Introduction.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hannes Kolehmainen in the United States, 1912– 1921 By: Adam Berg, Mark Dyreson Berg, A
The Flying Finn's American Sojourn: Hannes Kolehmainen in the United States, 1912– 1921 By: Adam Berg, Mark Dyreson Berg, A. & Dyreson, M. (2012). The Flying Finn’s American Sojourn: Hannes Kolehmainen in the United States, 1912-1921. International Journal of the History of Sport, 29(7), 1035-1059. doi: 10.1080/09523367.2012.679025 This is an Accepted Manuscript of an article published by Taylor & Francis in International Journal of the History of Sport on 15 May 2012, available online: http://www.tandfonline.com/10.1080/09523367.2012.679025 Made available courtesy of Taylor & Francis: http://dx.doi.org/10.1080/09523367.2012.679025 ***© Taylor & Francis. Reprinted with permission. No further reproduction is authorized without written permission from Taylor & Francis. This version of the document is not the version of record. Figures and/or pictures may be missing from this format of the document. *** Abstract: Shortly after he won three gold medals and one silver medal in distance running events at the 1912 Stockholm Olympics, Finland's Hannes Kolehmainen immigrated to the United States. He spent nearly a decade living in Brooklyn, plying his trade as a mason and dominating the amateur endurance running circuit in his adopted homeland. He became a naturalised US citizen in 1921 but returned to Finland shortly thereafter. During his American sojourn, the US press depicted him simultaneously as an exotic foreign athlete and as an immigrant shaped by his new environment into a symbol of successful assimilation. Kolehmainen's career raised questions about sport and national identity – both Finnish and American – about the complexities of immigration during the floodtide of European migration to the US, and about native and adopted cultures in shaping the habits of success. -

MARATHON (WO)MAN… Made in Athènes… Since 1896 !
NEWSLETTER N°13 JUILLET 2021 CÔTE DE JADE ATHLETIC CLUB Convivialité | Entraide | Performance L’édito d’été d’un triathlète impliqué, Samuel Brégeot "Depuis quelques semaines, on se réjouit de voir que le sport en compétition redémarre. Tout le monde connaît le triathlon avec le traditionnel enchaînement Natation / Vélo de route / Course à pied (CAP). Mais la section est tout d'abord définie comme un sport de disciplines enchaînées. On pratique de multiples épreuves combinées : - le Cross triathlon (on remplace le vélo de route par un VTT et la CAP se déroule toujours en mode trail, pour ceux qui préfèrent la nature au bitume)... - l'Aquathlon (natation / CAP) pour ceux qui n'aiment pas le vélo... - le Duathlon (CAP / vélo / CAP) pour ceux qui ne savent pas nager ... - le Vétathlon est la version nature de ce dernier avec du VTT à la place du vélo de route... - le Run&Bike par équipe de 2 pour ceux qui adorent sauter sur leur vélo et piquer des sprints... - le SwimRun en binôme où tu nages avec tes chaussures et tu cours avec ta combi, - des épreuves en équipe (triathlon, duathlon) ou en relais (chacun fait son sport de prédilection)... - le Swim&Bike, euh non ce sport n'existe pas (pas encore ) !!! Bien-sûr toutes ces épreuves sont proposées avec toute une palette de distances. Du triathlon XS (300m de nat' + 10km de vélo + 2,5km de Cap) jusqu'au XL, plus connu sous le nom d'Ironman (3,8km de nat' + 180km de vélo + 42km de CAP). Les pratiques sont très variées et c'est ce qui fait le charme de ce sport. -

Gold, Silver and Green: Theirish Olympic Journey 1896 to 1924 by Kevin Mccarthy Was Published by Cork University Press Last Week
TERAPROOF:User:kevinsmithDate:03/02/2010Time:08:34:13Edition:03/02/2010Wedwedecho030210Page:65 Zone:EE EE - V2 (YHQLQJ (FKR Wednesday, February 3, 2010 SPORT 65 SUCH is the popularity of hurling, football, soccer and rugby that the majority of people, when asked to asso- ciate another word with the word‘sport’, will inevitably respond with one of the fol- lowing; hurling, football, soccer or rugby. This is not surprising because we arefed aconstant diet of these four games by the various elements of the sports media. The improving sports book industry is also dominated by publications devoted to the big four. Other than Kieran Shannon’s recent Hanging from the Rafters,there are very few sports books that examine the social dimension behind the facts of sport. TheAmericans have led the way in true sports history. These writers not only produce the facts of their topic but explain them in the context of their time. A new book, Gold, Silver and Green: TheIrish Olympic Journey 1896 to 1924 by Kevin McCarthy was published by Cork University Press last week. It is a book thatcan sit comfortably on the history as well as the sports bookshelf. This book ex- amines the stories and circumstance of over 75 Olympic medals which werewon by Irish-bornathletes in the Olympics prior to 1924. The num- ber is even greater when you in- clude those of Irish parents who were born abroad. Billy Sherring, a second generation Irish runner, winning the Marathon for Canada in the 1906 (10th Anniversary) Olympic Games in Athens. Note the Irish The author,Kevin McCarthy is a shamrock on his vest and Prince George of Greece jogging along side. -

