Tight Error Analysis in Fixed-Point Arithmetic⋆
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Variable Precision in Modern Floating-Point Computing
Variable precision in modern floating-point computing David H. Bailey Lawrence Berkeley Natlional Laboratory (retired) University of California, Davis, Department of Computer Science 1 / 33 August 13, 2018 Questions to examine in this talk I How can we ensure accuracy and reproducibility in floating-point computing? I What types of applications require more than 64-bit precision? I What types of applications require less than 32-bit precision? I What software support is required for variable precision? I How can one move efficiently between precision levels at the user level? 2 / 33 Commonly used formats for floating-point computing Formal Number of bits name Nickname Sign Exponent Mantissa Hidden Digits IEEE 16-bit “IEEE half” 1 5 10 1 3 (none) “ARM half” 1 5 10 1 3 (none) “bfloat16” 1 8 7 1 2 IEEE 32-bit “IEEE single” 1 7 24 1 7 IEEE 64-bit “IEEE double” 1 11 52 1 15 IEEE 80-bit “IEEE extended” 1 15 64 0 19 IEEE 128-bit “IEEE quad” 1 15 112 1 34 (none) “double double” 1 11 104 2 31 (none) “quad double” 1 11 208 4 62 (none) “multiple” 1 varies varies varies varies 3 / 33 Numerical reproducibility in scientific computing A December 2012 workshop on reproducibility in scientific computing, held at Brown University, USA, noted that Science is built upon the foundations of theory and experiment validated and improved through open, transparent communication. ... Numerical round-off error and numerical differences are greatly magnified as computational simulations are scaled up to run on highly parallel systems. -

Integers in C: an Open Invitation to Security Attacks?
Integers In C: An Open Invitation To Security Attacks? Zack Coker Samir Hasan Jeffrey Overbey [email protected] [email protected] [email protected] Munawar Hafiz Christian Kästnery [email protected] Auburn University yCarnegie Mellon University Auburn, AL, USA Pittsburgh, PA, USA ABSTRACT integer type is assigned to a location with a smaller type, We performed an empirical study to explore how closely e.g., assigning an int value to a short variable. well-known, open source C programs follow the safe C stan- Secure coding standards, such as MISRA's Guidelines for dards for integer behavior, with the goal of understanding the use of the C language in critical systems [37] and CERT's how difficult it is to migrate legacy code to these stricter Secure Coding in C and C++ [44], identify these issues that standards. We performed an automated analysis on fifty-two are otherwise allowed (and sometimes partially defined) in releases of seven C programs (6 million lines of preprocessed the C standard and impose restrictions on the use of inte- C code), as well as releases of Busybox and Linux (nearly gers. This is because most of the integer issues are benign. one billion lines of partially-preprocessed C code). We found But, there are two cases where the issues may cause serious that integer issues, that are allowed by the C standard but problems. One is in safety-critical sections, where untrapped not by the safer C standards, are ubiquitous|one out of four integer issues can lead to unexpected runtime behavior. An- integers were inconsistently declared, and one out of eight other is in security-critical sections, where integer issues can integers were inconsistently used. -

Understanding Integer Overflow in C/C++
Appeared in Proceedings of the 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, June 2012. Understanding Integer Overflow in C/C++ Will Dietz,∗ Peng Li,y John Regehr,y and Vikram Adve∗ ∗Department of Computer Science University of Illinois at Urbana-Champaign fwdietz2,[email protected] ySchool of Computing University of Utah fpeterlee,[email protected] Abstract—Integer overflow bugs in C and C++ programs Detecting integer overflows is relatively straightforward are difficult to track down and may lead to fatal errors or by using a modified compiler to insert runtime checks. exploitable vulnerabilities. Although a number of tools for However, reliable detection of overflow errors is surprisingly finding these bugs exist, the situation is complicated because not all overflows are bugs. Better tools need to be constructed— difficult because overflow behaviors are not always bugs. but a thorough understanding of the issues behind these errors The low-level nature of C and C++ means that bit- and does not yet exist. We developed IOC, a dynamic checking tool byte-level manipulation of objects is commonplace; the line for integer overflows, and used it to conduct the first detailed between mathematical and bit-level operations can often be empirical study of the prevalence and patterns of occurrence quite blurry. Wraparound behavior using unsigned integers of integer overflows in C and C++ code. Our results show that intentional uses of wraparound behaviors are more common is legal and well-defined, and there are code idioms that than is widely believed; for example, there are over 200 deliberately use it. -

