Modelling ATP Tennis As a Network
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
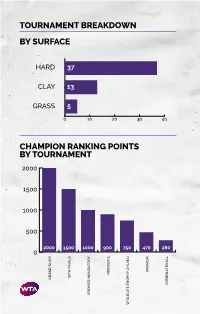
Tournament Breakdown by Surface Champion Ranking Points By
TOURNAMENT BREAKDOWN BY SURFACE HAR 37 CLAY 13 GRASS 5 0 10 20 30 40 CHAMPION RANKING POINTS BY TOURNAMENT 2000 1500 1000 500 2000 1500 1000 900 750 470 280 0 PREMIER PREMIER TA FINALS TA GRAN SLAM INTERNATIONAL PREMIER MANATORY TA ELITE TROPHY HUHAI TROPHY ELITE TA 55 WTA TOURNAMENTS BY REGION BY COUNTRY 8 CHINA 2 SPAIN 1 MOROCCO UNITED STATES 2 SWITZERLAND 7 OF AMERICA 1 NETHERLANDS 3 AUSTRALIA 1 AUSTRIA 1 NEW ZEALAND 3 GREAT BRITAIN 1 COLOMBIA 1 QATAR 3 RUSSIA 1 CZECH REPUBLIC 1 ROMANIA 2 CANADA 1 FRANCE 1 THAILAND 2 GERMANY 1 HONG KONG 1 TURKEY UNITED ARAB 2 ITALY 1 HUNGARY 1 EMIRATES 2 JAPAN 1 SOUTH KOREA 1 UZBEKISTAN 2 MEXICO 1 LUXEMBOURG TOURNAMENTS TOURNAMENTS International Tennis Federation As the world governing body of tennis, the Davis Cup by BNP Paribas and women’s Fed Cup by International Tennis Federation (ITF) is responsible for BNP Paribas are the largest annual international team every level of the sport including the regulation of competitions in sport and most prized in the ITF’s rules and the future development of the game. Based event portfolio. Both have a rich history and have in London, the ITF currently has 210 member nations consistently attracted the best players from each and six regional associations, which administer the passing generation. Further information is available at game in their respective areas, in close consultation www.daviscup.com and www.fedcup.com. with the ITF. The Olympic and Paralympic Tennis Events are also an The ITF is committed to promoting tennis around the important part of the ITF’s responsibilities, with the world and encouraging as many people as possible to 2020 events being held in Tokyo. -

How the Court Surface Is Affecting the Serve-And-Volley Tristan Barnett
How the court surface is affecting the serve-and-volley Tristan Barnett Strategic Games www.strategicgames.com.au 1. Introduction The modern version of the game (official name of Lawn Tennis) as we recognize it today was designed and patented by Major Walter Clopton Wingfield in 1873. Two years later in 1875, the official rules of the game were drawn up by Marylebone Cricket Club, and two years later in 1877, Wimbledon began on a grass surface as the first official championships. All four grand slam events have been played on a grass surface. Wimbledon is the only grand slam event played on a grass court today and has always been played on a grass court surface. The French Open began in 1891 on a grass surface and remained on grass until 1928 when the surface was changed to clay. The US Open began in 1881 on a grass surface; until it was changed to clay from 1975-1977 and from 1978 has been played on a hard court surface. Finally, the Australian Open began in 1905 on a grass surface and remained on grass until 1988 when the surface was changed to a hard court. There has been a change in the proportion of tournaments played on different court surfaces from 1877 to 2010. Firstly, for the first 14 years of the game, all tournaments (grand slam and non grand slam) were played on grass. Secondly, for the first 101 years of the game all tournaments were played on the natural surfaces of grass and clay. Thirdly, according to the ITF, until the early 1970’s, the majority of tournaments were played on grass including three out of the four grand slams. -

