Hampson, Cormac TCD-SCSS-PHD-2011-13.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
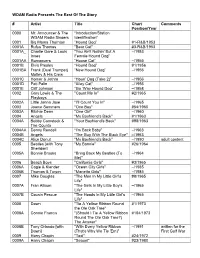
WDAM Radio Presents the Rest of the Story
WDAM Radio Presents The Rest Of The Story # Artist Title Chart Comments Position/Year 0000 Mr. Announcer & The “Introduction/Station WDAM Radio Singers Identification” 0001 Big Mama Thornton “Hound Dog” #1-R&B/1953 0001A Rufus Thomas "Bear Cat" #3-R&B/1953 0001A_ Charlie Gore & Louis “You Ain't Nothin' But A –/1953 Innes Female Hound Dog” 0001AA Romancers “House Cat” –/1955 0001B Elvis Presley “Hound Dog” #1/1956 0001BA Frank (Dual Trumpet) “New Hound Dog” –/1956 Motley & His Crew 0001C Homer & Jethro “Houn’ Dog (Take 2)” –/1956 0001D Pati Palin “Alley Cat” –/1956 0001E Cliff Johnson “Go ‘Way Hound Dog” –/1958 0002 Gary Lewis & The "Count Me In" #2/1965 Playboys 0002A Little Jonna Jaye "I'll Count You In" –/1965 0003 Joanie Sommers "One Boy" #54/1960 0003A Ritchie Dean "One Girl" –/1960 0004 Angels "My Boyfriend's Back" #1/1963 0004A Bobby Comstock & "Your Boyfriend's Back" #98/1963 The Counts 0004AA Denny Rendell “I’m Back Baby” –/1963 0004B Angels "The Guy With The Black Eye" –/1963 0004C Alice Donut "My Boyfriend's Back" –/1990 adult content 0005 Beatles [with Tony "My Bonnie" #26/1964 Sheridan] 0005A Bonnie Brooks "Bring Back My Beatles (To –/1964 Me)" 0006 Beach Boys "California Girls" #3/1965 0006A Cagle & Klender "Ocean City Girls" –/1985 0006B Thomas & Turpin "Marietta Girls" –/1985 0007 Mike Douglas "The Men In My Little Girl's #8/1965 Life" 0007A Fran Allison "The Girls In My Little Boy's –/1965 Life" 0007B Cousin Fescue "The Hoods In My Little Girl's –/1965 Life" 0008 Dawn "Tie A Yellow Ribbon Round #1/1973 the Ole Oak Tree" -

The Top 7000+ Pop Songs of All-Time 1900-2017
The Top 7000+ Pop Songs of All-Time 1900-2017 Researched, compiled, and calculated by Lance Mangham Contents • Sources • The Top 100 of All-Time • The Top 100 of Each Year (2017-1956) • The Top 50 of 1955 • The Top 40 of 1954 • The Top 20 of Each Year (1953-1930) • The Top 10 of Each Year (1929-1900) SOURCES FOR YEARLY RANKINGS iHeart Radio Top 50 2018 AT 40 (Vince revision) 1989-1970 Billboard AC 2018 Record World/Music Vendor Billboard Adult Pop Songs 2018 (Barry Kowal) 1981-1955 AT 40 (Barry Kowal) 2018-2009 WABC 1981-1961 Hits 1 2018-2017 Randy Price (Billboard/Cashbox) 1979-1970 Billboard Pop Songs 2018-2008 Ranking the 70s 1979-1970 Billboard Radio Songs 2018-2006 Record World 1979-1970 Mediabase Hot AC 2018-2006 Billboard Top 40 (Barry Kowal) 1969-1955 Mediabase AC 2018-2006 Ranking the 60s 1969-1960 Pop Radio Top 20 HAC 2018-2005 Great American Songbook 1969-1968, Mediabase Top 40 2018-2000 1961-1940 American Top 40 2018-1998 The Elvis Era 1963-1956 Rock On The Net 2018-1980 Gilbert & Theroux 1963-1956 Pop Radio Top 20 2018-1941 Hit Parade 1955-1954 Mediabase Powerplay 2017-2016 Billboard Disc Jockey 1953-1950, Apple Top Selling Songs 2017-2016 1948-1947 Mediabase Big Picture 2017-2015 Billboard Jukebox 1953-1949 Radio & Records (Barry Kowal) 2008-1974 Billboard Sales 1953-1946 TSort 2008-1900 Cashbox (Barry Kowal) 1953-1945 Radio & Records CHR/T40/Pop 2007-2001, Hit Parade (Barry Kowal) 1953-1935 1995-1974 Billboard Disc Jockey (BK) 1949, Radio & Records Hot AC 2005-1996 1946-1945 Radio & Records AC 2005-1996 Billboard Jukebox -

