This document describes all the commands that can be used with JOnAS JOnAS Team ( François FORNACIARI) - March 2009 - Copyright © OW2 Consortium 2008-2009 This work is licensed under the Creative Commons Attribution-ShareAlike License. To view a copy of this license,visit http://creativecommons.org/licenses/by-sa/2.0/deed.en or send a letter to Creative Commons, 559 Nathan Abbott Way, Stanford, California 94305, USA. Table of Contents 1. jonas command ......................................................................................................... 1 1.1. jonas start ...................................................................................................... 1 1.1.1. Options ............................................................................................... 1 1.1.2. Description .......................................................................................... 2 1.2. jonas stop ...................................................................................................... 2 1.2.1. Options ............................................................................................... 2 1.2.2. Description .......................................................................................... 2 1.3. jonas admin ................................................................................................... 2 1.3.1. Synopsis ............................................................................................. 3 1.3.2. Description ......................................................................................... -
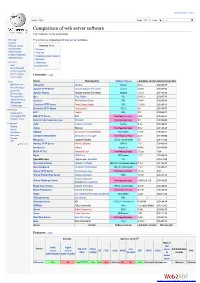
Comparison of Web Server Software from Wikipedia, the Free Encyclopedia
Create account Log in Article Talk Read Edit ViewM ohrisetory Search Comparison of web server software From Wikipedia, the free encyclopedia Main page This article is a comparison of web server software. Contents Featured content Contents [hide] Current events 1 Overview Random article 2 Features Donate to Wikipedia 3 Operating system support Wikimedia Shop 4 See also Interaction 5 References Help 6 External links About Wikipedia Community portal Recent changes Overview [edit] Contact page Tools Server Developed by Software license Last stable version Latest release date What links here AOLserver NaviSoft Mozilla 4.5.2 2012-09-19 Related changes Apache HTTP Server Apache Software Foundation Apache 2.4.10 2014-07-21 Upload file Special pages Apache Tomcat Apache Software Foundation Apache 7.0.53 2014-03-30 Permanent link Boa Paul Phillips GPL 0.94.13 2002-07-30 Page information Caudium The Caudium Group GPL 1.4.18 2012-02-24 Wikidata item Cite this page Cherokee HTTP Server Álvaro López Ortega GPL 1.2.103 2013-04-21 Hiawatha HTTP Server Hugo Leisink GPLv2 9.6 2014-06-01 Print/export Create a book HFS Rejetto GPL 2.2f 2009-02-17 Download as PDF IBM HTTP Server IBM Non-free proprietary 8.5.5 2013-06-14 Printable version Internet Information Services Microsoft Non-free proprietary 8.5 2013-09-09 Languages Jetty Eclipse Foundation Apache 9.1.4 2014-04-01 Čeština Jexus Bing Liu Non-free proprietary 5.5.2 2014-04-27 Galego Nederlands lighttpd Jan Kneschke (Incremental) BSD variant 1.4.35 2014-03-12 Português LiteSpeed Web Server LiteSpeed Technologies Non-free proprietary 4.2.3 2013-05-22 Русский Mongoose Cesanta Software GPLv2 / commercial 5.5 2014-10-28 中文 Edit links Monkey HTTP Server Monkey Software LGPLv2 1.5.1 2014-06-10 NaviServer Various Mozilla 1.1 4.99.6 2014-06-29 NCSA HTTPd Robert McCool Non-free proprietary 1.5.2a 1996 Nginx NGINX, Inc. -

Git and Gerrit in Action and Lessons Learned Along the Path to Distributed Version Control
Git and Gerrit in Action And lessons learned along the path to distributed version control Chris Aniszczyk (Red Hat) Principal Software Engineer [email protected] http://aniszczyk.org About Me I've been using and hacking open source for ~12 years - contribute{d} to Gentoo Linux, Fedora Linux, Eclipse Hack on Eclipse, Git and other things at Red Hat Member of the Eclipse Board of Directors Member in the Eclipse Architecture Council I like to run! (2 mins short of Boston qualifying ;/) Co-author of RCP Book (www.eclipsercp.org) An Introduction to Git and Gerrit | © 2011 by Chris Aniszczyk Agenda History of Version Control (VCS) The Rise of Distributed Version Control (DVCS) Code Review with Git and Gerrit Lessons Learned at Eclipse moving to a DVCS Conclusion Q&A An Introduction to Git and Gerrit | © 2011 by Chris Aniszczyk Version Control Version Control Systems manage change “The only constant is change” (Heraclitus) An Introduction to Git and Gerrit | © 2011 by Chris Aniszczyk Why Version Control? VCS became essential to software development because: They allow teams to collaborate They manage change and allow for inspection They track ownership They track evolution of changes They allow for branching They allow for continuous integration An Introduction to Git and Gerrit | © 2011 by Chris Aniszczyk Version Control: The Ancients 1972 – Source Code Control System (SCCS) Born out of Bell Labs, based on interleaved deltas No open source implementations as far as I know 1982 – Revision Control System (RCS) Released as an alternative to SCCS -

Third-Party Copyright Notices and Licenses
Third-Party Copyright Notices and Licenses For Intel® Omni-Path Software The following is a list of third party licenses that Intel has operated under in the course of producing Intel® Omni-Path Software. BSD 2-clause License ............................................................................................................. 4 RedHat shim ...................................................................................................................... 4 EFI Developer Kit (EDK) ...................................................................................................... 4 EFI Developer Kit II (EDK II) ................................................................................................ 5 BSD 3-clause License ............................................................................................................. 6 Automatically Tuned Linear Algebra Software ......................................................................... 6 chashtable ......................................................................................................................... 6 FreeBSD ............................................................................................................................ 7 HPC Challenge Benchmark ................................................................................................... 7 HyperSQL Database Engine (HSQLDB) ................................................................................... 8 jgraphx ............................................................................................................................ -

Oracle Communications Policy Management Licensing Information User Manual Release 12.5 Copyright © 2011, 2019, Oracle And/Or Its Affiliates
Oracle® Communications Policy Management Licensing Information User Manual Release 12.5.1 F16918-02 October 2019 Oracle Communications Policy Management Licensing Information User Manual Release 12.5 Copyright © 2011, 2019, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are “commercial computer software” pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -

Open Source Used in Cisco Findit Network Probe, Version 2.0.0
Open Source Used In FindIT Network Probe 2.0.0.x Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-185721177 Open Source Used In FindIT Network Probe 2.0.0.x 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-185721177 En ce qui a trait au logiciel gratuit ou à exploitation libre figurant dans ce document, si vous avez des questions ou souhaitez recevoir une copie du code source, auquel vous avez droit en vertu des licences gratuites ou d'exploitation libre applicables (telles que licences GNU Lesser/General Public), veuillez communiquer avec nous à l'adresse external- [email protected]. Dans vos demandes, veuillez inclure le numéro de référence 78EE117C99-185721177 Contents 1.1 @ngx-translate/core 7.2.2 1.1.1 Available under license 1.2 @ngx-translate/http-loader 1.1.0 1.2.1 Available under license 1.3 angular 4.4.6 1.4 Angular Bootstrap 0.12.0 1.4.1 Available under license 1.5 Angular UI Sortable 1.1.1 1.5.1 Available under license