Countrywide Classic USTA Men's Challenger and the Home Depot
Countrywide Classic USTA Men’s Challenger and The Home Depot Center USTA Women’s Challenger Pro Circuit Tournament Features Tennis’ Rising Stars The Home Depot Center to Host $50,000 Purse Tournament May 28 – June 3 CARSON, Calif., May 7, 2007 – The United States Tennis Association (USTA) today announced that The Home Depot Center in Carson, Calif., will host the Countrywide Classic USTA Men’s $50,000 Challenger and The Home Depot Center USTA Women’s $50,000 Challenger Monday, May 28 through Sunday, June 3. This is one of four combined tournaments on the USTA Pro Circuit scheduled for 2007. This year’s event marks the second time Carson has hosted a men’s challenger and is the inaugural event for the women. The Challenger tournament offers an opportunity for players to gain professional ranking points needed to compete on major tours. Players ranked as high as No. 50 in the world typically compete in challenger-level events. In 2005, Justin Gimelstob, a winner of nine professional titles, won the inaugural men’s event. Gimelstob has captured 13 ATP Tour doubles championships. Both fields will feature 32 singles players and 16 doubles teams, drawing from the Top 200 tennis world rankings. Men’s singles qualifying will take place on Saturday, May 26, while the women’s is slated for Sunday, May 27. The event is free to the public Monday, May 28 – Saturday, June 2. On Sunday, June 3, tickets to the finals are $5.00. For more information, please visit www.usta.com/carsonchallenger. The event will also offer a free Kids Day on Saturday, June 2 at The Home Depot Center from 9:00 a.m. -

Men's Singles Semi-Finals
2019 US OPEN New York, NY, USA | 26 August-8 September 2019 S-128, D-64 | $57,238,700 | Hard www.usopen.org DAY 12 MEDIA NOTES | Friday, 6 September 2019 MEN’S SINGLES SEMI-FINALS ARTHUR ASHE STADIUM [5] Daniil Medvedev (RUS) vs. Grigor Dimitrov (BUL) Series Tied 1-1 [24] Matteo Berrettini (ITA) vs [2] Rafael Nadal (ESP) First Meeting DAY 12 FAST FACTS No. 2 and three-time US Open champion Rafael Nadal is joined by three first-time semi-finalists in Flushing Meadows: No. 5 Daniil Medvedev, No. 24 seed Matteo Berrettini and unseeded Grigor Dimitrov. Nadal is in his seventh consecutive Grand Slam semi-final, eighth overall at the US Open and 33rd in his career, while Dimitrov is playing in his third Grand Slam semi-final. Medvedev and Berrettini are making their Grand Slam semi-final debuts. Medvedev and Berrettini are both 23 years old. This is the first Grand Slam tournament semi-final with two players 23 (or younger) since last year’s Australian Open with Hyeon Chung (21) and Kyle Edmund (23). The last US Open SFs with two players 23 (or younger) was Juan Martin del Potro (20) and Novak Djokovic (22) in 2009. This is also the first Grand Slam semi-final with three players born in the 1990s: Medvedev (1996), Berrettini (1996) and Dimitrov (1991). One of the three is looking to become the first Grand Slam champion born in the 1990s. There have been two finalists: Dominic Thiem at Roland Garros in 2018-19 and Milos Raonic at Wimbledon in 2016. -

ATP Challenger Tour by the Numbers
ATP MEDIA INFORMATION Updated: 20 September 2021 2021 ATP CHALLENGER BY THE NUMBERS Match Wins Leaders W-L Titles 1) Benjamin Bonzi FRA 49-11 6 2) Tomas Martin Etcheverry ARG 38-13 2 3) Zdenek Kolar CZE 29-18 3 4) Holger Rune DEN 28-7 3 5) Kacper Zuk POL 26-11 1 Nicolas Jarry CHI 26-12 1 7) Sebastian Baez ARG 25-5 3 Altug Celikbilek TUR 25-10 2 Juan Manuel Cerundolo ARG 25-10 3 Tomas Barrios Vera CHI 25-11 1 11) Jenson Brooksby USA 23-3 3 Gastao Elias POR 23-12 1 Win Percentage Leaders W-L Pct. Titles 1) Jenson Brooksby USA 23-3 88.5 3 2) Sebastian Baez ARG 25-5 83.3 3 3) Benjamin Bonzi FRA 49-11 81.7 6 4) Holger Rune DEN 28-7 80.0 3 5) Zizou Bergs BEL 19-6 76.0 3 6) Federico Coria ARG 18-6 75.0 1 7) Tomas Martin Etcheverry ARG 38-13 74.5 2 8) Arthur Rinderknech FRA 18-7 72.0 1 Botic van de Zandschulp NED 18-7 72.0 0 *Minimum 20 matches played* Singles Title Leaders ----- By Surface ----- Player Total Clay Grass Hard Carpet Benjamin Bonzi FRA 6 1 5 Sebastian Baez ARG 3 3 Zizou Bergs BEL 3 1 2 Jenson Brooksby USA 3 1 2 Juan Manuel Cerundolo ARG 3 3 Tallon Griekspoor NED 3 3 Zdenek Kolar CZE 3 3 Holger Rune DEN 3 3 Franco Agamenone ITA 2 2 Daniel Altmaier GER 2 2 Altug Celikbilek TUR 2 2 Mitchell Krueger USA 2 2 Tomas Martin Etcheverry ARG 2 2 Mats Moraing GER 2 2 Carlos Taberner ESP 2 2 Bernabe Zapata Miralles ESP 2 2 53 tied with 1 title each Winners by Age: 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 0 0 6 7 8 4 7 10 13 13 4 3 7 5 3 1 0 3 0 1 0 1 0 0 Youngest Final: Juan Manuel Cerundolo (19) d. -

