Uinzr8jhi534dj2slqgjg8z4csgioa.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

R&S®BBA100 Broadband Amplifier Open
R&S®BBA100 Broadband Amplifier Open Source Acknowledgment 5353.8300.00 – 01 /RL/1/EN 01.00 / Broadcasting 3575.4620.02 M: - T - PAD Open Source Acknowledgment R&S BBA100 Introduction Contents 1 Introduction ......................................................................................... 3 1.1 Disclaimer ..................................................................................................................... 3 1.2 How to obtain the source code .................................................................................. 3 2 Software packages ............................................................................. 4 3 Verbatim license texts ........................................................................ 7 3.1 Apache License 2.0 ..................................................................................................... 7 3.2 GNU Library General Public License, Version 2.0 (LGPL 2.0) ..............................10 3.3 Boost Software License ............................................................................................18 3.4 GNU General Public License, Version 2.0 (GPL 2.0) ..............................................18 3.5 GNU Lesser General Public License, Version 2.1 (LGPL 2.1) ...............................24 3.6 Mozilla Public License, Version 1.1 (MPL 1.1) ........................................................32 3.7 MIT ...............................................................................................................................40 3.8 JDOM License -

Build It with Nitrogen the Fast-Off-The-Block Erlang Web Framework
Build it with Nitrogen The fast-off-the-block Erlang web framework Lloyd R. Prentice & Jesse Gumm dedicated to: Laurie, love of my life— Lloyd Jackie, my best half — Jesse and to: Rusty Klophaus and other giants of Open Source— LRP & JG Contents I. Frying Pan to Fire5 1. You want me to build what?7 2. Enter the lion’s den9 2.1. The big picture........................ 10 2.2. Install Nitrogen........................ 11 2.3. Lay of the land........................ 13 II. Projects 19 3. nitroBoard I 21 3.1. Plan of attack......................... 21 3.2. Create a new project..................... 23 3.3. Prototype welcome page................... 27 3.4. Anatomy of a page...................... 30 3.5. Anatomy of a route...................... 33 3.6. Anatomy of a template.................... 34 3.7. Elements............................ 35 3.8. Actions............................. 38 3.9. Triggers and Targets..................... 39 3.10. Enough theory........................ 40 i 3.11. Visitors............................ 44 3.12. Styling............................. 64 3.13. Debugging........................... 66 3.14. What you’ve learned..................... 66 3.15. Think and do......................... 68 4. nitroBoard II 69 4.1. Plan of attack......................... 69 4.2. Associates........................... 70 4.3. I am in/I am out....................... 78 4.4. Styling............................. 81 4.5. What you’ve learned..................... 82 4.6. Think and do......................... 82 5. A Simple Login System 83 5.1. Getting Started........................ 83 5.2. Dependencies......................... 84 5.2.1. Rebar Dependency: erlpass ............. 84 5.3. The index page........................ 85 5.4. Creating an account..................... 87 5.4.1. db_login module................... 89 5.5. The login form........................ 91 5.5.1. -

The Glib/GTK+ Development Platform
The GLib/GTK+ Development Platform A Getting Started Guide Version 0.8 Sébastien Wilmet March 29, 2019 Contents 1 Introduction 3 1.1 License . 3 1.2 Financial Support . 3 1.3 Todo List for this Book and a Quick 2019 Update . 4 1.4 What is GLib and GTK+? . 4 1.5 The GNOME Desktop . 5 1.6 Prerequisites . 6 1.7 Why and When Using the C Language? . 7 1.7.1 Separate the Backend from the Frontend . 7 1.7.2 Other Aspects to Keep in Mind . 8 1.8 Learning Path . 9 1.9 The Development Environment . 10 1.10 Acknowledgments . 10 I GLib, the Core Library 11 2 GLib, the Core Library 12 2.1 Basics . 13 2.1.1 Type Definitions . 13 2.1.2 Frequently Used Macros . 13 2.1.3 Debugging Macros . 14 2.1.4 Memory . 16 2.1.5 String Handling . 18 2.2 Data Structures . 20 2.2.1 Lists . 20 2.2.2 Trees . 24 2.2.3 Hash Tables . 29 2.3 The Main Event Loop . 31 2.4 Other Features . 33 II Object-Oriented Programming in C 35 3 Semi-Object-Oriented Programming in C 37 3.1 Header Example . 37 3.1.1 Project Namespace . 37 3.1.2 Class Namespace . 39 3.1.3 Lowercase, Uppercase or CamelCase? . 39 3.1.4 Include Guard . 39 3.1.5 C++ Support . 39 1 3.1.6 #include . 39 3.1.7 Type Definition . 40 3.1.8 Object Constructor . 40 3.1.9 Object Destructor . -

