Implementing “Wrk” Discussing the Design and Implementation of an Experimental Programming Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Differential Fuzzing the Webassembly
Master’s Programme in Security and Cloud Computing Differential Fuzzing the WebAssembly Master’s Thesis Gilang Mentari Hamidy MASTER’S THESIS Aalto University - EURECOM MASTER’STHESIS 2020 Differential Fuzzing the WebAssembly Fuzzing Différentiel le WebAssembly Gilang Mentari Hamidy This thesis is a public document and does not contain any confidential information. Cette thèse est un document public et ne contient aucun information confidentielle. Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Technology. Antibes, 27 July 2020 Supervisor: Prof. Davide Balzarotti, EURECOM Co-Supervisor: Prof. Jan-Erik Ekberg, Aalto University Copyright © 2020 Gilang Mentari Hamidy Aalto University - School of Science EURECOM Master’s Programme in Security and Cloud Computing Abstract Author Gilang Mentari Hamidy Title Differential Fuzzing the WebAssembly School School of Science Degree programme Master of Science Major Security and Cloud Computing (SECCLO) Code SCI3084 Supervisor Prof. Davide Balzarotti, EURECOM Prof. Jan-Erik Ekberg, Aalto University Level Master’s thesis Date 27 July 2020 Pages 133 Language English Abstract WebAssembly, colloquially known as Wasm, is a specification for an intermediate representation that is suitable for the web environment, particularly in the client-side. It provides a machine abstraction and hardware-agnostic instruction sets, where a high-level programming language can target the compilation to the Wasm instead of specific hardware architecture. The JavaScript engine implements the Wasm specification and recompiles the Wasm instruction to the target machine instruction where the program is executed. Technically, Wasm is similar to a popular virtual machine bytecode, such as Java Virtual Machine (JVM) or Microsoft Intermediate Language (MSIL). -

Just Another Perl Hack Neil Bowers1 Canon Research Centre Europe
Weblint: Just Another Perl Hack Neil Bowers1 Canon Research Centre Europe Abstract Weblint is a utility for checking the syntax and style of HTML pages. It was inspired by lint [15], which performs a similar function for C and C++ programmers. Weblint does not aspire to be a strict SGML validator, but to provide helpful comments for humans. The importance of quality assurance for web sites is introduced, and one particular area, validation of HTML, is described in more detail. The bulk of the paper is devoted to weblint: what it is, how it is used, and the design and implementation of the current development version. 1. Introduction The conclusion opens with a summary of the information and opinions given in this paper. A Web sites are becoming an increasingly critical part of selection of the lessons learned over the last four years how many companies do business. For many companies is given, followed by plans for the future, and related web sites are their business. It is therefore critical that ideas. owners of web sites perform regular testing and analysis, to ensure quality of service. 2. Web Site Quality Assurance There are many different checks and analyses which The following are some of the questions you should be you can run on a site. For example, how usable is your asking yourself if you have a web presence. I have site when accessed via a modem? An incomplete list of limited the list to those points which are relevant to similar analyses are given at the start of Section 2. -
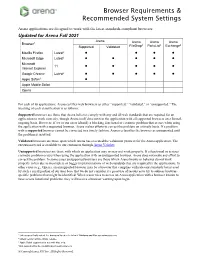
Browser Requirements & Recommended
Browser Requirements & Recommended System Settings Arena applications are designed to work with the latest standards-compliant browsers. Updated for Arena Fall 2021 Arena 1 Arena Arena Arena Browser 4 4 4 Supported Validated FileDrop PartsList Exchange Mozilla Firefox Latest2 l l l l Microsoft Edge Latest2 l l l l l Microsoft 11 l l l l l Internet Explorer Google Chrome Latest2 l l l l l Apple Safari3 l Apple Mobile Safari Opera For each of its applications, Arena certifies web browsers as either “supported,” “validated,” or “unsupported.” The meaning of each classification is as follows: Supported browsers are those that Arena believes comply with any and all web standards that are required for an application to work correctly, though Arena itself does not test the application with all supported browsers on a formal, ongoing basis. However, if we or our users identify a blocking functional or cosmetic problem that occurs when using the application with a supported browser, Arena makes efforts to correct the problem on a timely basis. If a problem with a supported browser cannot be corrected in a timely fashion, Arena reclassifies the browser as unsupported until the problem is resolved. Validated browsers are those upon which Arena has executed the validation protocol for the Arena application. The execution record is available to our customers through Arena Validate. Unsupported browsers are those with which an application may or may not work properly. If a functional or serious cosmetic problem occurs when using the application with an unsupported browser, Arena does not make any effort to correct the problem. -