2021 Rulebook16mar 1617 Lsw.Indd
CHALLENGER ADDENDUM I. ATP CIRCUIT REGULATIONS 1.21 Hotel Accommodations A. Tournament Obligations 2) ATP Challenger Tour Tournaments c) Qualifi ers. Complimentary hotel accommodations for players in the singles qualifying shall be available to begin on the night before the start of qualifying compe- tition and be available to each player through the night of the player’s last qualifying match (not applicable for events with 48 main draw). Successful qualifi ers shall have their hospitality at the offi cial hotel made ret- roactive from the night before the start of the qualifying competition. i) Eight (8) Day Events All 2021 Challenger events are eight (8) day events unless otherwise ap- proved by ATP. B. Player Obligations 6) Qualifi er Reservations. Players participating in the qualifying competition who wish to receive a player rate at a tournament hotel (for 48 draw events) or com- plimentary hotel accommodation (32 draw events) must make a hotel reservation no later than fi ve (5) days prior to the start of qualifying (48 draw events) or 14 days (for 32 draw events) with either the hotel or the tournament, as specifi ed on the tournament detail sheet. Reservation changes can be made up to forty-eight (48) hours prior to the start of the reservation except that a player still competing in either singles or doubles in the prior week’s tournament must confi rm reserva- tions when his travel plans are fi nalized. III. FINANCIAL 3.04 Fee Obligation B. 3) ATP Challenger Tour Tournaments The fee is payable in two (2) 50% installments. -

Changes to the Published 2021 Atp Official Rulebook
ATP London CHANGES Palliser House TO THE Palliser Road London W14 9EB PUBLISHED England PH: +44 207 381 7890 2021 ATP FAX: +44 207 381 7895 OFFICIAL RULEBOOK ATP Americas 201 ATP Tour Boulevard Ponte Vedra Beach, FL 32082 USA PH: +1 904 285 8000 FAX: +1 904 285 5966 ATP Europe Monte Carlo Sun 74 Boulevard D’Italie 98000 Monaco PH: 377-97-970404 FAX: 377-97-970400 ATP International Group Suite 208, 46a Macleay Street (This document includes all rule changes/additions/clarifications to date) Potts Point NSW Australia 2011 PH: +61 2 9336 7000 Last revised : 05/22//21 FAX: +61 2 8354 1945 Current Revision: 06/01/21 www.ATPTour.com Effective 11 January 2021: An amendment has been made to the ATP and Challenger (i) A player’s worst ‘best other’ will only be replaced if the 2020/21* result Addendums, Rankings Section, pgs. 389-390 and 404-405, 9.03, A. 2) and 4) a) (viii) as noted from an ATP Challenger/ITF WTT event is better. below in red and with new clarifications added in red: (ii) New results from an ATP Challenger/ITF WTT that replace player’s worst ‘best other’ will stay on the players’ FedEx ATP ranking for 52-weeks. ATP & CHALLENGER ADDENDUMS 5) Beginning on 15 22 March 2021, the ATP rankings will add and drop points 9.03 FedEx ATP Rankings as per the ATP Rules prior to the COVID-19 pandemic outbreak. A. Commitment Players & B. Non-commitment Players 1) Due to the suspension of the ATP Tour and impact of COVID-19 pandemic, the *Applicable for tournaments up to and including the week of 15 March 2021 only. -

