Metacluster.PT Um Meta-Motor De Pesquisa Para a Web Portuguesa
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Appendix I: Search Quality and Economies of Scale
Appendix I: search quality and economies of scale Introduction 1. This appendix presents some detailed evidence concerning how general search engines compete on quality. It also examines network effects, scale economies and other barriers to search engines competing effectively on quality and other dimensions of competition. 2. This appendix draws on academic literature, submissions and internal documents from market participants. Comparing quality across search engines 3. As set out in Chapter 3, the main way that search engines compete for consumers is through various dimensions of quality, including relevance of results, privacy and trust, and social purpose or rewards.1 Of these dimensions, the relevance of search results is generally considered to be the most important. 4. In this section, we present consumer research and other evidence regarding how search engines compare on the quality and relevance of search results. Evidence on quality from consumer research 5. We reviewed a range of consumer research produced or commissioned by Google or Bing, to understand how consumers perceive the quality of these and other search engines. The following evidence concerns consumers’ overall quality judgements and preferences for particular search engines: 6. Google submitted the results of its Information Satisfaction tests. Google’s Information Satisfaction tests are quality comparisons that it carries out in the normal course of its business. In these tests, human raters score unbranded search results from mobile devices for a random set of queries from Google’s search logs. • Google submitted the results of 98 tests from the US between 2017 and 2020. Google outscored Bing in each test; the gap stood at 8.1 percentage points in the most recent test and 7.3 percentage points on average over the period. -

Motori Di Ricerca E Portali, Dei
2 Repertorio Il testo è un repertorio di oltre 180 motori di ricerca e portali, dei escluse le piattaforme commerciali come Amazon, iTunes, ecc. motori I motori di ricerca sicuri e consigliati, quali SearX, Qwant, Startpage e DuckDuckGo, sono stati omessi, così come Google (analizzato esclusivamente per il carattere quasi monopolistico), in quanto di Repertorio dei trattati nel volume Motori di ricerca, Trovare informazioni in rete. ricer Strumenti per le ricerche sul web. Il catalogo è articolato per macro-aree tematiche relative alle ca. motori di ricerca possibili ricerche: privacy e sicurezza, tipologia di contenuti e T risultati, musica, video, foto, immagini, icone, eBook, documenti. r ovar Il capitolo primo tratta i motori di ricerca sicuri e a tutela della Trovare informazioni in rete privacy. e Il capitolo secondo riporta i motori di ricerca focalizzati sulla infor Strumenti per le ricerche sul web tipologia di contenuti e risultati. Un esempio sono CC Search, per la ricerca di contenuti multimediali non coperti da copyright, mazioni oppure FindSounds per l’individuazione di suoni in fonti aperte. I capitoli successivi hanno come oggetto le risorse per la ricerca di contenuti documentali e multimediali. Flavio Gallucci in Il capitolo terzo raccoglie le risorse per la ricerca di foto, immagini r e icone. TinEye merita attenzione per la tecnica di reverse image ete. search, ovvero la ricerca a partire dal caricamento di una foto. Strumenti Il capitolo quarto elenca strumenti e risorse per la ricerca di brani musicali, l’ascolto di musica in streaming e l’individuazione di eventi. Il capitolo quinto propone i portali dedicati alla ricerca di video. -

Evaluating the Suitability of Web Search Engines As Proxies for Knowledge Discovery from the Web
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 96 ( 2016 ) 169 – 178 20th International Conference on Knowledge Based and Intelligent Information and Engineering Systems, KES2016, 5-7 September 2016, York, United Kingdom Evaluating the suitability of Web search engines as proxies for knowledge discovery from the Web Laura Martínez-Sanahuja*, David Sánchez UNESCO Chair in Data Privacy, Department of Computer Engineering and Mathematics, Universitat Rovira i Virgili Av.Països Catalans, 26, 43007 Tarragona, Catalonia, Spain Abstract Many researchers use the Web search engines’ hit count as an estimator of the Web information distribution in a variety of knowledge-based (linguistic) tasks. Even though many studies have been conducted on the retrieval effectiveness of Web search engines for Web users, few of them have evaluated them as research tools. In this study we analyse the currently available search engines and evaluate the suitability and accuracy of the hit counts they provide as estimators of the frequency/probability of textual entities. From the results of this study, we identify the search engines best suited to be used in linguistic research. © 20162016 TheThe Authors. Authors. Published Published by by Elsevier Elsevier B.V. B.V. This is an open access article under the CC BY-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/). Peer-review under responsibility of KES International. Peer-review under responsibility of KES International Keywords: Web search engines; hit count; information distribution; knowledge discovery; semantic similarity; expert systems. 1. Introduction Expert and knowledge-based systems rely on data to build the knowledge models required to perform inferences or answer questions. -