Seamless Offloading of Web App Computations from Mobile Device to Edge Clouds Via HTML5 Web Worker Migration
Seamless Offloading of Web App Computations From Mobile Device to Edge Clouds via HTML5 Web Worker Migration Hyuk Jin Jeong Seoul National University SoCC 2019 Virtual Machine & Optimization Laboratory Department of Electrical and Computer Engineering Seoul National University Computation Offloading Mobile clients have limited hardware resources Require computation offloading to servers E.g., cloud gaming or cloud ML services for mobile Traditional cloud servers are located far from clients Suffer from high latency 60~70 ms (RTT from our lab to the closest Google Cloud DC) Latency<50 ms is preferred for time-critical games Cloud data center End device [Kjetil Raaen, NIK 2014] 2 Virtual Machine & Optimization Laboratory Edge Cloud Edge servers are located at the edge of the network Provide ultra low (~a few ms) latency Central Clouds Mobile WiFi APs Small cells Edge Device Cloud Clouds What if a user moves? 3 Virtual Machine & Optimization Laboratory A Major Issue: User Mobility How to seamlessly provide a service when a user moves to a different server? Resume the service at the new server What if execution state (e.g., game data) remains on the previous server? This is a challenging problem Edge computing community has struggled to solve it • VM Handoff [Ha et al. SEC’ 17], Container Migration [Lele Ma et al. SEC’ 17], Serverless Edge Computing [Claudio Cicconetti et al. PerCom’ 19] We propose a new approach for web apps based on app migration techniques 4 Virtual Machine & Optimization Laboratory Outline Motivation Proposed system WebAssembly -

Webassembly a New World of Native Exploits on the Web Agenda
WebAssembly A New World Of Native Exploits On The Web Agenda • Introduction • The WebAssembly Platform • Emscripten • Possible Exploit Scenarios • Conclusion Wasm: What is it good for? ● Archive.org web emulators ● Image/processing ● Video Games ● 3D Modeling ● Cryptography Libraries ● Desktop Application Ports Wasm: Crazy Incoming ● Browsix, jslinux ● Runtime.js (Node), Nebulet ● Cervus ● eWASM Java Applet Joke Slide ● Sandboxed ● Virtual Machine, runs its own instruction set ● Runs in your browser ● Write once, run anywhere ● In the future, will be embedded in other targets What Is WebAssembly? ● A relatively small set of low-level instructions ○ Instructions are executed by browsers ● Native code can be compiled into WebAssembly ○ Allows web developers to take their native C/C++ code to the browser ■ Or Rust, or Go, or anything else that can compile to Wasm ○ Improved Performance Over JavaScript ● Already widely supported in the latest versions of all major browsers ○ Not limited to running in browsers, Wasm could be anywhere Wasm: A Stack Machine Text Format Example Linear Memory Model Subtitle Function Pointers Wasm in the Browser ● Wasm doesn’t have access to memory, DOM, etc. ● Wasm functions can be exported to be callable from JS ● JS functions can be imported into Wasm ● Wasm’s linear memory is a JS resizable ArrayBuffer ● Memory can be shared across instances of Wasm ● Tables are accessible via JS, or can be shared to other instances of Wasm Demo: Wasm in a nutshell Emscripten ● Emscripten is an SDK that compiles C/C++ into .wasm binaries ● LLVM/Clang derivative ● Includes built-in C libraries, etc. ● Also produces JS and HTML code to allow easy integration into a site. -