Changes to the Published 2021 Atp Official
ATP London CHANGES Palliser House TO THE Palliser Road London W14 9EB PUBLISHED England PH: +44 207 381 7890 2021 ATP FAX: +44 207 381 7895 OFFICIAL RULEBOOK ATP Americas 201 ATP Tour Boulevard Ponte Vedra Beach, FL 32082 USA PH: +1 904 285 8000 FAX: +1 904 285 5966 ATP Europe Monte Carlo Sun 74 Boulevard D’Italie 98000 Monaco PH: 377-97-970404 FAX: 377-97-970400 ATP International Group Suite 208, 46a Macleay Street (This document includes all rule changes/additions/clarifications to date) Potts Point NSW Australia 2011 PH: +61 2 9336 7000 Last revised : 07/19//21 FAX: +61 2 8354 1945 Current Revision: 08/19//21 www.ATPTour.com Effective 11 January 2021: An amendment has been made to the ATP and Challenger (i) A player’s worst ‘best other’ will only be replaced if the 2020/21* result Addendums, Rankings Section, pgs. 389-390 and 404-405, 9.03, A. 2) and 4) a) (viii) as noted from an ATP Challenger/ITF WTT event is better. below in red and with new clarifications added in red: (ii) New results from an ATP Challenger/ITF WTT that replace player’s worst ‘best other’ will stay on the players’ FedEx ATP ranking for 52-weeks. ATP & CHALLENGER ADDENDUMS 5) Beginning on 15 22 March 2021, the ATP rankings will add and drop points 9.03 FedEx ATP Rankings as per the ATP Rules prior to the COVID-19 pandemic outbreak. A. Commitment Players & B. Non-commitment Players 1) Due to the suspension of the ATP Tour and impact of COVID-19 pandemic, the *Applicable for tournaments up to and including the week of 15 March 2021 only. -

6. ITF Level 2 Coaching Course
ITF Coaches Education Programme Level 2 Coaching Course Travelling with tournament players Coach Education Series Copyright © ITF 2007 By the end of this session you should be able to: • understand the different roles played by a coach/team captain • know the responsibilities of a team coach • understand the main characteristics of the International Tennis Structure • have effective and appropriate knowledge of the basics to define the career path for a junior player Coach Education Series Copyright © ITF 2007 The team captain roles • Technical • Financial manager • Tactician (budgeting, keeping • Psychologist / social records of expenditure) worker / surrogate • Medical consultant parent • Completing end of tour • Hitting partner reports on players • Organiser (court • Travel agent bookings, practice) • Leader / decision maker • Friend • Disciplinarian Coach Education Series Copyright © ITF 2007 Responsibilities of a team coach: prior to the tour • Contact the player's coach/parents to determine: – Game style, – Player's temperament, – Pre-match preparation routing, – Whether or not the player is under medication – Any other pertinent information that will assist the tour coach's relationship with the player Coach Education Series Copyright © ITF 2007 Responsibilities of a team coach: On tour • Team meeting to inform • Take disciplinary actions the players when necessary • Liaise with tournament • Complete expense record committees • Confirm airline • Plan training and pre- reservations match preparation • Get information about • Set -

