Module 12: an Olio of Topics in Applied Probabilistic Reasoning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Working Memory, Cognitive Miserliness and Logic As Predictors of Performance on the Cognitive Reflection Test
Working Memory, Cognitive Miserliness and Logic as Predictors of Performance on the Cognitive Reflection Test Edward J. N. Stupple ([email protected]) Centre for Psychological Research, University of Derby Kedleston Road, Derby. DE22 1GB Maggie Gale ([email protected]) Centre for Psychological Research, University of Derby Kedleston Road, Derby. DE22 1GB Christopher R. Richmond ([email protected]) Centre for Psychological Research, University of Derby Kedleston Road, Derby. DE22 1GB Abstract Most participants respond that the answer is 10 cents; however, a slower and more analytic approach to the The Cognitive Reflection Test (CRT) was devised to measure problem reveals the correct answer to be 5 cents. the inhibition of heuristic responses to favour analytic ones. The CRT has been a spectacular success, attracting more Toplak, West and Stanovich (2011) demonstrated that the than 100 citations in 2012 alone (Scopus). This may be in CRT was a powerful predictor of heuristics and biases task part due to the ease of administration; with only three items performance - proposing it as a metric of the cognitive miserliness central to dual process theories of thinking. This and no requirement for expensive equipment, the practical thesis was examined using reasoning response-times, advantages are considerable. There have, moreover, been normative responses from two reasoning tasks and working numerous correlates of the CRT demonstrated, from a wide memory capacity (WMC) to predict individual differences in range of tasks in the heuristics and biases literature (Toplak performance on the CRT. These data offered limited support et al., 2011) to risk aversion and SAT scores (Frederick, for the view of miserliness as the primary factor in the CRT. -

Bias and Politics
Bias and politics Luc Bonneux Koninklijke Nederlandse Academie van Wetenschappen NIDI / Den Haag What is bias? ! The assymmetry of a bowling ball. The size and form of the assymmetry will determine its route ! A process at any state of inference tending to produce results that depart systematically from the true values (Fletcher et al, 1988) ! Bias is SYSTEMATIC error Random versus systematic ! Random errors will cancel each other out in the long run (increasing sample size) ! Random error is imprecise ! Systematic errors will not cancel each other out whatever the sample size. Indeed, they will only be strenghtened ! Systematic error is inaccurate Types of bias ! Selection ! Intervention arm is systematically different from control arm ! Information (misclassification) ! Differential errors in measurement of exposure or outcome ! Confounding ! Distortion of exposure - case relation by third factor Experiment vs observation ! Randomisation disperses unknown variables at random between comparison groups ! Observational studies are ALLWAYS biased by known and unknown factors ! But you can understand and MITIGATE their effects Selection bias ! “Selective differences between comparison groups that impacts on relationship between exposure and outcome” Selection bias 1: Reverse causation ! “People engaging in vigorous activities are healthier than lazy ones.” ! “Bedridden people are less healthy than the ones engaging in vigorous activity” Lazy people include those that are unable to exercise because they are unhealthy Selection bias 2 ! Publicity -

Lecture Notes 2018
USMLE ® • UP-TO-DATE ® STEP 2 CK STEP Updated annually by Kaplan’s all-star faculty STEP2 CK • INTEGRATED Lecture Notes 2018 Notes Lecture Packed with bridges between specialties and basic science Lecture Notes 2018 • TRUSTED Psychiatry, Epidemiology, Ethics, Used by thousands of students each year to ace the exam USMLE Patient Safety Psychiatry, Epidemiology, Ethics, Patient Ethics, Epidemiology, Psychiatry, Safety Tell us what you think! Visit kaptest.com/booksfeedback and let us know about your book experience. ISBN: 978-1-5062-2821-1 kaplanmedical.com 9 7 8 1 5 0 6 2 2 8 2 1 1 USMLE® is a joint program of The Federation of State Medical Boards of the United States, Inc. and the National Board of Medical Examiners. USMLE® is a joint program of the Federation of State Medical Boards (FSMB) and the National Board of Medical Examiners (NBME), neither of which sponsors or endorses this product. 978-1-5062-2821-1_USMLE_Step2_CK_Psychiatry_Course_CVR.indd 1 6/15/17 10:24 AM ® STEP 2 CK Lecture Notes 2018 USMLE Psychiatry, Epidemiology, Ethics, Patient Safety USMLE® is a joint program of The Federation of State Medical Boards of the United States, Inc. and the National Board of Medical Examiners. USMLE Step 2 CK Psychiatry.indb 1 6/13/17 3:30 PM USMLE® is a joint program of the Federation of State Medical Boards (FSMB) and the National Board of Medical Examiners (NBME), neither of which sponsors or endorses this product. This publication is designed to provide accurate information in regard to the subject matter covered as of its publication date, with the understanding that knowledge and best practice constantly evolve. -