Superoptimization of Webassembly Bytecode
Superoptimization of WebAssembly Bytecode Javier Cabrera Arteaga Shrinish Donde Jian Gu Orestis Floros [email protected] [email protected] [email protected] [email protected] Lucas Satabin Benoit Baudry Martin Monperrus [email protected] [email protected] [email protected] ABSTRACT 2 BACKGROUND Motivated by the fast adoption of WebAssembly, we propose the 2.1 WebAssembly first functional pipeline to support the superoptimization of Web- WebAssembly is a binary instruction format for a stack-based vir- Assembly bytecode. Our pipeline works over LLVM and Souper. tual machine [17]. As described in the WebAssembly Core Specifica- We evaluate our superoptimization pipeline with 12 programs from tion [7], WebAssembly is a portable, low-level code format designed the Rosetta code project. Our pipeline improves the code section for efficient execution and compact representation. WebAssembly size of 8 out of 12 programs. We discuss the challenges faced in has been first announced publicly in 2015. Since 2017, it has been superoptimization of WebAssembly with two case studies. implemented by four major web browsers (Chrome, Edge, Firefox, and Safari). A paper by Haas et al. [11] formalizes the language and 1 INTRODUCTION its type system, and explains the design rationale. The main goal of WebAssembly is to enable high performance After HTML, CSS, and JavaScript, WebAssembly (WASM) has be- applications on the web. WebAssembly can run as a standalone VM come the fourth standard language for web development [7]. This or in other environments such as Arduino [10]. It is independent new language has been designed to be fast, platform-independent, of any specific hardware or languages and can be compiled for and experiments have shown that WebAssembly can have an over- modern architectures or devices, from a wide variety of high-level head as low as 10% compared to native code [11]. -

Arena Training Guide for Administrators Table of Contents
Arena training guide for administrators Table of contents Preface 4 About this guide 4 Get to know Axiell 4 About Arena 5 Liferay 5 Portlets 5 Language handling 5 Styling 5 Arena architecture 6 Administration in Arena 7 Arena articles 7 Signing in to Arena 7 Signing in to Liferay 8 The Arena administration user interface 8 Accounts 11 User types in Arena 11 Permissions 12 Managing users in Liferay 14 Managing a roles in Liferay 16 Arena portal site administration 17 Admin: installation details 17 Site settings 19 Managing pages 21 Page permissions 21 Navigation 21 Configuring pages 21 Creating a page 22 Deleting a page 23 Arena Nova 25 Focus shortcuts 25 That’s how it works-articles 25 News articles 26 Event articles 26 Branch articles 26 FAQ articles 27 Image resources and image handling 27 Portlets in Arena 28 Symbols in the list of portlets 28 Portlets required for basic Arena functionality 28 Placement of portlets 29 Configuring portlets 30 The control toolbar 30 Look and feel 30 2 Assigning user permissions to portlets and pages 30 Liferay articles 32 Creating a Liferay article 32 Adding a Liferay article on a page 32 Arena articles 33 Approving articles 33 Handling abuse and reviews 34 Admin: moderation 34 Searching in catalogue records 36 Single words 36 Phrases 36 Multiple words 36 Truncation 36 Boolean operators 36 Fuzzy search and the similarity factor 36 Search parameters for catalogue records 37 Search parameters for Arena articles 40 Examples 40 Linking and syntaxes 41 Dynamic links 41 Syntax for similar titles 42 Syntax for other titles by the same author 42 Syntax for dynamic news list 42 3 Preface Simple, stylish and engaging, Arena is perfect for archives, libraries and museums to showcase and organize their collections in the public domain. -