Trends in Singles Play Intensity on the ATP Tour
Trends in Singles Play Intensity on the ATP Tour Stephanie A. Kovalchik RAND Corporation NESSIS 2013 1 of 34 Has Tennis Become Too Demanding? John Isner and Nicholas Mahut, Wimbledon 2010 2 of 34 Study Objective Was the Isner-Mahut 11hr and 5-minute marathon at the 2010 Wimbledon an anomaly or a sign that match play has gotten increasingly arduous over time? This study sought to shed light on this question by analyzing trends in matches played and match duration over 20 years of the ATP Tour. 3 of 34 ATP Dataset Years 1991-2012 Tournaments All 250 Level and Higher∗ Play Singles Only Players End-of-Year Top 100 Total Players 482 Total Matches 100,460 (Qualifying+) Source www.atpworldtour.com * Excluding Davis Cup and the Olympics 4 of 34 500 Series and Above: Tournaments & Surfaces 25 24 23 22 21 20 19 18 17 16 Grass 15 14 Carpet 13 12 Hard 11 Clay 10 Total Tournaments 9 8 7 6 5 4 3 2 1 0 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 Champ Series Super 9 Tennis Masters Series ATP 1000 5 of 34 500 Series and Above: Tournaments & Surfaces • Tournaments in the 500 series and higher declined by 2 between 2003-2008, returning to the number 24 of the mid-1990s with the introduction of the Masters 1000s in 2009. • Over the first 20 years of the ATP Tour, carpet has been displaced by the hard court surface, which now makes up 70% of the most prestigious tournaments on the Tour. -

And Type in Recipient's Full Name
18 March 2020 ATP AND WTA EXTEND SUSPENSION OF TOURS After careful consideration, and due to the continuing outbreak of COVID-19, all ATP and WTA tournaments in the Spring clay-court swing will not be held as scheduled. This includes the combined ATP/WTA tournaments in Madrid and Rome, along with the WTA events in Strasbourg and Rabat and ATP events in Munich, Estoril, Geneva and Lyon. The professional tennis season is now suspended through 7 June 2020, including the ATP Challenger Tour and ITF World Tennis Tour. At this time, tournaments taking place from 8 June 2020 onwards are still planning to go ahead as per the published schedule. In parallel, the FedEx ATP Rankings and WTA Rankings will be frozen throughout this period and until further notice. The challenges presented by the COVID-19 pandemic to professional tennis demand greater collaboration than ever from everyone in the tennis community in order for the sport to move forward collectively in the best interest of players, tournaments and fans. We are assessing all options related to preserving and maximising the tennis calendar based on various different return dates for the Tours, which remains an unknown at this time. We are committed to working through these matters with our player and tournament members, and the other governing bodies, in the weeks and months ahead. Now is not a time to act unilaterally, but in unison. All decisions related to the impact of the coronavirus require appropriate consultation and review with the stakeholders in the game, a view that is shared by ATP, WTA, ITF, AELTC, Tennis Australia, and USTA. -

Changes to the Published 2021 Atp Official
ATP London CHANGES Palliser House TO THE Palliser Road London W14 9EB PUBLISHED England PH: +44 207 381 7890 2021 ATP FAX: +44 207 381 7895 OFFICIAL RULEBOOK ATP Americas 201 ATP Tour Boulevard Ponte Vedra Beach, FL 32082 USA PH: +1 904 285 8000 FAX: +1 904 285 5966 ATP Europe Monte Carlo Sun 74 Boulevard D’Italie 98000 Monaco PH: 377-97-970404 FAX: 377-97-970400 ATP International Group Suite 208, 46a Macleay Street (This document includes all rule changes/additions/clarifications to date) Potts Point NSW Australia 2011 PH: +61 2 9336 7000 Last revised : 02/01/21 FAX: +61 2 8354 1945 Current Revision: 02/12/21 www.ATPTour.com Effective 11 January 2021: An amendment has been made to the ATP and Challenger (i) A player’s worst ‘best other’ will only be replaced if the 2020/21* result Addendums, Rankings Section, pgs. 389-390 and 404-405, 9.03, A. 2) and 4) a) (viii) as noted from an ATP Challenger/ITF WTT event is better. below in red and with new clarifications added in red: (ii) New results from an ATP Challenger/ITF WTT that replace player’s worst ‘best other’ will stay on the players’ FedEx ATP ranking for 52-weeks. ATP & CHALLENGER ADDENDUMS 5) Beginning on 15 22 March 2021, the ATP rankings will add and drop points 9.03 FedEx ATP Rankings as per the ATP Rules prior to the COVID-19 pandemic outbreak. A. Commitment Players & B. Non-commitment Players 1) Due to the suspension of the ATP Tour and impact of COVID-19 pandemic, the *Applicable for tournaments up to and including the week of 15 March 2021 only.