Efficient Implementation of Data Objects in the OSD+-Based Fusion
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Globalfs: a Strongly Consistent Multi-Site File System
GlobalFS: A Strongly Consistent Multi-Site File System Leandro Pacheco Raluca Halalai Valerio Schiavoni University of Lugano University of Neuchatelˆ University of Neuchatelˆ Fernando Pedone Etienne Riviere` Pascal Felber University of Lugano University of Neuchatelˆ University of Neuchatelˆ Abstract consistency, availability, and tolerance to partitions. Our goal is to ensure strongly consistent file system operations This paper introduces GlobalFS, a POSIX-compliant despite node failures, at the price of possibly reduced geographically distributed file system. GlobalFS builds availability in the event of a network partition. Weak on two fundamental building blocks, an atomic multicast consistency is suitable for domain-specific applications group communication abstraction and multiple instances of where programmers can anticipate and provide resolution a single-site data store. We define four execution modes and methods for conflicts, or work with last-writer-wins show how all file system operations can be implemented resolution methods. Our rationale is that for general-purpose with these modes while ensuring strong consistency and services such as a file system, strong consistency is more tolerating failures. We describe the GlobalFS prototype in appropriate as it is both more intuitive for the users and detail and report on an extensive performance assessment. does not require human intervention in case of conflicts. We have deployed GlobalFS across all EC2 regions and Strong consistency requires ordering commands across show that the system scales geographically, providing replicas, which needs coordination among nodes at performance comparable to other state-of-the-art distributed geographically distributed sites (i.e., regions). Designing file systems for local commands and allowing for strongly strongly consistent distributed systems that provide good consistent operations over the whole system. -

Storage Systems and Input/Output 2018 Pre-Workshop Document
Storage Systems and Input/Output 2018 Pre-Workshop Document Gaithersburg, Maryland September 19-20, 2018 Meeting Organizers Robert Ross (ANL) (lead organizer) Glenn Lockwood (LBL) Lee Ward (SNL) (co-lead) Kathryn Mohror (LLNL) Gary Grider (LANL) Bradley Settlemyer (LANL) Scott Klasky (ORNL) Pre-Workshop Document Contributors Philip Carns (ANL) Quincey Koziol (LBL) Matthew Wolf (ORNL) 1 Table of Contents 1 Table of Contents 2 2 Executive Summary 4 3 Introduction 5 4 Mission Drivers 7 4.1 Overview 7 4.2 Workload Characteristics 9 4.2.1 Common observations 9 4.2.2 An example: Adjoint-based sensitivity analysis 10 4.3 Input/Output Characteristics 11 4.4 Implications of In Situ Analysis on the SSIO Community 14 4.5 Data Organization and Archiving 15 4.6 Metadata and Provenance 18 4.7 Summary 20 5 Computer Science Challenges 21 5.1 Hardware/Software Architectures 21 5.1.1 Storage Media and Interfaces 21 5.1.2 Networks 21 5.1.3 Active Storage 22 5.1.4 Resilience 23 5.1.5 Understandability 24 5.1.6 Autonomics 25 5.1.7 Security 26 5.1.8 New Paradigms 27 5.2 Metadata, Name Spaces, and Provenance 28 5.2.1 Metadata 28 5.2.2 Namespaces 30 5.2.3 Provenance 30 5.3 Supporting Science Workflows - SAK 32 5.3.1 DOE Extreme Scale Use cases - SAK 33 5.3.2 Programming Model Integration - (Workflow Composition for on line workflows, and for offline workflows ) - MW 33 5.3.3 Workflows (Engine) - Provision and Placement MW 34 5.3.4 I/O Middleware and Libraries (Connectivity) - both on-and offline, (not or) 35 2 Storage Systems and Input/Output 2018 Pre-Workshop -

HFAA: a Generic Socket API for Hadoop File Systems
HFAA: A Generic Socket API for Hadoop File Systems Adam Yee Jeffrey Shafer University of the Pacific University of the Pacific Stockton, CA Stockton, CA [email protected] jshafer@pacific.edu ABSTRACT vices: one central NameNode and many DataNodes. The Hadoop is an open-source implementation of the MapReduce NameNode is responsible for maintaining the HDFS direc- programming model for distributed computing. Hadoop na- tory tree. Clients contact the NameNode in order to perform tively integrates with the Hadoop Distributed File System common file system operations, such as open, close, rename, (HDFS), a user-level file system. In this paper, we intro- and delete. The NameNode does not store HDFS data itself, duce the Hadoop Filesystem Agnostic API (HFAA) to allow but rather maintains a mapping between HDFS file name, Hadoop to integrate with any distributed file system over a list of blocks in the file, and the DataNode(s) on which TCP sockets. With this API, HDFS can be replaced by dis- those blocks are stored. tributed file systems such as PVFS, Ceph, Lustre, or others, thereby allowing direct comparisons in terms of performance Although HDFS stores file data in a distributed fashion, and scalability. Unlike previous attempts at augmenting file metadata is stored in the centralized NameNode service. Hadoop with new file systems, the socket API presented here While sufficient for small-scale clusters, this design prevents eliminates the need to customize Hadoop’s Java implementa- Hadoop from scaling beyond the resources of a single Name- tion, and instead moves the implementation responsibilities Node. Prior analysis of CPU and memory requirements for to the file system itself. -

