Application Deployment and Dynamic Runtime - Initial Version
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Josh Malone Systems Administrator National Radio Astronomy Observatory Charlottesville, VA
heck What the #%!@ is wrong ^ with my server?!? Josh Malone Systems Administrator National Radio Astronomy Observatory Charlottesville, VA 1 Agenda • Intro to Monitoring • Internet protocols 101 • • Nagios SMTP • IMAP • Install/Config • HTTP • Usage • Custom plugins • Packet sniffing for dummies • Intro to Troubleshooting • Tools • telnet, openssl • grep, sed • ps, lsof, netstat 2 MONITORING 3 Automated Monitoring Workflow 4 Monitoring Packages: Open Source • • Pandora FMS • Opsview Core • Naemon • • • • • • Captialware ServerStatus • Core • Sensu All Trademarks and Logos are property of their respective trademark or copyright holders and are used by permission or fair use for education. Neither the presenter nor the conference organizers are affiliated in any way with any companies mentioned here. 5 Monitoring Packages: Commercial • Nagios XI • Groundwork • PRTG network monitor • CopperEgg • WhatsUp Gold • PRTG network monitor • op5 (Naemon) All Trademarks and Logos are property of their respective trademark or copyright holders and are used by permission or fair use for education. Neither the presenter nor the conference organizers are affiliated in any way with any companies mentioned here. 6 Why Automatic Service Monitoring? • Spot small problems before they become big ones • Learn about outages before your users do • Checklist when restoring from a power outage • Gives you better problem reports than users • Problems you might never spot otherwise • Failed HDDs in RAIDs • Full /var partitions • Logs not rotating • System temperature rising 7 Why Automatic Service Monitoring? • Capacity planning • Performance data can generate graphs of utilization • RAM, Disk, etc. • Availability reports - CAUTION • Easy to generate -- even easier to generate wrong • Make sure your configurations actually catch problems • Will also include problems with Nagios itself :( • If you’re going to quote your availability numbers (SLAs, etc.) make sure you understand what you’re actually monitoring. -

Pandora FMS: User Administration Guide
Pandora FMS 1.3.1 User Guide to Pandora FMS Administration Pandora FMS 1.3.1 User documentation April, 2008 Page 1 of 135 Pandora FMS 1.3.1 User Guide to Pandora FMS Administration Index 1 . Introduction to Pandora FMS ..................................................................................... 6 1.1. What is Pandora FMS? .............................................................................................. 6 1.2. What else can Pandora FMS do? ............................................................................... 6 1.2.1. Using agents ......................................................................................................7 1.3. Pandora FMS Architecture ........................................................................................ 9 1.4. Pandora FMS Agents................................................................................................ 10 1.4.1. Satellite Agents ............................................................................................... 12 1.4.2. XML data file ..................................................................................................12 1.5. Pandora FMS Servers............................................................................................... 14 1.6. Pandora FMS console...............................................................................................15 1.7. Database....................................................................................................................15 1.7.1. Compacting data ........................................................................................... -

1.3 SNMP Traps
PANDORA FMS NETWORK DEVICE MONITORING NETWORK DEVICE MONITORING PANDORA FMS pag. 2 INTRODUCTION 1. SNMP This document aims to explain how Pandora FMS is When we talk about SNMP Monitoring, the most able to monitor all network devices available on the important thing is to separate two concepts: Tests marke such as Routers, Switches, Modems, Access (polling) and Traps. points, etc. SNMP testing involves ordering Pandora FMS to execute a snmpget command to the SNMP device Pandora FMS can measure your network bandwidth such as a router or a switch or even a computer by consulting your router/switch through SNMP or with a SNMP agent installed. This is a synchronous by processing the network statistics sent by your operation (every X seconds). routers. Getting the correct information about the bandwidth and the consumption of the network In the opposite, receiving a SNMP trap is an asyn- devices is crucial to achieve a better network ma- chronous operation, that could happen or not, nagement. usually applied to get alerts coming from the device like, for example, when your switch drops a connec- These are some of the main things that Pandora tion with a port, or when your device gets too hot. FMS can do with your network: * Avoid bottlenecks in the network bandwidth and Pandora FMS works with SNMP using individual the server. OID’s. To Pandora FMS, each OID is a network mo- * Localize what applications and which servers are dule. So, if you want to monitor a 24 port Cisco Ca- consuming your bandwidth. talyst Switch, and be aware of the operative status * Provide better quality services to the users by of each port as well as the incoming and outgoing being proactive. -