5. Data Types
IEEE FOR THE FUNCTIONAL VERIFICATION LANGUAGE e Std 1647-2011 5. Data types The e language has a number of predefined data types, including the integer and Boolean scalar types common to most programming languages. In addition, new scalar data types (enumerated types) that are appropriate for programming, modeling hardware, and interfacing with hardware simulators can be created. The e language also provides a powerful mechanism for defining OO hierarchical data structures (structs) and ordered collections of elements of the same type (lists). The following subclauses provide a basic explanation of e data types. 5.1 e data types Most e expressions have an explicit data type, as follows: — Scalar types — Scalar subtypes — Enumerated scalar types — Casting of enumerated types in comparisons — Struct types — Struct subtypes — Referencing fields in when constructs — List types — The set type — The string type — The real type — The external_pointer type — The “untyped” pseudo type Certain expressions, such as HDL objects, have no explicit data type. See 5.2 for information on how these expressions are handled. 5.1.1 Scalar types Scalar types in e are one of the following: numeric, Boolean, or enumerated. Table 17 shows the predefined numeric and Boolean types. Both signed and unsigned integers can be of any size and, thus, of any range. See 5.1.2 for information on how to specify the size and range of a scalar field or variable explicitly. See also Clause 4. 5.1.2 Scalar subtypes A scalar subtype can be named and created by using a scalar modifier to specify the range or bit width of a scalar type. -

A Library for Interval Arithmetic Was Developed
1 Verified Real Number Calculations: A Library for Interval Arithmetic Marc Daumas, David Lester, and César Muñoz Abstract— Real number calculations on elementary functions about a page long and requires the use of several trigonometric are remarkably difficult to handle in mechanical proofs. In this properties. paper, we show how these calculations can be performed within In many cases the formal checking of numerical calculations a theorem prover or proof assistant in a convenient and highly automated as well as interactive way. First, we formally establish is so cumbersome that the effort seems futile; it is then upper and lower bounds for elementary functions. Then, based tempting to perform the calculations out of the system, and on these bounds, we develop a rational interval arithmetic where introduce the results as axioms.1 However, chances are that real number calculations take place in an algebraic setting. In the external calculations will be performed using floating-point order to reduce the dependency effect of interval arithmetic, arithmetic. Without formal checking of the results, we will we integrate two techniques: interval splitting and taylor series expansions. This pragmatic approach has been developed, and never be sure of the correctness of the calculations. formally verified, in a theorem prover. The formal development In this paper we present a set of interactive tools to automat- also includes a set of customizable strategies to automate proofs ically prove numerical properties, such as Formula (1), within involving explicit calculations over real numbers. Our ultimate a proof assistant. The point of departure is a collection of lower goal is to provide guaranteed proofs of numerical properties with minimal human theorem-prover interaction. -