Education, Faculty of Medicine, Thinking and Decision Making
J R Coll Physicians Edinb 2011; 41:155–62 Symposium review doi:10.4997/JRCPE.2011.208 © 2011 Royal College of Physicians of Edinburgh Better clinical decision making and reducing diagnostic error P Croskerry, GR Nimmo 1Clinical Consultant in Patient Safety and Professor in Emergency Medicine, Dalhousie University, Halifax, Nova Scotia, Canada; 2Consultant Physician in Intensive Care Medicine, Western General Hospital, Edinburgh, UK This review is based on a presentation given by Dr Nimmo and Professor Croskerry Correspondence to P Croskerry, at the RCPE Patient Safety Hot Topic Symposium on 19 January 2011. Department of Emergency Medicine and Division of Medical ABSTRACT A major amount of our time working in clinical practice involves Education, Faculty of Medicine, thinking and decision making. Perhaps it is because decision making is such a Dalhousie University, QE II – commonplace activity that it is assumed we can all make effective decisions. Health Sciences Centre, Halifax Infirmary, Suite 355, 1796 Summer However, this is not the case and the example of diagnostic error supports this Street, Halifax, Nova Scotia B3H assertion. Until quite recently there has been a general nihilism about the ability 2Y9, Canada to change the way that we think, but it is now becoming accepted that if we can think about, and understand, our thinking processes we can improve our decision tel. +1 902 225 0360 making, including diagnosis. In this paper we review the dual process model of e-mail [email protected] decision making and highlight ways in which decision making can be improved through the application of this model to our day-to-day practice and by the adoption of de-biasing strategies and critical thinking. -

Improving Lung Cancer Survival Time to Move On
. Heuvers E arlies arlies M Time to move on NG LUNG CANCER CANCER LUNG NG I VAL I IMPROV SURV Marlies E. Heuvers IMPROVING LUNG CANCER SURVIVAL Time to move on Improving lung cancer survival; Time to move on Marlies E. Heuvers ISBN: 978-94-6169-388-4 Improving lung cancer survival; time to move on Thesis, Erasmus University Copyright © M.E. Heuvers All rights reserved. No part of this thesis may be reproduced, stored in a retrieval system of any nature, or transmitted in any form or by any means without permission of the author. Cover design: Lay-out and printing: Optima Grafische Communicatie, Rotterdam, The Netherlands Printing of this thesis was kindly supported by the the Department of Respiratory Medicine, GlaxoSmithKline, J.E. Jurriaanse Stichting, Boehringer Ingelheim bv, Roche, TEVA, Chiesi, Pfizer, Doppio Rotterdam. Improving Lung Cancer Survival; Time to move on Verbetering van de overleving van longkanker; tijd om verder te gaan Proefschrift ter verkrijging van de graad van doctor aan de Erasmus Universiteit Rotterdam op gezag van de rector magnificus Prof. dr. H.G. Schmidt en volgens besluit van het College van Promoties. De openbare verdediging zal plaatsvinden op 11 juni 2013 om 13.30 uur door Marlies Esther Heuvers geboren te Hoorn Promotiecommissie Promotor: Prof. dr. H.C. Hoogsteden Copromotoren: dr. J.G.J.V. Aerts dr. J.P.J.J. Hegmans Overige leden: Prof. dr. R.W. Hendriks Prof. dr. B.H.Ch. Stricker Prof. dr. S. Sleijfer Ingenuas didicisse fideliter artes emollit mores, nec sinit esse feros. Ovidius, Epistulae ex Ponto -