Peter Helin, ABB Crane Systems Stefan Löfgren, Mälardalen
Fredrik Linder [email protected] Thesis for the Degree of Bachelor of Science in Engineering - Computer Network Engineering 15.0 hp IDT (academy for Innovation, Design and Technology) Mälardalen University Västerås, Sweden 2015-11-15 Supervisors: Peter Helin, ABB crane systems Stefan Löfgren, Mälardalen University Examinator: Mats Björkman, Mälardalen University | Network monitoring of automated harbor terminals | | Linder | ABSTRACT Nowadays, more information and services are migrated into computers using a network as the carrier for data communication. One example of this is the migration from PROFIBUS to PROFINET. The big problem is that there are no network monitoring solution implemented, despite the significance of the network. The drawback of not having a network monitor solution are many. This includes areas within security, availability, control and troubleshooting. The goal is to find a solution to this problem with providing a complete network monitor solution in ABB’s existing environment. The work was divided in four different parts, research, design, implementation and verification. Information from the World Wide Web (WWW) pointed towards that CentOS (operating system) together with OMD (network monitor software) would be the best choice for this task. The design phase described how all devices should be able to communicate with each other. The implementation part mostly were configuration of devices, such as servers, monitor software, switches and security. The configuration were made by using the built in user interface in each device. The verification part proved that all functions worked as expected, such as security and notifications. Rest of the verification could be seen in the web interface. The result is a complete solution demonstrated in ABB crane system’s lab, which includes a complete set of network devices that exist on sites all around the world. -

Monitoring Container Environment with Prometheus and Grafana
Matti Holopainen Monitoring Container Environment with Prometheus and Grafana Metropolia University of Applied Sciences Bachelor of Engineering Information and Communication Technology Bachelor’s Thesis 3.5.2021 Abstract Tekijä Matti Holopainen Otsikko Monitoring Container Environment with Prometheus and Grafana Sivumäärä Aika 50 sivua 3.5.2021 Tutkinto Insinööri (AMK) Tutkinto-ohjelma Tieto- ja viestintätekniikka Ammatillinen pääaine Ohjelmistotuotanto Ohjaajat Nina Simola, Projektipäällikkö Auvo Häkkinen, Yliopettaja Insinöörityön tavoitteena oli oppia pystyttämään monitorointijärjestelmä konttiympäristön re- surssien käytön seuraamista, monitorointia ja analysoimista varten. Tavoitteena oli helpot- taa monitorointijärjestelmän käyttöönottoa. Työ tehtiin käytettävien ohjelmistojen dokumen- taation ja käytännön tekemisellä opittujen asioiden pohjalta. Insinöörityön alussa käytiin läpi työssä käytettyjä teknologioita. Tämän jälkeen käytiin läpi monitorointi järjestelmän konfiguraatio ja käyttöönotto. Seuraavaksi tutustuttiin PromQL-ha- kukieleen, jonka jälkeen näytettiin kuinka pystyttää valvontamonitori ja hälytykset sähköpos- timuistutuksella. Työn lopussa käydään läpi kuinka monitorointijärjestelmässä saatua dataa analysoidaan ja mietitään miten monitorointijärjestelmää voisi parantaa. Keywords Monitorointi, Kontti, Prometheus, Grafana, Docker Abstract Author Matti Holopainen Title Monitoring Container Environment with Prometheus and Grafana Number of Pages Date 50 pages 3.5.2021 Degree Bachelor of Engineering Degree Programme Information -