Swivel: Hardening Webassembly Against Spectre
Swivel: Hardening WebAssembly against Spectre Shravan Narayan† Craig Disselkoen† Daniel Moghimi¶† Sunjay Cauligi† Evan Johnson† Zhao Gang† Anjo Vahldiek-Oberwagner? Ravi Sahita∗ Hovav Shacham‡ Dean Tullsen† Deian Stefan† †UC San Diego ¶Worcester Polytechnic Institute ?Intel Labs ∗Intel ‡UT Austin Abstract in recent microarchitectures [41] (see Section 6.2). In con- We describe Swivel, a new compiler framework for hardening trast, Spectre can allow attackers to bypass Wasm’s isolation WebAssembly (Wasm) against Spectre attacks. Outside the boundary on almost all superscalar CPUs [3, 4, 35]—and, browser, Wasm has become a popular lightweight, in-process unfortunately, current mitigations for Spectre cannot be im- sandbox and is, for example, used in production to isolate plemented entirely in hardware [5, 13, 43, 51, 59, 76, 81, 93]. different clients on edge clouds and function-as-a-service On multi-tenant serverless, edge-cloud, and function as a platforms. Unfortunately, Spectre attacks can bypass Wasm’s service (FaaS) platforms, where Wasm is used as the way to isolation guarantees. Swivel hardens Wasm against this class isolate mutually distursting tenants, this is particulary con- 1 of attacks by ensuring that potentially malicious code can nei- cerning: A malicious tenant can use Spectre to break out of ther use Spectre attacks to break out of the Wasm sandbox nor the sandbox and read another tenant’s secrets in two steps coerce victim code—another Wasm client or the embedding (§5.4). First, they mistrain different components of the under- process—to leak secret data. lying control flow prediction—the conditional branch predic- We describe two Swivel designs, a software-only approach tor (CBP), branch target buffer (BTB), or return stack buffer that can be used on existing CPUs, and a hardware-assisted (RSB)—to speculatively execute code that accesses data out- approach that uses extension available in Intel® 11th genera- side the sandbox boundary. -

Discontinued Browsers List
Discontinued Browsers List Look back into history at the fallen windows of yesteryear. Welcome to the dead pool. We include both officially discontinued, as well as those that have not updated. If you are interested in browsers that still work, try our big browser list. All links open in new windows. 1. Abaco (discontinued) http://lab-fgb.com/abaco 2. Acoo (last updated 2009) http://www.acoobrowser.com 3. Amaya (discontinued 2013) https://www.w3.org/Amaya 4. AOL Explorer (discontinued 2006) https://www.aol.com 5. AMosaic (discontinued in 2006) No website 6. Arachne (last updated 2013) http://www.glennmcc.org 7. Arena (discontinued in 1998) https://www.w3.org/Arena 8. Ariadna (discontinued in 1998) http://www.ariadna.ru 9. Arora (discontinued in 2011) https://github.com/Arora/arora 10. AWeb (last updated 2001) http://www.amitrix.com/aweb.html 11. Baidu (discontinued 2019) https://liulanqi.baidu.com 12. Beamrise (last updated 2014) http://www.sien.com 13. Beonex Communicator (discontinued in 2004) https://www.beonex.com 14. BlackHawk (last updated 2015) http://www.netgate.sk/blackhawk 15. Bolt (discontinued 2011) No website 16. Browse3d (last updated 2005) http://www.browse3d.com 17. Browzar (last updated 2013) http://www.browzar.com 18. Camino (discontinued in 2013) http://caminobrowser.org 19. Classilla (last updated 2014) https://www.floodgap.com/software/classilla 20. CometBird (discontinued 2015) http://www.cometbird.com 21. Conkeror (last updated 2016) http://conkeror.org 22. Crazy Browser (last updated 2013) No website 23. Deepnet Explorer (discontinued in 2006) http://www.deepnetexplorer.com 24. Enigma (last updated 2012) No website 25. -