Signedness-Agnostic Program Analysis: Precise Integer Bounds for Low-Level Code
Signedness-Agnostic Program Analysis: Precise Integer Bounds for Low-Level Code Jorge A. Navas, Peter Schachte, Harald Søndergaard, and Peter J. Stuckey Department of Computing and Information Systems, The University of Melbourne, Victoria 3010, Australia Abstract. Many compilers target common back-ends, thereby avoid- ing the need to implement the same analyses for many different source languages. This has led to interest in static analysis of LLVM code. In LLVM (and similar languages) most signedness information associated with variables has been compiled away. Current analyses of LLVM code tend to assume that either all values are signed or all are unsigned (except where the code specifies the signedness). We show how program analysis can simultaneously consider each bit-string to be both signed and un- signed, thus improving precision, and we implement the idea for the spe- cific case of integer bounds analysis. Experimental evaluation shows that this provides higher precision at little extra cost. Our approach turns out to be beneficial even when all signedness information is available, such as when analysing C or Java code. 1 Introduction The “Low Level Virtual Machine” LLVM is rapidly gaining popularity as a target for compilers for a range of programming languages. As a result, the literature on static analysis of LLVM code is growing (for example, see [2, 7, 9, 11, 12]). LLVM IR (Intermediate Representation) carefully specifies the bit- width of all integer values, but in most cases does not specify whether values are signed or unsigned. This is because, for most operations, two’s complement arithmetic (treating the inputs as signed numbers) produces the same bit-vectors as unsigned arithmetic. -

RICH: Automatically Protecting Against Integer-Based Vulnerabilities
RICH: Automatically Protecting Against Integer-Based Vulnerabilities David Brumley, Tzi-cker Chiueh, Robert Johnson [email protected], [email protected], [email protected] Huijia Lin, Dawn Song [email protected], [email protected] Abstract against integer-based attacks. Integer bugs appear because programmers do not antici- We present the design and implementation of RICH pate the semantics of C operations. The C99 standard [16] (Run-time Integer CHecking), a tool for efficiently detecting defines about a dozen rules governinghow integer types can integer-based attacks against C programs at run time. C be cast or promoted. The standard allows several common integer bugs, a popular avenue of attack and frequent pro- cases, such as many types of down-casting, to be compiler- gramming error [1–15], occur when a variable value goes implementation specific. In addition, the written rules are out of the range of the machine word used to materialize it, not accompanied by an unambiguous set of formal rules, e.g. when assigning a large 32-bit int to a 16-bit short. making it difficult for a programmer to verify that he un- We show that safe and unsafe integer operations in C can derstands C99 correctly. Integer bugs are not exclusive to be captured by well-known sub-typing theory. The RICH C. Similar languages such as C++, and even type-safe lan- compiler extension compiles C programs to object code that guages such as Java and OCaml, do not raise exceptions on monitors its own execution to detect integer-based attacks. -

