The Comparison of SQL, QBE, and DFQL As Query Languages for Relational Databases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Semantic Queries by Example
Semantic Queries by Example Lipyeow Lim Haixun Wang Min Wang University of Hawai‘i at Manoa¯ Microsoft Research Asia Google, Inc. [email protected] [email protected] [email protected] ABSTRACT 1. INTRODUCTION With the ever increasing quantities of electronic data, there A growing number of advanced applications such as prod- is a growing need to make sense out of the data. Many ad- uct information management (PIM) systems, customer re- vanced database applications are beginning to support this lationship management (CRM) systems, electronic medical need by integrating domain knowledge encoded as ontolo- records (EMRs) systems are recognizing the need to incor- gies into queries over relational data. However, it is ex- porate ontology into the realm of object relational databases tremely difficult to express queries against graph structured (ORDBMs) so that the user can query data and its related ontology in the relational SQL query language or its exten- ontology in a consistent manner [7, 14, 22]. However, it is sions. Moreover, semantic queries are usually not precise, extremely tedious and time consuming to understand ontol- especially when data and its related ontology are compli- ogy, and use ontology in database queries [15]. Such queries cated. Users often only have a vague notion of their infor- that leverage the semantic information stored in ontologies mation needs and are not able to specify queries precisely. to filter and retrieve data from relational tables are called In this paper, we address these challenges by introducing semantic queries. The success of the relational database a novel method to support semantic queries in relational technology is at least partly due to the spartan simplicity databases with ease. -

Ch06-The Relational Algebra and Calculus.Pdf
Copyright © 2007 Ramez Elmasri and Shamkant B. Navathe Slide 6- 1 Chapter 6 The Relational Algebra and Calculus Copyright © 2007 Ramez Elmasri and Shamkant B. Navathe Chapter Outline Relational Algebra Unary Relational Operations Relational Algebra Operations From Set Theory Binary Relational Operations Additional Relational Operations Examples of Queries in Relational Algebra Relational Calculus Tuple Relational Calculus Domain Relational Calculus Example Database Application (COMPANY) Overview of the QBE language (appendix D) Copyright © 2007 Ramez Elmasri and Shamkant B. Navathe Slide 6- 3 Relational Algebra Overview Relational algebra is the basic set of operations for the relational model These operations enable a user to specify basic retrieval requests (or queries) The result of an operation is a new relation, which may have been formed from one or more input relations This property makes the algebra “closed” (all objects in relational algebra are relations) Copyright © 2007 Ramez Elmasri and Shamkant B. Navathe Slide 6- 4 Relational Algebra Overview (continued) The algebra operations thus produce new relations These can be further manipulated using operations of the same algebra A sequence of relational algebra operations forms a relational algebra expression The result of a relational algebra expression is also a relation that represents the result of a database query (or retrieval request) Copyright © 2007 Ramez Elmasri and Shamkant B. Navathe Slide 6- 5 Brief History of Origins of Algebra Muhammad ibn Musa al-Khwarizmi (800-847 CE) wrote a book titled al-jabr about arithmetic of variables Book was translated into Latin. Its title (al-jabr) gave Algebra its name. Al-Khwarizmi called variables “shay” “Shay” is Arabic for “thing”. -