Hamilton Athlete Biography: William D. Sherring Leesha Deweerd and Krista Hoftyzer PED 201 Professor John Byl Redeemer Universit
Hamilton Athlete Biography: William D. Sherring Leesha deWeerd and Krista Hoftyzer PED 201 Professor John Byl Redeemer University College Friday April 9, 2010 As a diverse and cultured country, Canada has produced many phenomenal and successful athletes in the past and present. Athletics is not a new concept to Canadians, as citizens have been participating since its beginnings. Hamilton has long since been a hot spot for producing elite athletes. Among these athletes is William (Billy) Sherring, an Olympic marathon runner. Throughout his lifetime in the 1900’s, Billy participated in many events including the Olympics, the Boston marathon, and Hamilton’s renowned Around-the-Bay road race. Born September 18, 1877 in Hamilton, Ontario, William (Billy) D. Sherring’s roots are tightly linked with the Hamilton area. 1 Billy began his running career at a young age with the Y.M.C.A. Boy’s Club. With a small body frame and weighing only 98 pounds, Sherring quickly shone in his sport. He started competing in his early teen years at various county fairs. At the age of twenty, Sherring achieved his first major success. In a great athletic display, Billy defeated his opponents in a race at Bartonville in 1897. 2 Bartonville was only the beginning of Sherring’s many eminent successes. Two years later, at the age of 21, Billy Sherring won his first of two Around-the-Bay marathons. This marathon began on Christmas Day in 1984 and is the oldest road race in North America. 3 Sherring was not without competition in this marathon. One of his constant and closest competitors was Jack Caffery. -

2004 USA Olympic Team Trials: Men's Marathon Media Guide Supplement
2004 U.S. Olympic Team Trials - Men’s Marathon Guide Supplement This publication is intended to be used with “On the Roads” special edition for the U.S. Olympic Team Trials - Men’s Marathon Guide ‘04 Male Qualifier Updates in 2004: Stats for the 2004 Male Qualifiers as of OCCUPATION # January 20, 2004 (98 respondents) Athlete 31 All data is for ‘04 Entrants Except as Noted Teacher/Professor 16 Sales 13 AVERAGE AGE Coach 10 30.3 years for qualifiers, 30.2 for entrants Student 5 (was 27.5 in ‘84, 31.9 in ‘00) Manager 3 Packaging Engineer 1 Business Owner 2 Pediatrician 1 AVERAGE HEIGHT Development Manager 2 Physical Therapist 1 5’'-8.5” Graphics Designer 2 Planner 1 Teacher Aide 2 AVERAGE WEIGHT Researcher 1 U.S. Army 2 140 lbs. Systems Analyst 1 Writer 2 Systems Engineer 1 in 2004: Bartender 1 Technical Analyst 1 SINGLE (60) 61% Cardio Technician 1 Technical Specialist 1 MARRIED (38) 39% Communications Specialist 1 U.S. Navy Officer 1 Out of 98 Consultant 1 Webmaster 1 Customer Service Rep 1 in 2000: Engineer 1 in 2000: SINGLE (58) 51% FedEx Pilot 1 OCCUPATION # MARRIED (55) 49% Film 1 Teacher/Professor 16 Out of 113 Gardener 1 Athlete 14 GIS Tech 1 Coach 11 TOP STATES (MEN ONLY) Guidance Counselor 1 Student 8 (see “On the Roads” for complete list) Horse Groomer 1 Sales 4 1. California 15 International Ship Broker 1 Accountant 4 2. Michigan 12 Mechanical Engineer 1 3. Colorado 10 4. Oregon 6 Virginia 6 Contents: U.S. -