Complete Interval Arithmetic and Its Implementation on the Computer
Complete Interval Arithmetic and its Implementation on the Computer Ulrich W. Kulisch Institut f¨ur Angewandte und Numerische Mathematik Universit¨at Karlsruhe Abstract: Let IIR be the set of closed and bounded intervals of real numbers. Arithmetic in IIR can be defined via the power set IPIR (the set of all subsets) of real numbers. If divisors containing zero are excluded, arithmetic in IIR is an algebraically closed subset of the arithmetic in IPIR, i.e., an operation in IIR performed in IPIR gives a result that is in IIR. Arithmetic in IPIR also allows division by an interval that contains zero. Such division results in closed intervals of real numbers which, however, are no longer bounded. The union of the set IIR with these new intervals is denoted by (IIR). The paper shows that arithmetic operations can be extended to all elements of the set (IIR). On the computer, arithmetic in (IIR) is approximated by arithmetic in the subset (IF ) of closed intervals over the floating-point numbers F ⊂ IR. The usual exceptions of floating-point arithmetic like underflow, overflow, division by zero, or invalid operation do not occur in (IF ). Keywords: computer arithmetic, floating-point arithmetic, interval arithmetic, arith- metic standards. 1 Introduction or a Vision of Future Computing Computers are getting ever faster. The time can already be foreseen when the P C will be a teraflops computer. With this tremendous computing power scientific computing will experience a significant shift from floating-point arithmetic toward increased use of interval arithmetic. With very little extra hardware, interval arith- metic can be made as fast as simple floating-point arithmetic [3]. -
C Language Features
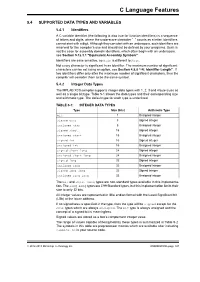
C Language Features 5.4 SUPPORTED DATA TYPES AND VARIABLES 5.4.1 Identifiers A C variable identifier (the following is also true for function identifiers) is a sequence of letters and digits, where the underscore character “_” counts as a letter. Identifiers cannot start with a digit. Although they can start with an underscore, such identifiers are reserved for the compiler’s use and should not be defined by your programs. Such is not the case for assembly domain identifiers, which often begin with an underscore, see Section 5.12.3.1 “Equivalent Assembly Symbols”. Identifiers are case sensitive, so main is different to Main. Not every character is significant in an identifier. The maximum number of significant characters can be set using an option, see Section 4.8.8 “-N: Identifier Length”. If two identifiers differ only after the maximum number of significant characters, then the compiler will consider them to be the same symbol. 5.4.2 Integer Data Types The MPLAB XC8 compiler supports integer data types with 1, 2, 3 and 4 byte sizes as well as a single bit type. Table 5-1 shows the data types and their corresponding size and arithmetic type. The default type for each type is underlined. TABLE 5-1: INTEGER DATA TYPES Type Size (bits) Arithmetic Type bit 1 Unsigned integer signed char 8 Signed integer unsigned char 8 Unsigned integer signed short 16 Signed integer unsigned short 16 Unsigned integer signed int 16 Signed integer unsigned int 16 Unsigned integer signed short long 24 Signed integer unsigned short long 24 Unsigned integer signed long 32 Signed integer unsigned long 32 Unsigned integer signed long long 32 Signed integer unsigned long long 32 Unsigned integer The bit and short long types are non-standard types available in this implementa- tion. -
Practical Integer Overflow Prevention
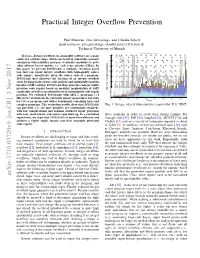
Practical Integer Overflow Prevention Paul Muntean, Jens Grossklags, and Claudia Eckert {paul.muntean, jens.grossklags, claudia.eckert}@in.tum.de Technical University of Munich Memory error vulnerabilities categorized 160 Abstract—Integer overflows in commodity software are a main Other Format source for software bugs, which can result in exploitable memory Pointer 140 Integer Heap corruption vulnerabilities and may eventually contribute to pow- Stack erful software based exploits, i.e., code reuse attacks (CRAs). In 120 this paper, we present INTGUARD, a symbolic execution based tool that can repair integer overflows with high-quality source 100 code repairs. Specifically, given the source code of a program, 80 INTGUARD first discovers the location of an integer overflow error by using static source code analysis and satisfiability modulo 60 theories (SMT) solving. INTGUARD then generates integer multi- precision code repairs based on modular manipulation of SMT 40 Number of VulnerabilitiesNumber of constraints as well as an extensible set of customizable code repair 20 patterns. We evaluated INTGUARD with 2052 C programs (≈1 0 Mil. LOC) available in the currently largest open-source test suite 2000 2002 2004 2006 2008 2010 2012 2014 2016 for C/C++ programs and with a benchmark containing large and Year complex programs. The evaluation results show that INTGUARD Fig. 1: Integer related vulnerabilities reported by U.S. NIST. can precisely (i.e., no false positives are accidentally repaired), with low computational and runtime overhead repair programs with very small binary and source code blow-up. In a controlled flows statically in order to avoid them during runtime. For experiment, we show that INTGUARD is more time-effective and example, Sift [35], TAP [56], SoupInt [63], AIC/CIT [74], and achieves a higher repair success rate than manually generated CIntFix [11] rely on a variety of techniques depicted in detail code repairs. -