Webassembly Backgrounder
Copyright (c) Clipcode Limited 2021 - All rights reserved Clipcode is a trademark of Clipcode Limited - All rights reserved WebAssembly Backgrounder [DRAFT] Written By Eamon O’Tuathail Last updated: January 8, 2021 Table of Contents 1: Introduction.................................................................................................3 2: Tooling & Getting Started.............................................................................13 3: Values.......................................................................................................18 4: Flow Control...............................................................................................27 5: Functions...................................................................................................33 6: (Linear) Memory.........................................................................................42 7: Tables........................................................................................................50 1: Introduction Overview The WebAssembly specification is a definition of an instruction set architecture (ISA) for a virtual CPU that runs inside a host embedder. Initially, the most widely used embedder is the modern standard web browser (no plug-ins required). Other types of embedders can run on the server (e.g. inside standard Node.js v8 – no add-ons required) or in future there could be more specialist host embedders such as a cross- platform macro-engine inside desktop, mobile or IoT applications. Google, Mozilla, Microsoft and -

Unix Quickref.Dvi
Summary of UNIX commands Table of Contents df [dirname] display free disk space. If dirname is omitted, 1. Directory and file commands 1994,1995,1996 Budi Rahardjo ([email protected]) display all available disks. The output maybe This is a summary of UNIX commands available 2. Print-related commands in blocks or in Kbytes. Use df -k in Solaris. on most UNIX systems. Depending on the config- uration, some of the commands may be unavailable 3. Miscellaneous commands du [dirname] on your site. These commands may be a commer- display disk usage. cial program, freeware or public domain program that 4. Process management must be installed separately, or probably just not in less filename your search path. Check your local documentation or 5. File archive and compression display filename one screenful. A pager similar manual pages for more details (e.g. man program- to (better than) more. 6. Text editors name). This reference card, obviously, cannot de- ls [dirname] scribe all UNIX commands in details, but instead I 7. Mail programs picked commands that are useful and interesting from list the content of directory dirname. Options: a user's point of view. 8. Usnet news -a display hidden files, -l display in long format 9. File transfer and remote access mkdir dirname Disclaimer make directory dirname The author makes no warranty of any kind, expressed 10. X window or implied, including the warranties of merchantabil- more filename 11. Graph, Plot, Image processing tools ity or fitness for a particular purpose, with regard to view file filename one screenfull at a time the use of commands contained in this reference card. -

Developing an Open Source Option for NASA Software
Developing An Open Source Option for NASA Software Patrick J. Moran NASA Ames Research Center, M/S T27A-2 Moffett Field, CA, 94035, USA [email protected] NAS Technical Report NAS-03-nnn April 7,2003 Abstract We present arguments in favor of developing an Open Source option for NASA software; in particular we discuss how Open Source is compatible with NASA’s mission. We compare and contrast several of the leading Open Source licenses, and propose one - the Mozilla license - for use by NASA. We also address some of the related issues for NASA with respect to Open Source. In particular, we dis- cuss some of the elements in the “External Release of NASA Software” document (NPG 2210.1A) that will likely have to be changed in order to make Open Source a’reality withm the agency. Contents 1 Introduction 3 2 Why Open Source Software? 4 2.1 NASA Perspective ........................... 4 2.2 Software Users’ Perspective ...................... 5 2.3 Software Developers’ Perspective ................... 5 2.4 PITAC Perspective ........................... 6 2.5 Academia Perspective .......................... 6 2.6 Department of Energy Perspective ................... 7 3 The Leading Open Source Licenses 7 3.1 GNU General Public License ...................... 7 3.2 GNU Lesser General Public License .................. 8 3.3 Mozilla Public License ......................... 8 3.4 BSD License .............................. 8 1 4 License Properties 9 4.1 Recognized by the Open Source Initiative ............... 9 4.2 Attribution Required ........................... 9 4.3 Redistribution Allowed ......................... 10 4.4 License Trumps in Derivative Works .................. 10 4.5 Derivatives Must Be Open Source Software .............. 10 4.6 Commercialization Allowed .....................