Making Story from System Logs with Elastic Stack
SANOG36 18 - 21 January, 2021 Making story from system logs with stack [email protected] https://imtiazrahman.com https://github.com/imtiazrahman Logs syslog Audit SNMP NETFLOW http METRIC DNS ids What is Elastic Stack ? Store, Analyze Ingest User Interface a full-text based, distributed NoSQL database. Written in Java, built on Apache Lucene Commonly used for log analytics, full-text search, security intelligence, business analytics, and operational intelligence use cases. Use REST API (GET, PUT, POST, and DELETE ) for storing and searching data Data is stored as documents (rows in relational database) Data is separated into fields (columns in relational database) Relational Database Elasticsearch Database Index Table Type Row/Record Document Column Name Field Terminology Cluster: A cluster consists of one or more nodes which share the same cluster name. Node: A node is a running instance of elasticsearch which belongs to a cluster. Terminology Index: Collection of documents Shard: An index is split into elements known as shards that are distributed across multiple nodes. There are two types of shard, Primary and replica. By default elasticsearch creates 1 primary shard and 1 replica shard for each index. Terminology Shard 1 Replica 1 Replica 2 Shard 2 Node 1 Node 2 cluster Terminology Documents { • Indices hold documents in "_index": "netflow-2020.10.08", "_type": "_doc", serialized JSON objects "_id": "ZwkiB3UBULotwSOX3Bdb", "_version": 1, • 1 document = 1 log entry "_score": null, "_source": { • Contains "field : value" pairs -

Decwindows Motif Guide to Application Programming
DECwindows Motif Guide to Application Programming Order Number: AA–PGZEB–TE January 1994 This document describes the programming interface for widgets provided by Digital in the DECwindows Motif Version 1.2 Toolkit. This document also includes tutorial programming information for the DECwindows Motif Version 1.2 Toolkit. Revision/Update Information: This is a revised manual. Operating System: OpenVMS AXP Version 1.5 VMS Version 5.5–2 Software Version: DECwindows Motif Version 1.2 for OpenVMS AXP DECwindows Motif Version 1.2 for OpenVMS VAX Digital Equipment Corporation Maynard, Massachusetts January 1994 The information in this document is subject to change without notice and should not be construed as a commitment by Digital Equipment Corporation. Digital Equipment Corporation assumes no responsibility for any errors that may appear in this document. The software described in this document is furnished under a license and may be used or copied only in accordance with the terms of such license. No responsibility is assumed for the use or reliability of software on equipment that is not supplied by Digital Equipment Corporation or its affiliated companies. Restricted Rights: Use, duplication, or disclosure by the U.S. Government is subject to restrictions as set forth in subparagraph (c)(1)(ii) of the Rights in Technical Data and Computer Software clause at DFARS 252.227-7013. © Digital Equipment Corporation 1994. All Rights Reserved. The postpaid Reader’s Comments forms at the end of this document request your critical evaluation to assist in preparing future documentation. The following are trademarks of Digital Equipment Corporation: Alpha AXP, AXP, Bookreader, DEC, DECpaint, DECterm, DECwindows, DECwrite, Digital, eXcursion, OpenVMS, VAX, VAX DOCUMENT, VMS, XUI, and the DIGITAL logo. -

Pro Netbeans IDE 6 Rich Client Platform Edition.Pdf
CYAN YELLOW MAGENTA BLACK PANTONE 123 C EMPOWERING PRODUCTIVITY FOR THE JAVA™ DEVELOPER THE EXPERT’S VOICE® IN Java™ TECHNOLOGY Companion eBook Available Author of IncIncludesludes newnew Pro NetBeans™ IDE 5.5 ™ NetBeans™ Enterprise Edition Pro NetBeans IDE 6 Pro (J)Ruby/Rails(J)Ruby/Rails IDEIDE Rich Client Platform Edition NetBeans Dear Reader, Today, numerous open source and commercial Java™ Integrated Development Environments (IDEs) are available. It seems that almost every month one of them comes out in a new version, claiming to be the best IDE. Making the decision to Pro migrate to a new IDE can be a big deal for some developers. This is especially true in professional software organizations that have an investment in IDE plugins, code-quality and build tools, and established development processes that can all ™ be affected by changing IDEs. If you or your organization have not yet switched to use NetBeans™ IDE platform, then the recent release of NetBeans IDE 6.0 will make you want to do so. NetBeans IDE 6 NetBeans 6 provides an amazing development environment. The NetBeans 6 Source Editor is arguably one of the most important features of an IDE, since that ™ is where developers spend a great deal of time. Through the newly rewritten core IDE 6 architecture, the NetBeans 6 Source Editor provides extremely intelligent and Rich Client Platform Edition powerful features such as code completion, syntax highlighting, and refactoring. NetBeans 6 has not only an updated code editor, but also many new features, such as Ruby/Rails support, Maven support, JUnit 4 support, and Local History, among others. -