Maximizing the Performance of Scientific Data Transfer By
Maximizing the Performance of Scientific Data Transfer by Optimizing the Interface Between Parallel File Systems and Advanced Research Networks Nicholas Millsa,∗, F. Alex Feltusb, Walter B. Ligon IIIa aHolcombe Department of Electrical and Computer Engineering, Clemson University, Clemson, SC bDepartment of Genetics and Biochemistry, Clemson University, Clemson, SC Abstract The large amount of time spent transferring experimental data in fields such as genomics is hampering the ability of scientists to generate new knowledge. Often, computer hardware is capable of faster transfers but sub-optimal transfer software and configurations are limiting performance. This work seeks to serve as a guide to identifying the optimal configuration for performing genomics data transfers. A wide variety of tests narrow in on the optimal data transfer parameters for parallel data streaming across Internet2 and between two CloudLab clusters loading real genomics data onto a parallel file system. The best throughput was found to occur with a configuration using GridFTP with at least 5 parallel TCP streams with a 16 MiB TCP socket buffer size to transfer to/from 4{8 BeeGFS parallel file system nodes connected by InfiniBand. Keywords: Software Defined Networking, High Throughput Computing, DNA sequence, Parallel Data Transfer, Parallel File System, Data Intensive Science 1. Introduction of over 2,500 human genomes from 26 populations have been determined (The 1000 Genomes Project [3]); genome Solving scientific problems on a high-performance com- sequences have been produced for 3,000 rice varieties from puting (HPC) cluster will happen faster by taking full ad- 89 countries (The 3000 Rice Genomes Project [4]). These vantage of specialized infrastructure such as parallel file raw datasets are but a few examples that aggregate into systems and advanced software-defined networks. -

Locofs: a Loosely-Coupled Metadata Service for Distributed File Systems
LocoFS: A Loosely-Coupled Metadata Service for Distributed File Systems Siyang Li∗ Youyou Lu Jiwu Shu† Tsinghua University Tsinghua University Tsinghua University [email protected] [email protected] [email protected] Tao Li Yang Hu University of Florida University of Texas, Dallas [email protected] [email protected] ABSTRACT 1 INTRODUCTION Key-Value stores provide scalable metadata service for distributed As clusters or data centers are moving from Petabyte level to Ex- file systems. However, the metadata’s organization itself, which is abyte level, distributed file systems are facing challenges in meta- organized using a directory tree structure, does not fit the key-value data scalability. The recent work IndexFS [38] uses hundreds of access pattern, thereby limiting the performance. To address this metadata servers to achieve high-performance metadata operations. issue, we propose a distributed file system with a loosely-coupled However, most of the recent active super computers only deploy metadata service, LocoFS, to bridge the performance gap between 1 to 4 metadata servers to reduce the complexity of management file system metadata and key-value stores. LocoFS is designed to and guarantee reliability. Besides, previous work [24, 39] has also decouple the dependencies between different kinds of metadata revealed that metadata operations consume more than half of all with two techniques. First, LocoFS decouples the directory content operations in file systems. The metadata service plays a major role and structure, which organizes file and directory index nodes ina in distributed file systems. It is important to support parallel pro- flat space while reversely indexing the directory entries. -

A Persistent Storage Model for Extreme Computing Shuangyang Yang Louisiana State University and Agricultural and Mechanical College
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 2014 A Persistent Storage Model for Extreme Computing Shuangyang Yang Louisiana State University and Agricultural and Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Part of the Computer Sciences Commons Recommended Citation Yang, Shuangyang, "A Persistent Storage Model for Extreme Computing" (2014). LSU Doctoral Dissertations. 2910. https://digitalcommons.lsu.edu/gradschool_dissertations/2910 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. A PERSISTENT STORAGE MODEL FOR EXTREME COMPUTING A Dissertation Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Department of Computer Science by Shuangyang Yang B.S., Zhejiang University, 2006 M.S., University of Dayton, 2008 December 2014 Copyright © 2014 Shuangyang Yang All rights reserved ii Dedicated to my wife Miao Yu and our daughter Emily. iii Acknowledgments This dissertation would not be possible without several contributions. It is a great pleasure to thank Dr. Hartmut Kaiser @ Louisiana State University, Dr. Walter B. Ligon III @ Clemson University and Dr. Maciej Brodowicz @ Indiana University for their ongoing help and support. It is a pleasure also to thank Dr. Bijaya B. Karki, Dr. Konstantin Busch, Dr. Supratik Mukhopadhyay at Louisiana State University for being my committee members and Dr. -