Bias Miguel Delgado-Rodrı´Guez, Javier Llorca
635 J Epidemiol Community Health: first published as 10.1136/jech.2003.008466 on 13 July 2004. Downloaded from GLOSSARY Bias Miguel Delgado-Rodrı´guez, Javier Llorca ............................................................................................................................... J Epidemiol Community Health 2004;58:635–641. doi: 10.1136/jech.2003.008466 The concept of bias is the lack of internal validity or Ahlbom keep confounding apart from biases in the statistical analysis as it typically occurs when incorrect assessment of the association between an the actual study base differs from the ‘‘ideal’’ exposure and an effect in the target population in which the study base, in which there is no association statistic estimated has an expectation that does not equal between different determinants of an effect. The same idea can be found in Maclure and the true value. Biases can be classified by the research Schneeweiss.5 stage in which they occur or by the direction of change in a In this glossary definitions of the most com- estimate. The most important biases are those produced in mon biases (we have not been exhaustive in defining all the existing biases) are given within the definition and selection of the study population, data the simple classification by Kleinbaum et al.2 We collection, and the association between different have added a point for biases produced in a trial determinants of an effect in the population. A definition of in the execution of the intervention. Biases in data interpretation, writing, and citing will not the most common biases occurring in these stages is given. be discussed (see for a description of them by .......................................................................... -

Phenomenon of Disease
4. The Phenomenon of Disease Concepts in defining, classifying, detecting, and tracking disease and other health states. The concept of natural history – the spectrum of development and manifestations of pathological conditions in individuals and populations. Definition and classification of disease Although the public health profession is sometimes inclined to refer to the health care system as a "disease care system", others have observed that public health also tends to be preoccupied with disease. One problem with these charges is that both "health" and "disease" are elusive concepts. Defining health and disease Rene Dubos (Man Adapting, p348) derided dictionaries and encyclopedias of the mid-20th century for defining "disease as any departure from the state of health and health as a state of normalcy free from disease or pain". In their use of the terms "normal" and "pathological", contemporary definitions (see table) have not entirely avoided an element of circularity. Rejecting the possibility of defining health and disease in the abstract, Dubos saw the criteria for health as conditioned by the social norms, history, aspirations, values, and the environment, a perspective that remains the case today (Temple et al., 2001). Thus diseases that are very widespread may come to be considered as "normal" or an inevitable part of life. Dubos observed that in a certain South American tribe, pinta (dyschromic spirochetosis) was so common that the Indians regarded those without it as being ill. Japanese physicians have regarded chronic bronchitis and asthma as unavoidable complaints, and in the mid-19th century U.S., Lemuel Shattuck wrote that tuberculosis created little alarm because of its constant presence (Dubos, 251). -
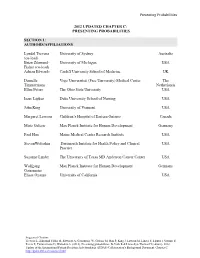
Chapter C: Presenting Probabilities
Presenting Probabilities 2012 UPDATED CHAPTER C: PRESENTING PROBABILITIES SECTION 1: AUTHORS/AFFILIATIONS Lyndal Trevena University of Sydney Australia (co-lead) Brian Zikmund- University of Michigan USA Fisher (co-lead) Adrian Edwards Cardiff University School of Medicine UK Danielle Vrije Universiteit (Free University) Medical Center The Timmermans Netherlands Ellen Peters The Ohio State University USA Isaac Lipkus Duke University School of Nursing USA John King University of Vermont USA Margaret Lawson Children’s Hospital of Eastern Ontario Canada Mirta Galesic Max Planck Institute for Human Development Germany Paul Han Maine Medical Center Research Institute USA StevenWoloshin Dartmouth Institute for Health Policy and Clinical USA Practice Suzanne Linder The University of Texas MD Anderson Cancer Center USA Wolfgang Max Planck Institute for Human Development Germany Gaissmaier Elissa Ozanne University of California USA Suggested Citation: Trevena L, Zikmund-Fisher B, Edwards A, Gaissmaier W, Galesic M, Han P, King J, Lawson M, Linder S, Lipkus I, Ozanne E, Peters E, Timmermans D, Woloshin S. (2012). Presenting probabilities. In Volk R & Llewellyn-Thomas H (editors). 2012 Update of the International Patient Decision Aids Standards (IPDAS) Collaboration's Background Document. Chapter C. http://ipdas.ohri.ca/resources.html. Presenting Probabilities SECTION 2: CHAPTER SUMMARY What is this quality dimension? Medical decisions have outcomes that may have been quantified through research. To assist patients and health professionals in balancing the benefits and harms of these options, decision aids aim to communicate estimates of the likelihoods of these outcomes based on the best available evidence. What is the theoretical rationale for including this quality dimension? When considering decision options and the likelihoods of their outcomes, estimates of both the changes and the outcome frequencies associated with each option need to be conveyed in a way that maximizes patients’ understanding and thereby facilitates informed decision making. -