A Successor to the X Window System
Y: A Successor to the X Window System Mark Thomas <[email protected]> Project Supervisor: D. R¨uckert <[email protected]> Second Marker: E. Lupu <[email protected]> June 18, 2003 ii Abstract UNIX desktop environments are a mess. The proliferation of incompatible and inconsistent user interface toolkits is now the primary factor in the failure of enterprises to adopt UNIX as a desktop solution. This report documents the creation of a comprehensive, elegant framework for a complete windowing system, including a standardised graphical user interface toolkit. ‘Y’ addresses many of the problems associated with current systems, whilst keeping and improving on their best features. An initial implementation, which supports simple applications like a terminal emulator, a clock and a calculator, is provided. iii iv Acknowledgements Thanks to Daniel R¨uckert for supervising the project and for his help and advice regarding it. Thanks to David McBride for his assistance with setting up my project machine and providing me with an ATI Radeon for it. Thanks to Philip Willoughby for his knowledge of the POSIX standard and help with the GNU Autotools and some of the more obscure libc functions. Thanks to Andrew Suffield for his help with the GNU Autotools and Arch. Thanks to Nick Maynard and Karl O’Keeffe for discussions on window system and GUI design. Thanks to Tim Southerwood for discussions about possible features of Y. Thanks to Duncan White for discussions about the virtues of X. All company and product names are trademarks and/or registered trademarks of their respective owners. -

Learning Javascript Design Patterns
Learning JavaScript Design Patterns Addy Osmani Beijing • Cambridge • Farnham • Köln • Sebastopol • Tokyo Learning JavaScript Design Patterns by Addy Osmani Copyright © 2012 Addy Osmani. All rights reserved. Revision History for the : 2012-05-01 Early release revision 1 See http://oreilly.com/catalog/errata.csp?isbn=9781449331818 for release details. ISBN: 978-1-449-33181-8 1335906805 Table of Contents Preface ..................................................................... ix 1. Introduction ........................................................... 1 2. What is a Pattern? ...................................................... 3 We already use patterns everyday 4 3. 'Pattern'-ity Testing, Proto-Patterns & The Rule Of Three ...................... 7 4. The Structure Of A Design Pattern ......................................... 9 5. Writing Design Patterns ................................................. 11 6. Anti-Patterns ......................................................... 13 7. Categories Of Design Pattern ............................................ 15 Creational Design Patterns 15 Structural Design Patterns 16 Behavioral Design Patterns 16 8. Design Pattern Categorization ........................................... 17 A brief note on classes 17 9. JavaScript Design Patterns .............................................. 21 The Creational Pattern 22 The Constructor Pattern 23 Basic Constructors 23 Constructors With Prototypes 24 The Singleton Pattern 24 The Module Pattern 27 iii Modules 27 Object Literals 27 The Module Pattern -