Expert Internet Searching
Bradley 5th ed 2017 7th proof 6 June 06/06/2017 17:19 Page i >>Expert internet searching FIFTH EDITION Bradley 5th ed 2017 7th proof 6 June 06/06/2017 17:19 Page ii Every purchase of a Facet book helps to fund CILIP’s advocacy, awareness and accreditation programmes for information professionals. Bradley 5th ed 2017 7th proof 6 June 06/06/2017 17:19 Page iii >>Expert internet searching FIFTH EDITION Phil Bradley Bradley 5th ed 2017 7th proof 6 June 06/06/2017 17:19 Page iv © Phil Bradley 1999, 2002, 2004, 2013, 2017 Published by Facet Publishing 7 Ridgmount Street, London WC1E 7AE www.facetpublishing.co.uk Facet Publishing is wholly owned by CILIP: the Library and Information Association. The author has asserted his right under the Copyright, Designs and Patents Act 1988 to be identified as author of this work. Except as otherwise permitted under the Copyright, Designs and Patents Act 1988 this publication may only be reproduced, stored or transmitted in any form or by any means, with the prior permission of the publisher, or, in the case of reprographic reproduction, in accordance with the terms of a licence issued by The Copyright Licensing Agency. Enquiries concerning reproduction outside those terms should be sent to Facet Publish- ing, 7 Ridgmount Street, London WC1E 7AE. Every effort has been made to contact the holders of copyright material reproduced in this text, and thanks are due to them for permission to reproduce the material indicated. If there are any queries please contact the publisher. British Library Cataloguing in Publication Data A catalogue record for this book is available from the British Library. -

Kommentierte Linkliste
Linkliste für Schüler*innen letztmals aktualisiert am 19.01.2021 Begabungslotse https://www.begabungslotse.de Insbesondere die Rubrik Digitalspecial und deren angedockte Tools und Links fürs Lernen (Live-Streams, Erklärvideos und Lern-Apps etc.) stellen eine echte Bereicherung für den Schulalltag dar. Bewertung (Evaluation) von Internetseiten http://www.ub.ruhr-uni-bochum.de/digibib/Seminar/Evaluation_WWW- Seiten.html Wie zuverlässig ist eine Internetquelle? Wie beurteile ich das? Worauf muss ich achten? Eine diesbezüglich sehr nützliche Zusammenstellung von Informationen insbesondere für Schüler*innen der gymnasialen Oberstufe und Student*innen. Britannica Library https://www.britannica.com/ Die berühmte Encyclodaedia Britannica ist eine englischsprachige Enzyklopädie, die das menschliche Wissen in möglichst großer Breite darzustellen versucht. Insbesondere ihre wissenschaftlichen Angaben (Quellennachweise, Quellenverweise, Bildnachweise etc.) sind sehr zuverlässig, was aus der Tatsache, dass viele namhafte Wissenschaftler*innen und Publizist*innen an der Enzyklopädie mitarbeiten, herrührt. Bundeszentrale für politische Bildung https://www.bpb.de/ Besonders für die gesellschaftswissenschaftlichen Fächer sind die Seiten der bpb absolut empfehlenswert; hier „lagern“ relevante Informationen zu so gut wie jeder Anfrage zum Thema. CC Search – Search for Content Reuse (Bildersuche) https://ccsearch.creativecommons.org/ Unzählige Bilder stehen hier zur weiteren kostenlosen! Verwendung zur Verfügung. Deutsche Biographie https://www.deutsche-biographie.de/index.html -