A Generalized Approach for Visual Query Formulation for Text
Query By Templates: A Generalized Approach for Visual Query Formulation for Text Dominated Databases y Arijit Sengupta Andrew Dillon Computer Science Department Scho ol of Library & Information Science Indiana University Indiana University Blo omington, IN 47405 Blo omington, IN 47405 [email protected] [email protected] structured do cuments not only for the traditional pur- Abstract p oses of reading, browsing, and printing, but also for The WWW has a great potential of evolving into searching and querying. Automated searches in nor- aglobal ly distributed digital document library.The pri- mal word-pro cessor do cuments are usually restricted mary use of such a library is to retrieve information to linear word searches. However, users can use do cu- quickly and easily. Because of the size of these li- ments enco ded in SGML to p ose much more complex braries, simple keyword searches often result in too searches involving b oth text content and structure. many matches. More complex searches involving boolean expressions are dicult to formulate and un- derstand. This paper describes QBT (Query By Tem- 1.1 SGML, Databases and Do cuments plates), a visual method for formulating queries for structured document databases modeled with SGML. Traditionally, do cuments in electronic formats like Based on Zloof 's QBE (Query By Example), this text or word-pro cessor do cuments are used mainly method incorporates the structure of the documents for word pro cessing, editing, publishing, and p ossible for composing powerful queries. The goal of this tech- reuse into other do cuments. The problem with these nique is to design an interface for querying struc- do cuments is that they can not b e easily used for pur- tured documents without prior know ledge of the in- p oses other than what they are primarily designed for. -
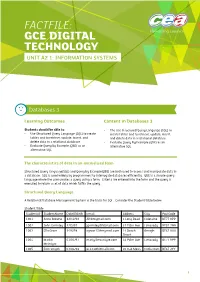
Factfile: Gce Digital Technology Unit A2 1: Information Systems
FACTFILE: GCE DIGITAL TECHNOLOGY UNIT A2 1: INFORMATION SYSTEMS Databases 3 Learning Outcomes Content in Databases 3 Students should be able to: • The Use Structured Query Language (SQL) to • Use Structured Query Language (SQL) to create create tables and to retrieve, update, insert, tables and to retrieve, update, insert, and and delete data in a relational database. delete data in a relational database. • Evaluate Query By Example (QBE) as an • Evaluate Query By Example (QBE) as an alternative SQL alternative SQL The characteristics of data in un-normalised form Structured Query language(SQL) and Query by Example(QBE) are both used to access and manipulate data in a database. SQL is used widely by programmers to interrogate databases efficiently. QBE is a simple query language where the user creates a query using a form. Criteria are entered into the form and the query is executed to return a set of data which fulfils the query. Structured Query Language A Relational Database Management System is the basis for SQL. Consider the Student table below. Student Table StudentID StudentName DateOfBirth Email Address City PostCode 1001 Anne Browne 12/12/98 [email protected] 1 Long Road Coleraine BT77 9PP 1002 John Gormley 12/5/97 [email protected] 37 Palm Ave Limavady BT02 7NN 1003 Ella Greer 14/6/98 [email protected] 14 Beech Omagh BT67 8UU Street 1004 Martin 01/01/97 [email protected] 34 Palm Ave Limavady BT77 9PP McIntyre 1005 Eoin Smyth 03/04/98 [email protected] 20 Oak Mews Cookstown BT67 2YY 1 FACTFILE: GCE DIGITAL TECHNOLOGY / DATABASE 3 The fields in the Student table are StudentID, StudentName, DateOfBirth, Email, Address, City, and PostCode. -

Migrating to Graphql: a Practical Assessment
Migrating to GraphQL: A Practical Assessment Gleison Brito, Thais Mombach, Marco Tulio Valente ASERG Group, Department of Computer Science, Federal University of Minas Gerais, Brazil fgleison.brito, thaismombach, [email protected] Abstract—GraphQL is a novel query language proposed by in the number of fields of the documents returned by servers? Facebook to implement Web-based APIs. In this paper, we (RQ5) When using GraphQL, what is the reduction in the size present a practical study on migrating API clients to this new of the documents returned by servers? To answer RQ1 and technology. First, we conduct a grey literature review to gain an in-depth understanding on the benefits and key characteristics RQ2, we conduct a grey literature review, covering 28 popular normally associated to GraphQL by practitioners. After that, we Web articles (mostly blog posts) about GraphQL. Since the assess such benefits in practice, by migrating seven systems to query language has just two years, we focus on grey literature, use GraphQL, instead of standard REST-based APIs. As our key instead of analysing scientific papers, as usually recommended result, we show that GraphQL can reduce the size of the JSON for emerging technologies [6]–[8]. As a result, we confirmed documents returned by REST APIs in 94% (in number of fields) and in 99% (in number of bytes), both median results. two key characteristics of GraphQL: (a) support to an hierar- Index Terms—GraphQL, REST, APIs, Migration Study chical data model, which can contribute to reduce the number of endpoints accessed by clients; (b) support to client-specific I. -