Disk Catalog by Category
COUNTRY: 50's 60's - KaraokeStar.com 800-386-5743 or 602-569-7827 COUNTRY: 50's & 60's COUNTRY: 50's & 60's COUNTRY: 50's & 60's COUNTRY: 50's & 60's You Are My Sunshine Autry, Gene Then And Only Then Smith, Connie Vocal Guides: Yes Vocal Guides: No CB20499 Lyric Sheet: No Wagon Wheels Arnold, Eddy CB60294 Lyric Sheet: No I'll Hold You In My Heart Arnold, Eddy Faster Horses Hall, Tom T You Two Timed Me One Time T Ritter, Tex Chartbuster 6+6 Country KaraokeStar.com Chartbuster Pro Country KaraokeStar.com Snakes Crawl At Night, The Pride, Charley Am I That Easy To Forget David, Skeeter Hits Of Eddy Arnold Vol 1 $12.99 Chartbuster Country Vol 294 $19.99 Big Boss Man Rich, Charlie Don't Fence Me In Autry, Gene Make The World Go Away Arnold, Eddy My Shoes Keep Walking Back To Price, Ray Don't Cry Joni Twitty, Conway Don't Rob Another Man's Castle Arnold, Eddy You Don't Know Me Arnold, Eddy Filipino Baby Tubb, Ernest You're The Best Thing That Ever Price, Ray Take Me To Your World Wynette, Tammy Anytime Arnold, Eddy Blue Side Of Lonesome Reeves, Jim It's So Easy Ronstadt, Linda Bouquet Of Roses Arnold, Eddy Crystal Chandeliers Pride, Charley Vocal Guides: No Mom And Dad's Waltz Frizzell, Lefty CB60333 Lyric Sheet: No Cattle Call Arnold, Eddy I've Done Enough Dyin' TodayGatlin, Larry & The KaraokeStar.com What's He Doing In My World Arnold, Eddy Vocal Guides: No It's All Wrong But It's All Right Parton, Dolly Chartbuster Classic Country CB60282 Lyric Sheet: No Classic Country Vol 333 Pop A Top Brown, Jim Ed $19.99 KaraokeStar.com Vocal Guides: -

Download This PDF File
Empirical Musicology Review Vol. 10, No. 3, 2015 “The Times They Were A-Changin’”: A Database-Driven Approach to the Evolution of Harmonic Syntax in Popular Music from the 1960s HUBERT LÉVEILLÉ GAUVIN [1] Schulich School of Music, McGill University ABSTRACT: The goal of this research is to investigate the pitch structures of popular music in the 1960s through a large corpus study in order to identify any consistent changes in harmonic and tonal syntax. More specifically, two studies based on the Billboard DataSet (Burgoyne, Wild & Fujinaga, 2011; Burgoyne, 2011), a new corpus presenting transcriptions for more than 700 songs, are presented. The first study looks at the incidence of multi-tonic songs throughout the decade, while the second study focuses on the incidence of flat-side harmonies (e.g. bIII, bVI, and bVII) over the same period of time. While no difference was observed in the frequency of multi-tonic songs, the study showed a significant increase in the incidence of flat-side harmonies during the second half of the decade. Submitted 2014 September 16; accepted 2015 April 9. KEYWORDS: popular music, corpus, Billboard, harmony, modulation IN January 1964 Bob Dylan released “The Times They Are A-Changin,” a politically-charged protest song encouraging changes in American society. Indeed the 1960s were a time of great political, but also sociological and cultural changes, accompanied by equally important developments in popular music. Many music scholars have addressed the attitudinal shift associated with this period, noting that “[r]ock musicians no longer aspire[d] so much to be professionals and craftspeople” but “artists” (Covach, 2006, p. -

Backforty Bunkhouse Newsletter Backforty Bunkhouse Newsletter
Backforty Bunkhouse Newsletter Distributed by BACKFORTY BUNKHOUSE PRODUCTIONS Home of the Backforty Roundup & CD Chorale 106 Roswell St Ruidoso, NM 88345 (575) 808-4111 Backforty Bunkhouse Publishing BMI Venue / Show Productions Western Music Radio Marketing www.BackfortyBunkhouse.com [email protected] www.MySpace.com/BackfortyBunkhouse Joe Baker - Publisher March, 2009 The Backforty Bunkhouse Newsletter is sent to over 600 email subscribers periodically and is growing every day. These are DJs, artists, and fans whose interests are Western Swing, Cowboy Poetry, Cowboy Heritage and Texas Honky Tonk music genres. We solicit your comments, suggestions and ways we may better serve you. If you do not want to receive this newsletter and want to be removed from our mailing list, reply to this email by entering “UNSUBSCRIBE” in the subject box of the email. Published By Joe Baker Joe Baker's KNMB Top Western Swing Albums Cowtown Society of Western Music Heroes • Brady Bowen, In My Spare Time Vol.#5 Academy of Western Artists Disc Jockey of the Year. • Cowtown Society of Western Music Disc Jockey of the Year Billy Mata, This Is Tommy Duncan, Vol.#1 Western Swing Music Society of the Southwest Hall of Fame • Rebecca Linda Smith, American Heroes Membership Director—Cowtown Society of Western Music • Johnny Lyon, Wynn Stewart Favorites Vol.#1 Board of Directors—Cowtown Society of Western Music • Bobby Flores, Eleven Roses Seattle Western Swing Music Society POWS Hall of Fame • Hank Stone, San Antone Editor: Howard Higgins • Jody Nix, The -

Hot Country Songs 1944 2012.Pdf
CONTENTS About The Author ................................................................................................................................................... 5 Synopsis Of Billboard’s Country Singles Charts 1944-2012 .................................................................................. 6 Researching Billboard’s Country Singles Charts.................................................................................................... 7 User’s Guide........................................................................................................................................................... 8 Top Country Songs & Artist Awards..................................................................................................................... 11 ARTIST SECTION ........................................................................................................................................13 An alphabetical listing, by artist, of every song to chart on Billboard’s Country singles charts from January 8, 1944 through December 29, 2012. SONG TITLE SECTION............................................................................................................................389 An alphabetical listing, by song title, of every song to chart on Billboard’s Country singles charts from January 8, 1944 through December 29, 2012. TOP ARTISTS ..............................................................................................................................................473 Kings & Queens Of