Internet Resources
Internet Resources Search Engines Alta Vista – (Now Yahoo) Gseek - www.gseek.com Ask – www.ask.com HotBot - www.hotbot.com/ Baidu - www.baidu.com/ (China) Kngine - www.kngine.com Bing - www.bing.com Lycos - www.lycos.com/ Blekko - blekko.com/ Mamma – www.mamma.com Cluuz - www.cluuz.com Mojeek - www.mojeek.com Deeperweb - www.deeperweb.com Mozbot - www.mozbot.com DuckDuckGo - duckduckgo.com/ Quintura – (Now a children’s Search Engine) Entireweb - www.entireweb.com Spacetime - www.spacetime.com Exalead - www.exalead.com/search/ Teoma – (Now Ask.com) Factbites - www.factbites.com Untabbed - untabbed.com (Google Results) Fagan Finder - www.faganfinder.com WbSrch - wbsrch.com/ Fraze It - fraze.it/ WolframAlpha - www.wolframalpha.com Google - www.google.com/ Yahoo - search.yahoo.com/ Gigablast - www.gigablast.com/ Yandex – www.yandex.com (Russia/CIS in English) Yandex - www.yandex.ru/ (Russia/CIS in Russian) Meta-Search Engines Carrot2 - search.carrot2.org Search.com - www.search.com/ Dogpile - www.dogpile.com/ Scour - www.scour.com/ eTools - www.etools.ch/ (15 Search Engines) Surfwax – www.surfwax.com (RSS Meta-Search) Excite – www.excite.co.uk Webcrawler – www.webcrawler.com Graball – www.graball.com Webfetch - www.webfetch.com/ Ixquick - ixquick.com/ YaBiGo - yabigo.com/ MetaCrawler – www.metacrawler.com Yippy - www.yippy.com/ MetaGer - metager.de/ Yometa - www.yometa.com/ oSkope - oskope.com/ Zapmeta - www.zapmeta.com/ PolyCola - www.polycola.com/ Zoo - www.zoo.com PolyMeta - www.polymeta.com/ Zuula - www.zuula.com/ Web Directories Accoona -
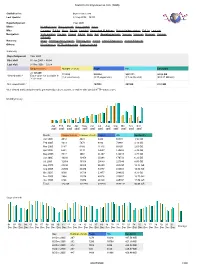
Statistics for Brynosaurus.Com (2005)
Statistics for brynosaurus.com (2005) Statistics for: brynosaurus.com Last Update: 27 Sep 2006 − 06:00 Reported period: Year 2005 When: Monthly history Days of month Days of week Hours Who: Countries Full list Hosts Full list Last visit Unresolved IP Address Robots/Spiders visitors Full list Last visit Navigation: Visits duration File type Viewed Full list Entry Exit Operating Systems Versions Unknown Browsers Versions Unknown Referers: Origin Refering search engines Refering sites Search Search Keyphrases Search Keywords Others: Miscellaneous HTTP Status codes Pages not found Summary Reported period Year 2005 First visit 01 Jan 2005 − 00:04 Last visit 31 Dec 2005 − 23:54 Unique visitors Number of visits Pages Hits Bandwidth <= 125249 151229 328224 2621111 94.06 GB Viewed traffic * Exact value not available in (1.2 visits/visitor) (2.17 pages/visit) (17.33 hits/visit) (652.17 KB/visit) 'Year' view Not viewed traffic * 167672 261929 7.32 GB * Not viewed traffic includes traffic generated by robots, worms, or replies with special HTTP status codes. Monthly history Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 2005 2005 2005 2005 2005 2005 2005 2005 2005 2005 2005 2005 Month Unique visitors Number of visits Pages Hits Bandwidth Jan 2005 4012 4621 8432 62678 1.93 GB Feb 2005 4919 5671 8892 79888 2.10 GB Mar 2005 5487 6460 11410 93405 2.66 GB Apr 2005 6941 8147 23657 130853 3.49 GB May 2005 7517 9004 21307 139015 3.71 GB Jun 2005 10393 12458 25968 170723 6.32 GB Jul 2005 12958 15156 28649 225540 8.05 GB Aug 2005 22292 25919 46389 355390 -