Session 5 – Main Theme
Database Systems Session 5 – Main Theme Relational Algebra, Relational Calculus, and SQL Dr. Jean-Claude Franchitti New York University Computer Science Department Courant Institute of Mathematical Sciences Presentation material partially based on textbook slides Fundamentals of Database Systems (7th Edition) by Ramez Elmasri and Shamkant Navathe Slides copyright © 2016 and on slides produced by Zvi Kedem copyight © 2014 1 Agenda 1 Session Overview 2 Relational Algebra and Relational Calculus 3 Relational Algebra Using SQL Syntax 5 Summary and Conclusion 2 Session Agenda . Session Overview . Relational Algebra and Relational Calculus . Relational Algebra Using SQL Syntax . Summary & Conclusion 3 What is the class about? . Course description and syllabus: » http://www.nyu.edu/classes/jcf/CSCI-GA.2433-001 » http://cs.nyu.edu/courses/spring16/CSCI-GA.2433-001/ . Textbooks: » Fundamentals of Database Systems (7th Edition) Ramez Elmasri and Shamkant Navathe Addition Wesley ISBN-10: 0133970779, ISBN-13: 978-0133970777 6th Edition (06/08/15) 4 Icons / Metaphors Information Common Realization Knowledge/Competency Pattern Governance Alignment Solution Approach 55 Agenda 1 Session Overview 2 Relational Algebra and Relational Calculus 3 Relational Algebra Using SQL Syntax 5 Summary and Conclusion 6 Agenda . Relational Algebra » Unary Relational Operations » Relational Algebra Operations From Set Theory » Binary Relational Operations » Additional Relational Operations » Examples of Queries in Relational Algebra . Relational Calculus » Tuple Relational Calculus » Domain Relational Calculus . Example Database Application (COMPANY) . Overview of the QBE language (appendix D) 7 The Relational Algebra and Relational Calculus . Relational algebra . Basic set of operations for the relational model . Relational algebra expression . Sequence of relational algebra operations . Relational calculus . Higher-level declarative language for specifying relational queries 8 Relational Algebra Overview . -

Chapter 5: Other Relational Languages Query-By-Example (QBE)
Chapter 5: Other Relational Languages I Query-by-Example (QBE) I Datalog Database System Concepts 5.1 ©Silberschatz, Korth and Sudarshan Query-by-Example (QBE) I Basic Structure I Queries on One Relation I Queries on Several Relations I The Condition Box I The Result Relation I Ordering the Display of Tuples I Aggregate Operations I Modification of the Database Database System Concepts 5.2 ©Silberschatz, Korth and Sudarshan 1 QBE — Basic Structure I A graphical query language which is based (roughly) on the domain relational calculus I Two dimensional syntax – system creates templates of relations that are requested by users I Queries are expressed “by example” Database System Concepts 5.3 ©Silberschatz, Korth and Sudarshan QBE Skeleton Tables for the Bank Example Database System Concepts 5.4 ©Silberschatz, Korth and Sudarshan 2 QBE Skeleton Tables (Cont.) Database System Concepts 5.5 ©Silberschatz, Korth and Sudarshan Queries on One Relation I Find all loan numbers at the Perryridge branch. • _x is a variable (optional; can be omitted in above query) • P. means print (display) • duplicates are removed by default • To retain duplicates use P.ALL Database System Concepts 5.6 ©Silberschatz, Korth and Sudarshan 3 Queries on One Relation (Cont.) I Display full details of all loans # Method 1: P._x P._y P._z # Method 2: Shorthand notation Database System Concepts 5.7 ©Silberschatz, Korth and Sudarshan Queries on One Relation (Cont.) I Find the loan number of all loans with a loan amount of more than $700 I Find names of all branches that are not located in Brooklyn Database System Concepts 5.8 ©Silberschatz, Korth and Sudarshan 4 Queries on One Relation (Cont.) I Find the loan numbers of all loans made jointly to Smith and Jones. -