LE STATISTICHE DELLA MARATONA 1. Migliori Prestazioni Mondiali Maschili Sulla Maratona Tabella 1 2. Migliori Prestazioni Mondial
LE STATISTICHE DELLA MARATONA 1. Migliori prestazioni mondiali maschili sulla maratona TEMPO ATLETA NAZIONALITÀ LUOGO DATA 1) 2h03’38” Patrick Makau Musyoki KEN Berlino 25.09.2011 2) 2h03’42” Wilson Kipsang Kiprotich KEN Francoforte 30.10.2011 3) 2h03’59” Haile Gebrselassie ETH Berlino 28.09.2008 4) 2h04’15” Geoffrey Mutai KEN Berlino 30.09.2012 5) 2h04’16” Dennis Kimetto KEN Berlino 30.09.2012 6) 2h04’23” Ayele Abshero ETH Dubai 27.01.2012 7) 2h04’27” Duncan Kibet KEN Rotterdam 05.04.2009 7) 2h04’27” James Kwambai KEN Rotterdam 05.04.2009 8) 2h04’40” Emmanuel Mutai KEN Londra 17.04.2011 9) 2h04’44” Wilson Kipsang KEN Londra 22.04.2012 10) 2h04’48” Yemane Adhane ETH Rotterdam 15.04.2012 Tabella 1 2. Migliori prestazioni mondiali femminili sulla maratona TEMPO ATLETA NAZIONALITÀ LUOGO DATA 1) 2h15’25” Paula Radcliffe GBR Londra 13.04.2003 2) 2h18’20” Liliya Shobukhova RUS Chicago 09.10.2011 3) 2h18’37” Mary Keitany KEN Londra 22.04.2012 4) 2h18’47” Catherine Ndereba KEN Chicago 07.10.2001 1) 2h18’58” Tiki Gelana ETH Rotterdam 15.04.2012 6) 2h19’12” Mizuki Noguchi JAP Berlino 15.09.2005 7) 2h19’19” Irina Mikitenko GER Berlino 28.09.2008 8) 2h19’36’’ Deena Kastor USA Londra 23.04.2006 9) 2h19’39’’ Sun Yingjie CHN Pechino 19.10.2003 10) 2h19’50” Edna Kiplagat KEN Londra 22.04.2012 Tabella 2 3. Evoluzione della migliore prestazione mondiale maschile sulla maratona TEMPO ATLETA NAZIONALITÀ LUOGO DATA 2h55’18”4 Johnny Hayes USA Londra 24.07.1908 2h52’45”4 Robert Fowler USA Yonkers 01.01.1909 2h46’52”6 James Clark USA New York 12.02.1909 2h46’04”6 -

The Marathon
46 Friday Sports Friday, October 11, 2019 Kipchoge compares sub two-hour marathon to going to the moon VIENNA: Kenya’s world record holder Eliud The sport’s governing body, the Interna- Kipchoge has compared running a sub two- tional Association of Athletics Federations hour marathon to going to the moon before (IAAF), will not recognise the run as an of- his unofficial attempt in Vienna tomorrow to ficial record because it is not in open com- become the first athlete to break the barrier. petition and it uses in and out pacemakers. “I am running to make history, to show In Monza, Kipchoge also received drinks that no human is limited. It’s not about from a moving motorbike rather than having money, it’s about showing a generation of to collect them from a table. But IAAF pres- people that there are no limits,” Kipchoge, ident Sebastian Coe told Reuters in an inter- who will make his second attempt to break view last month the milestone would still be the two-hour mark, told reporters. important. The 34-year-old Olympic champion set “If there’s an exciting attempt for getting the world record of 2:01.39 at the Berlin under two hours for the marathon I’m not marathon last September, smashing the pre- sure that most people are going to be sitting vious one by 78 seconds, but said Saturday’s there going, ‘Well, it wasn’t sanctioned as a race is a completely different challenge. world record because it wasn’t in open com- “Running Berlin and running Vienna are petition,’, said Coe. -
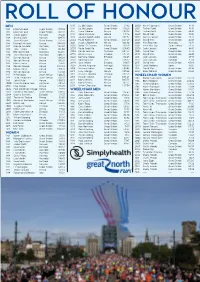
Roll of Honour
ROLL OF HONOUR MEN 1995 Liz McColgan Great Britain 1:11:42 2000 Kevin Papworth Great Britain 49:18 1981 Mike McLeod Great Britain 1:03:23 1996 Liz McColgan Great Britain 1:10:28 2001 Tushar Patel Great Britain 48:10 1982 Mike McLeod Great Britain 1:02:44 1997 Lucia Subano Kenya 1:09:24 2002 Tushar Patel Great Britain 48:46 1983 Carlos Lopes Portugal 1:02:46 1998 Sonia O'Sullivan Ireland 1:11:50 2003 David Weir Great Britain 45:41 1984 Øyvind Dahl Norway 1:04:36 1999 Joyce Chepchumba Kenya 1:09:07 2004 Kenny Herriot Great Britain 45:37 1985 Steve Kenyon Great Britain 1:02:44 2000 Paula Radcliffe Great Britain 1:07:07 2005 David Weir Great Britain 42:33 1986 Michael Musyoki Kenya 1:00:43 2001 Susan Chepkemei Kenya 1:08:40 2006 Kurt Fearnley Australia 42:39 1987 Rob de Castella Australia 1:02:04 2002 Sonia O' Sullivan Ireland 1:07:19 2007 Ernst Van Dyk South Africa 42:35 1988 John Treacy Ireland 1:01:00 2003 Paula Radcliffe Great Britain 1:05:40 2008 Josh Cassidy Canada 44:10 1989 EM Nechchadi Morocco 1:02:39 2004 Benita Johnson Australia 1:07:55 2009 David Weir Great Britain 41:34 1990 Steve Moneghetti Australia 1:00:34 2005 Derartu Tulu Ethiopia 1:07:33 2010 David Weir Great Britain 44:49 1991 Benson Masya Kenya 1:00:28 2006 Berhane Adere Ethiopia 1:10:03 2011 Josh Cassidy Canada 43:57 1992 Benson Masya Kenya 1:00:24 2007 Kara Goucher USA 1:06:57 2012 Josh Cassidy Canada 43:18 1993 Moses Tanui Kenya 59:47 2008 Gete Wami Ethiopia 1:08:51 2013 David Weir Great Britain 43:06 1994 Benson Masya Kenya 1:00:02 2009 Jéssica Augusto Portugal 1:09:08 -