Health Technology Assessment. Dépistage Du Cancer Colorectal : Connaissances Scientifiques Actuelles Et Impact Budgétaire Pour La Belgique
Health Technology Assessment Dépistage du cancer colorectal : connaissances scientifiques actuelles et impact budgétaire pour la Belgique KCE reports vol. 45B Federaal Kenniscentrum voor de gezondheidszorg Centre fédéral dexpertise des soins de santé 2006 Le Centre fédéral dexpertise des soins de santé Présentation : Le Centre fédéral dexpertise des soins de santé est un parastatal, créé le 24 décembre 2002 par la loi-programme (articles 262 à 266), sous tutelle du Ministre de la Santé publique et des Affaires sociales, qui est chargé de réaliser des études éclairant la décision politique dans le domaine des soins de santé et de lassurance maladie. Conseil dadministration Membres effectifs : Gillet Pierre (Président), Cuypers Dirk (Vice-Président), Avontroodt Yolande, De Cock Jo (Vice-Président), De Meyere Frank, De Ridder Henri, Gillet Jean- Bernard, Godin Jean-Noël, Goyens Floris, Kesteloot Katrien, Maes Jef, Mertens Pascal, Mertens Raf, Moens Marc, Perl François Smiets Pierre, Van Massenhove Frank, Vandermeeren Philippe, Verertbruggen Patrick, Vermeyen Karel Membres suppléants : Annemans Lieven, Boonen Carine, Collin Benoît, Cuypers Rita, Dercq Jean- Paul, Désir Daniel, Lemye Roland, Palsterman Paul, Ponce Annick, Pirlot Viviane, Praet Jean-Claude, Remacle Anne, Schoonjans Chris, Schrooten Renaat, Vanderstappen Anne, Commissaire du gouvernement : Roger Yves Direction Directeur général : Dirk Ramaekers Directeur général adjoint : Jean-Pierre Closon Contact Centre fédéral dexpertise des soins de santé (KCE). 62 Rue de la Loi B-1040 Bruxelles Belgium Tel: +32 [0]2 287 33 88 Fax: +32 [0]2 287 33 85 Email : [email protected] Web : http://www.centredexpertise.fgov.be Health Technology Assessment Dépistage du cancer colorectal : connaissances scientifiques actuelles et impact budgétaire pour la Belgique KCE reports vol. -