Lecture 7: Relational Algebra and Select Queries
Lecture 7: Relational Algebra and Select Queries Introduction Over the past several lectures we have been discussing the design and construction of relational databases. Last lecture we looked specifically at building relations in a database for restaurants. Today’s discussion will look at using relational algebra to extract information from relations. We will begin the discussion with two definitions; then describe each relational algebra operator; and conclude with a brief discussion of how these operators are used to make select queries. Definitions Relational Algebra: a collection of operators, such as join, union, and intersect, that take relations as their operands and return relations as their result Relational Closure: because the product of every operation is the same kind of object as the input, the output can become input for additional operations For example, the Relational Operator, Union, operates on the relations, A and B, to produce a new relation, AB (relational algebra). Because AB is a relation, it can be used in subsequent operations (relational closure). Relational Algebra Operators In 1970, E.F. Codd identified eight relational algebra operators (Codd 1970). Today, these remain the basis for most database transactions. Codd categorized these eight at Traditional (Union, Intersection, Difference, and Product) and Special (Restrict, Project, Join, and Divide). The following table contains definitions and graphic aids for each of these operators. RNR/GEOG 417-517 Gary L. Christopherson Traditional Operators Union Returns a relation consisting of all tuples appearing in either or both of two specified relations. Relations must be same shape. That is, the two tables must contain the same number of attributes, and each attribute in the tables must be defined in exactly the same way. -

Interactively Discovering Query from Example and Explanation
Interactively Discovering ery from Example and Explanation Anna Fariha Sheikh Muhammad Sarwar University of Massachusetts Amherst University of Massachusetts Amherst [email protected] [email protected] ABSTRACT understand why the example tuples provided by the user qualify Database management systems are heavily used for storing struc- her information need. tured data and retrieving relevant data as per user requirement. Given a set of example tuples, E, some challenges are: (1) how However, a large group of database users are not expert in query to “capture” the associated explanations XE , (2) how to nd Q 0 language and they lack knowledge about database schema. As a eciently from E and (3) how to construct the query Q 2 Q result, they struggle in cases where data retrieval requires them to reecting user’s actual intention with the help of XE . The task to formulate complex SQL queries with complete knowledge about discover query from example is challenging to accomplish without database schema. Interestingly, the users are often aware of a few any subsequent user feedback for eliminating some of the candidate example tuples and the properties or concepts of the majority of queries. It is even more challenging to do so without understanding the values present in those tuples that enable them to explain their the reason behind the choice of example and subsequent feedback. information need. However, to the best of our knowledge, there We propose a framework that leverages user provided explanations exists no framework that can help the user to communicate those XE associated with E towards retrieving the query that “captures” E information to a database system. -