Experimental Methods for the Evaluation of Big Data Systems Abdulqawi Saif
Experimental Methods for the Evaluation of Big Data Systems Abdulqawi Saif To cite this version: Abdulqawi Saif. Experimental Methods for the Evaluation of Big Data Systems. Computer Science [cs]. Université de Lorraine, 2020. English. NNT : 2020LORR0001. tel-02499941 HAL Id: tel-02499941 https://hal.univ-lorraine.fr/tel-02499941 Submitted on 5 Mar 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. AVERTISSEMENT Ce document est le fruit d'un long travail approuvé par le jury de soutenance et mis à disposition de l'ensemble de la communauté universitaire élargie. Il est soumis à la propriété intellectuelle de l'auteur. Ceci implique une obligation de citation et de référencement lors de l’utilisation de ce document. D'autre part, toute contrefaçon, plagiat, reproduction illicite encourt une poursuite pénale. Contact : [email protected] LIENS Code de la Propriété Intellectuelle. articles L 122. 4 Code de la Propriété Intellectuelle. articles L 335.2- L 335.10 http://www.cfcopies.com/V2/leg/leg_droi.php http://www.culture.gouv.fr/culture/infos-pratiques/droits/protection.htm -

Pentest-Report Prometheus 05.-06.2018 Cure53, Dr.-Ing
Dr.-Ing. Mario Heiderich, Cure53 Bielefelder Str. 14 D 10709 Berlin cure53.de · [email protected] Pentest-Report Prometheus 05.-06.2018 Cure53, Dr.-Ing. M. Heiderich, M. Wege, MSc. N. Krein, BSc. J. Hector, Dipl.-Ing. A. Inführ, J. Larsson Index Introduction Scope Test Methodology Part 1 (Manual Code Auditing) Part 2 (Code-Assisted Penetration Testing) Hardening Recommendations General Security Recommendations HTTP Security Headers Content Security Policy & Beyond Authentication / Authorization Non-Idempotent Request Protection Transport Security Clients/metrics endpoint API Endpoint Admin GUI Identified Vulnerabilities PRM-01-001 Web: Prometheus lifecycle killed with CSRF (Medium) PRM-01-003 Web: CORS header exposes API data to all origins (High) PRM-01-005 Server: Clients can cause Denial of Service via Gzip Bomb (Medium) Miscellaneous Issues PRM-01-002 Client: Clients leak Metrics data through unprotected endpoint (Low) PRM-01-004 Web: Parameters used insecurely in HTML templates (Low) Conclusions Cure53, Berlin · 06/11/18 1/18 Dr.-Ing. Mario Heiderich, Cure53 Bielefelder Str. 14 D 10709 Berlin cure53.de · [email protected] Introduction “An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.” From https://prometheus.io/ This report documents the findings of a security assessment targeting the Prometheus software compound and carried out by Cure53 in 2018. It should be noted that the project was sponsored by The Linux Foundation / Cloud Native Computing Foundation. In terms of the scope, the assignment entailed two main components as the Prometheus project was investigated through both a dedicated source code audit and comprehensive penetration testing. -