Zope Documentation Release 5.3
Zope Documentation Release 5.3 The Zope developer community Jul 31, 2021 Contents 1 What’s new in Zope 3 1.1 What’s new in Zope 5..........................................4 1.2 What’s new in Zope 4..........................................4 2 Installing Zope 11 2.1 Prerequisites............................................... 11 2.2 Installing Zope with zc.buildout .................................. 12 2.3 Installing Zope with pip ........................................ 13 2.4 Building the documentation with Sphinx ............................... 14 3 Configuring and Running Zope 15 3.1 Creating a Zope instance......................................... 16 3.2 Filesystem Permissions......................................... 17 3.3 Configuring Zope............................................. 17 3.4 Running Zope.............................................. 18 3.5 Running Zope (plone.recipe.zope2instance install)........................... 20 3.6 Logging In To Zope........................................... 21 3.7 Special access user accounts....................................... 22 3.8 Troubleshooting............................................. 22 3.9 Using alternative WSGI server software................................. 22 3.10 Debugging Zope applications under WSGI............................... 26 3.11 Zope configuration reference....................................... 27 4 Migrating between Zope versions 37 4.1 From Zope 2 to Zope 4 or 5....................................... 37 4.2 Migration from Zope 4 to Zope 5.0.................................. -
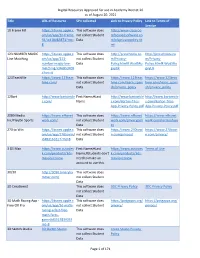
Digital Resources Approved for Use in Academy District 20 As Of
Digital Resources Approved for use in Academy District 20 as of August 20, 2021 Title URL of Resource SPII collected Link to Privacy Policy Link to Terms of Service 10 Frame Fill https://itunes.apple.c This software does http://www.classroo om/us/app/10-frame- not collect Student mfocusedsoftware.co fill/id418083871?mt= Data m/cfsprivacypolicy.ht 8 ml 123 NUMBER MAGIC https://itunes.apple.c This software does http://preschoolu.co http://preschoolu.co Line Matching om/us/app/123- not collect Student m/Privacy- m/Privacy- number-magic-line- Data Policy.html#.Wud5Ro Policy.html#.Wud5Ro matching/id46853409 gvyUk gvyUk 4?mt=8 123TeachMe https://www.123teac This software does https://www.123teac https://www.123teac hme.com/ not collect Student hme.com/learn_spani hme.com/learn_spani Data sh/privacy_policy sh/privacy_policy 12Bart http://www.bartontile First Name;#Last http://www.bartontile http://www.bartontile s.com/ Name s.com/Barton-Tiles- s.com/Barton-Tiles- App-Privacy-Policy.pdf App-Privacy-Policy.pdf 2080 Media https://www.nfhsnet This software does https://www.nfhsnet https://www.nfhsnet Inc/PlayOn Sports work.com/ not collect Student work.com/privacypoli work.com/termsofuse Data cy 270 to Win https://itunes.apple.c This software does https://www.270towi https://www.270towi om/us/app/270towin/ not collect Student n.com/privacy/ n.com/privacy/ id483161617?mt=8 Data 3 DS Max https://www.autodes First Name;#Last https://www.autodes Terms of Use k.com/products/3ds- Name;#Students don't k.com/products/3ds- max/overview need to make an max/overview account to use this. -

Appendix a the Ten Commandments for Websites
Appendix A The Ten Commandments for Websites Welcome to the appendixes! At this stage in your learning, you should have all the basic skills you require to build a high-quality website with insightful consideration given to aspects such as accessibility, search engine optimization, usability, and all the other concepts that web designers and developers think about on a daily basis. Hopefully with all the different elements covered in this book, you now have a solid understanding as to what goes into building a website (much more than code!). The main thing you should take from this book is that you don’t need to be an expert at everything but ensuring that you take the time to notice what’s out there and deciding what will best help your site are among the most important elements of the process. As you leave this book and go on to updating your website over time and perhaps learning new skills, always remember to be brave, take risks (through trial and error), and never feel that things are getting too hard. If you choose to learn skills that were only briefly mentioned in this book, like scripting, or to get involved in using content management systems and web software, go at a pace that you feel comfortable with. With that in mind, let’s go over the 10 most important messages I would personally recommend. After that, I’ll give you some useful resources like important websites for people learning to create for the Internet and handy software. Advice is something many professional designers and developers give out in spades after learning some harsh lessons from what their own bitter experiences. -

IBM Host Access Transformation Services: Rich Client Platform Programmer's Guide Chapter 1
IBM Host Access Transformation Services Rich Client Platform Programmer's Guide Ve r s i o n 9.5 SC27-5903-01 IBM Host Access Transformation Services Rich Client Platform Programmer's Guide Ve r s i o n 9.5 SC27-5903-01 Note Before using this information and the product it supports, be sure to read the general information under Appendix B, “Notices,” on page 125. Eighth Edition (November 2015) © Copyright IBM Corporation 2007, 2015. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Chapter 1. Introduction ........1 Using the runtime service .........36 Code examples .............2 Using the application service ........37 Using the API documentation (Javadoc) .....2 Using the client service ..........37 Using the session service ..........38 Chapter 2. Plug-ins and application Integration with other Eclipse UI views .....41 classes ...............3 An incoming communication scenario ....41 Samples ...............42 Plug-in project extension points ........4 Sample class and methods showing how to Allowing only one instance of an application . 4 access the different runtime services .....42 HATS runtime extension plug-in........5 Listening for 3270 Print Jobs........46 Application classes ............8 Creating a custom composite for use with the HostAccessApplication ..........8 Show action .............50 HostAccessWorkbenchAdvisor .......9 HostAccessWorkbenchWindowAdvisor ....10 Chapter 7. Integrating business logic 53 HostAccessActionBarAdvisor .......11