The Ceph Distributed Storage System
the ceph distributed storage system sage weil msst – april 17, 2012 outline ● why you should care ● what is it, what it does ● how it works, how you can use it ● architecture ● objects and data placement ● file system ● big data, cloud ● current status, roadmap ● who we are, why we do this why should you care about another storage system? requirements, time, money storage requirements ● scale ● terabytes, petabytes, exabytes ● heterogeneous hardware ● reliability and fault tolerance ● diverse storage needs ● object storage ● block devices ● shared file system (POSIX, coherent caches) ● structured data time ● ease of administration ● no manual data migration, load balancing ● painless scaling ● expansion and contraction ● seamless migration money ● low cost per gigabyte ● no vendor lock-in ● software solution ● commodity hardware ● open source what is ceph? unified storage system ● objects ● small or large ● multi-protocol Netflix VM Hadoop ● block devices radosgw RBD Ceph DFS ● snapshots, cloning RADOS ● files ● cache coherent ● snapshots ● usage accounting open source ● LGPLv2 ● copyleft ● free to link to proprietary code ● no copyright assignment ● no dual licensing ● no “enterprise-only” feature set ● active community ● commercial support distributed storage system ● data center (not geo) scale ● 10s to 10,000s of machines ● terabytes to exabytes ● fault tolerant ● no SPoF ● commodity hardware – ethernet, SATA/SAS, HDD/SSD – RAID, SAN probably a waste of time, power, and money architecture ● monitors (ceph-mon) ● 1s-10s, paxos ● lightweight -
![Introduction to Distributed File Systems. Orangefs Experience 0.05 [Width=0.4]Lvee-Logo-Winter](https://docslib.b-cdn.net/cover/5496/introduction-to-distributed-file-systems-orangefs-experience-0-05-width-0-4-lvee-logo-winter-1425496.webp)
Introduction to Distributed File Systems. Orangefs Experience 0.05 [Width=0.4]Lvee-Logo-Winter
Introduction to distributed file systems. OrangeFS experience Andrew Savchenko NRNU MEPhI, Moscow, Russia 16 February 2013 . .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. Outline 1. Introduction 2. Species of distributed file systems 3. Behind the curtain 4. OrangeFS 5. Summary . .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. Introduction Why one needs a non-local file system? • a large data storage • a high performance data storage • redundant and highly available solutions There are dozens of them: 72 only on wiki[1], more IRL. Focus on free software solutions. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. Introduction Why one needs a non-local file system? • a large data storage • a high performance data storage • redundant and highly available solutions There are dozens of them: 72 only on wiki[1], more IRL. Focus on free software solutions. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. Species of distributed file systems Network Clustered Distributed Terminology is ambiguous!. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. Network file systems client1 client2 clientN server storage A single server (or at least an appearance) and multiple network clients. Examples: NFS, CIFS. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. Clustered file systems server1 server2 serverN storage Servers sharing the same local storage (usually SAN[2] at block level). shared storage architecture. Examples: GFS2[3], OCFS2[4]. .. .. .. .. . -