Virtualization/Containerization of the PNNL High Energy Physics Computing Infrastructure
Virtualization/Containerization of the PNNL High Energy Physics Computing Infrastructure Kevin Fox, David Cowley, Malachi Schram, Evan Felix, James Czebotar, Smith Gary Grid Services Deployed DIRAC Belle2DB Distributed Data Management REST Service System UI Service Gatekeeper Services Payload Service Many development and testing Squid Cache services Postgresql Relational Database Condor CE's FTS3 DIRAC SiteDirector CVMFS Stratum HTCondor cluster Zero Squid Cache One Leadership Class Facility CE's Authorization DIRAC SiteDirector Gums HPC Cluster VOMS Server with multiple VO's SE's BestMan2 Gridftp Backed by Lustre Note to the Sysadmins New methodology for system administration. Cloud Native focuses around what the user cares about most, not what we Sysadmins are used to caring about. Users care about services. Users do not care about machines providing service. Pets vs Cattle analogy. We must unlearn what we have learned. Try and separate pets and cattle to different pools of resource. Our Infrastructure Journey Individual machines Automated provisioning Virtual machines OpenStack Cloud Repo Mirrors Containers Kubernetes Infrastructure Deployed Kubernetes + Docker Engine Prometheus OpenStack + KVM Grafana Ceph CheckMK GitLab ElasticSearch Lustre 389-DS LoadBalancing/HA Cobbler PerfSonar NFS Metric/Log gathering is very important for system problem analysis Current tool stack includes CheckMK Grafana/Prometheus Kibana/ElasticSearch/LogShippers Kubernetes Load Balancers Give users a load balancer to talk to. Back it with multiple instances of the software making up of the service whenever possible. When not possible, make it very quick to redeploy. Deployment Flow Separate Build and Deploy steps. Kubernetes/Docker example: #Build > docker build . -t pnnlhep/condor-compute:2017-09-01 … > docker push pnnlhep/condor-compute:2017-09-01 … #Deploy > helm install --name ce0-compute condor-compute \ –set version=2017-09-01 .. -
Lumada Edge Version
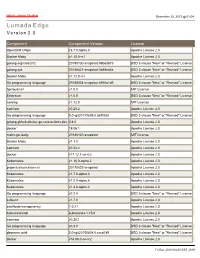
Hitachi - Inspire The Next December 20, 2019 @ 01:04 Lumada Edge V e r s i o n 3 . 0 Component Component Version License OpenShift Origin v3.7.0-alpha.0 Apache License 2.0 Docker Moby v1.10.0-rc1 Apache License 2.0 golang.org/x/oauth2 20190130-snapshot-99b60b75 BSD 3-clause "New" or "Revised" License golang sys 20180821-snapshot-3b58ed4a BSD 3-clause "New" or "Revised" License Docker Moby v1.12.0-rc1 Apache License 2.0 Go programming language 20180824-snapshot-4910a1d5 BSD 3-clause "New" or "Revised" License hpcloud-tail v1.0.0 MIT License Ethereum v1.5.0 BSD 3-clause "New" or "Revised" License zerolog v1.12.0 MIT License cadvisor v0.28.2 Apache License 2.0 Go programming language 0.0~git20170629.0.5ef0053 BSD 3-clause "New" or "Revised" License golang-github-docker-go-connections-dev 0.4.0 Apache License 2.0 docker 18.06.1 Apache License 2.0 mattn-go-isatty 20180120-snapshot MIT License Docker Moby v1.1.0 Apache License 2.0 cadvisor v0.23.4 Apache License 2.0 docker v17.12.1-ce-rc2 Apache License 2.0 Kubernetes v1.15.0-alpha.2 Apache License 2.0 projectcalico/calico-cni 20170522-snapshot Apache License 2.0 Kubernetes v1.7.0-alpha.3 Apache License 2.0 Kubernetes v1.2.0-alpha.6 Apache License 2.0 Kubernetes v1.4.0-alpha.2 Apache License 2.0 Go programming language v0.2.0 BSD 3-clause "New" or "Revised" License kubevirt v1.7.0 Apache License 2.0 certificate-transparency 1.0.21 Apache License 2.0 kubernetes/api kubernetes-1.15.0 Apache License 2.0 cadvisor v0.28.1 Apache License 2.0 Go programming language v0.3.0 BSD 3-clause "New" or "Revised" -