Epidemiologic Methods for Health Policy This Page Intentionally Left Blank Epidemiologic Methods for Health Policy
Epidemiologic Methods for Health Policy This page intentionally left blank Epidemiologic Methods for Health Policy ROBERTA. SPASOFF New York Oxford OXFORD UNIVERSITY PRESS 1999 Oxford University Press Oxford New York Athens Auckland Bangkok Bogota Buenos Aires Calcutta Cape Town Chennai Dar es Salaam Delhi Florence Hong Kong Istanbul Karachi Kuala Lumpur Madrid Melbourne Mexico City Mumbai Nairobi Paris Sao Paulo Singapore Taipei Tokyo Toronto Warsaw and associated companies in Berlin Ibadan Copyright © 1999 by Oxford University Press, Inc. Published by Oxford University Press, Inc. 198 Madison Avenue, New York, New York 10016 Oxford is a registered trademark of Oxford University Press All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior permission of Oxford University Press. Library of Congress Cataloging-in-Publication Data Spasoff, R. A. Epidemiologic methods for health policy / Robert A. Spasoff. p. cm. Includes bibliographical references and index. ISBN 0-19-511499-X 1. Epidemiology. 2. Medical policy. I. Title. RA652.S67 1999 362.1—dc21 98-50116 987654321 Printed in the United States of America on acid-free paper Preface Why another book on epidemiology and health policy? Because as the study of the health of populations, epidemiology can make a unique contribution to health policy, and because no book focusing on the most relevant methods appears to exist at present. Textbooks of general epi- demiology tend to ignore this subject and the descriptive epidemiologic methods that are most relevant to it, and to focus almost entirely on etio- logical research. -

Primacy, Congruence and Confidence in Diagnostic Decision-Making
Primacy, Congruence and Confidence in Diagnostic Decision-Making Thomas Frotvedt1, Øystein Keilegavlen Bondevik1, Vanessa Tamara Seeligmann, Bjørn Sætrevik Department of psychosocial science, University of Bergen 1: These authors contributed equally to the manuscript Abstract Some heuristics and biases are assumed to be universal for human decision-making, and may thus be expected to appear consistently and need to be considered when planning for real-life decision-making. Yet results are mixed when exploring the biases in applied settings, and few studies have attempted to robustly measure the combined impact of various biases during a decision-making process. We performed three pre-registered classroom experiments in which trained medical students read case descriptions and explored follow-up information in order to reach and adjust mental health diagnoses (∑N = 224). We tested whether the order of presenting the symptoms led to a primacy effect, whether there was a congruence bias in selecting follow-up questions, and whether confidence increased during the decision process. Our results showed increased confidence for participants that did not change their decision or sought disconfirming information. There was some indication of a weak congruence bias in selecting follow-up questions. There was no indication of a stronger congruence bias when confidence was high, and there was no support for a primacy effect of the order of symptom presentation. We conclude that the biases are difficult to demonstrate in pre-registered analyses of -
JHH 6.3 Nov 09 Layout
Volume 14 • Issue 2 Summer 201 7 JOURNAL OF holistic healthcare Re-imagining healthcare Breast cancer journey Breast screening? Birth doulas Vaginal health Fiona Hamilton Rewiring to pleasure Women doctors’ suicide Frontline NHS Self care – herbs A remarkable woman Research Reviews Women’s health JOURNAL OF holistic healthcare About the BHMA marker of good practice through policy, training and good management. We have a historical duty to pay In the heady days of 1983 while the Greenham Common special attention to deprived and excluded groups, Women’s Camp was being born, a group of doctors especially those who are poor, mentally ill, disabled and formed the British Holistic Medical Association (BHMA). elderly. Planning compassionate healthcare organisations They too were full of idealism. They wanted to halt the calls for social and economic creativity. More literally, relentless slide of mainstream healthcare towards the wider use of the arts and artistic therapies can help industrialised monoculture. They wanted medicine to create more humane healing spaces and may elevate the understand the world in all its fuzzy complexity, and to clinical encounter so that the art of healthcare can take embrace health and healing; healing that involves body, its place alongside appropriately applied medical science. mind and spirit. They wanted to free medicine from the grip of old institutions, from over-reliance on drugs and Integrating complementary therapies to explore the potential of other therapies. They wanted practitioners to care for themselves, understanding that Because holistic healthcare is patient-centred and practitioners who cannot care for their own bodies and concerned about patient choice, it must be open to feelings will be so much less able to care for others.