Wikireader Digest (2004, Woche 51) -- Seite 1 AARAU
WIKIREADER DIGEST EINE ARTIKELSAMMLUNG AUS WIKIPEDIA, DER FREIEN ENZYKLOPÄDIE Stand vom 12. Dezember 2004 um 23:05 CEST WOCHE 2004-51 Diese Woche: ● Aarau ● Angriff auf Pearl Habor ● Bleistift ● Günter Rinnhofer ● Hannes Kolehmainen ● PISA-Studie ● Schweizerdeutsch ● Sealand ● Willy Brandt W I K I M E D I A F O U N D A T I O N IMPRESSUM Verfasser: Die freiwilligen Schreiber der deutschsprachigen Wikipedia Herausgeber dieser Ausgabe: Robert Grän Besonders fleißige Wikipedianer: Necrophorus, Steschke, Wikinator, Southpark, Quo Stand der Ausgabe 2004-51: 12. Dezember 2004 um 23:05 CEST Verwendete Schriften: FreeSerif und FreeMono ISSN (Onlineausgabe): 1613-7752 URL der Wikipedia: http://de.wikipedia.org URL dieses Hefts: http://de.wikipedia.org/wiki/Wikipedia:WikiReader_Digest ÜBER WIKIPEDIA Die Wikipedia ist eine freie Enzyklopädie, die es sich zur Aufgabe gemacht hat, jedem eine freie Wissensquelle zu bieten, an der er nicht nur passiv durch lesen teilhaben kann, sondern WikiReader Internet auch aktiv als Autor mitwirken kann. Auf der Webseite http://de.wikipedia.org findet man Kaufen: http://shop.wikipedia.org nicht nur die aktuellen Artikel der deutschsprachigen Wikipedia, sondern darf auch sofort und ohne eine Anmeldung mitschreiben. Auf diese Art sind seit 2001 eine Million Artikel zustande gekommen, in mehr als 110 Sprachen. Inzwischen ist die Wikipedia seit 2003 Teil der Wikimedia Foundation, die für die technischen Voraussetzungen der Wikipedia zuständig ist und auch andere Projekte wie das Wörterbuch Wiktionary oder das Lehrbuch-Projekt WikiBooks beherbergt. ÜBER DIE REIHE "WIKIREADER DIGEST" "WikiReader Digest" ist ein Teilprojekt des WikiReaders und hat im Gegensatz zu den üblichen WikiReadern kein bestimmtes Thema vorausgesetzt, sondern enthält immer nur eine kleine Auswahl an Artikeln. -