Týrfs: Increasing Small Files Access Performance with Dynamic Metadata Replication Pierre Matri, María Pérez, Alexandru Costan, Gabriel Antoniu
TýrFS: Increasing Small Files Access Performance with Dynamic Metadata Replication Pierre Matri, María Pérez, Alexandru Costan, Gabriel Antoniu To cite this version: Pierre Matri, María Pérez, Alexandru Costan, Gabriel Antoniu. TýrFS: Increasing Small Files Access Performance with Dynamic Metadata Replication. CCGRID 2018 - 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, May 2018, Washington, United States. pp.452- 461, 10.1109/CCGRID.2018.00072. hal-01892691 HAL Id: hal-01892691 https://hal.archives-ouvertes.fr/hal-01892691 Submitted on 10 Oct 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. TyrFS:´ Increasing Small Files Access Performance with Dynamic Metadata Replication Pierre Matri∗, Mar´ıa S. Perez´ ∗, Alexandru Costanyz, Gabriel Antoniuz ∗Universidad Politecnica´ de Madrid, Madrid, Spain, fpmatri, mperezg@fi.upm.es yIRISA / INSA Rennes, Rennes, France, [email protected] zInria, Rennes, France, falexandru.costan, [email protected] Abstract—Small files are known to pose major performance We advocate that a different file system architecture is challenges for file systems. Yet, such workloads are increasingly necessary to reduce the cost of metadata management for common in a number of Big Data Analytics workflows or large- such workloads involving many small files. -
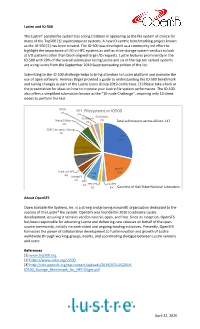
Filesystems in IO500 3% Gridscaler Datawarp 2% Wekaio Matrix 2% Total Submissions Across All Lists: 147 5% SUSE Enterprise Storage 1% Lustre 29%
Lustre and IO-500 The Lustre® parallel file system has a long tradition in appearing as the file system of choice for many of the Top500 [1] supercomputer systems. A new IO-centric benchmarking project known as the IO-500 [2] has been created. The IO-500 was developed as a community led effort to highlight the importance of I/O in HPC systems as well as drive storage system vendors to look at I/O patterns other than block-aligned large I/O requests. Lustre features prominently in the IO-500 with 29% of the overall submission listing Lustre and six of the top ten ranked systems are using Lustre from the September 2019 Supercomputing edition of the list. Submitting to the IO-500 challenge helps to bring attention to Lustre platform and promote the use of open software. Andreas Dilger provided a guide to understanding the IO-500 benchmark and tuning changes as part of the Lustre Users Group 2019 conference. [3] Please take a look at the presentation for ideas on how to improve your Lustre file system performance. The IO-500 also offers a simplified submission known as the “10-node Challenge”, requiring only 10 client nodes to perform the test. DAOS GPFS 1% Filesystems in IO500 3% GRIDScaler DataWarp 2% WekaIO Matrix 2% Total submissions across all lists: 147 5% SUSE Enterprise Storage 1% Lustre 29% Spectrum Scale 12% Scale-out NAS 7% BeeGFS Scale out NFS IME 20% 4% OrangeFS 7% 1% NFS 1% HPE XFS CephFS 2% 3% Courtesy of Oak Ridge National Laboratory About OpenSFS Open Scalable File Systems, Inc. -

Metadata Management in Distributed File Systems
Metadata Management in Distributed File Systems University of Oulu Faculty of Information Technology and Electrical Engineering Bachelor’s Thesis Joni Laitala 6.9.2017 2 Abstract The purpose of this research has been to study the architectures of popular distributed file systems used in cloud computing, with a focus on their metadata management, in order to identify differences between and issues within varying designs from the metadata perspective. File system and metadata concepts are briefly introduced before the comparisons are made. Keywords big data, distributed file system, distributed storage system, metadata management Supervisor Dr., University Lecturer Ari Vesanen 3 Contents Abstract ............................................................................................................................. 2 Contents ............................................................................................................................ 3 1. Introduction .................................................................................................................. 4 2. File Systems ................................................................................................................. 5 2.1 Disk File Systems ........................................................................................ 5 2.2 Cloud Distributed File Systems ................................................................... 5 2.3 Metadata ..................................................................................................... -

Analytical Study on Performance, Challenges and Future Considerations of Google File System
International Journal of Computer and Communication Engineering, Vol. 3, No. 4, July 2014 Analytical Study on Performance, Challenges and Future Considerations of Google File System Zahid Ullah, Sohail Jabbar, Muhammad Haris bin Tariq Alvi, and Awais Ahmad users can set the attributes of the files via operating system Abstract—In this paper we present a brief analysis on the commands for those files and directories which are located working and design of Google file System with its performance on the remote systems. analysis. A brief Comparison of Google File system with other There is a long list of distributed file systems available in Distributed File Systems (DFS) namely HDFS, Global FS, the market. Some are open source, some are specially GPFS and sector is also presented. Although Google shares many similarities with other DFSs but still it is unique in its designed by some organization for fulfilling their specific design which is made specifically to serve Google’s heavy needs and some are available for the use by the common workload. GFS’s Architecture has a single master which is users while some are provided to the end users for running responsible for performing some major duties as explained in their developed applications. Following are various types of the Architecture session. Reliability of data is maintained Distributed File Systems (DFS) with respect to their offered through triple replication of data. So it also provides fast features and dimensionality of their performance. recovery and fault tolerance. Comparison and future consideration enables the reader to understand the current A. Distributed Fault-Tolerant File Systems situation of GFS and its place in the future world.