Object-Oriented Databases & Db4o
Object-oriented Databases & db4o by Annemarie Burger (479207) & Pinar Turkyilmaz (476728) INFO-H-415: Advanced Databases prof. Esteban Zimányi December 17, 2018 Object-oriented Databases & db4o Table of Contents Introduction 2 Object-oriented Databases 2 History 2 db4o 4 How it works 4 How to Build db4o 5 Object Manager Enterprise (OME) 6 Queries 10 Applications 11 Pros & Cons 12 Comparison 13 Query syntax 13 Opening the database 14 Storing an object 15 Displaying the database/result 15 Query by Example (QBE) 15 SELECT statement with WHERE clause 16 UPDATE an object 16 DELETE an object 17 SODA Queries 17 SELECT all 18 SELECT with WHERE 18 SELECT with WHERE NOT 18 SELECT wiıth OR 18 SELECT with AND 19 Native Queries 19 SELECT statement with WHERE clause 19 SELECT statement with range 20 SELECT with AND 20 SORTING 20 Multiple classes 21 Query time / Performance 23 Conclusion 25 Bibliography 27 Annemarie Burger (479207), Pinar Turkyilmaz (476728) 1 Object-oriented Databases & db4o Introduction Object-oriented databases have been in use for quite some time, but only when db4o - database for objects - was developed, it became a more used database management system choice. In this report we will discuss the history and applications of an object-oriented database management system (OODBMS), how they compare to relational databases (RDB) and we will deal extensively with db4o; how it works, pros and cons, and we will compare its queries to SQL queries. Object-oriented Databases Object-oriented databases have been in and out of fashion. The development of db4o had a big influence on this, but also the history and popularity of relational (object-oriented) databases has to be considered. -

Ameliorated Methodology for Retrieval of Data Using Query by Example Dr
International Journal of Computer Trends and Technology (IJCTT) – Volume 67 Issue 5 - May 2019 Ameliorated Methodology For Retrieval Of Data Using Query By Example Dr. R. N. Kulkarni1, Ms.Chinmayi A2, Ms.Meghana A3, Ms.Sai Harika K4, Ms.Saraswathi Y5 1 Department of Computer Science & Engineering, Ballari Institute of Technology and Management, Ballari, Karnataka, India. 2,3,4,5VIII semester BE(CSE), Ballari Institute of Technology & Management Ballari, India. Abstract — Query By Example (QBE) is a database II. LITERATURE SURVEY query language for relational databases. The Query By Example uses visual tables where the user enters the In the paper [1], the article discusses about Visual query commands and the output is displayed in a table form. systems and languages emerged to alleviate the end- In this paper, we are proposing an automated tool user data access problem by providing intuitive and where the user gives the input in the form of natural natural end-user experiences. This article, having language statement (query). The tool processes the Optique as a motivating scenario, is concerned with input query and retrieves the relevant matching field(s) ontology-based visual query formulation for querying or record(s) from the input database. The proposed tool relational databases for end users with no technical comprises a parser where it translates the natural skills and knowledge, such as on programming, language statement into the tokens and retrieves the databases, query languages, and with low/no tolerance, appropriate data from the database and displays the intension, or time to use and learn formal languages as output in the form of a table. -

Computable Queries for Relational Data Bases
JOURNAL OF COMPUTER AND SYSTEM SCIENCES 21, 156-178 (1980) Computable Queries for Relational Data Bases ASHOK K. CHANDRA AND DAVID HAREL IBM Thomas J. Watson Research Center, P.O. Box 218, Yorktown Heikhts, N. Y. 10598 Received September 26, 1979; revised March 24, 1980 The concept of “reasonable” queries on relational data bases is investigated. We provide an abstract characterization of the class of queries which are computable, and define the completeness of a query language as the property of being precisely powerful enough to express the queries in this class. This definition is then compared with other proposals for measuring the power of query languages. Our main result is the completeness of a simple programming language which can be thought of as consisting of the relational algebra augmented with the power of iteration. 1. INTRODUCTION The relational model of data bases, introduced by Codd [7, 81 is attracting increasing attention lately [2-6, 11, 12, 16, 22, 231. 0 ne of the significant virtues of the relational approach is that, besides lending itself readily to investigations of a mathematical nature, its modelling of real data bases is quite honest. One of the central themes of research in relational data bases is the investigation of query languages. A query language is a well-defined linguistic tool, the expressions of which correspond to requests one might want to make to a data base. With each request, or query, there is associated a response, or answer. For example, in a data base which involves information about the personnel of some company, a reasonable query might be one whose answer is the set of names and addresses of all employees earning over $15,000 a year.