Garainyh 1 5 3 Keresőben
GARAINYH 1 5 3 KERESŐBEN TOP 1 5 3 – „*garainyh*” – World Wide Web www.cím Internet link domain név kereső és kulcsszó katalógus List of the best meta search engines and web browsers Forrás: https://www.garainyh.hu/kep/DOMAIN.pdf & https://www.garainyh.hu/garainyh/webcimeim.html Elérhető: https://www.andrisnyh.zsoltar.hu/ & https://www.garainyh.com/ Az ÚR Jézus Krisztus megjelenik a Tibériás-tengernél: a nagy halfogás; „Simon Péter beszállt, és kivonta a partra a hálót, amely tele volt nagy halakkal, szám szerint százötvenhárommal; és bár ilyen sok volt, nem szakadt el a háló.” (Jn 21,11; RÚF) – Az ÚR Jézus így szólt: „Hirdessétek az evangéliumot minden teremtménynek!” (Mk 16,15b; RÚF) * 11 HU: (hazai) * GOOGLE.HU * BLOG.HU * KERESOK.WYW.HU * ZOPE.LUTHERAN.HU * EVANGELIKUS.HU * ARCHIV.EVANGELIKUS.HU * DOCPLAYER.HU * LAPOZZ.HU * ZAPMETA.HU * KERESO.STARTLAP.HU * POLYMETA.HU # * * 78 COM: (nemzetközi) * GOOGLE.COM ¤ * SEARCH.YAHOO.COM ¤ * BING.COM ¤ * ASK.COM ¤ * MOJEEK.COM ¤ * SEARCH.AOL.COM ¤ * DUCKDUCKGO.COM ¤ * YANDEX.COM ¤ * BAIDU.COM ¤ * QWANT.COM ¤ * SEARCH.NAVER.COM ¤ * PEEKIER.COM ¤ * GIBIRU.COM ¤ * CSE.GOOGLE.COM * GIGABLAST.COM * GLOWSTERY.COM * SOCIAL-SEARCHER.COM * FINDX.COM * NORTONSAFE.SEARCH.ASK.COM * ONIONSEARCHENGINE.COM * SEARCHALOT.COM * DRAZE.COM * SPOKEO.COM * PEEKYOU.COM * SWISSCOWS.COM * RESULTS.SEARCHLOCK.COM * GIVERO.COM * WHALESLIDE.COM * SEARCH.MONSTERCRAWLER.COM * SEARCHYANDEX.COM * GOOFRAM.COM * TADADOO.COM * IZITO.COM * REFERENCE.COM * ALLTHEINTERNET.COM * WOW.COM * LUKOL.COM * ENTIREWEB.COM * ZAPMETA.COM -

Open Source Intelligence Tools and Resources Handbook.Pdf
Open Source Intelligence Tools and Resources Handbook November 2016 Table of Contents Table of Contents ...................................................................................................................................... 2 General Search ........................................................................................................................................... 5 Main National Search Engines ................................................................................................................. 7 Meta Search ............................................................................................................................................... 8 Specialty Search Engines .......................................................................................................................... 9 Visual Search and Clustering Search Engines ..................................................................................... 10 Similar Sites Search ................................................................................................................................. 11 Document and Slides Search ................................................................................................................. 12 Pastebins ................................................................................................................................................... 13 Code Search ............................................................................................................................................ -