NASSS 2016 Preliminary Program All Sessions October 2
1 La Sociedad Norteamericana para la Sociología del Deporte Société Nord-Americaine de Sociologie du Sport North American Society for the Sociology of Sport 2016 Annual Meeting Publicly Engaged Sociology of Sport Tampa Downtown Hilton, Tampa Bay, Florida, USA November 2 -5, 2016 2 Publicly Engaged Sociology of Sport Inspired by reCent momentous Cultural events, the ConFerenCe theme questions and Considers the role oF sport soCiology and sport soCiologists in publiC engagement. In the Context of growing economic inequality, we see publiC money being siphoned into private stadiums within proFessional sport, Corruption within international sporting organizations, and U.S. College Coaches being the highest paid employees in state institutions within ‘amateur’ sport. In a time oF Continued and deadly racial violenCe, sport remains segregated and stratiFied in terms oF sports, positions, and partiCularly in terms oF positions oF power. Even as girls and women demonstrate unFlagging interest in sport in all levels and types, they are still reCognized primarily For how they look rather than For what they Can acComplish. We have witnessed marriage equality For all people in the United States and many places around the world, regardless oF sexuality, yet ‘out’ gay male athletes remain rare in the highest levels oF sport. We watch teChnology transForm the athletiC possibilities oF those with a variety oF physiCal impairments, at the same time that acCess to sport partiCipation remains a barrier. Importantly, as we know, none oF these brieF examples work in isolation oF the others. The Clear, and also submerged, interseCtions oFFer Fruitful examinations in muCh oF the work that we do within our Field. -

A Brief History of the World Cross Country Championships
A Brief History of the World Cross Country Championships The first 70 years The World Cross Country Championships, often considered the toughest footraces on the planet, may be more difficult to win than the Olympics or the World Championships in Athletics. The predecessor of the World Cross Country Championships was the International Cross Country Championships, inaugurated in 1903. With only four countries (England, Wales, Scotland and Ireland) initially participating, these championships could hardly be considered “international” during their early years. However, by 1972, when 197 runners from 15 countries competed, the championships had gained international stature. Three great runners — Jack Holden (GBR), the 1950 European marathon champion; Alain Mimoun (FRA), the 1956 Olympic marathon champion; and Gaston Roelants (BEL), the 1964 Olympic 3000mSC champion — won four individual titles during the days of International Cross Country Championships. In the women’s event, Doris Brown won five straight championships from 1967 to 1971. Many Olympic medalists won the International Cross Country Championships. Jean Bouin (FRA), who won the silver medal at 5000m in the 1912 Olympics, won three championships from 1911, while Mohammed Gommoudi (TUN), who won the 5000m in the 1968 Olympics, also won the International Cross Country Championships in the same year. Franjo Mihalic (YUG), Rhadi ben Abdesselem (MAR), and Basil Heatley (GBR), all Olympic marathon silver medalist, won the International Cross Country Championships. However, because participation was generally limited to runners from nations that were members of the International Cross Country Union (ICCU), the championships were not truly “world” in scope. In fact, Emil Zatopek (CZE), 1952 Helsinki triple gold medalist, and Vladimir Kuts (URS), 1956 Melbourne double Olympic champion, never competed at the International Cross Country Championships. -

The Marathon Makers
Rich’s Book Review The Marathon Makers The year 2008 marked the centennial of one of the most famous of all marathons: the 1908 London Olympic marathon, which became famous for establishing the official length of the marathon at 26 miles, 385 yards, and for creating one of the most famous of all finish-line photos, that of Dorando Pietri staggering over the finish line after having fallen to the track several times and then being assisted to his feet by officials. The struggling Pietri would, of course, be disqualified when the American team protested his assisted “victory,” and Johnny Hayes of the U.S. would be declared the winner, the last time an American would win the Olympic marathon until Frank Shorter came along in Munich in 1972 to claim the title. The 100th anniversary of that notable event was marked by the publication of John Bryant’s The Marathon Makers (John Blake Publishing, London, 331 pages, $26.95, available in the U.S. through Trafalgar Square Publishing). The book follows the lives of the doughty Italian Dorando Pietri, the Irish-American stalwart Johnny Hayes, and Scottish sprinter Wyndham Halswelle. What does a sprinter have to do with two eccentric marathoners battling it out for the gold in London in 1908? Halswelle is symbolic of the British ideal of fair play in both sport and war that was endemic at the start of the 20th century and that was knocked all to hell with the coming of World War I, where Halswelle lost his life to a German sniper.