MPFI: a Library for Arbitrary Precision Interval Arithmetic
MPFI: a library for arbitrary precision interval arithmetic Nathalie Revol Ar´enaire (CNRS/ENSL/INRIA), LIP, ENS-Lyon and Lab. ANO, Univ. Lille [email protected] Fabrice Rouillier Spaces, CNRS, LIP6, Univ. Paris 6, LORIA-INRIA [email protected] SCAN 2002, Paris, France, 24-27 September Reliable computing: Interval Arithmetic (Moore 1966, Kulisch 1983, Neumaier 1990, Rump 1994, Alefeld and Mayer 2000. ) Numbers are replaced by intervals. Ex: π replaced by [3.14159, 3.14160] Computations: can be done with interval operands. Advantages: • Every result is guaranteed (including rounding errors). • Data known up to measurement errors are representable. • Global information can be reached (“computing in the large”). Drawbacks: overestimation of the results. SCAN 2002, Paris, France - 1 N. Revol & F. Rouillier Hansen’s algorithm for global optimization Hansen 1992 L = list of boxes to process := {X0} F : function to minimize while L= 6 ∅ loop suppress X from L reject X ? yes if F (X) > f¯ yes if GradF (X) 63 0 yes if HF (X) has its diag. non > 0 reduce X Newton applied with the gradient solve Y ⊂ X such that F (Y ) ≤ f¯ bisect Y into Y1 and Y2 if Y is not a result insert Y1 and Y2 in L SCAN 2002, Paris, France - 2 N. Revol & F. Rouillier Solving linear systems preconditioned Gauss-Seidel algorithm Hansen & Sengupta 1981 Linear system: Ax = b with A and b given. Problem: compute an enclosure of Hull (Σ∃∃(A, b)) = Hull ({x : ∃A ∈ A, ∃b ∈ b, Ax = b}). Hansen & Sengupta’s algorithm compute C an approximation of mid(A)−1 apply Gauss-Seidel to CAx = Cb until convergence. -

Multistage Algorithms in C++
Multistage Algorithms in C++ Dissertation zur Erlangung des Doktorgrades der Mathematisch-Naturwissenschaftlichen FakultÄaten der Georg-August-UniversitÄat zu GÄottingen vorgelegt von Andreas Priesnitz aus GÄottingen GÄottingen 2005 D7 Referent: Prof. Dr. G. Lube Korreferent: Prof. Dr. R. Schaback Tag der mundlicÄ hen Prufung:Ä 2. November 2005 Andreas Priesnitz Multistage Algorithms in C++ in commemoration of my father, Kuno Priesnitz Contents 1 Frequently Asked Questions 1 1.1 Who is it for? . 1 1.1.1 Domain of interest . 1 1.1.2 Domain of knowledge . 2 1.2 What is it for? . 2 1.2.1 E±ciency . 2 1.2.2 Abstraction . 3 1.2.3 Situation . 4 1.2.4 Quest . 5 1.3 Where is it from? . 5 1.3.1 Related subjects . 6 1.3.2 Related information . 6 1.3.3 Related software . 6 1.4 How is it done? . 7 1.4.1 Structure . 7 1.4.2 Language . 7 1.4.3 Layout . 8 I Paradigms 9 2 Object-oriented programming 11 2.1 User-de¯ned types . 11 2.1.1 Enumeration types . 11 2.1.2 Class types . 12 2.1.3 Class object initialization . 13 2.1.4 Class interface . 14 2.1.5 Global functions . 14 2.1.6 Inheritance . 15 2.1.7 Performance impact . 18 2.2 Dynamic polymorphism . 19 2.2.1 Virtual functions . 19 2.2.2 Integration into the type system . 20 2.2.3 Performance impact . 22 I 3 Generic programming 25 3.1 Class templates . 25 3.1.1 Constant template parameters .