Giant List of Search Engines
Giant List of Search Engines Search & find, try new dataset, new methods & ways to break the monotony of their ministry. Add extra power to your IR. Fast finding dear scholar. All links open in new windows. 1. 100 Search Engines https://www.100searchengines.com 2. 360Daily http://www.360daily.com 3. AddressSearch http://addresssearch.com 4. Alibaba https://www.alibaba.com 5. Alleba http://www.alleba.com 6. Allrecipes http://allrecipes.com 7. Alumni http://www.alumni.net 8. Amazon https://www.amazon.com 9. American Hospital Directory https://www.ahd.com 10. Answers.com https://www.answers.com 11. AnyWho http://www.anywho.com 12. Ask.com https://www.ask.com 13. Baidu https://www.baidu.com 14. Bankersalmanac https://www.bankersalmanac.com 15. BeenVerified https://www.beenverified.com 16. BigOven http://www.bigoven.com 17. Bing https://www.bing.com 18. Bing Maps https://www.bing.com/maps 19. Blockchain Explorer https://www.blockchain.com/explorer 20. Blockchair https://blockchair.com 21. Boardreader http://boardreader.com 22. BuiltWith http://builtwith.com 23. BuzzSumo http://buzzsumo.com 24. Canadian Law List https://www.canadianlawlist.com 25. CareerBuilder http://www.careerbuilder.com 26. CC Search https://ccsearch.creativecommons.org 27. Cheat Search http://www.cheatsearch.net 28. Check Usernames https://checkusernames.com 29. Chegg https://www.chegg.com 30. Classmates http://www.classmates.com 31. ClinicalTrials.gov https://clinicaltrials.gov 32. CookThing http://www.cookthing.com 33. Court Record Finder https://www.courtrecordfinder.com 34. Craigsist https://www.craigslist.org 35. DataparkSearch Engine http://www.dataparksearch.org 36. Daum https://www.daum.net 37. -
The Case of a Green Search Engine
Article The Effect of Internet Searches on Afforestation: The Case of a Green Search Engine Pedro Palos-Sanchez 1,2,* ID and Jose Ramon Saura 3,* ID 1 Department of Business Management, University of Extremadura, Av. Universidad, s/n, 10003 Cáceres, Spain 2 Department of Business Organization, Marketing and Market Research, International University of La Rioja, Av. de la Paz, 137, 26006 Logroño, Spain 3 Department of Business and Economics, Rey Juan Carlos University, Paseo Artilleros s/n, 28027 Madrid, Spain * Correspondence: [email protected] (P.P.-S.); [email protected] (J.R.S.); Tel.: +34-927-257-480 (P.P.-S.); +34-91-488-80-11 (J.R.S.) Received: 17 November 2017; Accepted: 19 January 2018; Published: 23 January 2018 Abstract: Ecosia is an Internet search engine that plants trees with the income obtained from advertising. This study explored the factors that affect the adoption of Ecosia.org from the perspective of technology adoption and trust. This was done by using the Unified Theory of Acceptance and Use of Technology (UTAUT2) and then analyzing the results with PLS-SEM (Partial Least Squares-Structural Equation Modeling). Subsequently, a survey was conducted with a structured questionnaire on search engines, which yielded the following results: (1) the idea of a company helping to mitigate the effects of climate change by planting trees is well received by Internet users. However, few people accept the idea of changing their habits from using traditional search engines; (2) Ecosia is a search engine believed to have higher compatibility rates, and needing less hardware resources, and (3) ecological marketing is an appropriate and future strategy that can increase the intention to use a technological product. -

Information Quality Is an Ethical Responsibility of Search Engines
Online information of vaccines: information quality is an ethical responsibility of search engines Pietro Ghezzi1*, Peter G Bannister1, Gonzalo Casino2-3, Alessia Catalani4, Michel Goldman5, Jessica Morley6, Marie Neunez5, Andreu Prados2-7, Mariarosaria Taddeo6-8, Tania Vanzolini4 and Luciano Floridi 6-8 1 Brighton & Sussex Medical School, Falmer, Brighton, UK 2 Communication Department, Pompeu Fabra University, Barcelona, Spain 3 Iberoamerican Cochrane Center, Barcelona, Spain 4 Department of Biomolecular Sciences, University of Urbino Carlo Bo, Urbino, PU, Italy. 5 Institute for Interdisciplinary Innovation in healthcare (I3h), Université libre de Bruxelles 6 Oxford Internet Institute, University of Oxford, Oxford, UK 7 Blanquerna School of Health Sciences, Universitat Ramon Llull, Barcelona, Spain. 8 The Alan Turing Institute, London, UK *Corresponding author: Professor Pietro Ghezzi, Brighton and Sussex Medical School, Trafford Centre, University of Sussex, Falmer, Brighton, BN19RY, UK. Email: [email protected]; phone: +44-(0)1273-873112 1 Abstract The fact that Internet companies may record our personal data and track our online behaviour for commercial or political purpose has emphasized aspects related to online privacy. This has also led to the development of search engines that promise no tracking and privacy. Search engines also have a major role in spreading low-quality health information such as that of anti-vaccine websites. This study investigates the relationship between search engines’ approach to privacy and the scientific quality of the information they return. We analyzed the first 30 webpages returned searching “vaccines autism” in English, Spanish, Italian and French. The results show that “alternative” search engines (Duckduckgo, Ecosia, Qwant, Swisscows and Mojeek) may return more anti-vaccine pages (10-53%) than Google.com (0%).