(PDF) What Can Cloud Native Do for Csps?
What Can Cloud Native Do for CSPs? Cloud Native Can Improve…. Development Cloud native is a way of approaching the development and deployment of applications in such a way that takes account of the characteristics and nature of the cloud—resulting in processes and workflows that fully take advantage of the platform. Operations Cloud native is an approach to building and running software applications that exploits the advantages of the cloud computing delivery model. Cloud-native is about how applications are created and deployed, not where. Infrastructure Cloud native platforms available “as a service” in the cloud can accommodate hybrid and multi-cloud environments. What are Cloud Native Core Concepts? Continuous Integration DevSecOps Microservices Containers and Deployment Not My Problem Release Once Every Tightly Coupled Directly Ported to a VM Separate tools, varied 6 Months Components Monolithic application incentives, opaque process More bugs in production Slow deployment cycles unable to leverage modern waiting on integrated tests cloud tools teams Shared Responsibility Release Early Loosely Coupled Packaged for Containers Common incentives, tools, and Often Components Focus on business process and culture Higher quality of code Automated deploy without software by leveraging waiting on individual the platform ecosystem components What are the Benefits of Cloud Native? Business Optimization Microservices architecture enables flexibility, agility, and reuse across various platforms. CAPEX and OPEX Reduction Service-based architecture allows integration with the public Cloud to handle overload capacity, offer new services with less development, and take advantage of other 3rd party services such as analytics, machine learning, and artificial intelligence. Service Agility Common services can be shared by all network functions deployed on the Cloud-Native Environment (CNE). -

Comparative Research Review
American Journal of Applied Sciences Literature Online Traffic Measurement and Analysis in Big Data: Comparative Research Review 1Lena T. Ibrahim, 1Rosilah Hassan, 1Kamsuriah Ahmad, 1Asrul Nizam Asat and 2Halizah Omar 1Research Center for Software Technology and Management (SOFTAM), Faculty of Information Science and Technology, Universiti Kebangsaan Malaysia, 43600 Bangi, Selangor, Malaysia 2Pusat Citra UKM, Universiti Kebangsaan Malaysia, 43600 Bangi, Selangor, Malaysia Article history Abstract: The Internet traffic measurement and analysis is important to Received: 16-11-2015 avoid many problems of data transferring via online networks such as data Revised: 23-04-2016 losing and slow data transferring. The Internet traffic measuring and Accepted: 27-04-2016 analysis could be effective to avoid the data transferring challenges. The Internet traffic measuring and analysis flexibility is important due to many Corresponding Author: Lena T. Ibrahim reasons such as dynamicity of transferred data such as size and format, the Research Center for Software data transferring protocols and the dynamicity of measure the traffic based Technology and Management on the networks available resources depend on the transferred data (SOFTAM), Faculty of characteristics. The main objective of this paper is to review the most Information Science and flexible Internet traffic measuring and analysis tools that could be adopted Technology, Universiti to handle the dynamicity of data transferring characteristics. The Kebangsaan Malaysia, 43600 significance results -

Evaluation of Different Monitoring Software Packages
Ref. Ares(2017)4003221 - 10/08/2017 JUMPING JIVE 730884 – JUMPING JIVE – H2020-INFRADEV- 2016-2017/H2020-INFRADEV-2016-1 Evaluation of software packages (for system monitoring) Written by A. Neidhardt Deliverable 8.4 Submission date: 07.08.2017 Content 1 Overview .............................................................................................................. 3 2 Evaluation criteria................................................................................................. 5 3 Used software packages for system monitoring and control of VLBI ................... 7 3.1 VLBI network monitoring ............................................................................... 8 3.1.1 "MoniCA" or “openMoniCA” (Australia Telescope National Facility and AuScope geodetic VLBI telescopes) .................................................................... 8 3.1.2 ZABBIX & SysMon (Wettzell Observatory) ........................................... 11 3.1.3 Telegraf - InfluxDB - Grafana (TIG) (NASA FS) .................................... 14 3.1.4 Radboud Radio Lab VLBI monitor (EVN, mm-VLBI) ............................. 18 3.1.5 Monitoring and Control Infrastructure MCI (MIT Haystack Observatory)20 3.1.6 Industrial monitoring tools (Nagios, Zabbix, etc.) .................................. 22 3.1.7 SKA Telescope Manager (SKA) ............................................................ 30 3.1.8 Individual Linux scripts .......................................................................... 32 3.1.9 Goddard Mission Services Evolution